On Bringing Robots Home
关于引入机器人到家庭
文章目录
- On Bringing Robots Home
- 关于引入机器人到家庭
- 1 Introduction
- 1 引言
- 2 Technical Components and Method
- 2 技术组件与方法
- 2.1 Hardware Design
- 2.1 硬件设计
- 2.2 Pretraining Dataset – Homes of New York
- 2.2 预训练数据集 – 纽约家庭
- 2.3 Policy Learning with Home Pretrained Representations
- 2.3 使用家庭预训练表示进行策略学习
- 2.4 Deployment in Homes
- 2.4 在家中部署
- 3 Experiments
- 3 实验
- 3.1 List of Tasks in Homes
- 3.1 家庭任务列表
- 3.2 Understanding the Performance of Dobb·E
- 3.2 理解Dobb·E的性能
- 3.3 Failure Modes and Analysis
- 3.3 失败模式与分析
- 3.4 Ablations
- 3.4 消融实验
- 4 Open Problems and Request for Research
- 4 开放问题与研究请求
- 4.1 Scaling to Long Horizon Tasks
- 4.1 长时程任务的扩展
- 4.2 Incorporating Memory
- 4.2 整合记忆
- 4.3 Improving Sensors and Sensory Representations
- 4.3 改进传感器和感知表示
- 4.4 Robustifying Robot Hardware
- 4.4 加强机器人硬件的稳健性
- 5 Reproducibility and Call for Collaboration
- 5 可复现性和合作呼吁
- Acknowledgments
- 致谢
Throughout history, we have successfully integrated various machines into our homes. Dishwashers, laundry machines, stand mixers, and robot vacuums are just a few recent examples. However, these machines excel at performing only a single task effectively. The concept of a “generalist machine” in homes – a domestic assistant that can adapt and learn from our needs, all while remaining cost-effective – has long been a goal in robotics that has been steadily pursued for decades. In this work, we initiate a large-scale effort towards this goal by introducing Dobb·E, an affordable yet versatile general-purpose system for learning robotic manipulation within household settings. Dobb·E can learn a new task with only five minutes of a user showing it how to do it, thanks to a demonstration collection tool (“The Stick”) we built out of cheap parts and iPhones. We use the Stick to collect 13 hours of data in 22 homes of New York City, and train Home Pretrained Representations (HPR). Then, in a novel home environment, with five minutes of demonstrations and fifteen minutes of adapting the HPR model, we show that Dobb·E can reliably solve the task on the Stretch, a mobile robot readily available on the market. Across roughly 30 days of experimentation in homes of New York City and surrounding areas, we test our system in 10 homes, with a total of 109 tasks in different environments, and finally achieve a success rate of 81%. Beyond success percentages, our experiments reveal a plethora of unique challenges absent or ignored in lab robotics. These range from effects of strong shadows to variable demonstration quality by nonexpert users. With the hope of accelerating research on home robots, and eventually seeing robot butlers in every home, we open-source Dobb·E software stack and models, our data, and our hardware designs.
在历史长河中,我们成功地将各种机器整合到我们的家庭中。洗碗机、洗衣机、搅拌机和扫地机器人只是一些最近的例子。然而,这些机器擅长有效地执行单一任务。在家庭中使用“通用机器”——一个可以适应并从我们的需求中学习的家庭助手,同时保持经济实惠——一直是机器人领域长期追求的目标。在这项工作中,我们通过引入Dobb·E,一个价格实惠而多才多艺的通用系统,致力于实现这一目标。Dobb·E能够在用户向它展示如何执行任务的五分钟内学会新任务,这得益于我们用廉价零件和iPhone制作的演示采集工具(“The Stick”)。我们使用这个工具在纽约市的22个家庭中收集了13小时的数据,并训练了家庭预训练表示(HPR)。然后,在一个新颖的家庭环境中,通过五分钟的演示和十五分钟的调整HPR模型,我们展示了Dobb·E能够可靠地在市场上随时可得的移动机器人Stretch上解决任务。在纽约市及周边地区的家庭中进行了约30天的实验,我们在10个家庭中测试了我们的系统,在不同环境中完成了总计109个任务,最终取得了81%的成功率。除了成功率之外,我们的实验证明了在实验室机器人中缺乏或被忽视的一系列独特挑战。这些挑战涉及从强烈阴影的影响到非专业用户演示质量的变化。希望加速家用机器人研究,并最终看到每个家庭都有机器人管家,我们开源了Dobb·E软件栈和模型、我们的数据和硬件设计。

Figure 1: We present Dobb·E, a simple framework to train robots, which is then field tested in homes across New York City. In under 30 mins of training per task, Dobb·E achieves 81% success rates on simple household tasks.
图1:我们呈现Dobb·E,一个简单的培训机器人的框架,然后在纽约市的家庭中进行现场测试。在每项任务的培训时间不到30分钟内,Dobb·E在简单的家务任务上达到了81%的成功率。
1 Introduction
1 引言
Since our transition away from a nomadic lifestyle, homes have been a cornerstone of human existence. Technological advancements have made domestic life more comfortable, through innovations ranging from simple utilities like water heaters to advanced smart-home systems. However, a holistic, automated home assistant remains elusive, even with significant representations in popular culture [1].
自从我们放弃游牧生活以来,家庭一直是人类存在的基石。技术的进步使得家庭生活更加舒适,通过从简单的水加热器到先进的智能家居系统的创新。然而,一个全面的、自动化的家庭助手仍然难以实现,即使在流行文化中有着显著的代表 [1]。
Our goal is to build robots that perform a wide-range of simple domestic tasks across diverse realworld households. Such an effort requires a shift from the prevailing paradigm – current research in robotics is predominantly either conducted in industrial environments or in academic labs, both containing curated objects, scenes, and even lighting conditions. In fact, even for the simple task of object picking [2] or point navigation [3] performance of robotic algorithms in homes is far below the performance of their lab counterparts. If we seek to build robotic systems that can solve harder, general-purpose tasks, we will need to reevaluate many of the foundational assumptions in lab robotics.
我们的目标是构建能够在不同真实家庭中执行各种简单家务任务的机器人。这样的努力需要从当前的范式转变——当前机器人领域的研究主要在工业环境或学术实验室中进行,这两者都包含精心策划的物体、场景,甚至照明条件。实际上,即使对于简单的物体拾取 [2] 或点导航 [3] 这样的任务,机器人算法在家庭中的性能远低于实验室中的性能。如果我们希望构建能够解决更难、通用性更强的任务的机器人系统,我们将需要重新评估实验室机器人领域的许多基本假设。
In this work we present Dobb·E, a framework for teaching robots in homes by embodying three core principles: efficiency, safety, and user comfort. For efficiency, we embrace large-scale data coupled with modern machine learning tools. For safety, when presented with a new task, instead of trial-and-error learning, our robot learns from a handful of human demonstrations. For user comfort, we have developed an ergonomic demonstration collection tool, enabling us to gather task-specific demonstrations in unfamiliar homes without direct robot operation.
在这项工作中,我们介绍了Dobb·E,一个在家中教授机器人的框架,体现了三个核心原则:效率、安全和用户舒适。为了提高效率,我们采用大规模数据与现代机器学习工具相结合。为了安全,当面临新任务时,我们的机器人不是通过反复试错学习,而是通过少数人类演示进行学习。为了提高用户舒适度,我们开发了一种人体工程学的演示采集工具,使我们能够在陌生的家庭中收集特定任务的演示,而无需直接操作机器人。
Concretely, the key components of Dobb·E include:
具体而言,Dobb·E 的关键组件包括:
• Hardware: The primary interface is our demonstration collection tool, termed the “Stick.” It combines an affordable reacher-grabber with 3D printed components and an iPhone. Additionally, an iPhone mount on the robot facilitates direct data transfer from the Stick without needing domain adaptation.
• 硬件:主要接口是我们的演示采集工具,被称为“Stick”(手杖)。它结合了一个经济实惠的夹取器、3D打印的组件和一个iPhone。此外,机器人上的iPhone支架方便直接从Stick传输数据,无需进行域适应。
Pretraining Dataset: Leveraging the Stick, we amass a 13 hour dataset called Homes of New York (HoNY), comprising 5620 demonstrations from 216 environments in 22 New York homes, bolstering our system’s adaptability. This dataset serves to pretrain representation models for Dobb·E.
• 预训练数据集:利用Stick,我们积累了一个名为“Homes of New York(HoNY)”的13小时数据集,包括来自22个纽约家庭的216个环境中的5620个演示,增强了我们系统的适应性。该数据集用于为Dobb·E预训练表示模型。
Models and algorithms: Given the pretraining dataset we train a streamlined vision model, called Home Pretrained Representations (HPR), employing cutting-edge self-supervised learning (SSL) techniques. For novel tasks, a mere 24 demonstrations sufficed to finetune this vision model, incorporating both visual and depth information to account for 3D reasoning.
• 模型和算法:根据预训练数据集,我们训练了一个简化的视觉模型,称为“Home Pretrained Representations(HPR)”,采用先进的自监督学习(SSL)技术。对于新任务,仅仅通过24个演示就足以微调这个视觉模型,融合了视觉和深度信息以考虑3D推理。
Integration: Our holistic system, encapsulating hardware, models, and algorithms, is centered around a commercially available mobile robot: Hello Robot Stretch [4].
集成:我们的整体系统,包括硬件、模型和算法,围绕一款商用移动机器人展开:Hello Robot Stretch [4]。

Figure 2: (A) We design a new imitation learning framework, starting with a data collection tool. (B) Using this data collection tool, users can easily collect demonstrations for household tasks. © Using a similar setup on a robot, (D) we can transfer those demos using behavior cloning techniques to real homes.
图2:(A)我们设计了一个新的模仿学习框架,从一个数据采集工具开始。 (B)利用这个数据采集工具,用户可以轻松收集家务任务的演示。 (C)在机器人上使用类似的设置,(D)我们可以使用行为克隆技术将这些演示转移到真实的家庭中。

Figure 3: We ran experiments in a total of 10 homes near the New York City area, and successfully completed 102 out of 109 tasks that we tried. The figure shows a subset of 60 tasks, 6 tasks from 10 homes each, from our home robot experiments using Dobb·E.
图3:我们在纽约市附近的共10个家庭进行了实验,并成功完成了我们尝试的109项任务中的102项。图中展示了60个任务的子集,每个家庭中有10个任务,这些任务来自我们使用Dobb·E进行的家庭机器人实验。
We run Dobb·E across 10 homes spanning 30 days of experimentation, over which it tried 109 tasks and successfully learned 102 tasks with performance ≥ 50% and an overall success rate of 81%. Concurrently, extensive experiments run in our lab reveals the importance of many key design decisions. Our key experimental findings are:
我们在跨越30天的实验中在10个家庭中运行了Dobb·E,尝试了109项任务,并成功学习了102项任务,性能≥50%,整体成功率为81%。与此同时,我们在实验室进行的广泛实验揭示了许多关键设计决策的重要性。我们的主要实验性发现如下:
Surprising effectiveness of simple methods: Dobb·E follows a simple behavior cloning recipe for visual imitation learning using a ResNet model [5] for visual representation extraction and a two-layer neural network [6] for action prediction (see Section 2). On average, only using 91 seconds of data on each task collected over five minutes, Dobb·E can achieve a 81% success rate in homes (see Section 3).
简单方法的出乎意料的有效性:Dobb·E遵循一个简单的行为克隆配方,使用ResNet模型 [5] 进行视觉模仿学习,用于视觉表示提取,以及一个两层神经网络 [6] 进行动作预测(详见第2节)。平均而言,Dobb·E在每项任务上仅使用5分钟内收集的91秒数据,就能在家庭中达到81%的成功率(详见第3节)。
• Impact of effective SSL pretraining: Our foundational vision model, HPR trained on home data improves tasks success rate by at least 23% compared to other foundational vision models [7–9], which were trained on much larger internet datasets (see Section 3.4.1).
有效的自监督学习预训练的影响:我们的基础视觉模型HPR在家庭数据上的训练,相较于其他在更大的互联网数据集上训练的基础视觉模型 [7–9],至少提高了23%的任务成功率(详见第3.4.1节)。
Odometry, depth, and expertise: The success of Dobb·E is heavily reliant on the Stick providing highly accurate odometry and actions from the iPhones’ pose and position sensing, and depth information from the iPhone’s Lidar. Ease of collecting demonsrations also makes iterating on research problems with the Stick much faster and easier (see Section 3.4).
航迹、深度和专业知识的影响:Dobb·E的成功在很大程度上依赖于Stick提供的来自iPhone姿势和位置感测的高精度航迹和动作,以及来自iPhone激光雷达的深度信息。使用Stick收集演示的便利性还使得在Stick上迭代研究问题更加快速和容易(详见第3.4节)。
Remaining challenges: Hardware constraints such as the robot’s force, reach, and battery life, limit tasks our robot can physically solve (see Section 3.3.3), while our policy framework suffers with ambiguous sensing and more complex, temporally-extended tasks (see Sections 3.3.4, 4.1).
尚存的挑战:硬件约束,如机器人的力量、可达性和电池寿命,限制了我们的机器人可以在物理上解决的任务(详见第3.3.3节),而我们的策略框架在模糊的感知和更复杂、时间较长的任务方面存在问题(详见第3.3.4节、第4.1节)。
To encourage and support future work in home robotics, we have open-sourced our code, data, models, hardware designs, and are committed to supporting reproduction of our results. More information along with robot videos are available on our project website: https://dobb-e.com.
为了鼓励和支持未来的家庭机器人研究,我们已经开源了我们的代码、数据、模型、硬件设计,并致力于支持我们结果的再现。更多信息以及机器人视频可在我们的项目网站上找到:https://dobb-e.com。
2 Technical Components and Method
2 技术组件与方法
To create Dobb·E we partly build new robotic systems from first principles and partly integrate state-of-the-art techniques. In this section we will describe the key technical components in Dobb·E. To aid in reproduction of Dobb·E, we have open sourced all of the necessary ingredients in our work; please see Section 5 for more detail.
为了创建Dobb·E,我们部分地从头构建了新的机器人系统,部分地整合了最先进的技术。在本节中,我们将描述Dobb·E中的关键技术组件。为了方便再现Dobb·E,我们已经开源了我们工作中所有必要的组件;更多详细信息请参见第5节。
At a high level, Dobb·E is an behavior cloning framework [10]. Behavior cloning is a subclass of imitation learning, which is a machine learning approach where a model learns to perform a task by observing and imitating the actions and behaviors of humans or other expert agents. Behavior cloning involves training a model to mimic a demonstrated behavior or action, often through the use of labeled training data mapping observations to desired actions. In our approach, we pretrain a lightweight foundational vision model on a dataset of household demonstrations, and then in a new home, given a new task, we collect a handful of demonstrations and fine-tune our model to solve that task. However, there are many aspects of behavior cloning that we created from scratch or re-engineered from existing solutions to conform to our requirements of efficiency, safety, and user comfort.
在高层次上,Dobb·E是一个行为克隆框架 [10]。行为克隆是模仿学习的一个子类,是一种机器学习方法,模型通过观察和模仿人类或其他专家代理的动作和行为来执行任务。行为克隆涉及训练一个模型来模仿演示的行为或动作,通常通过使用标记的训练数据将观察映射到所需的动作。在我们的方法中,我们在家庭演示的数据集上预训练了一个轻量级的基础视觉模型,然后在一个新的家庭中,给定一个新任务,我们收集了少量演示,并微调我们的模型以解决该任务。然而,有许多行为克隆的方面是我们从头开始创建的,或者从现有解决方案中重新设计以符合我们对效率、安全性和用户舒适性的要求。
Our method can be divided into four broad stages: (a) designing a hardware setup that helps us in the collection of demonstrations and their seamless transfer to the robot embodiment, (b) collecting data using our hardware setup in diverse households, © pretraining foundational models on this data, and (d) deploying our trained models into homes.
我们的方法可以分为四个广泛的阶段:(a) 设计一个硬件设置,帮助我们收集演示并无缝地将它们传输到机器人实体,(b) 使用我们的硬件设置在不同家庭中收集数据,© 在这些数据上预训练基础模型,和 (d) 部署我们训练过的模型到家庭中。
2.1 Hardware Design
2.1 硬件设计
The first step in scaling robotic imitation to arbitrary households requires us to take a closer look at the standard imitation learning process and its inefficiencies. Two of the primary inefficiencies in current real-world imitation learning lay in the process of collecting the robotic demonstrations and transferring them across environments.
在将机器人模仿扩展到任意家庭的第一步要求我们更仔细地研究标准的模仿学习过程及其低效性。当前实际世界模仿学习中的两个主要低效性在于收集机器人演示和在环境之间传输这些演示的过程中。
Collecting robot demonstrations The standard approach to collect robot demonstrations in a robotic setup is to instrument the robot to pair it with some sort of remote controller device [11, 12], a full robotic exoskeleton [13–16], or simpler data collection tools [17–19]. Many recent works have used a video game controller or a phone [11], RGB-D cameras [20], or virtual reality device [12, 21, 22] to control the robot. Other works [23] have used two paired robots in a scene where one of the robots is physically moved by the demonstrator while the other robot is recorded by the cameras. However, such approaches are hard to scale up to households efficiently. Physically moving a robot is generally unwieldy, and for a home robotic task would require having multiple robots present at the site. Similarly, full exoskeleton based setups as shown in [13, 15, 16] are also unwieldy in a household setting. Generally, the hardware controller approach suffers from inefficiency because the human demonstrators have to map the controller input to the robot motion. Using phones or virtual reality devices are more efficient, since they can map the demonstrators’ movements directly to the robot. However, augmenting these controllers with force feedback is nearly impossible, often leading users to inadvertently apply extra force or torque on the robot. Such demonstrations frequently end up being unsafe, and the generally accepted solution to this problem is to limit the force and torque users can apply; however, this often causes the robot to diverge from the human behavior.
收集机器人演示:在机器人设置中收集机器人演示的标准方法是将机器人配置为与某种遥控器设备 [11, 12]、全身式机器人外骨骼 [13–16] 或更简单的数据采集工具 [17–19] 配对。许多最近的作品使用视频游戏控制器或手机 [11]、RGB-D摄像头 [20] 或虚拟现实设备 [12, 21, 22] 来控制机器人。其他作品 [23] 使用了一个场景中的两个配对机器人,其中一个机器人由演示者物理移动,而另一个机器人由摄像头记录。然而,这样的方法难以有效地扩展到家庭。物理移动机器人通常不便携,而对于家庭机器人任务,需要在现场准备多个机器人。类似地,像 [13, 15, 16] 中所示的基于全身外骨骼的设置在家庭环境中也不方便。通常,硬件控制器方法效率低下,因为人类演示者必须将控制器输入映射到机器人运动。使用手机或虚拟现实设备更有效,因为它们可以直接将演示者的动作映射到机器人。然而,几乎不可能使用这些控制器增加力反馈,通常导致用户无意中在机器人上施加额外的力或扭矩。这样的演示通常是不安全的,通常被接受的解决方案是限制用户可以施加的力和扭矩;然而,这通常会导致机器人偏离人类行为。
In this project, we take a different approach by trying to combine the versatility of mobile controllers with the intuitiveness of physically moving the robot. Instead of having the users move the entire robot, we created a facsimile of the Hello Robot Stretch end-effector using a cheap $25 reachergrabber stick that can be readily bought online, and augmented it ourselves with a 3D printed iPhone mount. We call this tool the “Stick,” which is a natural evolution of tools used in prior work [19, 24] (see Figure 4).
在这个项目中,我们采取了一种不同的方法,尝试将移动控制器的多功能性与物理移动机器人的直观性相结合。我们并没有让用户移动整个机器人,而是使用一根便宜的25美元的伸手器夹爪棒(reacher-grabber stick),可以在网上方便购买,制作了Hello Robot Stretch末端执行器的仿制品,并自行增加了一个3D打印的iPhone支架。我们将这个工具称为“Stick”,这是之前工作中使用的工具的自然演进 [19, 24](见图4)。
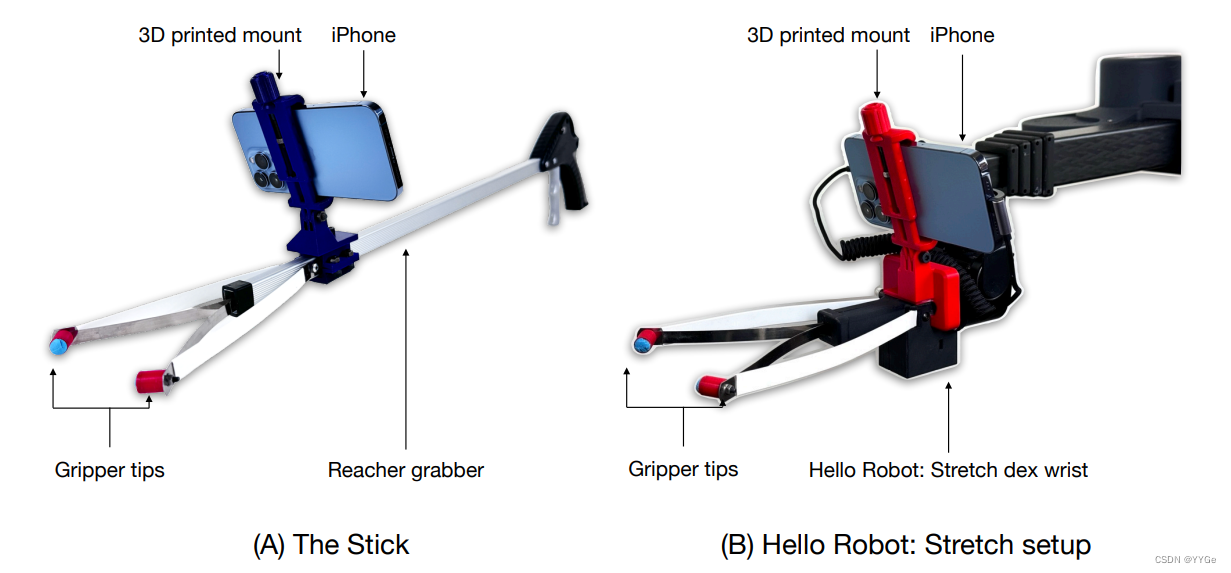
Figure 4: Photographs of our designed hardware, including the (A) Stick and the (B) identical iPhone mount for Hello Robot: Stretch wrist. From the iPhone’s point of view, the grippers look identical between the two setups.
图4:我们设计的硬件的照片,包括(A)Stick和(B)适用于Hello Robot: Stretch手腕的相同iPhone支架。从iPhone的视角来看,两个设置中的夹爪看起来是相同的。
The Stick helps the user intuitively adapt to the limitations of the robot, for example by making it difficult to apply large amounts of force. Moreover, the iPhone Pro (version 12 or newer), with its camera setup and internal gyroscope, allows the Stick to collect RGB image and depth data at 30 frames per second, and its 6D position (translation and rotation). In the rest of the paper, for brevity, we will refer to the iPhone Pro (12 or later) simply as iPhone.
Stick有助于用户直观地适应机器人的限制,例如通过使施加大量力量变得困难。此外,iPhone Pro(12版或更新),具有其摄像头设置和内置陀螺仪,允许Stick以每秒30帧收集RGB图像和深度数据,以及其6D位置(平移和旋转)。在本文的其余部分,为简洁起见,我们将iPhone Pro(12版或更新)简称为iPhone。
Captured Data Modalities Our Stick collects the demonstration data via the mounted iPhone using an off-the-shelf app called Record3D. The Record3D app is able to save the RGB data at 1280×720 pixels recorded from the camera, the depth data at 256×192 pixels from the lidar sensor, and the 6D relative translation and rotation data from the iPhone’s internal odometry and gyroscope. We record this data at 30 FPS onto the phone and later export and process it.
捕获的数据模态:我们的Stick通过安装在iPhone上使用的一款名为Record3D的现成应用程序收集演示数据。Record3D应用程序能够保存从摄像头记录的1280×720像素的RGB数据,从激光雷达传感器记录的256×192像素的深度数据,以及从iPhone的内部航迹计和陀螺仪获取的6D相对平移和旋转数据。我们以每秒30帧的速度将这些数据记录到手机上,然后导出和处理它。
Robot Platform All of our systems are deployed on the Hello Robot Stretch, which is a single-arm mobile manipulator robot already available for purchase on the open market. We use the Stretch RE1 version in all of our experiments, with the dexterous wrist attachment that confers 6D movement abilities on the robot. We chose this robot because it is cheap, lightweight–weighing just 51 pounds (23 kilograms)–and can run on a battery for up to two hours. Additionally, Stretch RE1 has an Intel NUC computer on-board which can run a learned policy at 30 Hz.
机器人平台:我们的所有系统都部署在Hello Robot Stretch上,这是一款已经在市场上可以购买的单臂移动操作机器人。在我们的所有实验中,我们使用Stretch RE1版本,配备有能使机器人具有6D运动能力的灵巧手腕附件。我们选择了这款机器人,因为它价格便宜,轻巧——只有51磅(23千克)——并且可以在电池上运行长达两小时。此外,Stretch RE1上配有一个Intel NUC计算机,可以以30 Hz的速度运行学习的策略。
Camera Mounts We create and use matching mounts on the Stick and the Hello Robot arm to mount our iPhone, which serves as the camera and the sensor in both cases. One of the main advantages of collecting our data using this setup is that, from the camera’s point of view, the Stick gripper and the robot gripper looks identical, and thus the collected data and any trained representations and policies on such data can be directly transferred from the Stick to the robot. Moreover, since our setup operates with only one robot mounted camera, we don’t have to worry about having and calibrating a third-person, environment mounted camera, which makes our setup robust to general camera calibration issues and mounting-related environmental changes.
摄像机支架:我们在Stick和Hello Robot手臂上创建并使用匹配的支架,用于安装我们的iPhone,它在两种情况下都充当摄像机和传感器。使用这种设置收集我们的数据的一个主要优势是,从摄像机的角度来看,Stick的夹爪和机器人的夹爪看起来是相同的,因此可以直接将从Stick到机器人的数据以及任何在这些数据上训练的表示和策略直接传输。此外,由于我们的设置仅使用一个机器人安装的摄像机,我们无需担心拥有和校准第三方环境安装的摄像机,这使得我们的设置对一般摄像机校准问题和与安装相关的环境变化更加健壮。
Gripper Tips As a minor modification to the standard reacher-grabber as well as the Hello Robot Stretch end-effector, we replace the padded, suction-cup style tips of the grippers with small, cylindrical tips. This replacement helps our system manipulate finer objects, such as door and drawer handles, without getting stuck or blocked. In some preliminary experiments, we find that our cylindrical tips are better at such manipulations, albeit making pick-and-place like tasks slightly harder.
夹持器尖:作为对标准伸手器夹持器和Hello Robot Stretch末端执行器的轻微修改,我们用小的圆柱形尖端替换了夹持器的软垫吸盘式尖端。这种替换有助于我们的系统操作更细小的对象,如门把手和抽屉把手,而不会被卡住或阻塞。在一些初步实验中,我们发现我们的圆柱形尖端在这样的操作中更好,尽管使得类似拾取和放置的任务稍微更难一些。
2.2 Pretraining Dataset – Homes of New York
2.2 预训练数据集 – 纽约家庭
With our hardware setup, collecting demonstrations for various household tasks becomes as simple as bringing the Stick home, attaching an iPhone to it, and doing whatever the demonstrator wants to do while recording with the Record3D app. To understand the effectiveness of the Stick as a data collection tool and give us a launching pad for our large-scale learning approach, we, with the help of some volunteers, collected a household tasks dataset that we call Homes of New York (HoNY).
有了我们的硬件设置,收集各种家务任务的演示变得非常简单,只需把Stick带回家,将iPhone连接到Stick上,然后在使用Record3D应用程序录制时做演示者想做的任何事情。为了了解Stick作为数据收集工具的有效性,并为我们的大规模学习方法提供一个起点,我们在一些志愿者的帮助下收集了一个名为纽约家庭(Homes of New York,简称HoNY)的家务任务数据集。

Figure 5: Subsample of 45 frames from Homes of New York dataset, collected using our Stick in 22 homes.
图5:来自纽约家庭数据集的45帧子样本,使用我们的Stick在22个家庭中收集。
The HoNY dataset is collected with the help of volunteers across 22 different homes, and it contains 5620 demonstrations in 13 hours of total recording time and totalling almost 1.5 million frames. We asked the volunteers to focus on eight total defined broad classes of tasks: switching button, door opening, door closing, drawer opening, drawer closing, pick and place, handle grasping, and play data. For the play data, we asked the volunteers to collect data from doing anything arbitrary around their household that they would like to do using the stick. Such playful behavior has in the past proven promising for representation learning purposes [21, 24].
HoNY数据集是在22个不同家庭中的志愿者的帮助下收集的,它包含5620个演示,在总共13小时的录制时间中,总共约150万帧。我们要求志愿者专注于八个总体定义的任务类别:开关按钮、开门、关门、打开抽屉、关闭抽屉、拾取和放置、握把、以及游戏数据。对于游戏数据,我们要求志愿者使用Stick在他们的家里做任何他们想用Stick做的事情来收集数据。过去这种轻松自由的行为对于表示学习目的已被证明是有希望的 [21, 24]。
We instructed our volunteers to spend roughly 10 minutes to collect demonstrations in each “environment” or scene in their household. However, we did not impose any limits on how many different tasks they can collect in each home, nor how different each “environment” needs to be across tasks. Our initial demonstration tasks were chosen to be diverse and moderately challenging while still being possible for the robot.
我们要求志愿者在他们的家中的每个“环境”或场景中花费大约10分钟来收集演示。但是,我们没有规定他们可以在每个家庭中收集多少不同的任务,以及在不同任务之间每个“环境”需要有多大的不同。我们最初选择的演示任务是多样且适度具有挑战性的,同时对于机器人而言仍然是可能的。
In Figure 6, we can see a breakdown of the dataset by the number of frames belonging to each broad class of tasks. As we can see, while there is some imbalance between the number of frames in each task, they are approximately balanced.
在图6中,我们可以看到按任务类别划分的数据集的帧数。正如我们所看到的,虽然每个任务的帧数之间存在一些不平衡,但它们大致上是平衡的。
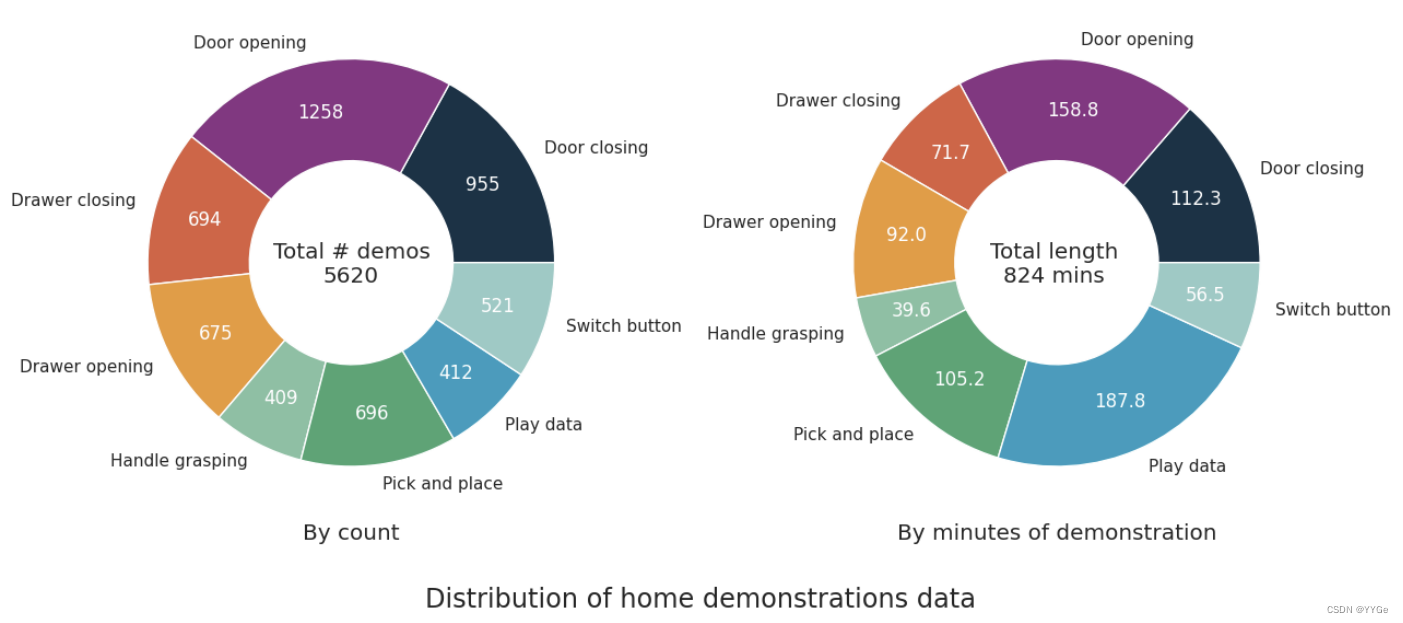
Figure 6: Breakdown of Homes of New York dataset by task: on the left, the statistics is shown by number of demonstrations, and on the right, the breakdown is shown by minutes of demonstration data collected.
Figure 6: 纽约家庭数据集按任务的分解:左边是按演示数量显示的统计数据,右边是按收集的演示数据的分钟数显示的分解。
Moreover, our dataset contains a mixture of a diverse number of homes, as shown in Figure 7, with each home containing 67K frames and 255 trajectories on average.
此外,我们的数据集包含了多个不同家庭的混合,如图7所示,每个家庭平均包含67K帧和255个轨迹。
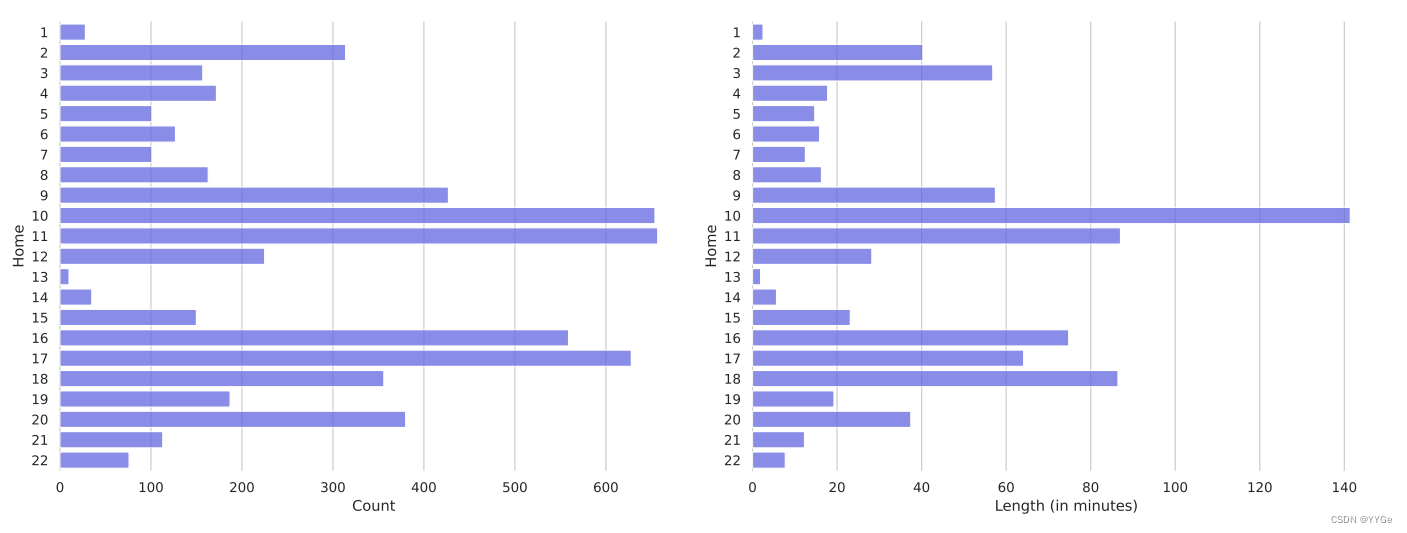
Figure 7: Breakdown of our collected dataset by homes. On the left, the statistics are shown by number of demonstrations, and on the right, the breakdown is shown by minutes of demonstration data collected. The Y-axis is marked with the home ID.
Figure 7: 我们收集的数据集按房屋分解。左边是按演示数量显示的统计数据,右边是按收集的演示数据的分钟数显示的分解。Y轴上标有房屋ID。
Gripper Data While the iPhone can give us the pose of the end-effector, there is no way to trivially get the open or closed status of the gripper itself. To address this, we trained a model to track the gripper tips. We extracted 500 random frames from the dataset and marked the two gripper tip positions in pixel coordinates on those frames. We trained a gripper model on that dataset, which is a 3-layer ConvNet that tries to predict the distance between the gripper tips as a normalized number between 0 and 1. This model, which gets a 0.035 MSE validation error (on a scale from 0-1) on a heldout evaluation set, is then used to label the rest of the frames in the dataset with a gripper value between 0 and 1.
夹持器数据:虽然iPhone可以提供末端执行器的姿势,但不能轻松获取夹持器本身的开启或关闭状态。为了解决这个问题,我们训练了一个模型来跟踪夹持器尖端。我们从数据集中提取了500个随机帧,并在这些帧上用像素坐标标记了两个夹持器尖端的位置。我们在该数据集上训练了一个夹持器模型,这是一个三层卷积神经网络,试图预测夹持器尖端之间的距离,其标准化为0到1之间的数字。该模型在一个保留评估集上获得了0.035的均方误差(在0-1的范围内)。然后,我们使用该模型将数据集中的其余帧标记为0到1之间的夹持器值。
Dataset Format As mentioned in the previous section, we collect the RGB and depth data from the demonstration, as well as the 6D motion of the stick, at 30 Hz. For use in our models, we scale and reshape our images and depths into 256×256 pixels. For the actions, we store the absolute 6D poses of the iPhone at 30 Hz. During model training or fine-tuning, we calculate the relative pose change as the action at the desired frequency during runtime.
数据集格式:如前一节所述,我们以每秒30帧的频率从演示中收集RGB和深度数据,以及Stick的6D运动。为了在我们的模型中使用,我们将图像和深度进行缩放和重新整形为256×256像素。对于动作,我们以每秒30帧的速度存储iPhone的绝对6D姿势。在模型训练或微调期间,我们计算运行时的相对姿势变化作为动作,其频率为所需频率。
Dataset Quality Control We manually reviewed the videos in the dataset to validate them and filter them for any bad demonstrations, noisy actions, and any identifying or personal information. We filtered out any videos that were recorded in the wrong orientation, as well as any videos that had anyone’s face or fingers appearing in them.
数据集质量控制:我们手动审查了数据集中的视频,以验证它们的有效性并过滤掉任何不良演示、嘈杂动作以及任何识别或个人信息。我们筛除了以错误方向录制的任何视频,以及在其中出现任何人脸或手指的视频。
Related Work Collecting large robotic manipulation datasets is new. Especially in recent years, there have been a few significant advances in collecting large datasets for robotics [2, 25–29, 29–52]. While our dataset is not as large as the largest of them, it is is unique in a few different ways. Primarily, our dataset is focused on household interactions, containing 22 households, while most datasets previously were collected in laboratory settings. Secondly, we collect first-person robotic interactions, and are thus inherently more robust to camera calibration issues which affect previous datasets [11, 26, 47, 53–55]. Thirdly, using an iPhone gives us an advantage over previous work that used cheap handheld tools to collect data [17–19] since we can extract high quality action information quite effortlessly using the onboard gyroscope. Moreover, we collect and release high quality depth information from our iPhone, which is generally rare for standard robotic datasets. The primary reason behind collecting our own dataset instead of using any previous dataset is because we believe in-domain pretraining to be a key ingredient for generalizable representations, which we empirically verify in section 3.4.1 by comparing with previously released general-purpose robotic manipulation focused representation models. A line of work that may aid in future versions of this work are collections of first-person non-robot household videos, such as [56–58], where they can complement our dataset by augmenting it with off-domain information.
相关工作:收集大规模的机器人操纵数据集是一项新工作。特别是近年来,对机器人学领域的大型数据集进行了一些重大的进展 [2, 25–29, 29–52]。虽然我们的数据集不如其中最大的数据集那么大,但它在几个方面是独一无二的。首先,我们的数据集侧重于家庭互动,包含22个家庭,而以前的大多数数据集是在实验室环境中收集的。其次,我们收集了第一人称的机器人互动,因此对于影响以前数据集的摄像机校准问题具有内在的鲁棒性 [11, 26, 47, 53–55]。第三,使用iPhone使我们比以前使用廉价手持工具收集数据的工作 [17–19] 具有优势,因为我们可以使用内置的陀螺仪轻松提取高质量的动作信息。此外,我们从iPhone中收集并发布了高质量的深度信息,这在标准机器人数据集中通常是罕见的。我们之所以收集自己的数据集而不使用以前的任何数据集,是因为我们认为在域内预训练是可广泛使用的表示学习的关键要素,我们通过与先前发布的面向通用机器人操纵的表示模型进行比较,在第3.4.1节中通过经验验证这一点。这项工作未来版本可能有助于的一个方向是收集第一人称非机器人家庭视频,例如 [56–58],在那里它们可以通过在域外信息的补充来增强我们的数据集。
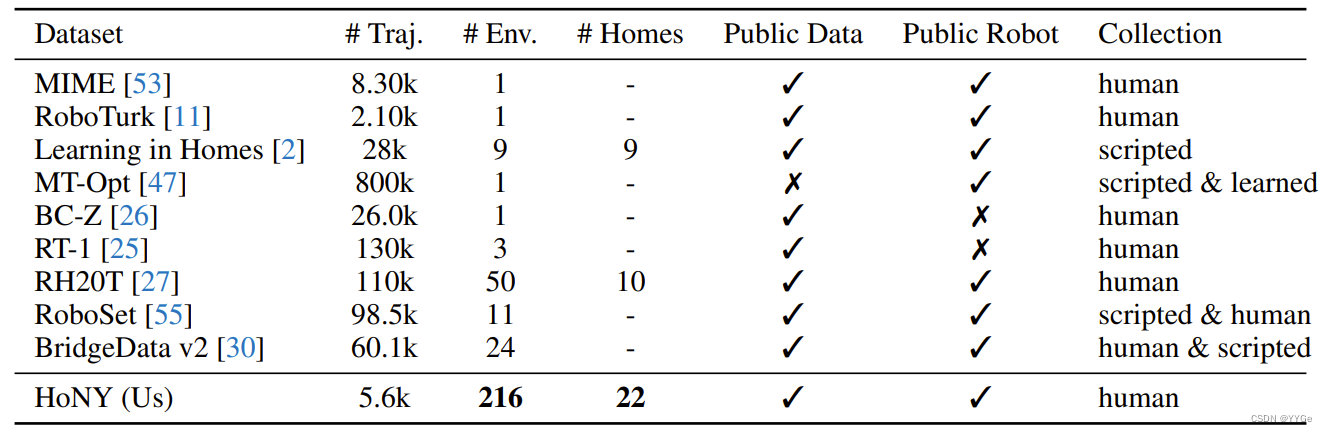
Table 1: While previous datasets focused on the number of manipulation trajectories, we instead focus on diverse scenes and environments. As a result, we end up with a dataset that is much richer in interaction diversity.
表1:尽管以前的数据集侧重于操作轨迹的数量,但我们专注于多样化的场景和环境。因此,我们得到了一个在交互多样性方面更为丰富的数据集。
2.3 Policy Learning with Home Pretrained Representations
2.3 使用家庭预训练表示进行策略学习
With the diverse home dataset, our next step in the process is to train a foundational visual imitation model that we can easily modify and deploy in homes. To keep our search space small, in this work we only consider simple visual imitation learning algorithms that only consider a single step at a time. While this inevitably limits the capabilities of our system, we leave temporally extended policies as a future direction we want to explore on home robots. Our policy is built of two simple components: a visual encoder and a policy head.
拥有多样化的家庭数据集后,我们在流程中的下一步是训练一个基础的视觉模仿模型,我们可以轻松修改并在家庭中部署。为了保持搜索空间的小型化,在这项工作中,我们仅考虑简单的视觉模仿学习算法,每次仅考虑单个步骤。虽然这不可避免地限制了系统的能力,但我们将时态扩展的策略作为我们希望在家庭机器人上探索的未来方向。我们的策略由两个简单的组件构建:视觉编码器和策略头。
Visual Encoder Learning We use a ResNet34 architecture as a base for our primary visual encoder. While there are other novel architectures that were developed since ResNet34, it satisfies our need for being performant while also being small enough to run on the robot’s onboard computer. We pretrain our visual encoder on our collected dataset with the MoCo-v3 self-supervised learning algorithm for 60 epochs. We call this model the Home Pretrained Representation (HPR) model, based on which all of our deployed policies are trained. We compare the effects of using our own visual encoder vs. a pretrained visual encoder trained on different datasets and algorithms, such as R3M [8], VC1 [9], and MVP [7], or even only pretraining on ImageNet-1K [59], in Section 3.4.1.
视觉编码器学习:我们使用ResNet34架构作为主要视觉编码器的基础。虽然自ResNet34以来已经开发了其他新颖的架构,但它满足我们的性能需求,同时足够小以在机器人的板载计算机上运行。我们使用MoCo-v3自监督学习算法在我们收集的数据集上为视觉编码器进行60个时期的预训练。我们将这个模型称为家庭预训练表示(HPR)模型,所有我们部署的策略都基于这个模型进行训练。我们在第3.4.1节中比较了使用我们自己的视觉编码器与在不同数据集和算法上训练的预训练视觉编码器的效果,例如R3M [8]、VC1 [9]、MVP [7],甚至只是在ImageNet-1K [59]上进行预训练。
Downstream Policy Learning On every new task, we learn a simple manipulation policy based on our visual encoder and the captured depth values. For the policy, the input space is an RGB-D image (4 channels) with shape 256×256 pixels, and the output space is a 7-dimensional vector, where the first 3 dimensions are relative translations, next 3 dimensions are relative rotations (in axis angle representation), and the final dimension is a gripper value between 0 and 1. Our policy is learned to predict an action at 3.75 Hz, since that is the frequency with which we subsample our trajectories.
下游策略学习:在每个新任务上,我们基于我们的视觉编码器和捕获的深度值学习一个简单的操作策略。对于策略,输入空间是一个RGB-D图像(4个通道),形状为256×256像素,输出空间是一个7维向量,其中前3个维度是相对平移,接下来的3个维度是相对旋转(以轴角表示),最后一个维度是夹持器值在0到1之间。我们的策略被设计为以3.75 Hz的频率预测动作,因为这是我们对轨迹进行子采样的频率。
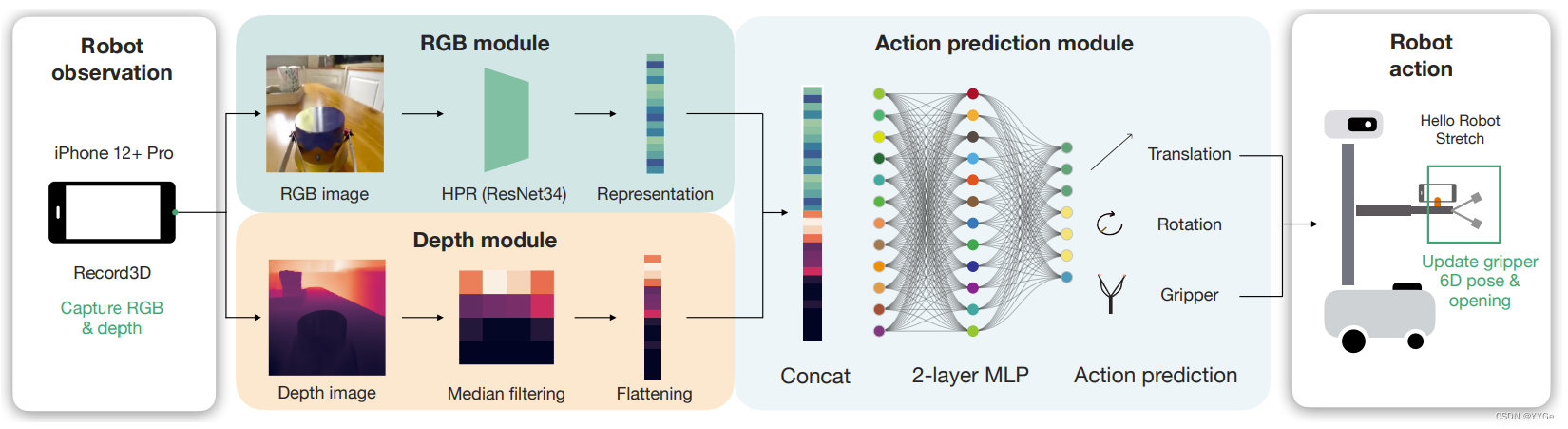
Figure 8: Fine-tuning the pretrained HPR model to learn a model that maps from the robot’s RGB and depth observations into robot actions: 6D relative pose and the gripper opening.
图8:对预训练的HPR模型进行微调,学习一个将机器人的RGB和深度观测映射到机器人动作的模型:6D相对姿势和夹持器的开启。
The policy architecture simply consists of our visual representation model applied to the RGB channels in parallel to a median-pooling applied on the depth channel, followed by two fully connected layers that project the 512 dimensional image representation and 512 dimensional depth values down to 7 dimensional actions. During this supervised training period where the network learns to map from observation to actions, we do not freeze any of the parameters, and train them for 50 epochs with a learning rate of 3×10−5 . We train our network with a mean-squared error (MSE) loss, and normalize the actions per axis to have zero mean and unit standard deviation before calculating the loss.
策略架构:策略架构简单地由我们的视觉表示模型应用于RGB通道并行于对深度通道应用的中值池化组成,然后是两个全连接层,将512维图像表示和512维深度值投影到7维动作中。在网络学习从观察到动作的映射的监督训练期间,我们不冻结任何参数,并在学习率为3×10^(-5)的情况下训练它们50个时期。我们使用均方误差(MSE)损失训练我们的网络,并在计算损失之前将每个轴的动作归一化为零均值和单位标准差。
Our pretrained visual encoders and code for training a new policy on your own data is available open-source with a permissive license. Please see Section 5 for more details.
我们的预训练视觉编码器和在自己的数据上训练新策略的代码都是开源的,并带有宽松的许可证。请参阅第5节以获取更多详细信息。
Related Work While the pretraining-finetuning framework has been quite familiar in other areas of Machine Learning such as Natural Language [60, 61] and Computer Vision [5, 62], it has not caught on in robot learning as strongly. Generally, pretraining has taken the form of either learning a visual representation [7–9, 19, 24, 63–68] or learning a Q-function [69, 70] which is then used to figure out the best behavior policy. In this work, we follow the first approach, and pretrain a visual representation that we fine-tune during deployment. While there are recent large-scale robotic policy learning approaches [25, 49, 71], the evaluation setup for such policies generally have some overlap with the (pre-)training data. This work, in contrast, focuses on entirely new households which were never seen during pretraining.
相关工作:尽管在其他机器学习领域(如自然语言处理[60, 61]和计算机视觉[5, 62])中,预训练-微调框架已经相当熟悉,但在机器人学习领域并没有像这样强烈地被接受。通常,预训练采用学习视觉表示[7–9, 19, 24, 63–68]或学习Q函数[69, 70]的形式,然后用于找出最佳行为策略。在这项工作中,我们采用了第一种方法,并对我们的视觉表示进行了预训练,然后在部署期间进行微调。虽然最近有大规模的机器人策略学习方法[25, 49, 71],但这些策略的评估设置通常与(预)训练数据有一些重叠。相比之下,这项工作专注于以前从未在预训练中看到的全新家庭。
2.4 Deployment in Homes
2.4 在家中部署
Once we have our Stick to collect data, the dataset preparation script, and the algorithm to finetune our pretrained model, the final step is to combine them and deploy them on a real robot in a home environment. In this work, we focus on solving tasks that mostly involve manipulating the environment, and thus we assume that the robot has already navigated to the task space and is starting while facing the task target (which for example could be an appliance to open or an object to manipulate).
一旦我们有了用于收集数据的Stick、准备数据集的脚本以及微调我们预训练模型的算法,最后一步就是将它们结合起来,并在家庭环境中部署它们到一个真实的机器人上。在这项工作中,我们专注于解决主要涉及操作环境的任务,因此我们假设机器人已经导航到任务空间并在面对任务目标时开始(例如可以是要打开的器具或要操作的物体)。
Protocol for Solving Home Tasks In a novel home, to solve a novel task, we start by simply collecting a handful of demonstrations on the task. We generally collect 24 new demonstrations as a rule of thumb, which our experiments show is sufficient for simple, five second tasks. In practice, collecting these demos takes us about five minutes. However, some environments take longer to reset, in which case collecting demonstrations may also take longer. To confer some spatial generalization abilities to our robot policy, we generally collect the data starting from a variety of positions in front of the task setup, generally in a small 4×6 or 5×5 grid (Figure 9)

Figure 9: (a) The data collection grid: the demonstrator generally started data collection from a 5×5 or 4×6 grid of starting positions to ensure diversity of the collected demos. (b) To ensure our policies generalize to different starting positions, we start the robot policy roll-outs from 10 pre-scheduled starting positions.
图9:(a) 数据收集网格:演示者通常从5×5或4×6的起始位置网格开始数据收集,以确保收集的演示具有多样性。 (b) 为确保我们的策略推广到不同的起始位置,我们从10个预定的起始位置开始执行机器人策略展开。
Policy Training Details Once the data is collected, it takes about 5 minutes to process the data from R3D files into our dataset format. From there, for 50 epochs of training it takes about 20 minutes on average on a modern GPU (RTX A4000). As a result, on average, within 30 minutes from the start of the data collection, we end up with a policy that we can deploy on the robot.
策略训练细节:一旦数据收集完成,将从R3D文件处理成我们的数据集格式大约需要5分钟。然后,对于50个训练周期,平均在现代GPU(RTX A4000)上需要约20分钟。因此,平均而言,从数据收集开始到结束,我们最终得到了一个可以部署到机器人上的策略,整个过程大约30分钟。
Robot Execution Details We deploy the policy on the robot by running it on the robot’s onboard Intel NUC computer. We use the iPhone mounted on the arm and the Record3D app to stream RGB-D images via USB to the robot computer. We run our policy on the input images and depth to get the predicted action. We use a PyKDL based inverse kinematics solver to execute the predicted relative action on the robot end-effector. Since the model predicts the motion in the camera frame, we added a joint in the robot’s URDF for the attached camera, and so we can directly execute the predicted action without exactly calculating the transform from the camera frame to the robot end-effector frame. For the gripper closing, we binarize the predicted gripper value by applying a threshold that can vary between tasks. We run the policy synchronously on the robot by taking in an observation, commanding the robot to execute the policy-predicted action, and waiting until robot completes the action to take in the next observation. For our evaluation experiments we generally use 10 initial starting positions for each robot task (Figure 9 (b)). These starting positions vary our robot gripper’s starting position in the vertical and horizontal directions. Between each of these 10 trials, we manually reset the robot and the environment.
机器人执行细节:我们通过在机器人的内置Intel NUC计算机上运行它来部署策略。我们使用安装在机械臂上的iPhone和Record3D应用程序通过USB向机器人计算机传送RGB-D图像。我们在输入图像和深度上运行我们的策略以获取预测的动作。我们使用基于PyKDL的逆运动学求解器在机器人末端执行预测的相对动作。由于模型预测相机框架中的运动,我们在机器人的URDF中添加了一个用于附加相机的关节,因此我们可以直接执行预测的动作,而无需精确计算从相机框架到机器人末端执行器框架的变换。对于夹爪的闭合,我们通过应用可以在任务之间变化的阈值来对预测的夹爪值进行二值化。我们同步在机器人上运行策略,通过接收观察,命令机器人执行策略预测的动作,并等待机器人完成动作以接收下一个观察。在评估实验中,我们通常对每个机器人任务使用10个初始起始位置(图9(b))。这些起始位置在垂直和水平方向上改变我们机器人夹爪的起始位置。在这10次试验之间,我们手动重置机器人和环境。
Related Work While the primary focus of our work is deploying robots in homes, we are not the first one to do so. The most popular case would be commercial robots such as Roomba [72] from iRobot or Astro [73] from Amazon. While impressive as a commercial product, such closed-source robots are not conducive to scientific inquiry and are difficult to build upon as a community. Some application of robots in home includes early works such as [74] exploring applications of predefined behaviors in homes, [75, 76] exploring tactile perception in homes, or [2] exploring the divergence between home and lab data. More recently, ObjectNav, i.e. navigating to objects in the real world [3] has been studied by taking robots to six different houses. While [3] mostly experimented on short-term rental apartments and houses, we focused on homes that are currently lived in where cluttered scenes are much more common. There have been other works such as [77, 78] which focus on “in the wild” evaluation. However, evaluation-wise, such works have been limited to labs and educational institutions [77], or have focused on literal “in the wild” setups such as cross-country navigation [78].
相关工作:尽管我们的工作的主要重点是在家中部署机器人,但我们并不是第一个这样做的。最受欢迎的情况可能是商业机器人,如iRobot的Roomba [72]或亚马逊的Astro [73]。尽管作为商业产品令人印象深刻,但这些封闭源代码的机器人不利于科学探究,并且难以作为一个社区进行进一步构建。机器人在家中的一些应用包括早期的工作,比如[74]探索在家中的预定义行为的应用,[75, 76]探索在家中的触觉感知,或[2]探索家庭和实验室数据之间的差异。最近,通过将机器人带到六个不同的房屋来研究ObjectNav,即在现实世界中导航到物体 [3]。尽管[3]主要在短期租赁公寓和房屋进行实验,我们专注于当前有人居住的房屋,其中杂乱的场景更为普遍。还有其他一些作品,如[77, 78],专注于“野外”评估。然而,从评估的角度来看,这些作品受到实验室和教育机构[77]的限制,或者专注于字面上的“野外”设置,如跨国导航[78]。
3 Experiments
3 实验
We experimentally validated our setup by evaluating it across 10 households in the New York and New Jersey area on a total of 109 tasks. On these 109 tasks, the robot gets an 81% success rate, and can complete 102 tasks with at least even odds. Alongside these household experiments, we also set up a “home” area in our lab, with a benchmark suite with 10 tasks that we use to run our baselines and ablations. Note that none of our experiments overlapped with the environments on which our HoNY dataset was collected to ensure that the experimental environments are novel.
我们通过在纽约和新泽西地区的10个家庭中评估我们的设置,对其进行了实验证实。在这109个任务中,机器人获得了81%的成功率,并且能够在至少50%的成功率下完成102个任务。除了这些家庭实验之外,我们还在实验室设置了一个“家庭”区域,其中包含一个基准套件,其中有10个任务,我们用它来运行我们的基线和消融实验。请注意,为了确保实验环境是新颖的,我们的任何实验都没有与我们的HoNY数据集收集的环境重叠。
3.1 List of Tasks in Homes
3.1 家庭任务列表
In Table 2 we provide an overview of the 109 tasks that we attempted in the 10 homes, as well as the associated success rate on those tasks. Video of all 109 tasks can also be found on our website: https://dobb-e.com/#videos.
在表2中,我们概述了我们在10个家庭中尝试的109个任务,以及这些任务的相关成功率。所有109个任务的视频也可以在我们的网站上找到:https://dobb-e.com/#videos。

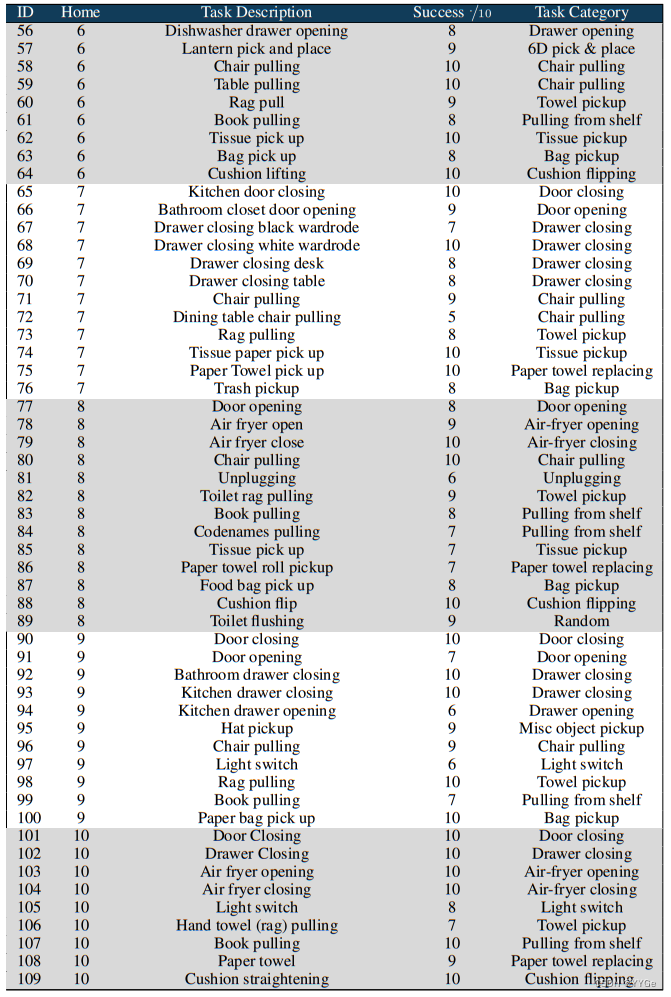
Table 2: A list of all tasks in the home enviroments, along with their categories and success rates out of 10 trials.
表2:家庭环境中所有任务的列表,以及它们的类别和在10次尝试中的成功率。

Figure 10: A small subset of 8 robot rollouts from the 109 tasks that we tried in homes. A complete set of rollout videos can also be found at our website: https://dobb-e.com/#videos
图10: 我们在家庭中尝试的109个任务中的8个机器人执行的小子集。完整的执行视频也可以在我们的网站上找到:https://dobb-e.com/#videos
3.2 Understanding the Performance of Dobb·E
3.2 理解Dobb·E的性能
On a broad level, we cluster our tasks into 20 broad categories, 19 task specific and one for the miscellaneous tasks. There are clear patterns in how easy or difficult different tasks may be, compared to each other.
在较宽泛的层面上,我们将我们的任务分成20个广泛的类别,其中有19个特定任务和一个杂项任务。与其他任务相比,不同任务之间的难易程度存在明显的模式。
Breakdown by Task Type We can see from Figure 11 that Air Fryer Closing and Cushion Flipping are the task groups with the highest average success rate (100%) while the task group with the lowest success rate is 6D pick & place (56%). We found that 6D pick and place tasks generally fail because they generally require robot motion in a variety of axes: like translations and rotations at different axes at different parts of the trajectory, and we believe more data may alleviate the issue. We discuss the failure cases further in Section 3.3.
任务类型细分: 从图11可以看出,Air Fryer Closing和Cushion Flipping是平均成功率最高的任务组(100%),而平均成功率最低的任务组是6D pick & place(56%)。我们发现,6D pick and place任务通常失败,因为它们通常需要机器人在各种轴上进行运动:例如在轨迹的不同部分进行不同轴上的平移和旋转,我们相信更多的数据可能会缓解这个问题。我们在第3.3节进一步讨论了失败的情况。
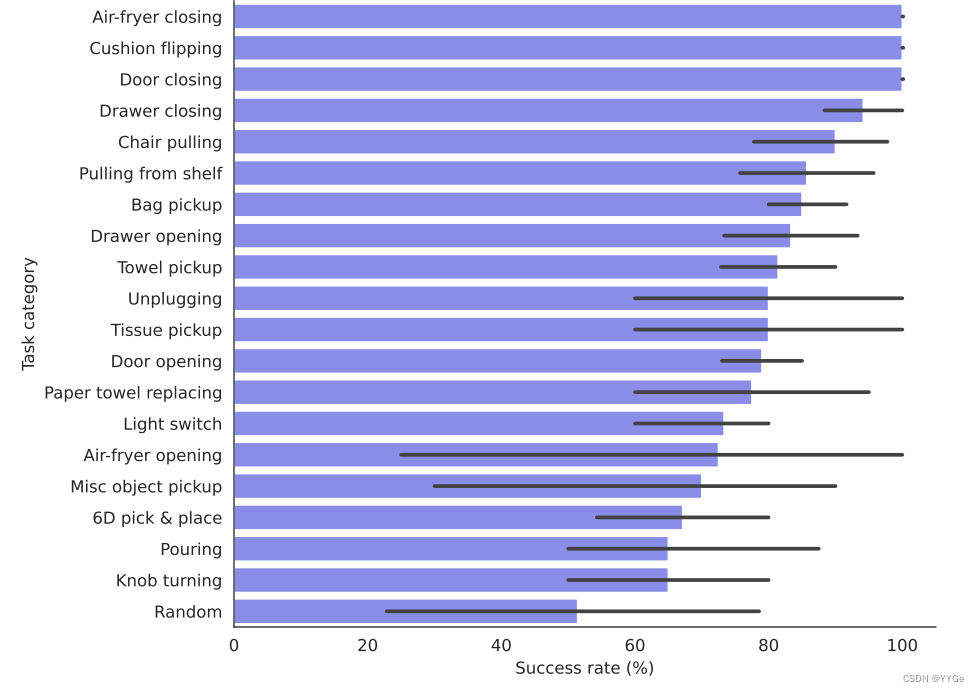
Figure 11: Success rate of our 20 different task groups, with the variance in each group’s success rate shown in the error bar.
图11: 我们20个不同任务组的成功率,每个组的成功率差异显示在误差条中。
Breakdown by Action Type We can cluster the tasks into buckets by their difficulty as shown in Figure 12. We find that the type of movement affects the success rate of the tasks. Specifically, the distribution of success rates for tasks which do not require any wrist rotation is skewed much more positively compared to tasks where we need either yaw or roll, or a combination of yaw, pitch, and roll. Moreover, the distribution of successes for tasks which require 6D motion is the flattest, which shows that tasks requiring full 6D motions are harder compared to tasks where Dobb·E doesn’t require full 6D motion.
动作类型细分: 我们可以按难度将任务分成不同的桶,如图12所示。我们发现,运动类型影响任务的成功率。具体而言,对于不需要任何手腕旋转的任务,成功率分布明显偏向正面,而对于需要偏航或翻滚,或者需要偏航、俯仰和翻滚的任务,成功率分布则较为平坦。此外,需要6D运动的任务的成功分布最为平坦,表明相对于Dobb·E不需要完整的6D运动的任务而言,需要完整的6D运动的任务更为困难。
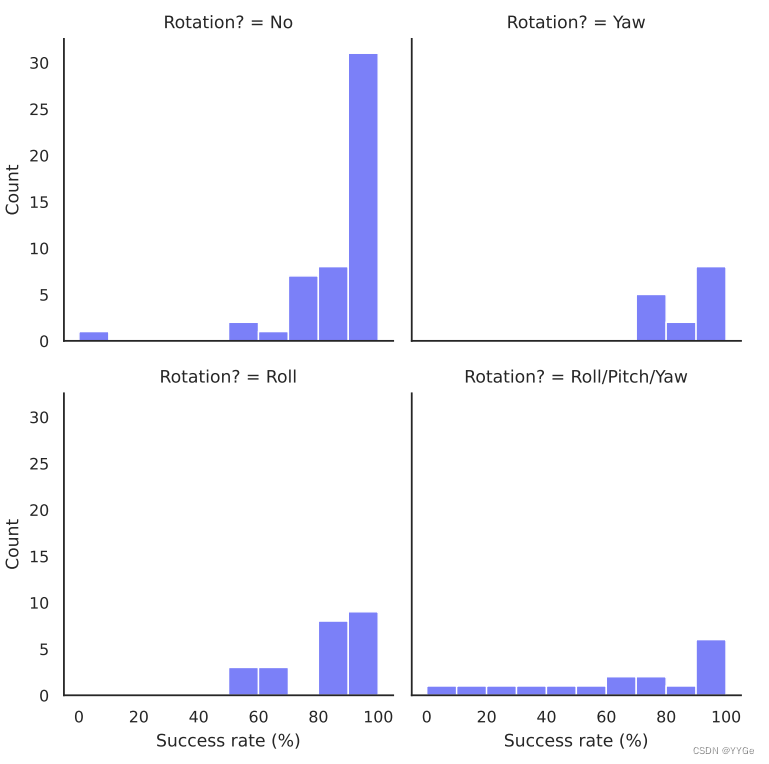
Figure 12: Success rate breakdown by type of actions needed to solve the task. The X-axis shows the number of successes out of 10 rollouts, and the Y-axis shows number of tasks with the corresponding number of success.
图12: 按解决任务所需的动作类型划分的成功率。X轴显示了在10次执行中的成功次数,Y轴显示了具有相应成功次数的任务数量。
Correlation between demo time and difficulty Here, we try to analyze the relationship between the difficulty of a task group when done by the robot, and the time required to complete the task by a human. To understand the relationship between these two variables related to a task, we perform a regression analysis between them.
演示时间和难度之间的相关性: 在这里,我们尝试分析由机器人完成的任务组的难度与人类完成任务所需时间之间的关系。为了理解与任务相关的这两个变量之间的关系,我们在它们之间进行回归分析。
We see from Figure 13 that there is a weak negative correlation (r = −0.24, with p = 0.012 < 0.05) between the amount of time taken to complete a demo by the human demonstrator and how successful the robot is at completing the task. This analysis implies that while longer tasks may be harder for the robot to accomplish, there are other factors that contribute to making a task easy or difficult.
从图13可以看出,完成任务的人类演示者所需的时间与机器人成功完成任务之间存在弱负相关性(r = -0.24,p = 0.012 < 0.05)。这个分析表明,尽管较长的任务可能更难让机器人完成,但还有其他因素影响任务的难易程度。
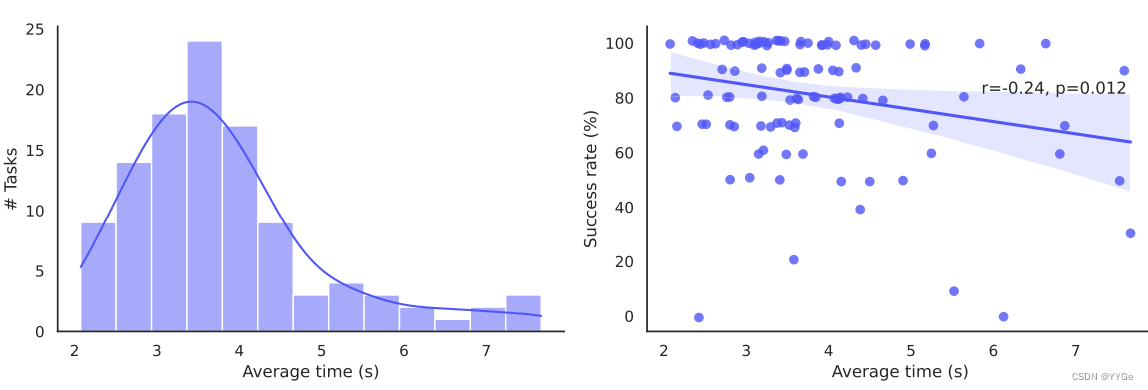
Figure 13: (a) Distribution of time (in seconds) taken to demonstrate a task on our experiment setup. The mean time taken to complete one demonstration is 3.82 seconds, and the median time taken is 3.49 seconds. (b) Correlation analysis between time taken to demonstrate a task and the success rate of the associated robot policy.
图13:(a) 展示在我们的实验设置中演示任务所需的时间(以秒为单位)的分布。完成一次演示所需的平均时间为3.82秒,中位时间为3.49秒。(b) 分析演示任务所需时间与相关机器人策略成功率之间的相关性。
3.3 Failure Modes and Analysis
3.3 失败模式与分析
Lighting and shadows In many cases, the demos were collected in different lighting conditions than the policy execution. Generally, with enough ambient lighting, our policies succeeded regardless of day and night conditions. However, we found that if there was a strong shadow across the task space during execution that was not there during data collection, the policy may behave erratically.
光照和阴影: 在许多情况下,演示收集是在与策略执行时的不同光照条件下进行的。通常情况下,有足够的环境光,我们的策略无论在白天还是晚上都能成功。但是,我们发现如果在执行过程中出现了在数据收集时不存在的强烈阴影,策略可能会表现得不稳定。
The primary example of this is from Home 1 Air Fryer Opening (see Figure 14), where the strong shadow of the robot arm caused our policy to fail. Once we turned on an overhead light for even lighting, there were no more failures. However, this shadow issue is not consistent, as we can see in Figure 15, where the robot performs the Home 6 table pulling task successfully despite strong shadows.
主要例子来自Home 1 Air Fryer Opening(见图14),机器人手臂的强烈阴影导致我们的策略失败。一旦打开了顶部灯,确保了均匀的光照,就不再出现失败。然而,这个阴影问题并不一致,正如图15所示,机器人成功执行Home 6桌子拉动任务,尽管存在强烈的阴影。

Figure 14: First-person POV rollouts of Home 1 Air Fryer Opening comparing (top row) the original demonstration environment, against robot performance in environments with (middle row) similar lighting, and (bottom row) altered lighting conditions with additional shadows
图14: Home 1 Air Fryer Opening的第一人称视角演示,比较(顶部行)原始演示环境,与(中部行)类似光照条件下机器人的表现,以及(底部行)具有额外阴影的改变光照条件下的机器人表现。

Figure 15: First person view from the iPhone from the (top row) Stick during demonstration collection and (bottom row) the robot camera during rollout. Even with strong shadows during rollout, the policy succeeds in pulling the table.
图15: iPhone的第一人称视角,来自Home 1 Air Fryer Opening的演示收集时(顶部行),以及机器人执行时的摄像机视角(底部行)。即使在执行过程中有强烈的阴影,策略仍然成功地拉动桌子。

Figure 16: First person view from the iPhone from the (top row) Stick during demo collection and (bottom row) robot camera during rollout. The demonstrations were collected during early afternoon while rollouts happened at night; but because of the iPhone’s low light photography capabilities, the robot view is similar.
图16: iPhone的第一人称视角,来自Home 8 cushion straightening的演示收集时(顶部行),以及机器人执行时的摄像机视角(底部行)。演示是在白天收集的,而执行是在夜间进行的;但由于iPhone的低光摄影能力,机器人视图相似。
In many cases with lighting variations, the low-light photography capabilities of the iPhone helped us generalize across lighting conditions. For example, in Home 8 cushion straightening (Figure 16), we collected demos during the day and ran the robot during the night. However, from the robot perspective the difference in light levels is negligible.
在许多具有光照变化的情况下,iPhone低光摄影的能力帮助我们在不同的光照条件下进行泛化。例如,在Home 8 cushion straightening中(图16),我们在白天收集演示,而在夜间运行机器人。然而,从机器人的视角来看,光照水平的差异可以忽略不计。
Sensor limitations One of the limitations of our system is that we use a lidar-based depth sensor on the iPhone. Lidar systems are generally brittle at detecting and capturing the depth of shiny and reflective objects. As a result, around reflective surfaces we may get a lot of out-of-distribution values on our depth channel and our policies can struggle.
传感器限制: 我们系统的一个局限性是我们使用iPhone上基于激光雷达的深度传感器。激光雷达系统通常很难检测和捕捉光滑和反光物体的深度。因此,在反光表面周围,我们可能会在深度通道上获得许多超出分布范围的值,我们的策略可能会受到影响。

Figure 17: First-person POV rollouts of Home 3 Air Fryer Opening showcasing (top row) a demonstration of the task and (bottom row) robot execution.
图17: Home 3 Air Fryer Opening的第一人称视角演示,展示了任务的演示(顶部行)和机器人执行(底部行)。

Figure 18: Opening an outward facing window blind (top row) both without depth (second row) and with depth (third row). The depth values (bottom row) for objects outside the window are high noisy, which cause the depth-aware behavior model to go out of distribution.
图18: 打开朝外的窗帘(顶部行),无深度(第二行)和有深度(第三行)。窗外物体的深度值(底部行)非常嘈杂,这导致深度感知行为模型越界。
A secondary problem with reflective surfaces like mirrors is that we collect demonstrations using the Stick but run the trained policies on the robot. In front of a mirror, the demonstration may actually end up recording the demo collector in the mirror. Then, once the policy is executed on the robot, the reflection on the mirror captures the robot instead of the demonstrator, and so the policy goes out-of-distribution and fails.
反光表面的另一个问题是,我们使用Stick收集演示,但在机器人上运行经过训练的策略。在镜子前面,演示实际上可能会录制镜子中的演示收集者。然后,一旦在机器人上执行策略,镜子上的反射捕捉到的是机器人而不是演示者,因此策略会出现超出分布范围并失败。
One of the primary examples of this is Home 3 Air Fryer Opening (Figure 17). There, the air fryer handle was shiny, and so had both bad depth and captured the demonstration collector reflection which was different from the robot reflection. As a result, we had 0/10 successes on this task.
失败例子1: Home 3 Air Fryer Opening(图17)。在这里,炸锅的把手很亮,因此深度感知不良,并且捕捉到演示收集器的反射,这与机器人的反射不同。结果,在这个任务中我们的成功率是0/10。
Another example is Home 1 vertical window blinds opening, where the camera faced outwards in the dark and provided many out-of-distribution values for the depth (Figure 18). In this task, depth-free models performed better (10/10 successes) than depth-using models (2/10 successes) because of such values.
失败例子2: Home 1垂直百叶窗的打开任务,在这个任务中,相机朝着黑暗的窗外,提供了很多深度值的分布之外的值(图18)。在这个任务中,无深度模型的表现更好(10/10成功),而使用深度的模型则因为这些值而失败(2/10成功)。
Robot hardware limitations Our robot platform, Hello Robot Stretch RE1, was robust enough that we were able to run all the home experiments on a single robot with only minor repairs. However, there are certain hardware limitations that caused several of our tasks to fail.
机器人硬件限制: 我们的机器人平台Hello Robot Stretch RE1足够强大,可以在一个机器人上运行所有家庭实验,只需进行一些小的修复。然而,有一些硬件限制导致我们的一些任务失败。
The primary constraint we faced was the robot’s height limit. While the Stretch is tall, the manipulation space caps out at 1m, and thus a lot of tasks like light switch flicking or picking and placing from a high position are hard for the robot to do. Another challenge with the robot is that since the robot is tall and bottom-heavy, putting a lot of pulling or pushing force with the arm near the top of the robot would tilt the robot rather than moving the arm (Figure 19), which was discussed in [79]. Comparatively, the robot was much more successful at opening heavy doors and pulling heavy objects when they were closer to the ground than not, as shown in the same figure. A study of such comparative pulling forces needed can be found in [80, 81].
我们面临的主要约束是机器人的高度限制。尽管Stretch很高,但操作空间的上限为1米,因此一些任务,比如开关灯开关或从高处拿起和放置物体,对机器人来说很难完成。另一个机器人的挑战是,由于机器人高大而底部沉重,在机器人的顶部附近施加大量拉力或推力会使机器人倾斜而不是移动手臂(图19),有关此类比较拉力的研究可以在[80, 81]中找到。

Knob turning, another low performing task, had 65% success rate because of the fine manipulation required: if the robot’s grasp is not perfectly centered on the knob, the robot may easily move the wrist without moving the knob properly.
图19: 在不同高度上拉门和拉取重物时机器人行为的比较。机器人在接近地面时更成功,而在较高位置时则更容易倾斜。
Temporal dependencies Finally, while our policy only relies on the last observations, for a lot of tasks, being able to consider temporal dependency would give us a much more capable policy class. For example, for a lot of Pick and Place tasks, the camera view right after picking up an object and the view right before placing the object may look the same. In that case, a policy that is not aware of time or previous observations gets confused and can’t decide between moving forward and moving backwards. A clear example of this is in Home 3 Pick and Place onto shelf (Figure 20), where the policy is not able to place the object if the pick location and the place location (two shelf racks) look exactly the same, resulting in 0/10 successes. However, if the policy is trained to pick and place the exact same object on a different surface (here, a red book on the shelf rack), the model succeeds 7/10 times. A policy with temporal knowledge [82–84] could solve this issue.
时间依赖性: 最后,尽管我们的策略仅依赖于最后的观察,但对于许多任务来说,考虑到时间依赖性将使我们能够拥有更强大的策略类别。例如,在许多Pick and Place任务中,捡起物体后的相机视图和放置物体之前的视图可能看起来相同。在这种情况下,一个不了解时间或先前观察的策略会感到困惑,无法决定前进还是后退。一个明显的例子是在Home 3 Pick and Place onto shelf(图20)中,如果挑选位置和放置位置(两个架子)看起来完全相同,策略无法放置物体,导致0/10次成功。然而,如果策略被训练在不同的表面上(这里是架子上的一本红色书)挑选和放置相同的物体,模型成功率为7/10。具有时间知识的策略[82–84]可以解决这个问题。

Figure 20: First-person POV rollouts of Home 3 Pick and Place comparing (top) a policy trained on demos where the object is picked and placed onto a red book on a different shelf and (bottom) a policy trained on demos where the object is picked and placed onto that same shelf without a red book. In the second case, since there is no clear signal for when to place the object, the BC policy keeps moving left and fails to complete the task.
图20: Home 3 Pick and Place的第一人称视角演示,比较了(顶部)一个在不同架子上的红书上捡起物体并放置的演示训练的策略和(底部)一个在相同架子上没有红书的演示训练的策略。在第二种情况下,由于没有明确的信号指示何时放置物体,BC策略一直向左移动并未能完成任务。
3.4 Ablations
3.4 消融实验
We created a benchmark set of tasks in our lab, with a setup that closely resembles a home, to be able to easily run a set of ablation experiments for our framework. To compare various parts of our system, we compare them with alternate choices, and show the relative performance in different tasks. These ablation experiments evaluate different components of our system and how they contribute to our performance. The primary elements of our model that we ran ablations over are the visual representation, number of demonstrations required for our tasks, depth perception, expertise of the demonstrator, and the need for a parametric policy.
我们在实验室创建了一组任务作为基准,该设置与家庭环境非常相似,以便能够轻松地运行一组我们框架的消融实验。为了比较我们系统的各个部分,我们将它们与备选选择进行比较,并展示在不同任务中的相对性能。这些消融实验评估我们系统的不同组件以及它们对性能的贡献。我们对模型的主要元素进行了消融实验,包括视觉表示,任务所需的演示数量,深度感知,演示者的专业知识以及是否需要参数化策略。
Alternate visual representation models Our alternate visual representation comparison is with other pretrained representation models such as MVP [7], R3M [8], VC1 [9], and a pretrained ImageNet1k [5, 59] model. We compare them against our own pretrained models on the benchmark tasks, and compare the performances.
备选视觉表示模型: 我们的备选视觉表示比较是与其他预训练表示模型,如MVP [7]、R3M [8]、VC1 [9]以及预训练的ImageNet1k [5, 59]模型进行的。我们将它们与我们自己在基准任务上预训练的模型进行比较,并比较它们的性能。
We see that in our benchmark environments, VC1 is the only representation that comes close to our trained representation. As a result, we ran some more experiments with VC1 representation in a household environment. As we can see, while VC1 is closer in performance to our model compared to IN-1K, R3M and MVP, it under-performs our model in household environments. However, VC-1 shows an interesting pattern of bimodal behavior: in each enviroment it either performs comparatively to HPR, or fails to complete the task entirely
我们可以看到,在我们的基准环境中,VC1是唯一接近我们训练表示的模型。因此,我们对VC1表示进行了一些在家庭环境中的实验。正如我们所看到的,虽然VC1在性能上与我们的模型更接近,与IN-1K、R3M和MVP相比,但在家庭环境中表现不佳。然而,VC-1显示出一种有趣的双峰行为模式:在每个环境中,它要么与HPR相比较,要么完全无法完成任务。

Figure 21: Comparison between different representation models at a set of tasks done in (a) our lab and (b) in a real home enviroment. As we can see, VC-1 is the representation model closest to ours in performance, however it has a high variance behavior where it either performs well or fails to complete the task entirely. The X-axis shows task completion rate distribution with the error bars showing the 95% confidence interval.
图21: 在我们的实验室(a)和真实家庭环境(b)中完成一组任务的不同表示模型的比较。正如我们所看到的,VC-1是性能最接近我们的表示模型,然而它具有高方差的行为,要么表现良好,要么完全无法完成任务。X轴显示任务完成率分布,误差条显示95%的置信区间。
Number of demonstrations required for tasks While we perform all our tasks with 24 demonstrations each, different tasks may require different numbers of demonstrations. In this set of experiments, we show how models trained on different numbers of demonstrations compare to each other.
任务所需的演示数量: 虽然我们对所有任务都进行了24次演示,但不同的任务可能需要不同数量的演示。在这组实验中,我们展示了在不同演示数量下训练的模型之间的比较。
As we see in Figure 22, adding more demonstrations always improves the performance of our system. Moreover, we see that the performance of the model scales with the number of demonstrations until it saturates. This shows us that on the average case, if our model can somewhat solve a task, we can improve the performance of the system by simply adding more demonstrations.
如图22所示,增加更多的演示总是提高了我们系统的性能。此外,我们看到模型的性能随着演示数量的增加而增加,直到饱和。这向我们表明,在平均情况下,如果我们的模型能够在某种程度上解决一个任务,通过简单地添加更多的演示,我们可以提高系统的性能。
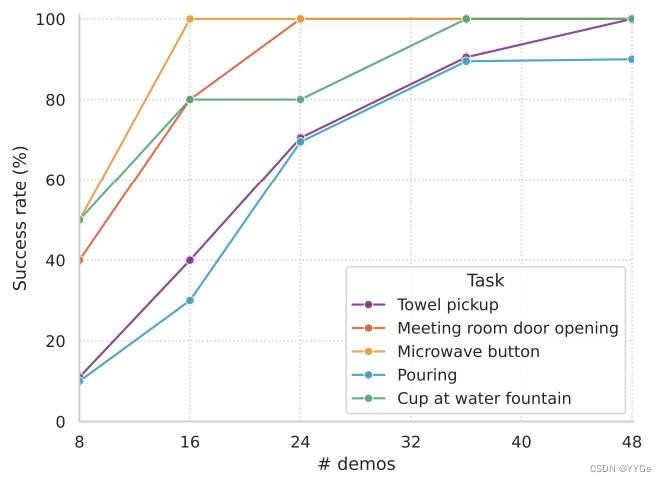
Figure 22: Success rates for a given number of demonstrations for five different tasks. We see how the success rate converges as the number of demonstrations increase.
图22: 给定演示数量的成功率,针对五个不同任务。我们看到随着演示数量的增加,成功率趋于稳定。
Depth Perception In this work, we use depth information from the iPhone to give our model approximate knowledge of the 3D structure of the world. Comparing the models trained with and without depth in Figure 23, we can see that adding depth perception to the model helps it perform much better than the model with RGB-only input.
深度感知: 在这项工作中,我们使用iPhone的深度信息为模型提供对世界3D结构的粗略了解。在图23中比较使用深度和不使用深度训练的模型,我们可以看到添加深度感知对模型的性能有很大帮助,比仅使用RGB输入的模型表现更好。

Figure 23: Barplot showing the distribution of task success rates in our two setups, one using depth and another not using depth. In most settings, using depth outperforms not using depth. However, there are some exceptional cases which are discussed in Section 3.3.2.
图23: 条形图显示任务成功率在我们的两个设置中的分布,一个使用深度,另一个不使用深度。在大多数情况下,使用深度优于不使用深度。然而,在第3.3.2节中讨论了一些特殊情况。
The failure modes for tasks without depth are generally concentrated around cases where the robot end-effector (and thus the camera) is very close to some featureless task object, for example a door or a drawer. Because such scenes do not have many features, it is hard for a purely visual imitation model without any depth information to know when exactly to close the gripper. On the other hand, the depth model can judge by the distance between the camera and the task surface when to open or close the gripper.
没有深度的任务的失败模式通常集中在机器末端执行器(因此是相机)非常靠近一些没有特征的任务对象的情况,例如门或抽屉。因为这样的场景没有太多特征,对于一个纯粹的视觉模仿模型而言,没有任何深度信息,它很难知道何时准确关闭夹爪。另一方面,深度模型可以通过相机与任务表面之间的距离来判断何时打开或关闭夹爪。
Demonstrator Expertise Over the course of our project, we gained experience of how to collect demonstrations with the Stick. A question still remains of how much expertise is needed to operate the Stick and collect workable demonstrations with it.
演示者的专业知识: 在项目的过程中,我们积累了如何使用Stick收集演示的经验。一个问题仍然存在,即使用Stick和它收集可用演示需要多少专业知识。
For this experiment, we have two novice demonstrators collect demonstrations for two tasks in our lab setup. In Task 1, our collected data gave 100% success, while in Task 2, our collected data gave 70% success. Novice collector 1 collected data for Task 1 first and Task 2 second, while collector 2 collected data for Task 2 first and Task 1 second. Collector 1’s data had 10% success rate on Task 1, but had 70% success on Task 2. Collector 2’s data had 0% success on Task 2 but 90% success on Task 1. From the data, we can see that while it may not be trivial initially to collect demonstrations and teach the robot new skills, with some practice both of our demonstrators were able to collect demonstrations that were sufficient.
对于这个实验,我们让两名新手演示者在我们的实验室设置中为两个任务收集演示。在任务1中,我们的收集的数据给出了100%的成功率,而在任务2中,我们的收集的数据给出了70%的成功率。新手收集者1首先为任务1收集数据,然后为任务2收集数据,而收集者2首先为任务2收集数据,然后为任务1收集数据。收集者1的数据在任务1上的成功率为10%,但在任务2上的成功率为70%。收集者2的数据在任务2上的成功率为0%,但在任务1上的成功率为90%。从数据中我们可以看到,虽然最初收集演示并教导机器新技能可能不是微不足道的,但通过一些实践,我们的两名演示者都能够收集足够的演示。
Odometry In our system, we used the Stick odometry information based on the iPhone’s odometry estimate. Previous demonstration collection systems in works like [19, 24] used structure-frommotion based visual odometry methods instead, like COLMAP [85] and OpenSfM [86]. In this section, we show the difference between the iPhone’s hardware-based and OpenSfM’s visual odometry methods, and compare the quality of the actions extracted from them.
里程计: 在我们的系统中,我们使用基于iPhone的Stick测距信息。先前的演示收集系统,如[19, 24]中所使用的是基于结构运动的视觉测距方法,如COLMAP [85]和OpenSfM [86]。在这一部分中,我们展示了iPhone硬件基础和OpenSfM的视觉测距方法之间的差异,并比较了从中提取的动作的质量。
As we can see from the Figure 24, OpenSfM-extracted actions are generally okay while the camera is far away from everything. However, it fails as soon as the camera gets very close to any surface and loses all visual features. The hardware odometry from the iPhone is much more robust, and thus the actions extracted from it are also reliable regardless of the camera view.
从图24中,我们可以看到,当相机远离所有物体时,OpenSfM提取的动作通常还可以。然而,一旦相机非常靠近任何表面并失去所有视觉特征,它就会失败。与之相比,来自iPhone的硬件测距更为稳健,因此从中提取的动作也更可靠,而不受相机视角的影响。

Figure 24: Open-loop rollouts from our demonstrations where the robot actions were extracted using (a) the odometry from iPhone and (b) OpenSfM respectively.
图24: 我们的演示的开环展示,其中机器人的动作分别使用(a) iPhone的测距仪和(b) OpenSfM提取的数据。
4 Open Problems and Request for Research
4 开放问题与研究请求
In this work we have presented an approach to scalable imitation learning that can be applied in household settings. However, there remains open problems that we must address before truly being able to bring robots to homes.
在这项工作中,我们提出了一种可在家庭环境中应用的可扩展模仿学习方法。然而,在真正将机器人引入家庭之前,仍然存在一些需要解决的开放性问题。
4.1 Scaling to Long Horizon Tasks
4.1 长时程任务的扩展
We primarily focused on short-horizon tasks in this work, but intuitively, our framework should be easily extensible to longer-horizon, multi-step tasks with algorithmic improvements. To validate this intuition, we train Dobb·E to perform some multi-step tasks in our lab.
在这项工作中,我们主要关注了短时程任务,但直观地说,我们的框架应该很容易通过算法改进来扩展到更长时程、多步骤任务。为了验证这一直觉,我们训练了Dobb·E在我们的实验室执行一些多步骤任务。
In Figures 26a, 26b, and 26c, we can see that Dobb·E can successfully perform multi-step, long horizon tasks like putting a cup in a drawer, placing a muffin in a toaster oven, or placing a can in a recycling bag and lifting it. However, because of the compound nature of these tasks, the failure cases also tend to compound with our simple methods, as seen in Figure 25. For example, in the muffin-in-toaster task, our model got 1 success out of 10 trials, and in the cup-in-drawer task, our model got 6 success out of 10 trials. In both cases, the sub-task causing primary failure was not letting go of the grasped object (cup or muffin). If we can improve on such particular subtasks, possibly using force-aware methods similar to [87], we believe Dobb·E can easily scale up to long-horizon tasks. Fast on-line adaptation on top of offline training [88, 89] has potential to improve such long horizon cases as well. In other cases, the robot was able to open the door but unable to disengage safely from the handle because some part of the robot gripper got stuck to the handle. This failure mode points to the need of better designed, less bare-boned robot grippers for household tasks.
在图26a、26b和26c中,我们可以看到Dobb·E成功地执行了多步骤、长时程的任务,如将杯子放入抽屉中、将松饼放入烤箱中或将罐头放入回收袋并将其提起。然而,由于这些任务的复合性质,失败案例也往往会随着我们简单的方法而累积,如图25所示。例如,在松饼进烤箱的任务中,我们的模型在10次试验中只成功了1次,在将杯子放入抽屉的任务中,我们的模型在10次试验中成功了6次。在这两种情况下,导致主要失败的子任务是不放开抓取的物体(杯子或松饼)。如果我们能改进这些特定的子任务,可能使用类似于[87]的力感知方法,我们相信Dobb·E可以轻松扩展到长时程任务。在线快速适应离线训练[88, 89]也有可能改进这些长时程案例。在其他情况下,机器人能够打开门,但无法安全脱离把手,因为机器人夹具的某个部分被卡在把手上。这种失败模式表明需要更好设计、更不简陋的家用任务机器人夹具。
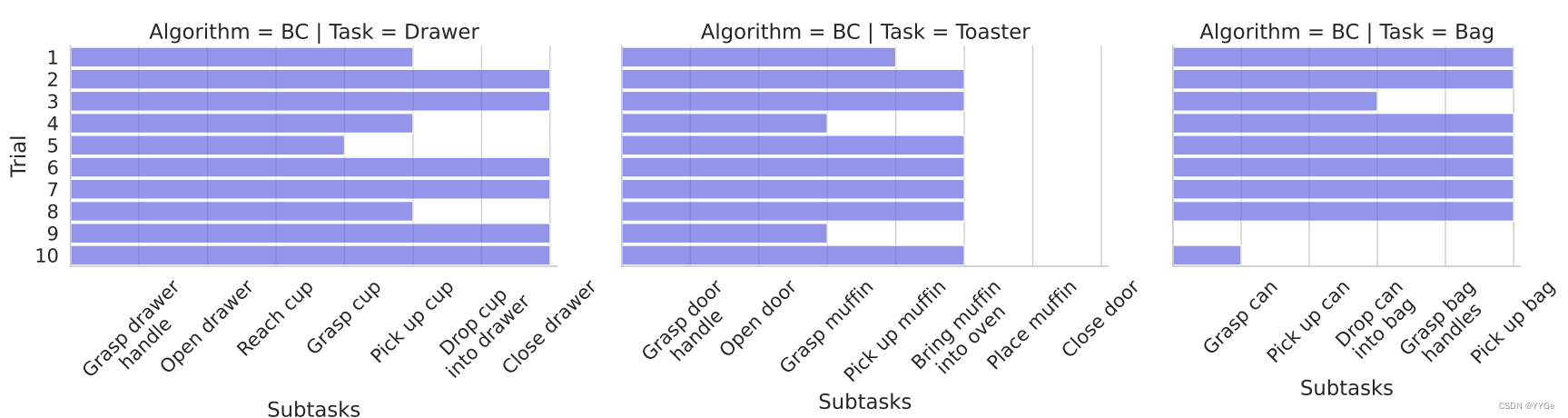
Figure 25: Analysis of our long-horizon tasks by subtasks. We see that Dobb·E can chain subtasks, although the errors can accumulate and make overall task success rate low.



Figure 26: Dobb·E completing three temporally extended tasks each made up of five to seven subtasks
图26:Dobb·E完成三个由五到七个子任务组成的时间扩展任务。
4.2 Incorporating Memory
4.2 整合记忆
Another large challenge in our setup is the problem of robotic scene memory. With a single first person point of view on the Stick, the robot needs to either see or remember large parts of the scene to operate on it effectively. However, there is a dearth of algorithms that can act as standalone memory module for robots. The algorithms that currently exist, such as [90–97] also tend to have a rigid representation of the scene that is hard to change or edit on the fly, which will need to improve for real household deployments.
在我们的设置中,另一个巨大的挑战是机器人场景记忆的问题。通过Stick上的单一第一人称视角,机器人需要有效地查看或记住场景的大部分部分。然而,目前存在的算法,如[90–97],也往往具有难以在运行时更改或编辑的刚性场景表示,这在实际家庭部署中需要改进。
4.3 Improving Sensors and Sensory Representations
4.3 改进传感器和感知表示
Most of current visual representation learning algorithms focus on learning from third-person views, since that is the dominant framework in Computer Vision. However, third person cameras often rely on camera calibration, which generally makes using large robot datasets and transferring data between robots difficult [55]. A closer focus on learning from first person cameras and eye-in-hand cameras would make sharing data from different environments, tasks, and robots much easier. Finally, one of the modality that our Stick is missing is having tactile and force sensors on the gripper. In deployment, we have observed the robot sometimes applies too much or too little force because our framework doesn’t contain such sensors. Better integration of cheap sensors [98] with simple data collection tools like the Stick, or even more methods like learned visual contact force estimation [99, 100] could be crucial in such settings.
目前大多数视觉表示学习算法侧重于从第三人称视图学习,因为这是计算机视觉中主导的框架。然而,第三人称摄像头通常依赖于摄像机校准,这通常使使用大型机器人数据集并在不同机器人之间传输数据变得困难[55]。更加专注于从第一人称摄像头和手眼摄像头学习将使从不同环境、任务和机器人共享数据变得更容易。最后,我们的Stick缺少的一种模态是在夹持器上使用触觉和力传感器。在部署中,我们观察到机器人有时会因为我们的框架不包含这些传感器而施加过多或过少的力。更好地集成廉价传感器[98]与像Stick这样的简单数据收集工具,甚至更多的方法,如学习视觉接触力估计[99, 100],在这种情境中可能至关重要。
4.4 Robustifying Robot Hardware
4.4 加强机器人硬件的稳健性
A large limitation on any home robotics project is the availability of cheap and versatile robot platforms. While we are able to teach the Hello Robot Stretch a wide-variety of tasks, there were many more tasks that we could not attempt given the physical limitations of the robot: its height, maximum force output, or dexterous capabilities. Some of these tasks may be possible while teleoperating the robot directly rather than using the Stick, since the demonstrator can be creative and work around the limits. However, availability of various home-ready robotic platforms and further development of such demonstration tools would go a long way to accelerate the creation of household robot algorithms and frameworks.
在任何家庭机器人项目中的一个重要限制是廉价且多功能的机器人平台的可用性。虽然我们能够教Hello Robot Stretch各种任务,但由于机器人的物理限制,有许多其他任务我们无法尝试:它的高度、最大输出力或灵巧性能。在直接遥操作机器人而不使用Stick的情况下,一些这些任务可能是可能的,因为演示者可以富有创造性地解决问题并绕过限制。然而,各种家用机器人平台的可用性和这种演示工具的进一步发展将大大加速家用机器人算法和框架的创建。
5 Reproducibility and Call for Collaboration
5 可复现性和合作呼吁
To make progress in home robotics it is essential for research projects to contribute back to the pool of shared knowledge. To this end, we have open-sourced practically every piece of this project, including hardware designs, code, dataset, and models. Our primary source of documentation for getting started with Dobb·E can be found at https://docs.dobb-e.com.
要在家庭机器人领域取得进展,研究项目有必要向共享知识库贡献。为此,我们已经开源了项目的几乎每个部分,包括硬件设计、代码、数据集和模型。我们开始使用Dobb·E的文档主要位于https://docs.dobb-e.com。
• Robot base: Our project uses Hello Robot Stretch as a platform, which is similarly open sourced and commercially available on the market for US$24,000 as of November 2023.
机器人基础:我们的项目使用Hello Robot Stretch作为平台,该平台同样是开源的,并且2023年11月市场上售价为24,000美元。
• Hardware design: We have shared our 3D-printable STL files for the gripper and robot attachment in the GitHub repo: https://github.com/notmahi/dobb-e/tree/main/hardware. We have also created some tutorial videos on putting the pieces together and shared them on our website. The reacher-grabber stick can be bought at online retailers, links to which are also shared on our website https://dobb-e.com/#hardware.
硬件设计:我们在GitHub仓库https://github.com/notmahi/dobb-e/tree/main/hardware中分享了用于夹持器和机器人附件的3D可打印STL文件。我们还制作了一些关于如何组装这些零件的教程视频,并在我们的网站上分享了这些视频。抓手棒可以在在线零售商处购买,链接也在我们的网站上https://dobb-e.com/#hardware上分享。
• Dataset: Our collected home dataset is shared on our website. We share two versions, a 814 MB version with the RGB videos and the actions, and an 77 GB version with RGB, depth, and the actions. They can be downloaded from our website, https://dobb-e.com/#dataset. At the same time, we share our dataset preprocessing code in GitHub https://github.com/notmahi/ dobb-e/tree/main/stick-data-collection so that anyone can export their collected R3D files to the same format.
数据集:我们收集的家庭数据集在我们的网站上共享。我们分享了两个版本,一个包含RGB视频和动作的814 MB版本,另一个包含RGB、深度和动作的77 GB版本。它们可以从我们的网站https://dobb-e.com/#dataset上下载。同时,我们在GitHub https://github.com/notmahi/dobb-e/tree/main/stick-data-collection上分享了我们的数据集预处理代码,以便任何人都可以将其收集的R3D文件导出到相同的格式。
• Pretrained model: We have shared our visual pretraining code as well as checkpoints of our pretrained visual model in our GitHub https://github.com/notmahi/dobb-e/tree/main/ imitation-in-homes and Huggingface Hub https://huggingface.co/notmahi/dobb-e. For this work, we also created a high efficiency video dataloader for robotic workload, which is also shared under the same GitHub repository
预训练模型:我们在GitHub https://github.com/notmahi/dobb-e/tree/main/imitation-in-homes和Huggingface Hub https://huggingface.co/notmahi/dobb-e上分享了我们的视觉预训练代码以及预训练视觉模型的检查点。为了这项工作,我们还创建了一个用于机器人工作负载的高效视频数据加载器,也在相同的GitHub存储库下分享。
Robot deployment: We have shared our pretrained model fine-tuning code in https://github. com/notmahi/dobb-e/tree/main/imitation-in-homes, and the robot controller code in https://github.com/notmahi/dobb-e/tree/main/robot-server. We also shared a stepby-step guide to deploying this system in a household, as well as best practices that we found during our experiments, in a handbook under https://docs.dobb-e.com.
机器人部署: 我们在https://github.com/notmahi/dobb-e/tree/main/imitation-in-homes中分享了我们的预训练模型微调代码,以及在https://github.com/notmahi/dobb-e/tree/main/robot-server中分享了机器人控制器代码。我们还在https://docs.dobb-e.com的手册中分享了在家庭中部署该系统的逐步指南,以及在我们的实验中发现的最佳实践。
Beyond these shared resources, we are also happy to help other researchers set up this framework in their own labs or homes. We have set up a form on our website to schedule 30-minutes online meetings, and shared some available calendar slots where we would be available to meet online and help set up this system. We hoping these steps would be beneficial for practitioners to quickly get started with our framework.
除了这些共享的资源之外,我们也乐意帮助其他研究人员在他们自己的实验室或家中建立这个框架。我们在我们的网站上设置了一个表单,用于安排30分钟的在线会议,并分享了一些我们将在线可用的日历时间段,在这些时间段我们将在线并帮助设置这个系统。我们希望这些步骤对于从业者快速入门我们的框架会有所帮助。
Finally, we believe that our work is an early step towards learned household robots, and thus can be improved in many possible ways. So, we welcome contributions to our repositories and our datasets, and invite researchers to contact us with their contributions. We would be happy to share such contributions with the world with proper credits given to the contributors.
最后,我们认为我们的工作是朝着学习型家庭机器人迈出的早期步骤,因此还有许多可能的改进。因此,我们欢迎对我们的存储库和数据集的贡献,并邀请研究人员与我们联系,分享他们的贡献。我们将很乐意在给予贡献者适当的赞誉的情况下与世界分享这些贡献。
Acknowledgments
致谢
NYU authors are supported by grants from Amazon, Honda, and ONR award numbers N00014-21-1- 2404 and N00014-21-1-2758. NMS is supported by the Apple Scholar in AI/ML Fellowship. LP is supported by the Packard Fellowship. Our utmost gratitude goes to our friends and colleagues who helped us by hosting our experiments in their homes, and those who helped us collect the pretraining data. We thank Binit Shah and Blaine Matulevich for support on the Hello Robot Platform and the NYU HPC team, especially Shenglong Wang, for compute support. We thank Jyo Pari and Anya Zorin for their work on earlier iterations of the Stick. We additionally thank Sandeep Menon and Steve Hai for his help in the early stages of data collection. We thank Paula Nina and Alexa Gross for their input on the designs and visuals. We thank Chris Paxton, Ken Goldberg, Aaron Edsinger, and Charlie Kemp for feedback on early versions of this work. Finally, we thank Zichen Jeff Cui, Siddhant Haldar, Ulyana Pieterberg, Ben Evans, and Darcy Tang for the valuable conversations that pushed this work forward.
NYU作者得到了来自亚马逊、本田和ONR奖励号码N00014-21-1-2404和N00014-21-1-2758的资助。NMS得到了苹果AI/ML奖学金的支持。LP得到了Packard Fellowship的支持。我们要深深感谢那些在他们的家中帮助我们进行实验的朋友和同事,以及那些帮助我们收集预训练数据的人。我们感谢Binit Shah和Blaine Matulevich对Hello Robot平台的支持,以及NYU HPC团队,特别是Shenglong Wang,对计算的支持。我们感谢Jyo Pari和Anya Zorin在Stick的早期版本上的工作。此外,我们还感谢Sandeep Menon和Steve Hai在数据收集的早期阶段的帮助。我们感谢Paula Nina和Alexa Gross对设计和视觉的建议。我们感谢Chris Paxton、Ken Goldberg、Aaron Edsinger和Charlie Kemp对该工作早期版本的反馈。最后,我们感谢Zichen Jeff Cui、Siddhant Haldar、Ulyana Pieterberg、Ben Evans和Darcy Tang的有价值的对话,推动着这项工作的进展。











![# [NOI2019] 斗主地 洛谷黑题题解](https://img-blog.csdnimg.cn/img_convert/3007d79cbabbe2b8191d12104a0ff062.png)