一、背景
二月底的时候,提到一个文档中心的链接有效性问题,文档中心的某个超链接跳转后,页面内容是空的或者提示页面内容不存在。
分析一下可知,其实文档中心的每个页面都有很多不定位置、不定数量的超链接,每个超链接的页面又包含很多超链接,无限下钻的结果就会有很很多的链接。
这种数量庞大、位置不定的链接,人工测试,其实没办法覆盖全,点着点着就不知道自己在那里了,点击过那个页面了?点击过那个链接了?目前的测试,应该就是几个主要页面点一下,没问题就算通过了。
所以,需要一个工具可以将整个文档中心的链接爬取下来、去重、请求、存储、分析,找出那部分访问后页面是空的或者提示页面内容不存在的链接和该链接对应的父链接和文案,通过父链接和父链接的页面找到失效链接的文案,就能定位到失效链接。
二、工具特点和优势
互联网上搜索一下死链接工具巡查,其实有很多,但是真正能应用到项目中的,几乎没有,至少个人是没见过,或者有些需要付费的。因为实际项目中会更加复杂,比如:
1.首先提供一个站点的初始URL,站点的其它页面内容是需要登录后有权限才能获取的,而大部分死链接检查工具只能检查一些简单的URL,如 baidu.com。而 DeadLinkHunter工具可以通过添加cookie解决这个问题。
2.最核心的问题是,如何从初始URL站点跟踪获取全部链接。比较牛的大佬,可能自己用算法手撸一个,但需要保证获取整个站点所有链接的覆盖率和准确性,其实难度很大,当然,我不会[捂脸]。另外有些死链接巡查工具只能爬取一页或几页。而创建scrapy框架的大牛也考虑到了这个问题,而且,开源出来给我们用,就是scrapy框架的CrawlSpider类。DeadLinkHunter工具就是使用了scrapy框架的CrawlSpider类,从一个初始的URL,自动发现链接并跟踪它们,从而方便地爬取整个网站。(CrawlSpider的作者和Scrapy框架的作者是同一个人,他的名字是Pablo Hoffman)
3.现在互联网的前端页面,99%都使用了Ajax异步加载,使用Ajax异步加载的页面,直接请求url的返回是获取不到页面全部源码的,目前没有见过那个死链接检查工具是可以获取动态页面的源码的,包括scrapy框架,也是获取不到Ajax异步加载的页面的源码。所以,DeadLinkHunter工具才需要在scrapy中自定义selenium中间件去访问URL来获取源码,可以解决这个问题。
(tips:ajax异步加载指通过XMLHttpRequest对象向服务端发送请求,获取服务端返回的数据,然后通过JavaScript动态地将这些数据插入到当前页面中,而不需要重新刷新整个页面。这样可以避免页面的闪烁、卡顿等不良的用户体验,并且可以减少网络带宽的消耗,提高页面加载速度和性能)
4.发现一个失效链接后,如果想要修改怎么办,就需要知道这个链接是从那个页面的那个文案跳转的。我了解过的死链接巡检工具都没有这个功能的,功能强大些的可能就会把失效的链接返回给你,但是失效的链接是在那个页面那个文案点击跳转的是没有的,那就无法定位失效链接进行修复。DeadLinkHunter工具中截取了部分CrawlSpider源码进行重写,实现了这个功能,获取的每个链接都关联父链接、父链接文案,一起存储到db。(详细实现逻辑:CrawlSpider【获取当前访问链接的父链接和锚文本】代码逻辑)
5.DeadLinkHunter工具支持多个环境执行,把环境配置的相关信息存储到redis,在redis修改要执行的环境变量,就可以实现兼容跑多套不同的环境,和代码完全隔离;爬取的数据也存储到redis,redis基于内存,读写都会更快。
三、工具工作原理
1.使用的技术
py + scrapy + CrawlSpider + selenium + redis + pytest + allure + jenkins
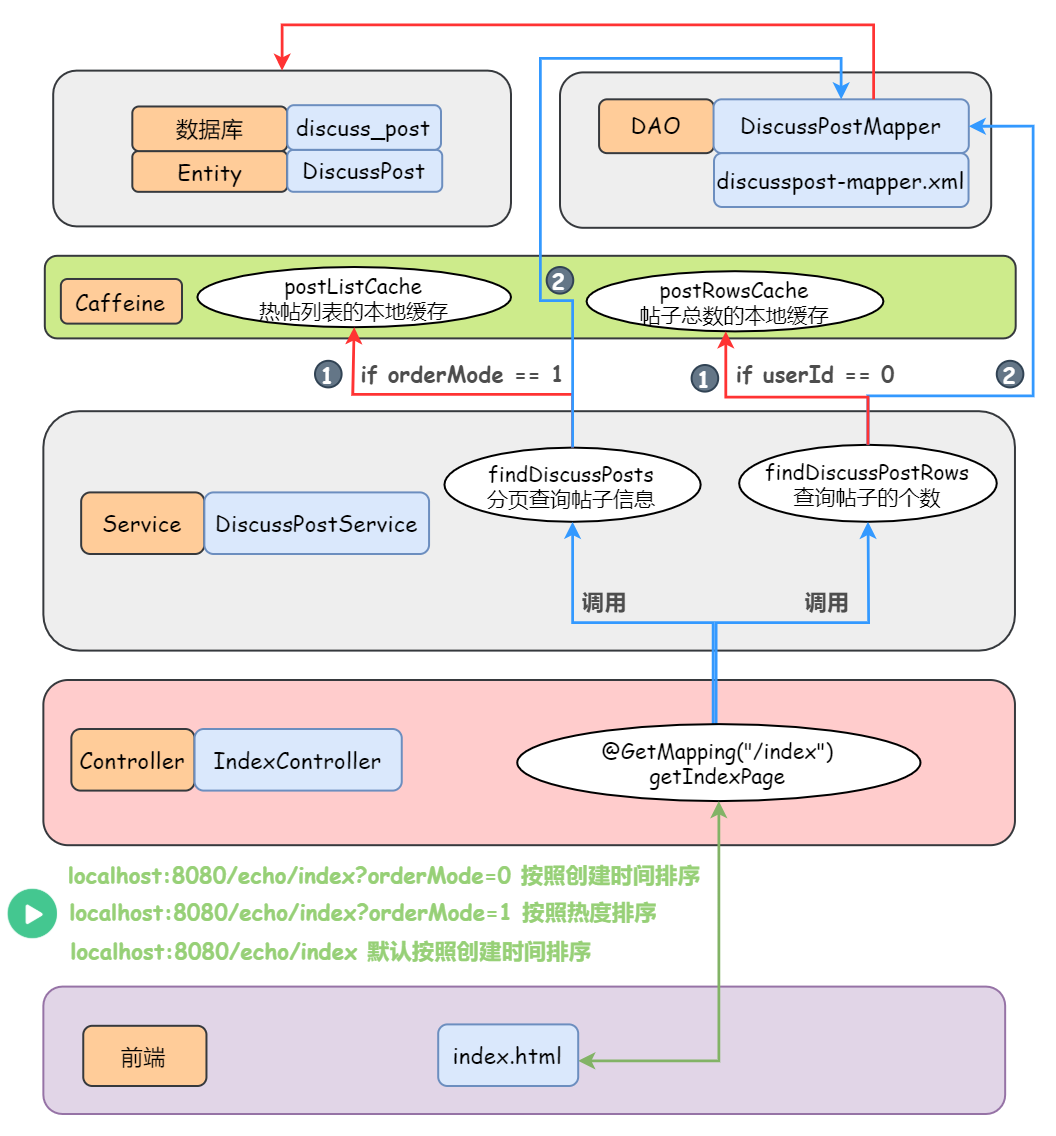
2.架构图

架构图解析:
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。例如:本工具增加自定义selenium组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。
简单点来说,架构图中,scrapy框架实现了如:请求、调度、去重、下载、响应....等功能,其中CrawlSpider(Scrapy框架中的一个子类,它继承了Scrapy.Spider类)是本工具实现的核心,与普通的Spider不同,CrawlSpider能够自动发现链接并跟踪它们,从而方便地爬取整个网站。另外,CrawlSpider还支持基于规则的过滤和提取数据(如何解析页面和如何使用XPath或CSS选择器来提取数据),这使得我们可以更加灵活地控制爬取的数据。(具体了解可以访问scrapy官网文档:Scrapy 2.11 documentation — Scrapy 2.11.0 documentation)
3.编写代码逻辑的节点
而架构图中,另外需要程序员编写代码逻辑的节点是:
Spider(程序)&CrawlSpider
- 定义巡查的站点的初始链接
- 配置CrawlSpider的发现链接并爬取规则
- 定义页面内容来判断页面是否存在和是否为死链接的
- 获取跳转到爬取到的链接的父链接 referer_url 和 父链接的文案 referer_url_text,详情:CrawlSpider【获取当前访问链接的父链接和锚文本】代码逻辑
1~3的知识都是CrawSpider的内容,就不赘述了,4是个人想法实现的。
Selenium 中间件
- 为了避免selenium的driver驱动、浏览器版本各种更新导致失败,就在ks上面起了一个docker部署的selenium,通过remote-selenium来访问scrapy的链接获取链接的源码。
- 使用selenium过程遇到一些问题,已解决具体可以看:【重启ks容器自动化】
- 然后在scrapy框架的middlewares.py文件的中间件类,添加selenium相关的代码。
将数据写入Redis
- 在scrapy框架自带的pipelines.py添加redis的写入逻辑即可,这个也是scrapy框架和py-redis的内容,就不赘述了。
- 在pipelines里面获取scrapy爬虫结束后的统计信息,详情:【scrapy pipelines】
Pytest&Allure进行断言输出结果报告
- 获取链接的数据写入reids后,需要进行分析,哪些链接是失效链接,个人使用了pytest进行断言,allure进行报告展示,详情:【Pytest&Allure分析Redis的数据并动态生成testCase报告】
四、使用步骤和实际成果
使用步骤:
- 连接redis终端,参考已经有的配置,进行添加、修改相关配置信息:


- 在Jenkins点击后,巡查开始....

注:为了DeadLinkHunter工具更加灵活通用,Jenkins没有绑定任何配置信息,只是利用Jenkins的定时运行、报告在线展示。
把DeadLinkHunter工具的配置全部剥离放在redis,因为DeadLinkHunter工具获取到的数据是存到redis,那么只需要在redis同时配置好环境信息,就可以跑起来了,不需要强耦合Jenkins才能用。
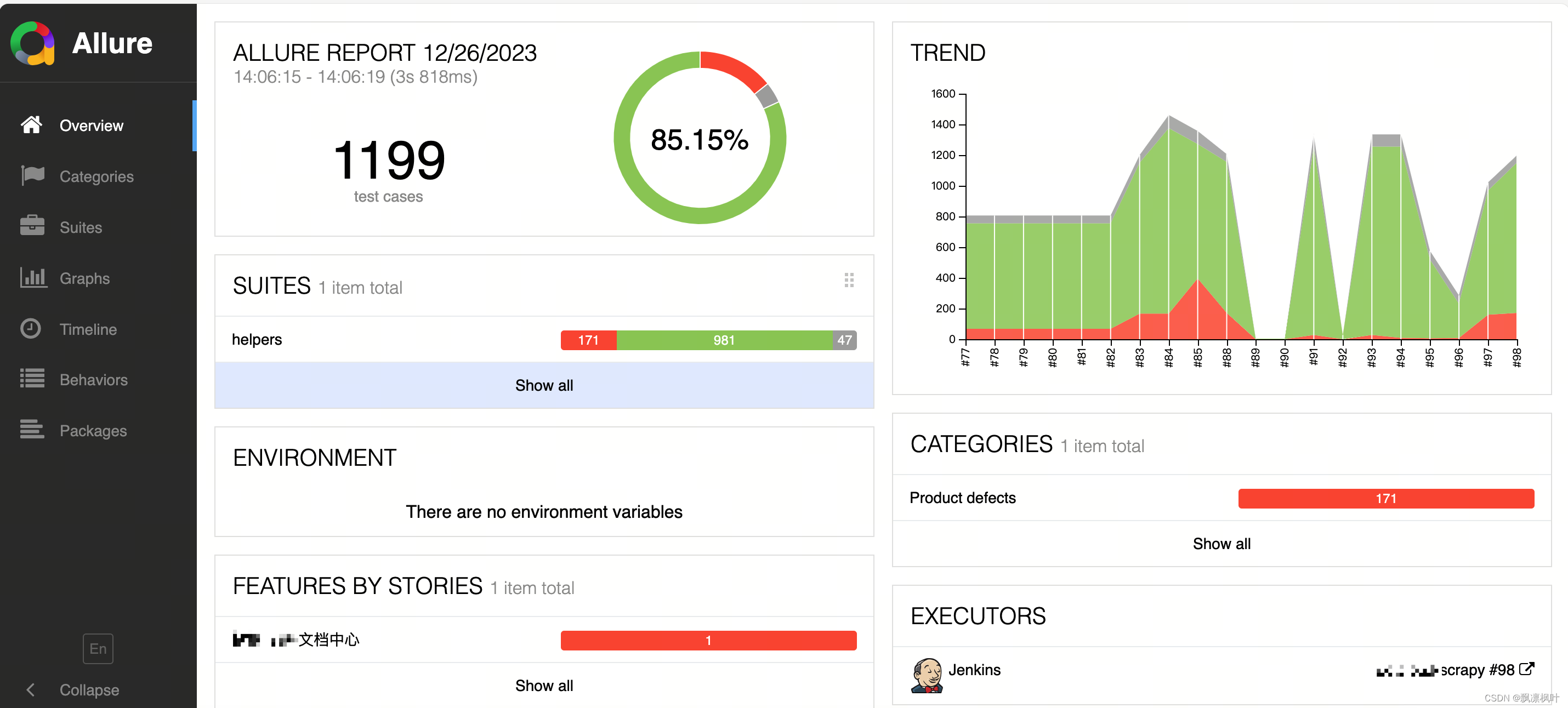
最终效果:
报告链接:http://jenkins.iot-qa.org.com/view/org-scrapy/job/org-scrapy/35/allure/#


五、工具的局限性
DeadLinkHunter工具使用 Scrapy 和 Selenium 获取动态源码的方法,目前来看,是准确性最高的方法。但由于 Selenium 是通过浏览器驱动实现的,因此也有一些局限性:
Selenium 是基于浏览器自动化测试的技术,因此其性能和效率较差,相对于 Scrapy 自带的 HTTP 请求库来说,Selenium 的处理速度更加缓慢,无法满足高并发请求的需求。同时,使用 Selenium 还需要启动浏览器进行页面渲染,也会导致内存占用和 CPU 使用率的增加。
所以,文档中心巡查一次大概700多个页面,时间都会超过一小时。
六、相关资源
gitlab地址:git@gitlab.org.com:name/org-scrapy.git
Jenkins地址:http://jenkins.****.com/view/org-scrapy/job/org-scrapy/