文章目录
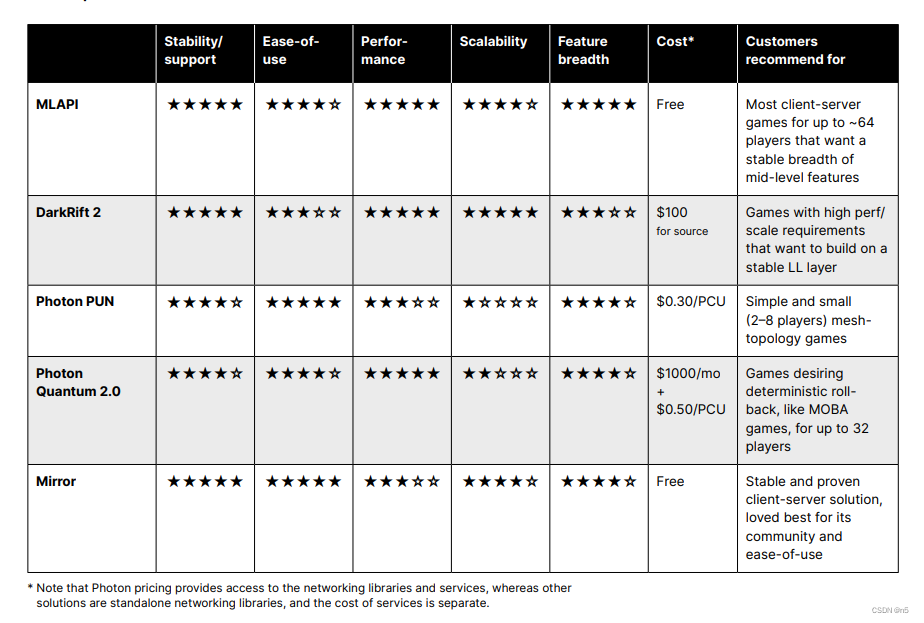
- 1. rpm安装ck
- 2. 集群规划
- 3. config.xml文件配置
- (1)分片副本信息配置
- (2)zookeeper信息配置
- (3)macros 信息配置
- (4)注释掉映射信息
- (5)修改实例中的日志路径
- (6)user.xml信息配置
- (7)端口修改
- 4. 服务启停(需要指定配置文件)
- 5. clickhouse客户端常用参数
- 6. clickhouse CPU内存优化配置
- 7. 用户密码配置
官方文档
1. rpm安装ck
分别在每台集器上上传rpm包,放在同一目录下,然后直接解压即可。
解压命令:sudo rpm -ivh *.rpm
2. 集群规划
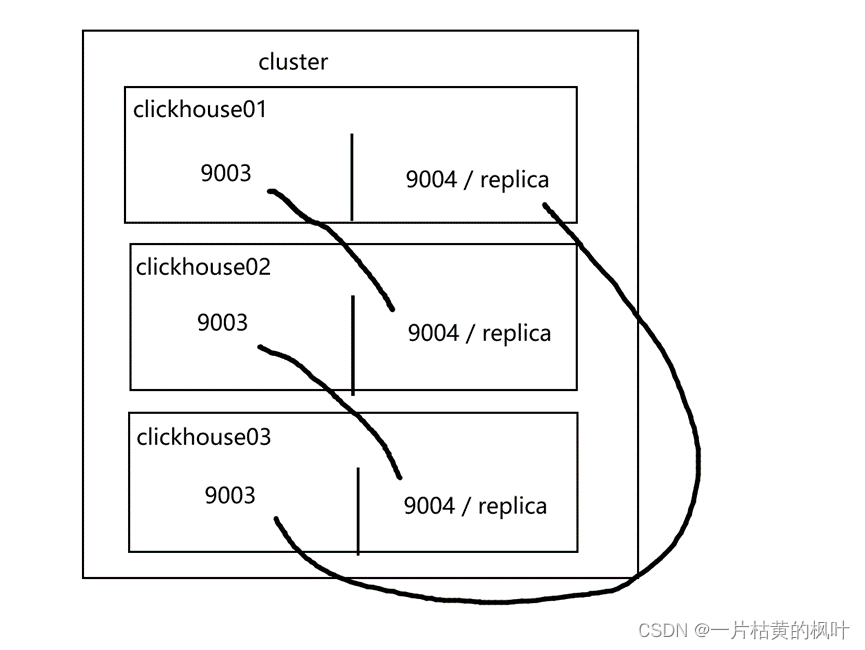
经过测试验证,6实例配置文件的所有信息统一都放在config.xml文件中更妥当,省略去metrika.xml文件。否则6实例需要多维护12个配置文件,而且config.xml中配置映射也可能找不到其它metrika.xml文件,最终导致客户端不显示集群,无法正常使用。
Clickhouse01 实例1
端口tcp_port 9003, http_port 8123, interserver_http_port 9009;
config.xml文件为/etc/clickhouse-server/ config01.xml;
users.xml文件为/etc/clickhouse-server/users01.xml;
Clickhouse01 实例2
端口tcp_port 9004, http_port 8124, interserver_http_port 9010;
config.xml文件为/etc/clickhouse-server/ config02.xml;
users.xml文件为/etc/clickhouse-server/users02.xml;
Clickhouse02 实例1
端口tcp_port 9003, http_port 8123, interserver_http_port 9009;
config.xml文件为/etc/clickhouse-server/ config01.xml;
users.xml文件为/etc/clickhouse-server/users01.xml;
Clickhouse02 实例2
端口tcp_port 9004, http_port 8124, interserver_http_port 9010;
config.xml文件为/etc/clickhouse-server/ config02.xml;
users.xml文件为/etc/clickhouse-server/users02.xml;
Clickhouse03 实例1
端口tcp_port 9003, http_port 8123, interserver_http_port 9009;
config.xml文件为/etc/clickhouse-server/ config01.xml;
users.xml文件为/etc/clickhouse-server/users01.xml;
Clickhouse03 实例2
端口tcp_port 9004, http_port 8124, interserver_http_port 9010;
config.xml文件为/etc/clickhouse-server/ config02.xml;
users.xml文件为/etc/clickhouse-server/users02.xml;
3. config.xml文件配置
(1)分片副本信息配置
如下信息是3分片1副本的配置信息,这部分信息是所有实例中相同的
需要在每台节点下中的config01.xml 和 config02.xml 文件中配置。
<shards3_replications2>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton1</host>
<port>9003</port>
</replica>
<replica>
<host>foton2</host>
<port>9004</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton2</host>
<port>9003</port>
</replica>
<replica>
<host>foton3</host>
<port>9004</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton3</host>
<port>9003</port>
</replica>
<replica>
<host>foton1</host>
<port>9004</port>
</replica>
</shard>
</shards3_replications2>
(2)zookeeper信息配置
这部分信息也是所有实例相同
<zookeeper>
<node>
<host>foton1</host>
<port>2181</port>
</node>
<node>
<host>foton2</host>
<port>2181</port>
</node>
<node>
<host>foton3</host>
<port>2181</port>
</node>
</zookeeper>
(3)macros 信息配置
Clickhouse01下的config01.xml配置如下:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01_01_1</replica>
</macros>
Clickhouse01下的config02.xml配置如下:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01_03_2</replica>
</macros>
Clickhouse02下的config01.xml配置如下:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01_02_1</replica>
</macros>
Clickhouse02下的config02.xml配置如下:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>cluster01_01_2</replica>
</macros>
Clickhouse03下的config01.xml配置如下:
<macros>
<layer>01</layer>
<shard>03</shard>
<replica>cluster01_03_1</replica>
</macros>
Clickhouse03下的config02.xml配置如下:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>
(4)注释掉映射信息
由于省略去了metrika.xml文件,在config.xml中要注释掉对应的映射信息
<!--
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika*.xml</include_from>
-->
(5)修改实例中的日志路径
Clickhouse01/clickhouse02/clickhouse03中config01.xml中修改如下:
<log>/var/log/clickhouse-server01/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server01/clickhouse-server.err.log</errorlog>
<!-- Path to data directory, with trailing slash. -->
<path>/var/lib/clickhouse01/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/var/lib/clickhouse01/tmp/</tmp_path>
<!-- Directory with user provided files that are accessible by 'file' table function. -->
<user_files_path>/var/lib/clickhouse01/user_files/</user_files_path>
Clickhouse01/clickhouse02/clickhouse03中config02.xml中修改如下:
<log>/var/log/clickhouse-server02/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server02/clickhouse-server.err.log</errorlog>
<!-- Path to data directory, with trailing slash. -->
<path>/var/lib/clickhouse02/</path>
<!-- Path to temporary data for processing hard queries. -->
<tmp_path>/var/lib/clickhouse02/tmp/</tmp_path>
<!-- Directory with user provided files that are accessible by 'file' table function. -->
<user_files_path>/var/lib/clickhouse02/user_files/</user_files_path>
(6)user.xml信息配置
Clickhouse01/clickhouse02/clickhouse03中config01.xml中修改如下:
<!-- Sources to read users, roles, access rights, profiles of settings, quotas. -->
<user_directories>
<users_xml>
<!-- Path to configuration file with predefined users. -->
<path>users01.xml</path>
</users_xml>
<local_directory>
<!-- Path to folder where users created by SQL commands are stored. -->
<path>/var/lib/clickhouse01/access/</path>
</local_directory>
Clickhouse01/clickhouse02/clickhouse03中config01.xml中修改如下:
<!-- Sources to read users, roles, access rights, profiles of settings, quotas. -->
<user_directories>
<users_xml>
<!-- Path to configuration file with predefined users. -->
<path>users02.xml</path>
</users_xml>
<local_directory>
<!-- Path to folder where users created by SQL commands are stored. -->
<path>/var/lib/clickhouse02/access/</path>
</local_directory>
(7)端口修改
Clickhouse01/clickhouse02/clickhouse03中config01.xml中修改如下:
<http_port>8123</http_port>
<tcp_port>9003</tcp_port>
Clickhouse01/clickhouse02/clickhouse03中config02.xml中修改如下:
<http_port>8124</http_port>
<tcp_port>9004</tcp_port>
4. 服务启停(需要指定配置文件)
| 集群信息 | 命令 |
|---|---|
| 3分片2副本集群 | shards3_replications2 |
| 对外端口 | 8124 |
| 客户端入口 | clickhouse-client --port 9004 -m |
| ck集群启停 | 需要指定配置文件 |
| 后台启动 | nohup clickhouse-server --config-file=/etc/clickhouse-server/config01.xml >null 2>&1 & ,nohup clickhouse-server --config-file=/etc/clickhouse-server/config02.xml >null 2>&1 & (3台节点) |
| 停止:ps -ef | grep clickhouse 查看进程 kill -9 杀死 |
5. clickhouse客户端常用参数
| 客户端参数 | 含义 |
|---|---|
| -h -host | 指定服务器主机 |
| –port | 指定端口,默认值:9000 |
| -u -user | 指定用户,默认:default |
| –password 密码 | 默认:空字符串 |
| -d -database | 指定操作的数据库,默认:default |
| -q -query | 非交互式下的查询语句 |
| -m -multiline | 允许多行的居于查询 |
| -f -format | 使用指定的默认格式输出结果 |
| -t -time | 非交互式下会打印查询执行的时间窗口 |
| -stacktrace | 如果出现异常,会打印堆栈跟踪信息 |
| -config-file | 配置文件的名称 |
6. clickhouse CPU内存优化配置
参数示例:
config.xml
<max_concurrent_queries>200</max_concurrent_queries>
<max_table_size_to_drop>0</max_table_size_to_drop>
users.xml
<background_pool_size>128</background_pool_size>
<max_memory_usage>100000000000</max_memory_usage>
<max_bytes_before_external_group_by>50000000000</max_bytes_before_external_group_by>
<max_bytes_before_external_sort>80000000000</max_bytes_before_external_sort>
<background_schedule_pool_size>128</background_schedule_pool_size>
<background_distributed_schedule_pool_size>128</background_distributed_schedule_pool_size>
参数含义:
<background_pool_size>128</background_pool_size>
此参数在 users.xml中,用于设置后台线程池的大小, merge 线程就是在该线程池中执行,该线程池不仅仅是给 merge 线程用的,默认值 16,允许的前提下建议改成 cpu 个数的 2倍(线程数)。
<background_schedule_pool_size>128</background_schedule_pool_size>
此参数在 users.xml中,用于设置执行后台任务(复制表、 Kafka 流、DNS 缓存更新)的线程数。 默认 128,建议改成 cpu 个数的 2 倍(线程数)。
<background_distributed_schedule_pool_size>128</background_distributed_schedule_pool_size>
此参数在 users.xml中,用于设置分布式发送执行后台任务的线程数,默认 16,建议改成 cpu个数的 2 倍(线程数)。
<max_memory_usage>100000000000</max_memory_usage>
此参数在 users.xml中,表示单次 Query 占用内存最大值,该值可以设置的比较大,这样可以提升集群查询的上限。保留一点给 OS,比如 128G内存的机器,设置为 100GB。
<max_bytes_before_external_group_by>50000000000</max_bytes_before_external_group_by>
此参数在 users.xml中,一般按照 max_memory_usage 的一半设置内存,当 group 使用内存超过阈值后会刷新到磁盘进行。因为 clickhouse 聚合分两个阶段:查询并及建立中间数据、合并中间数据,结合上一项,建议 50GB。注意变量是字节
<max_bytes_before_external_sort>80000000000</max_bytes_before_external_sort>
此参数在 users.xml中,当 order by 已使用 max_bytes_before_external_sort 内存就进行溢写磁盘(基于磁盘排序),如果不设置该值,那么当内存不够时直接抛错,设置了该值 order by 可以正常完成,但是速度相对存内存来说肯定要慢点(实测慢的非常多,但比报错好)。
<max_concurrent_queries>200</max_concurrent_queries>
此参数在 config.xml中,用于设置最大并发处理的请求数 (包含 select,insert 等),默认值 100,推荐 200(不够再加)~300。
<max_table_size_to_drop>0</max_table_size_to_drop>
此参数在 config.xml 中,应用于需要删除表或分区的情况,默认是50GB,意思是如果删除 50GB 以上的分区表会失败。建议修改为 0,这样不管多大的分区表都可以删除。
7. 用户密码配置
users.xml中在user下添加agg用户,密码为123
<agg>
<password>123</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</agg>
config.xml,比如要把shards3_replications2集群的权限给agg用户那么就需要在集群信息中配置用户密码,如下。
<shards3_replications2>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton1</host>
<port>9003</port>
<user>agg</user>
<password>123</password>
</replica>
<replica>
<host>foton2</host>
<port>9004</port>
<user>agg</user>
<password>123</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton2</host>
<port>9003</port>
<user>agg</user>
<password>123</password>
</replica>
<replica>
<host>foton3</host>
<port>9004</port>
<user>agg</user>
<password>123</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<weight>1</weight>
<replica>
<host>foton3</host>
<port>9003</port>
<user>agg</user>
<password>123</password>
</replica>
<replica>
<host>foton1</host>
<port>9004</port>
<user>agg</user>
<password>123</password>
</replica>
</shard>
</shards3_replications2>