用于野外精确人体姿态估计的自适应多视图融合
Abstract
AdaFuse:一种自适应的多视图融合方法,利用可见视图中的特征增强被遮挡视图中的特征
核心:确定两个视图之间的点-点对应关系
- 通过研究热图表示的稀疏性
我们还学习了一个自适应的融合权值,以反映其特征质量,以减少良好的特征被不良的视图损坏的机会。融合模型由姿态估计网络端到端训练,可以直接应用于新的相机配置,无需额外的自适应。我们在Human3.6M、Total Capture和CMU Panoptic三个公共数据集上对该方法进行了广泛评估。本文方法在所有这些数据集上的表现都超过了先进水平。我们还创建了一个大规模的合成数据集Occlusion-Person,它允许我们对被遮挡的关节进行数值评估,因为它为图像中的每个关节提供遮挡标签。
Introduction
从多个摄像机中准确地估计出3D人体姿势是计算机视觉长期以来的目标,最终目的是从放置在自然环境中的多个摄像机中恢复人体关节在世界坐标系统中的绝对3D位置。由于该任务可以为增强现实和虚拟现实等应用带来诸多益处,因此受到了广泛的关注。
两步框架:
- 检测所有摄像机视图中的2D姿势:CNN
- 通过解析法或者判别模型从多视图二维姿态恢复三维姿态
然而,在基准数据集上获得小的错误并不意味着任务已经真正解决了,除非解决了现实世界应用中遇到的挑战,如背景杂波、人类外观变化和遮挡。事实上,许多人致力于提高具有挑战性场景下的姿态估计性能。
在本工作中,我们提出了一种不同的方法来解决该问题的多视图特征融合,AdaFuse,即使在某些视图中被遮挡,也能准确地检测出关节。该方法能有效提高被遮挡视图的特征质量。此外,对于具有不同相机姿态的新环境,只要相机参数可用,我们可以直接使用AdaFuse,无需重新训练。这提高了该方法在实际应用中的适用性。
AdaFused的原理:在一个视图中被遮挡的关节可能在其他视图中可见。因此,在不同的视图中,融合对应位置的特征通常是有帮助的
AdaFuse的步骤:
- 使用相机参数来计算一对视图之间的点线对应关系
- 在不进行具有挑战性的点-点匹配的情况下,通过研究热图表示的稀疏性,在直线上“找到”匹配点
- 融合匹配点在不同视图中的特征
**具体:**以多视图图像作为输入,联合输出各视图的2D位姿。它首先使用一个姿态估计网络来获得每个视图的2D热图。然后在极线几何上,从所有摄像机视图的热图被融合。最后,利用SoftMax算子抑制融合过程中引入的小噪声。因此,每个视图中的姿态估计受益于其他视图。

通过学习每个视图的自适应融合权值来反映其特征质量,AdaFuse的性能进一步提高。为了减少低质量视图的影响,在融合中使用了这种权重。如果一个关节在一个视图中被遮挡,它的特征也可能被损坏。在这种情况下,我们希望在进行多视图融合时给予该视图较小的权重,以使可见视图中的高质量特征占主导地位,而不会被低质量特征所破坏。我们在位姿估计网络中加入一些简单的层,根据热图分布和交叉视图一致性来预测热图质量。我们在实验中观察到自适应融合的使用显著地提高了性能。
我们在三个公共数据集上评估了我们的方法,包括Human3.6M 、Total Capture 和CMU Panoptic 。它超越了最先进的技术,证明了我们方法的有效性。此外,我们还将其与RANSAC等多种标准多视图融合方法进行了比较,以给出更详细的见解。通过对不同数据集的训练和测试,评估了该方法的泛化能力。我们还创建了一个合成的人体姿态数据集,其中人体被物体故意遮挡。数据集允许我们对被遮挡的关节进行评估。
Related Work
多视图3D人体姿态估计
方法分类:
- 基于模型的方法(综合分析方法)
两步框架:
- 首先用木棍和圆柱体等简单的原始物体来模拟人体。
- 然后根据多视图图像中的观测值不断更新模型的参数(即位姿),直到模型能够被图像特征解释为止。
所得到的优化问题通常是非凸的。因此经常使用昂贵的采样技术。这些方法的主要区别在于所采用的图像特征和优化算法。基于模型的方法的优点在于它能够处理人体模型固有的结构。这些方法以人体固有结构为约束,以局部特征为依据,对模型参数进行综合推断。因此,如果一个关节被遮挡,它仍然可以依靠其他关节来猜测与先前一致的可能位置。然而,基于模型的方法由于存在较难的优化问题,会比基于模型的方法产生较大的三维误差。
- 无模型方法
两步框架:
- 首先在所有相机视图的图像中检测2D姿势
- 然后在相机参数的帮助下,他们使用任一三角测量或图像结构模型恢复3D姿态
引入递归图形结构模型来加快推理过程,使用可学习三角测量进行人体姿态估计,这对不准确的2D姿态更有鲁棒性。如果2D位姿准确,则可以保证恢复的3D位姿准确,而无需担心陷入局部最优。
更强大的网络架构的开发极大地提高了基准数据集上的2D位姿估计精度,这反过来也降低了3D位姿估计误差。例如,在最流行的基准Human3.6M 上,3D MPJPE误差已经降低到约20mm,可以满足许多现实生活应用的要求。
提高“在野外”的表现
传感器遮挡的解决:
- 使用额外的传感器,如imu和无线电信号,它们不受遮挡的影响
- 该方法的精度受到漂移问题的限制
- 提出融合图像和imu,以实现更鲁棒的姿态估计。
- 一种基于无线电的系统:WiFi频率中的无线信号穿过墙壁并反射到人体,,即使在人完全被墙壁遮挡的情况下,也可以估计2D姿势。
- 然而,这些方法也有自己的问题。例如,如何有效地融合基于imu的方法的视觉和惯性信号?此外,在身体上佩戴传感器具有侵入性,在足球比赛等一些场景中是不允许的。另一方面,基于wifi的解决方案不能解决自遮挡问题,这是一个很大的限制。
数据增强:收集更多的图像进行模型训练是提高泛化性能的有效方法
- 注释一个足够大的姿态数据集是昂贵和耗时的
- 提出生成合成图像。主要问题是如何弥补合成图像和真实图像之间的差距,使在合成图像上训练的模型能够应用到真实图像上。为此,提出使用生成式对抗网络来生成逼真的图像。
**时空上下文模型:**联合检测视频序列中的所有关节,使每个关节可以从同一帧或相邻帧中的其他关节中受益。直观上,如果一个身体关节被遮挡,根据自身的外观很难被检测到,他们可以利用其他关节的位置来猜测可能的位置。
-
过往研究:
- 检测身体部位:即连接两个关节的链接,除了单个关节。这提供了一个相互增强两个连接关节的检测的机会。
- 利用时间卷积来处理当前帧中的遮挡。
- 建立多摄像机视图间的空间对应关系,利用多视图特征进行鲁棒联合检测。在几个基准数据集上,被遮挡关节的性能得到了显著的提高。该方法的主要缺点是在实践中缺乏灵活性,因为它需要为每个可能的摄像机位置训练一个单独的融合网络。
-
**AdaFuse方法:**可以应用于具有不同数量相机和不同相机姿势的新环境,而无需额外的适应性。
共识学习
多传感器融合的一个基本问题是检测和去除异常值,因为传感器可能产生不一致的测量值
RANSAC:最常用的离群值检测方法
- 主要的假设是数据集由内层组成。它只有在一定的概率下才能产生合理的结果,这种概率随着内层数的增加而增加。在实际应用中,当传感器数量较少时,检测到真实离群值的概率也较小。例如,在多视角人体姿态估计中,对于大多数基准数据集来说,摄像机的数量只有4到8个。对于这种情况,我们认为RANSAC可能不是最好的选择
**不确定性学习:**这对高风险的应用尤其重要
-
其主要思想是,当一个模型做出预测时,它还输出一个反映预测可信度的分数。例如,一辆使用神经网络来探测人的自动驾驶汽车。如果网络对预测没有信心,汽车可以依靠其他传感器来做出正确的决定。另外一个方法是,训练模型,使与预测类别标签相关的概率与它的真实标签的置信度一致。
-
不确定性被引入计算机视觉: 可以用来减少离群值的影响。例如,在(Iskakov et al., 2019)中,作者建议预测每个视图中每个关节的不确定性得分。在进行三角剖分时,该分数用于衡量每个视图。这极大地减少了3D姿态估计误差。
-
**AdaFuse方法:**受不确定性学习在计算机视觉任务中的成功应用的启发,提出了学习不确定性进行多视图特征融合。在融合多视图特征时,使用预测的不确定性作为权重。结果表明,该自适应特征融合方法能有效地提高融合质量。
The Basics for Multiview Fusion
通过局部特征匹配可以有效地解决窄基线对应问题。然而,在多视点人体姿态估计的情况下,当摄像机数量较少且彼此距离较远时,局部特征不能被鲁棒检测和匹配,特别是对于无纹理的人体区域。这是一个严峻的挑战。为了解决这一问题,我们提出了一种由粗到细的方法来寻找匹配点。它首先通过极线几何建立两个视图之间的点对线对应关系,然后通过研究热图表示的稀疏性隐式确定点对点对应关系。这种方法显著地简化了任务,因为它避免了寻找精确对应的挑战性步骤。
极线几何:
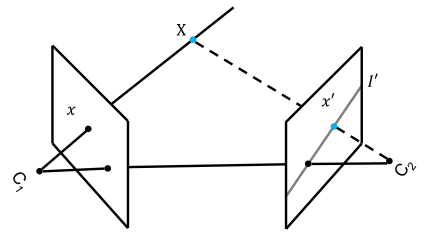
两种视图中的点线对应图。对于一个视图中的任意点,另一个视图中x对应的x’必须在对极线I’上。这是AdaFuse在其他视图中寻找对应点的核心。两极几何在两个视图之间本质上是图像平面与以基线为轴的平面铅笔相交的几何。基线是连接摄像机中心C1和C2的线。
图像点 x x x、 x ′ x' x′、3D X X X和摄像机中心点C1、C2在同一平面π上。该平面与两个图像平面分别在极线I和I0处相交。
Sampson Distance
在实践中,通常我们有2D测量
x
x
x和
x
’
x’
x’对应于相同的未知3D位置
X
X
X。由于测量噪声和误差,直线C1x和C2x0可能不完全相交于X点。为了得到X的最优估计,我们搜索
x
^
\hat{x}
x^
d Reproj 2 = min X ^ d 2 ( x , P X ^ ) + d 2 ( x ′ , P ′ X ^ ) d_{\text {Reproj }}^{2}=\min _{\hat{\mathbf{X}}} d^{2}(\mathbf{x}, \mathbf{P} \hat{\mathbf{X}})+d^{2}\left(\mathbf{x}^{\prime}, \mathbf{P}^{\prime} \hat{\mathbf{X}}\right) dReproj 2=minX^d2(x,PX^)+d2(x′,P′X^)
式中,d(·)为欧氏距离, d R e p r o j d_{Reproj} dReproj为 x x x到 x ’ x’ x’的重投影距离。由于获得 d R e p r o j d_{Reproj} dReproj时存在优化过程,我们采用了一步法,即它的一阶逼近,这个近似也称为Sampson Distance
d Sampson = x ′ ⊤ F x ( F x ) 1 2 + ( F x ) 2 2 + ( F ⊤ x ′ ) 1 2 + ( F ⊤ x ′ ) 2 2 d_{\text {Sampson }}=\frac{\mathbf{x}^{\prime \top} \mathbf{F} \mathbf{x}}{(\mathbf{F} \mathbf{x})_{1}^{2}+(\mathbf{F} \mathbf{x})_{2}^{2}+\left(\mathbf{F}^{\top} \mathbf{x}^{\prime}\right)_{1}^{2}+\left(\mathbf{F}^{\top} \mathbf{x}^{\prime}\right)_{2}^{2}} dSampson =(Fx)12+(Fx)22+(F⊤x′)12+(F⊤x′)22x′⊤Fx
其中F是基本矩阵,下标1或2表示向量的第一个或第二个元素。通过使用Sampson距离,我们可以直接得到一对位置之间的距离,而不需要知道中间的 x ^ \hat{x} x^。在AdaFuse中,我们使用Sampson距离来表示一对2D联合检测相互支持的程度。
热图融合
基于极线几何的热图融合。对于第一个视图中的每个位置x,我们首先在其他两个视图中计算相应的外极线。然后分别求出两条直线上的最大响应,并将它们与x处的原始响应相加

多视图融合应用于热图而不是中间特征,这是因为heatmap具有良好的稀疏性,可以简化点-点匹配。热图生成图像中联合位置的逐像素可能性。具体来说,它是生成一个以关节坐标为中心的二维高斯分布。所以它在关节附近有少量的大响应,而在其他位置有大量的零。
稀疏热图允许我们安全地跳过精确的点-点匹配,因为在极线上的“零”位置的特征对特征融合没有贡献。因此,我们不需要在另一个视图中寻找精确的对应位置,而只需选择极线段上最大的响应作为匹配点。这是一个合理的简化,因为对应点通常有最大的响应。例如,对于每个位置x,我们首先在其他两个相机视图中计算相应的外极线。然后我们分别在两个极线上找到最大的响应,并将它们与x处的响应融合。
根据每个位置x的摄像机参数,可以解析地计算出极线,然后将多视点融合表示为:
H
^
v
(
x
)
=
λ
H
v
(
x
)
+
1
−
λ
N
∑
u
=
1
N
max
x
′
∈
I
u
(
x
)
H
u
(
x
′
)
\hat { H } ^ { v } ( x ) = \lambda H ^ { v } ( x ) + \frac { 1 - \lambda } { N } \sum _ { u = 1 } ^ { N } \operatorname*{ max }_{{ x ^ { \prime } \in I ^ { u } ( x ) } }H ^ { u } ( x ^ { \prime } )
H^v(x)=λHv(x)+N1−λ∑u=1Nmaxx′∈Iu(x)Hu(x′)
副作用及解决方法
简化的融合模型产生的一个副作用是,一些背景位置可能会被不希望的增强。我们在图5的第二行中看到一个示例。我们可以看到很多背景像素,例如x,有非零响应,这是由融合引起的。这种现象的发生是因为多个极线(在其他视图中)可能会通过响应较大的地面真值联合位置,而某些极线实际上对应于当前视图中的背景像素点。图5解释了这一点。对于当前视图中的位置x,其他三个视图中相应的外极线绘制在第一行。我们可以看到,虽然x不在一个有意义的关节位置,外极第一视图经过真实膝关节,导致x出现较大的意外反应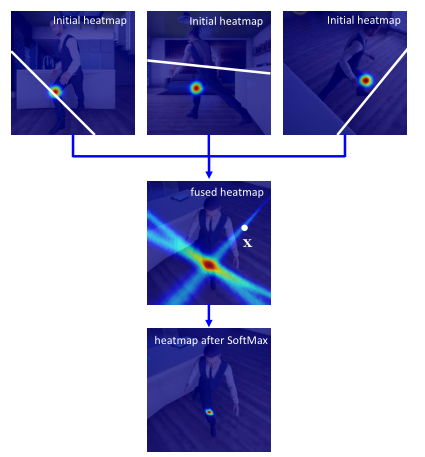
通常,在另一个视图中受高响应位置影响的像素保证位于同一条线上。更重要的是,不同视图对应的线不会重叠。这意味着,对于背景中的位置x,它的响应最多只能通过一个视图来增强。相反,与有意义的身体关节对应的位置将通过多个视图来增强。换句话说,对于一般情况,正确的位置保证有最大的响应。因此,我们利用这一观察结果,直接应用SoftMax操作符去除小的响应。
实现细节
值得注意的是,上述融合方法没有可学习的参数。因此,我们只需要训练SimpleBaseline等骨干网来估计位姿热图。骨干网训练的损失函数定义为估计热图和地面真值热图之间的均方误差损失。在测试阶段,给定SimpleBaseline估计的热图,我们通过我们的方法确定地融合它们。
Adaptive Weight for Multiview Fusion
前一节中介绍的融合策略均匀地对待所有视图,而不考虑每个视图的特征质量。然而,在一些相机视图的热图不正确的情况下,该策略是有问题的。这是因为这些特征可能会破坏良好视图中的特征,导致完全不正确的2D姿态估计结果。为了解决这一问题,我们提出了一种权值学习网络,为每个视图学习自适应权值,以真实反映其热图质量。它以位姿估计网络提取的N个视图的热图为输入,回归N个权重的ωu。然后重写多视图融合,考虑如下权值:
H
^
v
(
x
)
=
ω
v
H
v
(
x
)
+
∑
u
=
1
N
ω
v
max
x
′
∈
I
u
(
x
)
H
u
(
x
′
)
\hat { H } ^ { v } ( x ) = \omega ^ { v } H ^ { v } ( x ) + \sum _ { u = 1 } ^ { N } \omega ^ { v }\operatorname*{ max }_{{ x ^ { \prime } \in I ^ { u } ( x ) } }H ^ { u } ( x ^ { \prime } )
H^v(x)=ωvHv(x)+∑u=1Nωvmaxx′∈Iu(x)Hu(x′)
自适应融合权值ω的预测由轻量级神经网络实现,如图所示。在位姿估计网络提供的热图H上,我们提取两类信息来进行预测。一是The Appearance Embedding,提取热图的分布特征等信息。二是考虑交叉视图位置一致性的The Geometry Embedding。这两项是互补的。将特征串接后输入权值学习网络,学习反映各视图热图质量的融合权值。所提出的权值学习网络可以与姿态估计网络相结合进行端到端的训练,而无需对权值进行强制监督。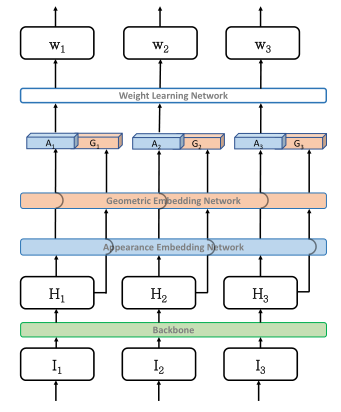
The Appearance Embedding
每个节点的热图实际上包含了丰富的信息来推断其热图质量。例如,如果预测的热图有一个理想的高斯核形状,那么在很多情况下,热图的质量是好的。相反,如果预测的热图在整个空间中都有随机且较小的响应(例如,当接缝被遮挡时),那么质量很可能很差。
我们提出了一个简单的网络来提取每个摄像机视图中每个关节的外观嵌入。图7显示了网络结构。从heatmap Hi开始,我们使用卷积层来提取特征。然后通过平均池化对特征进行下采样,并将其反馈到全连接(FC)层进行外观嵌入提取。不同的关节类型和摄像机视图共享相同的权重。为了简单起见,我们只显示单个视图和单个关节的网络。The Appearance Embedding网络与姿态估计网络进行端到端联合学习。
The Geometry Embedding
在某些具有挑战性的情况下,高斯核的热图具有理想的形状,但却在错误的位置,单靠外观嵌入是不够的。其中一个例子就是在右膝的位置发现了左膝,这通常被社会称为“重复计算”的问题。为了解决这个问题,我们提出利用所有摄像机视图之间的位置一致性信息。我们的核心动机是,如果在一个摄像机视图中预测的联合位置与其他视图中的位置一致,那么它就更可靠。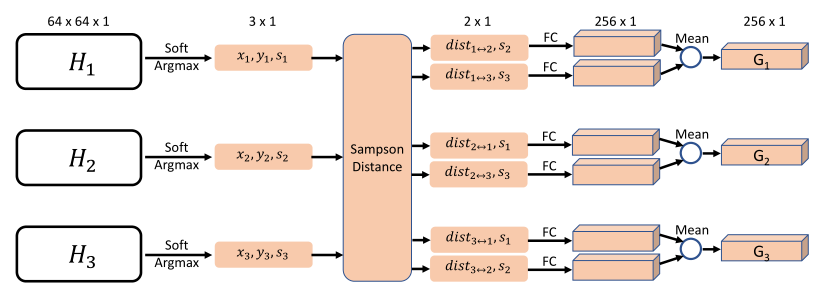
我们首先应用“soft-argmax”算子来获得每个视图中的关节位置(x, y)。我们还得到了该位置的热图响应值s,以反映其置信度。然后计算当前视图与其他视图之间的Sampson distance以衡量当前视图与其他视图之间的对应或一致性误差。小的
d
i
s
t
i
↔
j
dist _{i\leftrightarrow j}
disti↔j表示两幅画面的衔接位置一致。从直观上看,与大多数视图一致的位置更可靠。最后,我们提出使用一个FC层嵌入到特征向量的Sampson distance。然后对所有摄像机对的特征向量求平均,得到最终的The Geometry Embedding。
权重学习网络
我们提出了一个简单的由三个FC层组成的网络来转换连接的外观和几何嵌入来回归最终的权值。值得注意的是,我们并没有独立地训练权值学习网络。相反,我们将其与位姿估计网络相结合,以最小化融合的二维热图损耗,而无需对融合权值进行中间监督。图9中的第一列显示了我们的方法预测的一些权重示例。我们可以看到,当关节被遮挡,并且定位在不正确的位置时,对应的融合权值确实比其他关节小。
Datasets and Metrics
Datasets
Human3.6M数据集提供由四个摄像头捕获的同步图像。有七个受试者在进行日常活动。我们使用一个跨学科评估方案,其中受试者1、5、6、7、8用于训练,受试者9、11用于测试。我们还使用MPII数据集来增加训练数据,以避免对简单的背景过度拟合。由于MPII数据集只提供单眼图像,所以我们在多视图融合前只对骨干网进行训练。
CMU全景数据集: 这个最近推出的数据集提供了数十个相机捕捉的图像。我们统一选择了6个摄像机来评估摄像机数量对三维位姿估计的影响。其中,首先选取相机1、2、10构建三视图实验设置。然后将13,3,23相机依次添加到前面的3个相机上,分别构建4、5、6视图实验设置。我们遵循之前工的做法,选择只有一个人的训练和测试序列。由于很少有工作在这个数据集上报告数值结果,我们只将我们的方法与基线进行比较。
Occlusion-Person数据集: 之前的基准没有为图像中的关节提供遮挡标签,这使得我们无法对被遮挡的关节进行数值评估。此外,基准中的闭塞量是有限的。为了解决这些限制,我们提出构建这个合成数据集遮挡-人。我们采用UnrealCV (Qiu et al., 2017)渲染3D模型中的多视图图像和深度图。特别是,在客厅、卧室、办公室等9个不同的场景中,将13个穿着不同衣服的人体模特放在一起。人体模型由从CMU运动捕捉数据库中选择的姿势驱动。我们故意使用像沙发和桌子这样的物体来遮挡一些身体关节。在每个场景中放置8个摄像机来渲染多视图图像和深度图。8台摄像机分别以0.9米和2.3米的高度,在半径为2米的圆上以45度角平均放置。我们提供了15个关节的3D位置作为真实标签。图10显示了来自数据集的一些示例图像和相机的空间配置。

图像中每个关节的遮挡标签是通过将其深度值(可在深度图中获得)与摄像机坐标系中的3D关节的深度进行比较获得的。如果两个深度值的差值小于30cm,则关节未被堵塞。否则,它被遮挡。表1将此数据集与现有基准进行了比较。特别是,在我们的数据集中,大约20%的人体关节被遮挡。我们使用75%的数据集进行培训,25%的数据集进行验证。
Metrics
**2D Metrics:**引入的正确关键点百分比(Percentage of Correct Keypoints, PCK)度量通常用于二维姿态评估。PCKh@t测量的是那些比真实标签小于头部长度t倍的预估节点的百分比。根据之前的工作,我们在t为1/2时报告结果。由于所使用的三个基准中没有提供头部长度,对于所有基准,我们大约将其设置为人类包围框宽度的2.5%。

**3D Metrics:**三维姿态估计的精度是由平均每关节位置与真实标签之间的差距所评估的(MPJPE )
3D pose :
y
=
[
p
1
3
,
.
.
.
,
p
M
3
]
y=[p^3_1,...,p^3_M]
y=[p13,...,pM3]
estimated 3D pose:
y
ˉ
=
[
p
1
3
ˉ
,
.
.
.
,
p
M
3
ˉ
]
\bar{y}=[\bar{p^3_1},...,\bar{p^3_M}]
yˉ=[p13ˉ,...,pM3ˉ]
MPJPE =
1
M
∑
i
=
1
M
∣
∣
p
1
3
−
p
M
3
ˉ
∣
∣
2
\frac { 1 } { M} \sum _ { i = 1 } ^ { M } ||p^3_1-\bar{p^3_M}||_2
M1∑i=1M∣∣p13−pM3ˉ∣∣2
Experimental Results
我们将我们的方法与四个基线进行比较
- **NoFuse:**它在没有多视图融合的情况下,独立估计每个视图的2D姿态。
- **HeuristicFuse:**它根据Eq.(4)为每个视图分配一个固定的融合权重。通过交叉验证,将参数λ设置为0.5。
- **ScoreFuse:**使用与AdaFuse相同的公式,即式(5)进行特征融合。它与AdaFuse的区别仅仅在于我们计算ω的方式。特别地,ScoreFuse计算ω作为热图h的最大值
- **AdaFuse:**它使用预测的权重进行融合,如式(5)。
H
^
v
(
x
)
=
ω
v
H
v
(
x
)
+
∑
u
=
1
N
ω
v
max
x
′
∈
I
u
(
x
)
H
u
(
x
′
)
\hat { H } ^ { v } ( x ) = \omega ^ { v } H ^ { v } ( x ) + \sum _ { u = 1 } ^ { N } \omega ^ { v }\operatorname*{ max }_{{ x ^ { \prime } \in I ^ { u } ( x ) } }H ^ { u } ( x ^ { \prime } )
H^v(x)=ωvHv(x)+∑u=1Nωvmaxx′∈Iu(x)Hu(x′)
这四种方法都使用三角剖分从多视图2D位姿估计3D位姿。我们还比较了基线RANSAC,它不进行多视图融合,但使用RANSAC去除三角剖分中的离群值。
Results on Human3.6M
**二维姿态估计结果:**二维位姿估计结果如表2所示。所有的多视图融合方法都明显优于NoFuse。由于肘关节和手腕关节经常被人体遮挡,因此改善效果最为显著。结果表明,多视角融合是一种有效的遮挡处理策略。AdaFuse在所有融合方法中平均准确率最高,验证了学习适当的融合权值可以有效减少低质量视图特征带来的负面影响。
**三维姿态估计结果:**表3显示了基线和我们方法的三维位姿估计误差。我们可以看到NoFuse的平均误差为22.9mm。这是一个非常强的基线,其误差仅略大于最新的水平,在这个强基线之上,我们观察到添加多视图融合可以进一步减少3D姿态估计误差。
**启发式融合:**得到的误差小于NoFuse,这与表2中的2D结果一致。平均误差仅减少1.9mm,因为大多数示例相对容易,没有多少改进空间。然而,具有挑战性的关节,如手腕,得到了显著的改善。ScoreFuse得到的错误比HeuristicFuse小。这意味着为低质量的视图分配较小的权重,有助于提高熔融热图的质量。最后,我们采用AdaFuse方法,通过综合考虑外观线索和几何一致性来确定融合权值,将平均误差显著降低到19.5mm。考虑到基线已经非常强大,改进是显著的。我们注意到AdaFuse在少数关节如髋关节和头部的效果稍差。这主要是因为这些关节在数据集中很少被遮挡,所以2D位姿估计器可以获得非常精确的估计。进一步应用交叉视图融合会给热图带来小噪声,导致2D位姿估计精度稍差。但在实际应用中经常出现遮挡的情况下,交叉视图融合所带来的好处要远远大于小噪声带来的危害。
**RANSAC:**是解决稳健估计问题的实际标准。如表3所示,它通过在三角剖分中去除一些离群的2D姿势而优于NoFuse。然而,它不如多视图融合方法有效,因为后者除了去除异常姿态外,还试图细化。另一个原因是这个任务中的摄像机数量很少,这降低了找到真正的异常值的机会。此外,我们发现RANSAC对用来确定数据点是内层还是离群值的阈值非常敏感。在我们的实验中,我们通过交叉验证来设置阈值
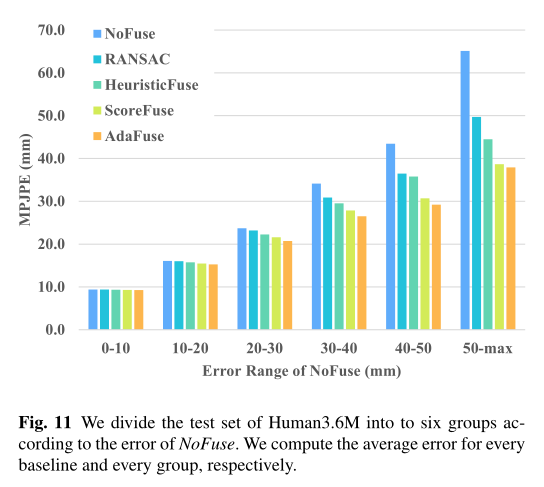
为了更好的理解AdaFuse带来的改进,我们将Human3.6M数据集的测试样本根据NoFuse的3D误差分为六组。然后我们计算每组的平均误差。图11显示了各种基线的结果。我们可以看到,当NoFuse的原始误差较大时,AdaFuse的改进最为显著。然而,即使NoFuse的姿态估计已经很精确,AdaFuse仍然可以略微减小误差。
消融对融合权重的研究
ScoreFuse失败的一个典型情况是当姿态估计网络在不准确的位置生成较大的分数时。在这种情况下,AdaFuse可以利用多视图的几何一致性来超越ScoreFuse。为了支持这个猜想,我们将两种方法分别预测的一些典型的热图和相应的融合权值可视化,如图12所示。我们发现四个视图的热图响应都很大,尽管第一和第三个视图的位置是不准确的。ScoreFuse为所有视图提供很大的权重,最终导致热图损坏。相反,AdaFuse发现,尽管第一和第三个视图的预测位置得分很高,但与其他两个视图的预测位置不一致。从而降低了重量,保证了熔接热图的质量。
、
此外,我们也仅使用两种嵌入网络中的一种对AdaFuse进行消融研究。当只使用 appearance embedding 和geometry embedding时,三维误差分别增大到20.3mm和19.9mm。请注意,在那些具有挑战性的例子中,改进实际上要大得多。结果表明,两种嵌入方式具有互补性。
与最新技术相比较
我们的方法比现有的技术都要好,Iskakov等人使用了两种方法,即三角测量和V容积测量,将2D姿势提升到3D。三角测量法比我们的方法更有可比性。我们的AdaFuse方法将他们的误差降低了约13%,考虑到尖端技术的误差已经非常小,这一改进是显著的。
Results on Panoptic
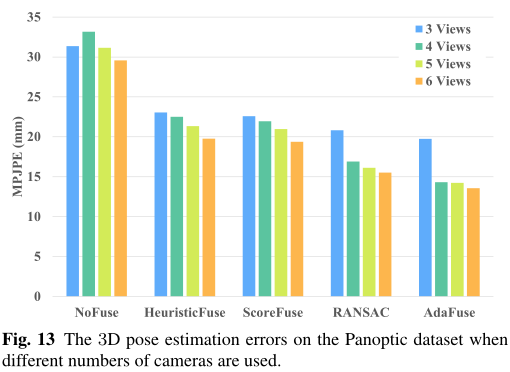
我们评估相机数量对该数据集的影响。图13分别显示了使用3到6个摄像机时的平均3D误差。一般来说,当更多的相机用于大多数基线时,误差减小。但是我们观察到,当摄像机数量从3个增加到4个时,NoFuse的误差实际上变大了。这种不希望出现的现象是因为新的摄像机视图非常具有挑战性,因此2D姿态估计结果是不准确的。然而,对于我们的AdaFuse方法,由于自适应多视图融合,低质量的热图在单个视图中的负面影响是有限的。我们可以看到AdaFuse的误差随着摄像机数量的增加而不断减小。由于没有一个普遍采用的评估协议,很少有工作报告了这个新数据集的结果,我们没有将我们的方法与其他方法进行比较。
Results on Occlusion-Person
2D Pose Estimation Results:
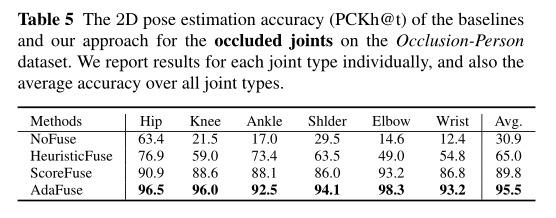
表5显示了遮挡节点的结果。NoFuse仅能准确检测30.9%的遮挡关节。由于遮挡节点的特征严重破坏,计算结果是合理的。三种多视图融合方法均显著提高了融合精度。特别是,AdaFuse能够正确检测90%以上的咬合关节。实验结果表明了该方法在学习融合权值方面的优势。
3D Pose Estimation Results :、
我们在表6中显示了每种关节类型的三维姿态估计误差(mm)。NoFuse的误差较大,为48.1mm。通过改进被遮挡关节的2D位姿估计结果,3D误差也显著降低,特别是对于四肢关节如踝关节和腕关节。特别是,我们的方法将3D误差显著降低到12.6mm。
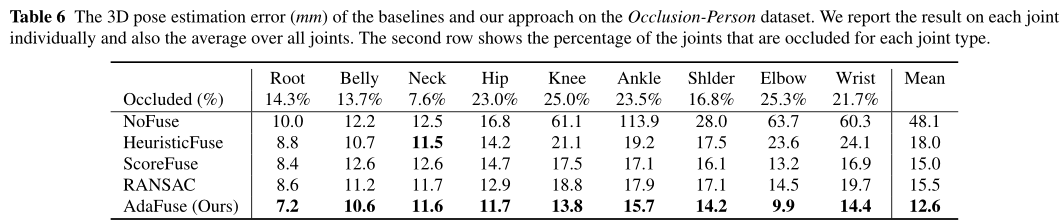
Impact of Number of Occluded Views:
我们还评估了被遮挡视图的数量对该数据集的影响。特别地,我们根据遮挡视图的数量将每个关节分为五组中的一组,并分别报告每组的平均关节误差。结果如表7所示。我们可以看到,当关节在所有视图中都可见时,简单的基线NoFuse也实现了13.0mm的非常小的误差。然而,当四个视图被遮挡时,误差会急剧增加到82.6mm。回想一下,这个数据集总共有8个视图。相比之下,多视图融合方法,特别是我们的AdaFuse,与NoFuse相比,始终获得更小的误差。更重要的是当更多的相机视图被遮挡时,误差增加比NoFuse慢得多,这验证了我们的方法遮挡的鲁棒性。

泛化能力
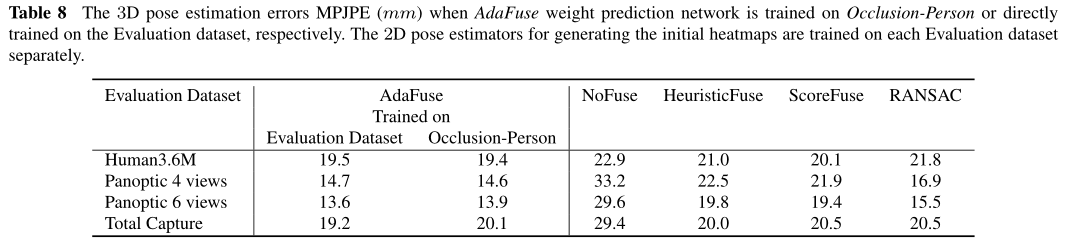
在我们的融合方法中,唯一可学习的参数是在appearance embedding和geometry embedding。在本节中,我们评估在Occlusion-Person上学习的AdaFuse权值预测网络是否可以直接应用于其他数据集。特别是,我们将在Occlusion-Person上学习到的AdaFuse权值预测网络附加到在每个数据集上训练的2D位姿估计器上,作为最终的评估模型。表8显示了不同数据集上的三维姿态估计结果。我们发现,在合成的咬合Occlusion-Person数据集上学习的融合网络在三个真实的数据集上获得了与在每个目标数据集上学习的网络相似的性能。结果表明,该融合模型具有较强的泛化能力。
同样值得注意的是,由于两个原因,我们的方法可以自然地处理不同数量的相机。
- 首先,对所有摄像机视图共享外观嵌入网络和几何嵌入网络中的参数
- 其次,几何嵌入网络中的“Mean”算子使其独立于图7和图8所示的视图数。总之,AdaFuse可以部署在不同相机姿势的新环境中,而不需要额外的自适应优化选择
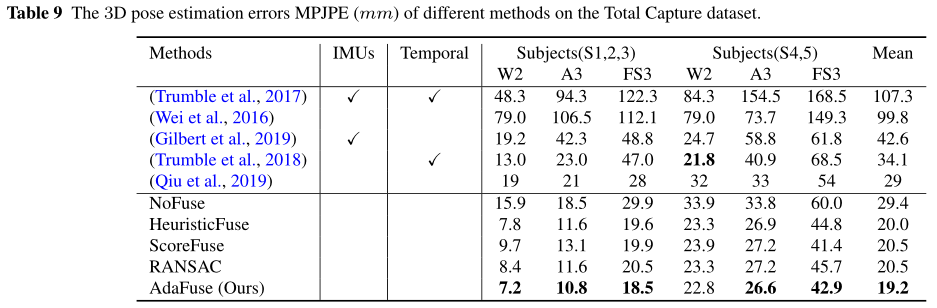
Results on Total Capture
我们在表9中报告Total Capture数据集上的3D姿态估计结果。值得注意的是,除了多视图图像之外,有些方法也使用imu。我们可以看到,我们的方法比之前所有的方法都要好。我们注意到,对于S4,5的“W2 (walking)”动作,我们的方法的误差略大于LSTM-AE 。我们倾向于认为,这是因为LSTM应用于周期性动作,如“walking”,可以获得显著的好处。这在另一项研究中也被独立观察到。我们在图14中展示了一些3D姿态估计的例子。在大多数情况下,我们的方法可以准确地估计3D姿态。该方法失败的一个典型情况是,当2D姿态估计结果不准确的许多相机视图。例如,在Panoptic数据集中,当人类开始进入穹顶时,他们可能会在多个视图中被遮挡。在这种情况下,每个视图中的热图都是低质量的。因此,熔融热图的质量也会下降,导致2D姿态估计不准确。

Summary and Future Work
我们提出了一种多视角融合方法来处理人体姿态估计中的遮挡问题。AdaFuse具有实用价值,因为它非常简单,可以灵活地应用到新的环境中,而不需要额外的适应。此外,它还可以与任何二维位姿估计网络相结合。我们在三个基准数据集上广泛地评估了该方法的有效性。该方法出色地超越了最先进的水平。我们还构建了一个大规模的有严重遮挡的人类数据集,以促进这一方向的更多研究。我们下一步的工作是利用时间信息来进一步提高姿态估计的精度。