文章目录
- 常见的Action算子
- 常见分区操作算子
常见的Action算子
- countByKey算子:统计Key出现的次数,部分代码如下:
rdd_file = sc.textFile("../Data/input/words.txt")
rdd_map = rdd_file.flatMap(lambda line: line.split(" ")).map(lambda x:(x, 1))
rdd_count = rdd_map.countByKey()
print(rdd_count)
print(type(rdd_count))
# 返回结果为字典
# defaultdict(<class 'int'>, {'Apple': 4, 'Banana': 5, 'Orange': 4, 'Peach': 2})
# <class 'collections.defaultdict'>
-
collect算子:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。RDD是分布式对象,数据量可以很大,所以用这个算子之前需要知道如果数据集结果很大,就会把driver内存撑爆,出现oom。
-
reduce算子:对RDD数据集按照传入的逻辑进行聚合操作,部分代码如下:
rdd = sc.parallelize(range(1,10))
rdd_reduce = rdd.reduce(lambda a,b : a+b)
print(rdd_reduce)
# 45
- fold算子:和reduce一样接收传入逻辑进行聚合,聚合是带有初始值的。这个初始值既要作用在分区内,也要作用在分区间,部分代码如下:
rdd = sc.parallelize(range(1,10),3)
rdd_reduce = rdd.fold(10,lambda a,b : a+b)
print(rdd_reduce)
# 1 分为[1,2,3] [4,5,6] [7,8,9]
# 2 每个分区+10
# 3 最后汇总再+10 得到结果85
- first算子:取出RDD第一个元素
sc.parallelize([1,2,3,4]).first()
# 1
- take算子:取出RDD的前N个元素
sc.parallelize([1,2,3,4],3).take(2)
# [1,2]
- top算子:对RDD元素进行降序排序,取前N个
sc.parallelize([1,2,3,4],3).top(2)
# [4, 3]
- count算子:计算RDD有多少条数据,返回值为一个数字
sc.parallelize([1,2,3,4],3).count()
# 4
- takeSample算子:随机抽样RDD的数据,部分代码如下:
rdd = sc.parallelize([1,2,3,4,5,6,7,6,5,4,3,2,1],1)
rdd_takeSample1 = rdd.takeSample(True, 18)
print(rdd_takeSample1)
rdd_takeSample2 = rdd.takeSample(False, 18)
print(rdd_takeSample2)
# [1, 1, 1, 4, 6, 4, 1, 1, 5, 4, 6, 7, 5, 1, 6, 6, 6, 2]
# [2, 4, 2, 5, 5, 6, 3, 7, 4, 1, 6, 3, 1]
# 参数一:bool型,True表示运行取同一个数据,False表示不允许取同一个数据,与数据内容无关,是否重复表示的是同一个位置的数据。
# 参数二:抽样的数目(设置为false则无法超越RDD总数)
# 参数三:随机种子(一般不需要传参)
- takeOrdered算子:对RDD排序取前N个,部分代码如下:
rdd = sc.parallelize([1,2,3,4,5,6,7])
#升序
rdd_takeOrdered1 = rdd.takeOrdered(4)
#降序
rdd_takeOrdered2 = rdd.takeOrdered(4,lambda x : -x)
print(rdd_takeOrdered1)
print(rdd_takeOrdered2)
# [1, 2, 3, 4]
# [7, 6, 5, 4]
- foreach算子:对RDD的每个元素,执行逻辑操作与map类似,但是这个方法没有返回值。如果想显示值,只能在里面自行打印(无需经过Driver,直接在Executor打印效率更高)。
rdd = sc.parallelize([1,2,3,4,5,6,7],1)
rdd1 = rdd.foreach(lambda x : 2*x +1)
rdd2 = rdd.foreach(lambda x : print(2*x +1))
print(rdd1)
3
5
7
9
11
13
15
None
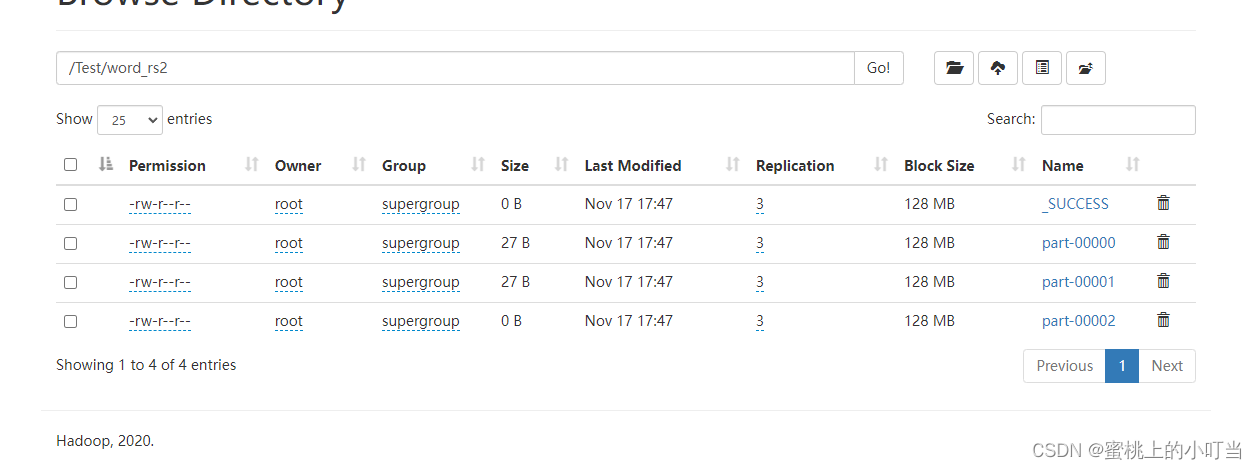
- saveAsTextFile算子:保存文件API,分布式执行,不经过Driver,每个分区所在的Executor直接控制数据写出到目标文件系统中,每个分区产生1个结果文件。
#设置为三个分区
rdd_file = sc.textFile("hdfs://node1:8020/Test/WordCount.txt",3)
rdd_words = rdd_file.flatMap(lambda line: line.split(" "))
rdd_map = rdd_words.map(lambda x:(x, 1))
rdd_total = rdd_map.reduceByKey(lambda a,b: a + b)
rdd_rs = rdd_total.saveAsTextFile("hdfs://node1:8020/Test/word_rs1")
结果如下图所示在HDFS WebUI上查看
常见分区操作算子
- mapPartitions算子:与map相似,只是一次被传递的是一整个分区的数据,虽然在执行次数上与map相同,但是可以因为减少了网络io的传输次数,效率会大大的提高。部分代码如下:
rdd = sc.parallelize([1,2,3,4,5,6],3)
def func(iter):
rs = list()
for it in iter:
rs.append(2 * it + 1)
return rs
rdd_part = rdd.mapPartitions(func)
rdd_rs = rdd_part.collect()
print(rdd_rs)
# [3, 5, 7, 9, 11, 13]
- foreachPartition算子:与普通foreach一样,只是一次被传递的是一整个分区的数据,部分代码如下:
rdd = sc.parallelize([1,2,3,4,5,6],3)
# 因为没有返回值所以不需要return
def func(iter):
rs = list()
for it in iter:
rs.append(2 * it + 1)
print(rs)
rdd_part = rdd.foreachPartition(func)
# [3, 5]
# [7, 9]
# [11, 13]
- partitionBy算子:对RDD进行自定义分区操作,部分代码如下
# 参数1 重新分区后有几个分区
# 参数2 自定义分区规则,函数传入(返回编号为int类型,分区编号从0开始,不要超过分区数)
rdd = sc.parallelize([('a',1),('b',2),('c',3),('d',4),('e',5),('f',6)])
def func(key):
if key == 'a' or key == 'b' : return 0
if key == 'c' or key == 'd' : return 1
return 2
rdd_part = rdd.partitionBy(3,func)
rdd_rs = rdd_part.glom().collect()
print(rdd_rs)
# [[('a', 1), ('b', 2)], [('c', 3), ('d', 4)], [('e', 5), ('f', 6)]]
- repartition算子:对RDD的分区执行重新分区。不建议使用此算子,除非做全局排序的时候,将其设置为1。如果修改尽量减少,不要增加,增加会导致shuffle。不管是增加还是减少都会影响并行计算(内存迭代并行的管道数量),部分代码如下:
rdd = sc.parallelize([1,2,3,4,5,6],3)
rdd_re1 = rdd.getNumPartitions()
print(rdd_re1)
rdd_re2 = rdd.repartition(1).getNumPartitions()
print(rdd_re2)
rdd_re3 = rdd.repartition(5).getNumPartitions()
print(rdd_re3)
# 3
# 1
# 5
- coalesce算子:对分区数量进行增减,部分代码如下:
# 参数1:分区数
# 参数2:Bool True表示允许shuffle,False表示不允许(默认)。
rdd_re4 = rdd.coalesce(1).getNumPartitions()
print(rdd_re4)
rdd_re5 = rdd.coalesce(5).getNumPartitions()
print(rdd_re5)
rdd_re6 = rdd.coalesce(5,shuffle=True).getNumPartitions()
print(rdd_re6)
# 1
# 3 没有加shuffle=True这里有个API安全机制,分区不会增加
# 5
- 在源码中我们可以发现reparation算子底层调用的就是coalesce算子,只不过shuffle定义为true。源码如下:
def repartition(self, numPartitions):
return self.coalesce(numPartitions, shuffle=True)