Xshell远程连接进行Ubuntu的Pytorch配置
- 写在最前面
- 参考
- Xshell常用命令
- Ubantu
- 检查系统的各项配置
- 查看ubuntu系统的版本信息
- 查看Linux的内核版本和系统是多少位的
- Ubuntu版本
- 各种验证
- 禁用nouveau
- 安装显卡驱动
- 卸载显卡驱动
- 安装显卡驱动
- 加入PPA,然后更新库
- 方法一:直接装系统推荐显卡驱动,出错几率小(但需要注意:cuda11.3要求465以上!!!)
- 方法二:人工查看并选择适合本机的nvidia驱动
- 查看安装状态
- 错误处理
- 1
- 2
- 第一次尝试时,它报错了
- 先尝试重启
- (不是这个原因)内核版本更新的问题,导致新版本内核和原来显卡驱动不匹配
- CUDA
- 选择
- 下载+安装
- 报错:wget提示无法建立ssl连接
- 参考1:开启SSH服务
- 参考2:在网址后面加上--no-check-certificate
- 参考三:把https修改为http地址
- 新的报错
- 下载axel + 将com改为cn
- 执行结束
- 报错:Installation failed. See log at /var/log/cuda-installer.log for details.
- 成功了!!!!
- 安装vim
- 配置环境
- 测试CUDA
- 报错unknown error Result = FAIL
- CUDNN
- 下载+安装
- 方法1:下载deb文件(tgz易错,但deb卸载麻烦)
- 方法2 下载zip
- 查看一下cudnn版本
- 方法1
- 方法2
- 测试样例(如果是deb安装,并且才下载了测试案例才可以)
- 如果报错
- Anaconda
- 下载+安装
- 环境配置
- 添加清华源
- Pytorch
- conda虚拟环境
- 安装
- 最新版GPU版本的:
- CPU-Only版本的:
- 测试
- cpu only测试
- gpu测试
- 报错
- gpu下载成cpu
- 重新安装gpu版本
- CUDA 11.3
- 删除下载源
- 本机安装whl报错
写在最前面
是我,那个会遇到各种报错的小雨
为了少遇到一些报错,这次看了八篇帖子,并且尽量将命令都理解了,结果还是遇到各种没看到过的报错。。。。感谢互联网的各位大佬,各种犄角格拉的错误都能被百度到(抱拳
因此这篇文章是两万字保姆级的安装配置(可以先根据需要结合目录跳着看,我回头整理一份一遍过教程)
亲测有效,有图有真相:
pytorch1.12_gpu
pytorch11.3_cpu

参考
https://blog.csdn.net/TU_Dresden/article/details/121049141
https://blog.csdn.net/weixin_43491255/article/details/118549032
https://blog.csdn.net/a563562675/article/details/119458550
https://blog.csdn.net/a563562675/article/details/119458550
https://blog.csdn.net/qq_44315987/article/details/106314054
(下面这个链接内含各种报错)
https://blog.csdn.net/Williamcsj/article/details/123523087
https://blog.csdn.net/A496608119/article/details/123455529
https://blog.csdn.net/qq_51570094/article/details/124148671
Xshell常用命令
Ctrl + Shift 复制
Insert + Shift 粘贴
Ubantu
Ctrl+Alt+T打开终端
检查系统的各项配置
查看ubuntu系统的版本信息
cat /proc/version
Linux version 5.4.0-131-generic (buildd@lcy02-amd64-092) linux内核版本号
gcc version 7.5.0 gcc编译器版本号
Ubuntu 7.5.0-3ubuntu1~18.04 Ubuntu版本号

查看Linux的内核版本和系统是多少位的
查看已安装内核
dpkg --get-selections |grep linux-image
查看正在使用的内核
uname -a

显示正在使用的内核为5.4.0-131-generic。
X86_64代表系统是64位的。
Ubuntu版本
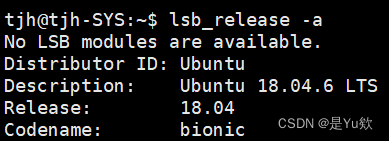
lsb_release -a
Distributor ID: Ubuntu //类别是ubuntu Description: Ubuntu 18.04.6 LTS //18年4月6月发布的稳定版本,LTS是Long Term Support:长时间支持版本 三年 ,一般是18个月
Release: 18.04 //发行日期或者是发行版本号 Codename: bionic //ubuntu的代号名称
各种验证
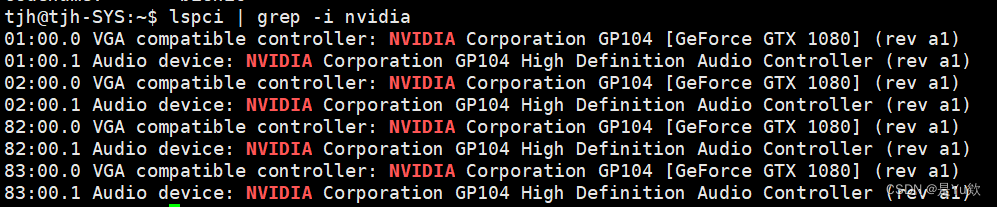
验证机器是否具有n卡
lspci | grep -i nvidia
gcc验证
gcc --version
7.5.0

验证内核
sudo apt-get install linux-headers-$(uname -r)
查看原有的显卡版本和CUDA支持
nvidia-smi

禁用nouveau
sudo gedit /etc/modprobe.d/blacklist.conf
vim
打开上述文档添加这两行保存
blacklist nouveau
options nouveau modeset=0
刷新
sudo update-initramfs -u
重启电脑,一定要重启。
sudo reboot
然后输入这个命令
lsmod | grep nouveau
如果啥也没输出,就是成功关闭了。
cd /lib/firmware/rtl_nic/
sudo wget https://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git/tree/rtl_nic/rtl8125a-3.fw
安装显卡驱动
卸载显卡驱动
sudo apt-get remove --purge nvidia*
sudo apt autoremove
安装显卡驱动
加入PPA,然后更新库
sudo apt-get update
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
方法一:直接装系统推荐显卡驱动,出错几率小(但需要注意:cuda11.3要求465以上!!!)
会自动安装推荐的版本(一般是最高的版本)
sudo ubuntu-drivers autoinstall
报警告且不动时,再等一会就开始自己安装了
警告类似于:
WARNING:root:_pkg_get_support nvidia-driver-510-server: package has invalid Support n model
最后的界面显示
方法二:人工查看并选择适合本机的nvidia驱动
查看适合本机的nvidia驱动
ubuntu-drivers devices
有的小伙伴到这里会发现推荐的驱动基本都是no-free
那么进行下面命令,如果有 那就跳过
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
更新完后就重新 ubuntu-drivers devices
就会有推荐的免费版本了
选择合适自己的版本,具体情况看你的推荐
根据下列结果,这里 nvidia-driver-465 为推荐驱动安装版本(注意cuda11.3要求465以上!!!)
sudo apt-get install nvidia-driver-440 nvidia-settings nvidia-prime
查看安装状态
查看状态后需要重启!!!要不然会报错
sudo reboot
使用nvidia-smi 查看是否已经读取到安装的驱动,如果提示没有找到命令重启后再试
nvidia-smi
会出现显卡版本和CUDA支持
例子:
| NVIDIA-SMI 430.26 Driver Version: 430.26 CUDA Version: 10.2 |
这个表示:显卡P106-100,显存6G,驱动430.26,CUDA10.2

错误处理
1
如果出现NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running. 需要手动关闭BIOS的安全模式。
2
如果安装 nvidia-driver-410 或以上版本提示 packages 无法安装,请执行以下步骤:
移除已添加的 PPA
sudo apt-add-repository -r ppa:graphics-drivers/ppa
更新 apt
sudo apt update
移除 NVIDIA 显卡驱动文件
sudo apt remove nvidia*
执行自动清理
sudo apt autoremove
然后重新回到本文初步骤重新安装
第一次尝试时,它报错了
however,它报错了
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the lat
先尝试重启
sudo reboot
然后服务器挂了。。。连接不上了
属于服务器重启后,无法被远程连接
参考:https://blog.csdn.net/GX_1_11_real/article/details/80925900
排查:
【1】确定是否是本地的问题,即执行远程的主机的问题
连接同一vpn下,另一台服务器
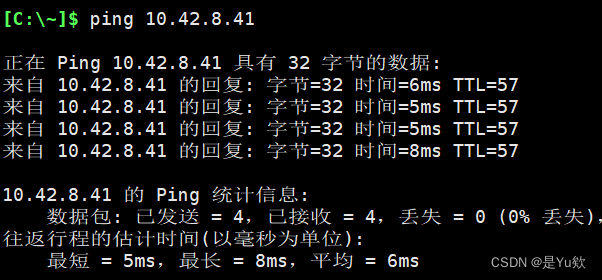
所以不是本机电脑配置的问题
【2】确认是否重启服务器的问题
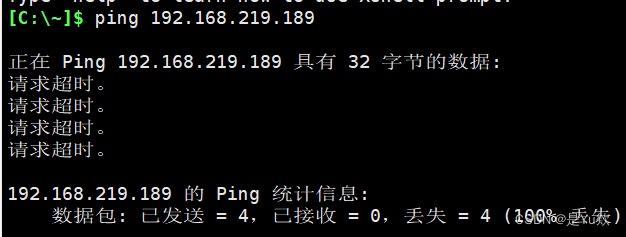
好吧,那台服务器可能有问题。
服务器重新挂起后就能连接了,然后驱动也有了,果然是没重启的原因。。。。
(不是这个原因)内核版本更新的问题,导致新版本内核和原来显卡驱动不匹配
https://blog.csdn.net/xiaojinger_123/article/details/121161446
之前看过,正在使用的内核为5.4.0-131-generic。
在上面命令行中找到对应的版本,安装nvidia驱动时记下了当时的内核版本为5.4.0-131-generic。
所以应该不是这个问题
CUDA
选择
下载前仔细看这张图
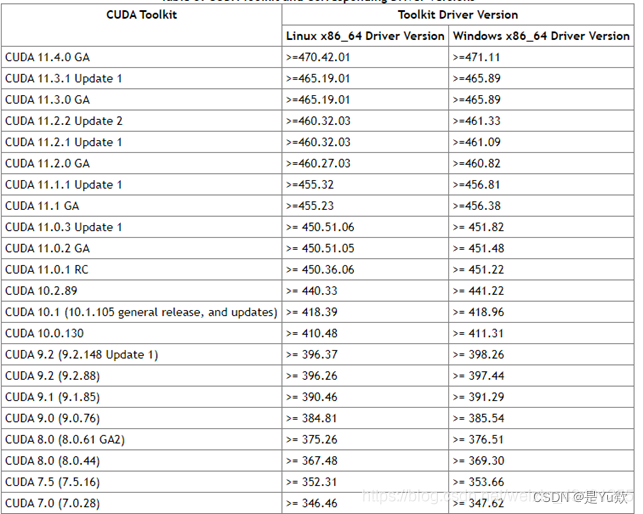
Table 1. CUDA Toolkit and Compatible Driver Versions
CUDA Toolkit Linux x86_64 Driver Version Windows x86_64 Driver Version
CUDA 10.2.89 >= 440.33 >= 441.22
CUDA 10.1 (10.1.105 general release, and updates) >= 418.39 >= 418.96
CUDA 10.0.130 >= 410.48 >= 411.31
CUDA 9.2 (9.2.148 Update 1) >= 396.37 >= 398.26
CUDA 9.2 (9.2.88) >= 396.26 >= 397.44
CUDA 9.1 (9.1.85) >= 390.46 >= 391.29
CUDA 9.0 (9.0.76) >= 384.81 >= 385.54
CUDA 8.0 (8.0.61 GA2) >= 375.26 >= 376.51
CUDA 8.0 (8.0.44) >= 367.48 >= 369.30
CUDA 7.5 (7.5.16) >= 352.31 >= 353.66
CUDA 7.0 (7.0.28) >= 346.46 >= 347.62
上图给出了不同版本所要求的的最低驱动要求,尽量选择相同的进行安装。
编译cuda samples会报错,例如 chrono模块、gcc版本过高等提示。
与之前的gcc版本进行比对
gcc --version
cuda的gcc依赖版本在官方文档的安装指南上会给出
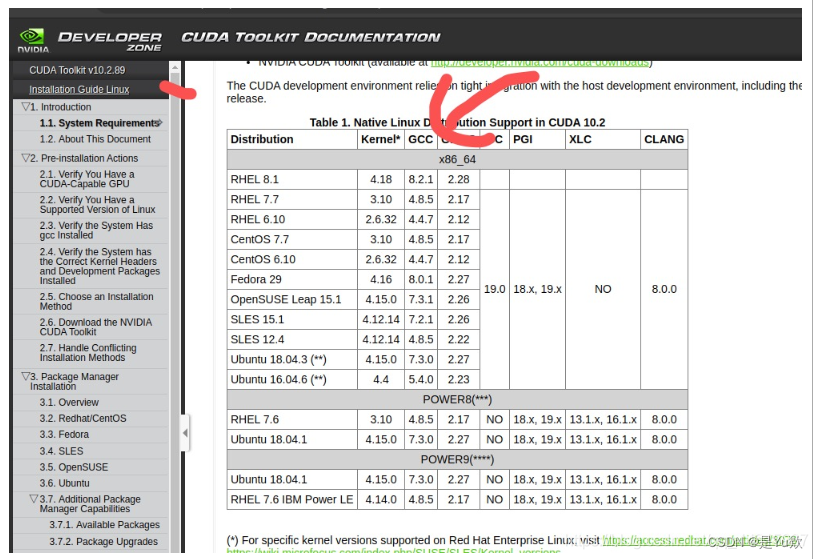
我是Ubuntu18.04.6,gcc7.5.0
第一步,如果版本和cuda依赖gcc不对应,就安装cuda需要的版本
sudo apt-get install gcc-7.0
sudo apt-get install g++-7.0
第二步,配置gcc版本的优先级。默认使用的gcc版本为优先级最高的。设置gcc 10优先级为100,设置gcc 7优先级为70。那么默认使用gcc10。
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 100
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 100
第三步,切换需要的gcc版本,命令为sudo update-alternatives --config gcc,默认是0选项。输入需要的gcc版本序号后,即可成功切换。
sudo update-alternatives --config gcc
选择 路径 优先级 状态
------------------------------------------------------------
* 0 /usr/bin/gcc-9 50 自动模式
1 /usr/bin/g++-9 50 手动模式
2 /usr/bin/gcc-7 50 手动模式
输入前面显示的编号即可
下载+安装
进入官网
https://developer.nvidia.com/cuda-toolkit-archive
普通机器:x86_64 服务器 power architecture
选择需要的CUDA安装包(runfile格式)
可以创建一个文件夹保存下载的文件,然后在终端切换到那个目录下,进行相应的命令行 (如下图末尾箭头所指)
一定要注意版本!!!
网上推荐CUDA 11.3.0 + CUDNN 8.2.1 + Pytorch 1.10
这三者的组合非常麻烦,这套那位博主亲测成功,别的搭配不敢保证。
例子:
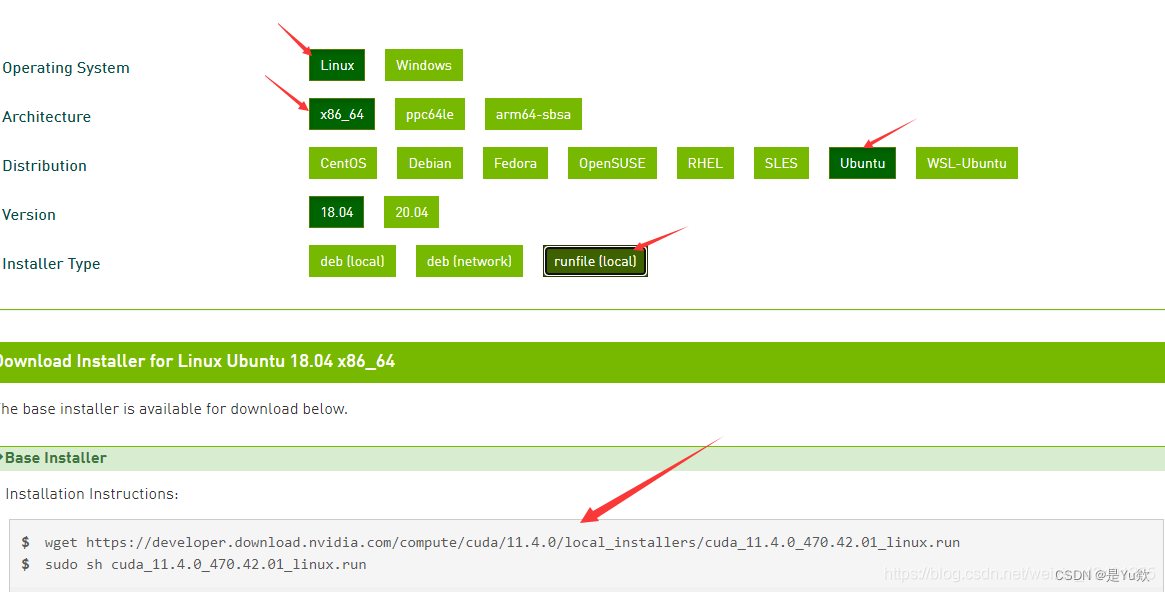
实际:
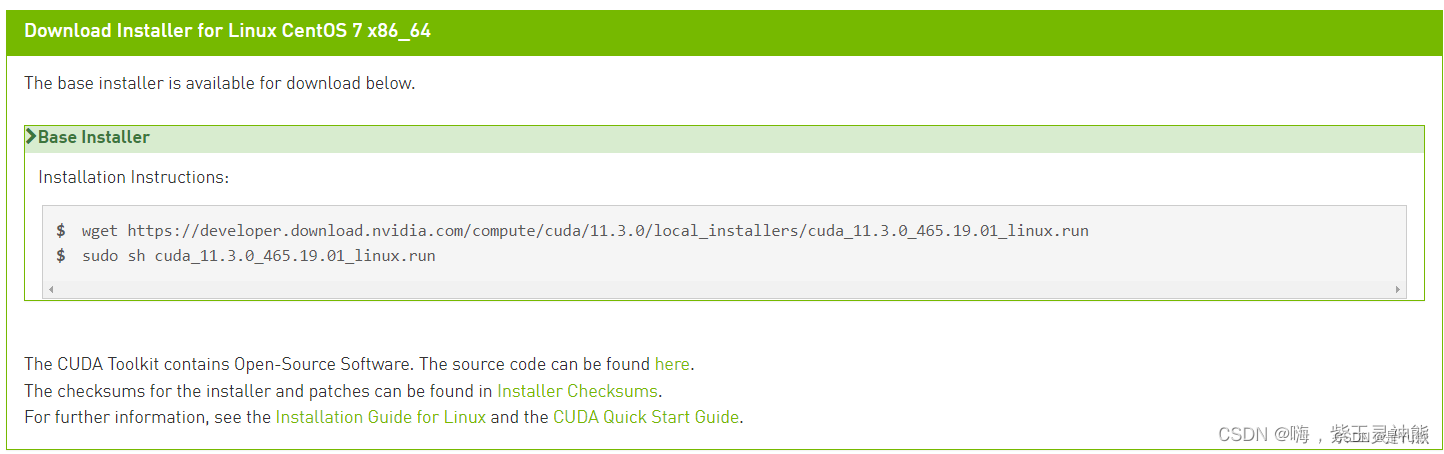
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
然后报错了、无语这都能报错。。。。
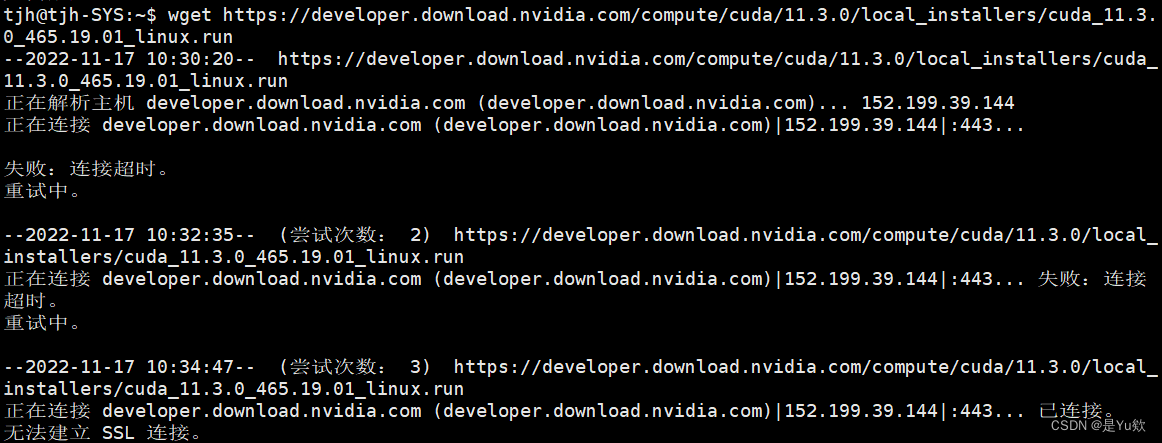
报错:wget提示无法建立ssl连接
参考1:开启SSH服务
https://blog.csdn.net/qq_42130526/article/details/119972366
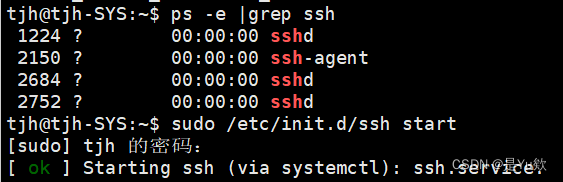
检查是否开启SSH服务
因为Ubuntu默认是不安装SSH服务的,所以在安装之前可以查看目前系统是否安装,通过以下命令:
ps -e |grep ssh
输出的结果ssh-agent表示ssh-client启动,sshd表示ssh-server启动。我们是需要安装服务端所以应该看是否有sshd,如果没有则说明没有安装。
启动SSH服务
sudo /etc/init.d/ssh start
参考2:在网址后面加上–no-check-certificate
https://blog.csdn.net/qq_38883271/article/details/116278157
在网址后面加上–no-check-certificate,例如:
wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run --no-check-certificate
原因:wget在使用https协议时会验证网站证书,而证书会经常失效,加上–no-check-certificate忽略验证证书的步骤。
参考三:把https修改为http地址
参考:
https://blog.csdn.net/qq_28887735/article/details/81842592
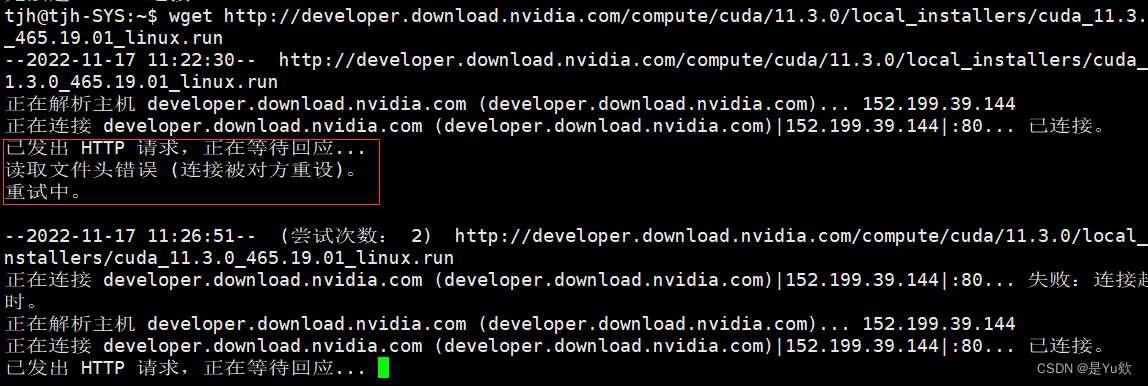
wget http://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run --no-check-certificate
新的报错
已发出 HTTP 请求,正在等待回应…
读取文件头错误 (连接被对方重设)。
重试中。
下载axel + 将com改为cn
Tensorflow官网下载东西也是无法直接访问的,但是可以通过镜像访问。微软的官网直接访问速度很慢,可是把网站的后缀.com改成.cn后速度就很快了。
访问确实快了,但是下载的连接改为cn后是404页面,需要进一步操作
参考:https://blog.csdn.net/yxt916/article/details/109402650
1.下载axel(wget的哥哥):
终端输入:
sudo apt install -y axel
2.看图,复制底下的下载链接:(以下是cuda11.3.0的下载链接,做个示范,你需要复制对应自己的)
http://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
3.把.com改成.cn,使用axel下载cuda11.1:
终端输入:
axel -n 50 http://developer.download.nvidia.cn/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
(注意这里网址里的.com已经改成了.cn)(具体参数 -n 50作用:狡兔50窟)
效果:不断线,不降速,已经是成了
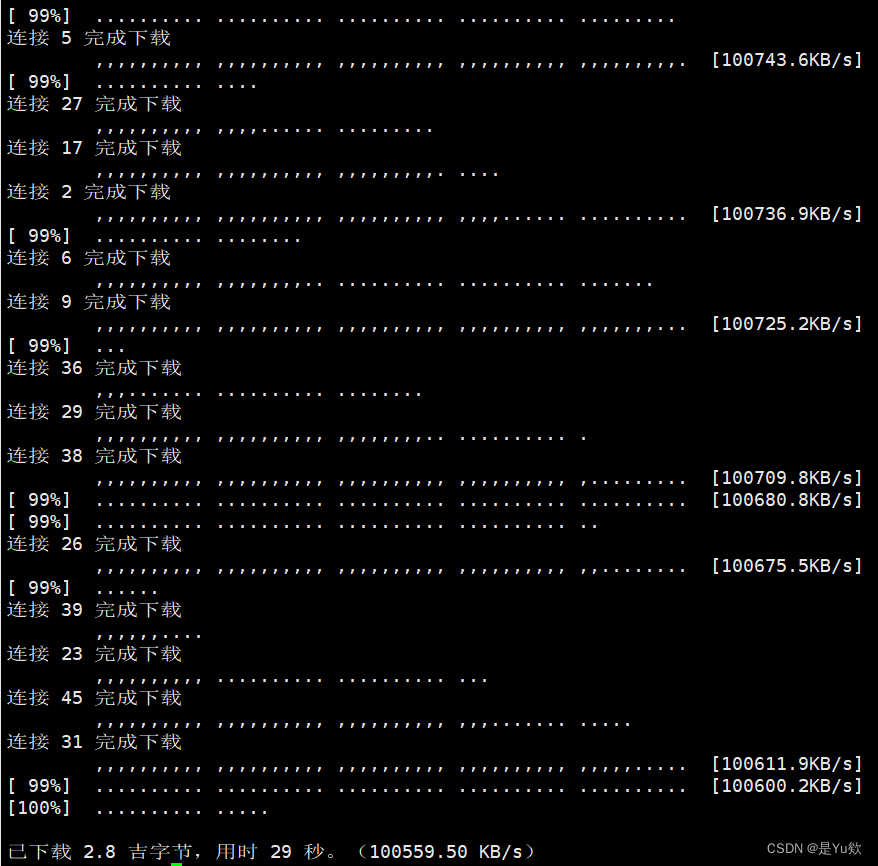
执行结束
sudo sh cuda_11.3.0_465.19.01_linux.run
上述命令执行结束出现一个框
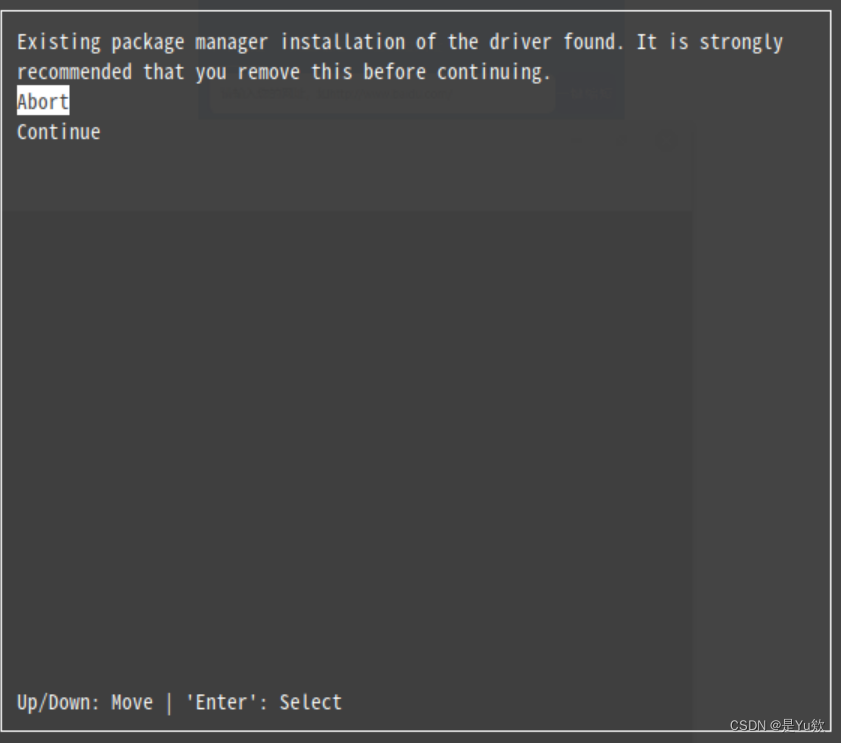
通过方向键下移光标,选择continue
打字输入accept
然后就是下面这个了
由于已经安装了驱动 按方向键,使得光标在driver上,再按回车,之后通过方向键使光标移动到install
此时下图里需要将第一行的Driver CUDA 11.0去掉。(注意:回车键作用是将 [X] 就会变成[ ],[X]代表有,[ ]代表无)
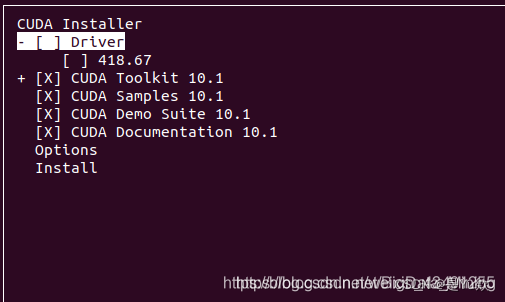
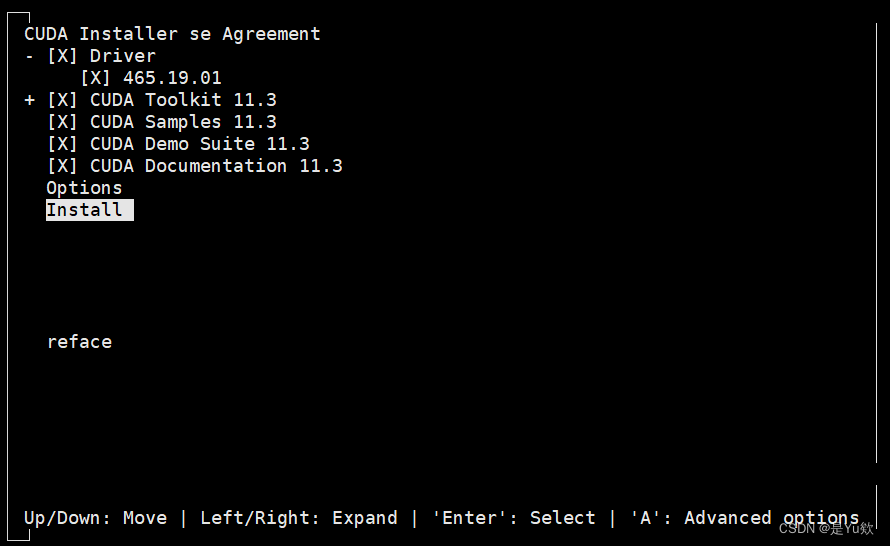
报错:Installation failed. See log at /var/log/cuda-installer.log for details.

因为应该将[X] 就会变成[ ],弄反了
成功了!!!!
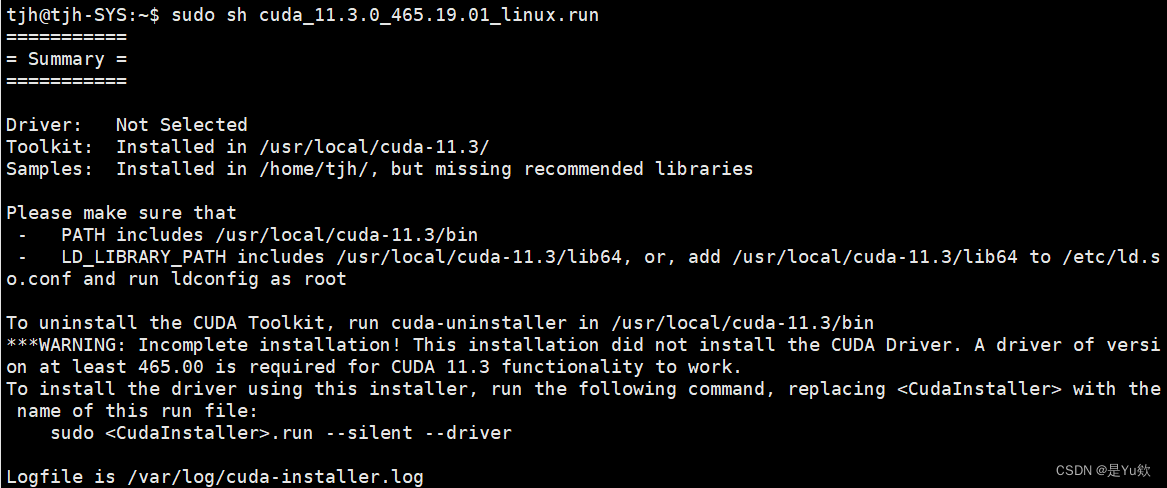
安装vim
sudo apt-get install vim
配置环境
装好之后打开环境变量
vim ~/.bashrc
i键进入编辑模式,esc退出,写:wq保存退出
加入这两行保存,注意我这里是11.3,你如果是别的版本,要改成自己的
export PATH="/usr/local/cuda-11.3/bin:$PATH"
export LD_LIBRARY_PATH="/usr/lcoal/cuda-11.3/lib64:$LD_LIBRARY_PATH"
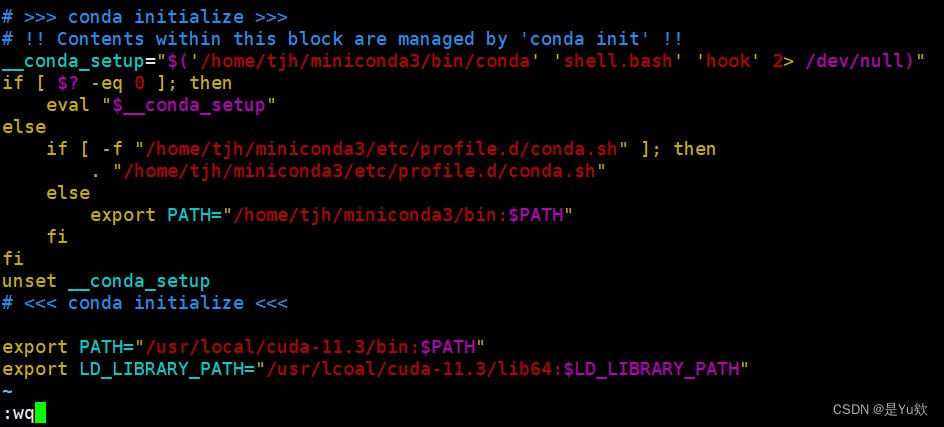
刷新环境变量生效
source ~/.bashrc
测试CUDA
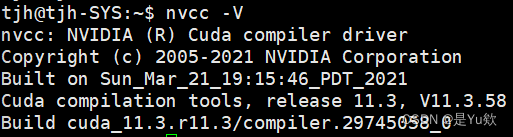
查看版本
nvcc -V
啊啊啊啊啊啊我成功了
终端输入
cd /usr/local/cuda-11.3/samples/1_Utilities/deviceQuery
sudo make
sudo ./deviceQuery
输出Result=pass代表成功了,里面显示了CUDA可用的设备信息。
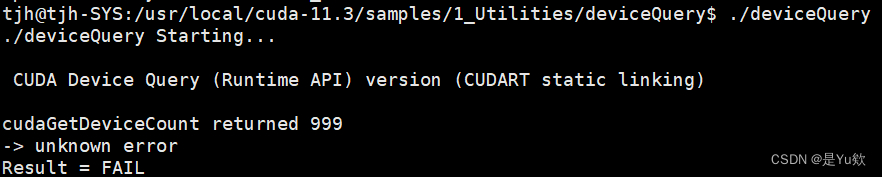
报错unknown error Result = FAIL
./deviceQuery
./deviceQuery Starting…
CUDA Device Query (Runtime API) version (CUDART static linking)
cudaGetDeviceCount returned 999
-> unknown error Result = FAIL
尝试
sudo ./deviceQuery
就PASS了,好神奇
那么没有输出成功的小伙伴。首先确认你的cuda版本是否跟驱动对应,如果没有问题。那么输入 reboot 进行重启。问题大概率能解决。然后在按照上述命令行执行,就能输出pass了。
CUDNN
进入网址下载,要把cudnn版本与cuda版本对应正确
https://developer.nvidia.com/rdp/cudnn-archive
上述网址需要注册登录,按照要求完成即可
本机翻墙下载,然后Xftp传过去

查看传过去后的文件名
ls

下载+安装
方法1:下载deb文件(tgz易错,但deb卸载麻烦)
先下载三个deb包,一定要用deb,出错几率小
官网:https://developer.nvidia.com/rdp/cudnn-archive
我的是11.3,选择里面的8.2.1 for 11.x

进入到下载文件所在目录,安装这三个包
谢谢,这里都能遇到问题
Oops, sorry for the inconvenience It seems that the file you have tried to download is no longer available or the URL used is no longer valid. Please refer back to the product page and follow the links to get the latest downloadable version.
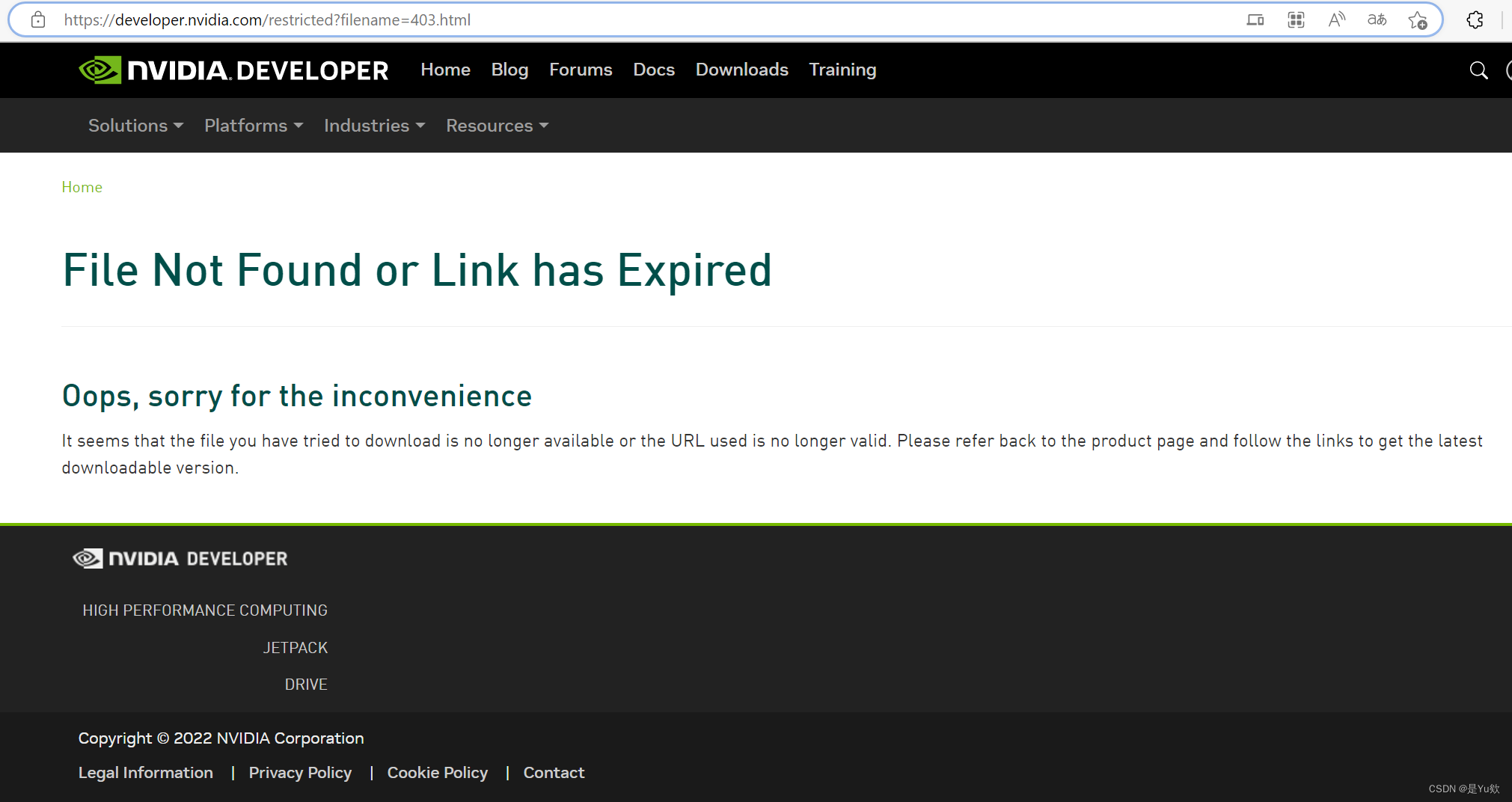
可以到阿里镜像下载包
https://mirrors.aliyun.com/nvidia-cuda/ubuntu1804/x86_64/
注意要下载2个包

然后按照顺序依次安装,这样才不会报错。
sudo dpkg -i xxxxxxx.deb
注意修改指令中的对应的版本信息。
第一步:安装runtime library
sudo dpkg -i libcudnn8_8.2.1.32-1+cuda11.3_amd64.deb
第二步:安装developer library
sudo dpkg -i libcudnn8-dev_8.2.1.32-1+cuda11.3_amd64.deb
(可选,和后面测试有关)
第三步:安装code samples and the cuDNN Library User Guide
sudo dpkg -i libcudnn8-samples_8.2.1.32-1+cuda11.3_amd64.deb
方法2 下载zip
进入下载后的文件夹解压后,就可以看见cuda文件夹(浏览器下在的文件一般在Downloads中,解压后子目录就能看见cuda)在解压后的文件夹中输入一下命令
参考:https://blog.csdn.net/avideointerfaces/article/details/104793245
重命名,然后再解压缩。命令如下所示。
mv cudnn-11.3-linux-x64-v8.2.1.32.tgz cudnn-11.3.tgz
tar -xvzf cudnn-11.3.tgz
因为下载的是库,不是源代码,所以不需要编译了。只需要将解压缩出来的so库和头文件拷贝到系统目录下即可。

将cudnn解压后的include和lib64文件夹复制到cuda中
cuda-11.3 此处是自己版本号 。
一行行复制,因为要输密码
sudo cp cuda/include/cudnn.h /usr/local/cuda-11.3/include/ #解压后的文件夹名字为cuda-11.3
sudo cp cuda/include/cudnn_version.h /usr/local/cuda-11.3/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-11.3/lib64/
sudo chmod a+r /usr/local/cuda-11.3/include/cudnn.h

最后安装一下依赖
sudo apt-get install libfreeimage3 libfreeimage-dev
查看一下cudnn版本
方法1
使用find命令找到对应的文件就可以了
sudo find / -name cudnn_version.h 2>&1 | grep -v "Permission denied"
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

出现出现cudnn版本就是安装成功了。
如果命令不可用,尝试方法二。
方法2
之前网上提供的方式cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2已经不能用了,因为cudnn.h文件里内容修改了,不再存放版本信息。
使用命令
cat /usr/local/cuda/include/cudnn.h | grep cudnn
查看,发现里面导入了cudnn_version.h文件,版本信息就存放在这个文件里
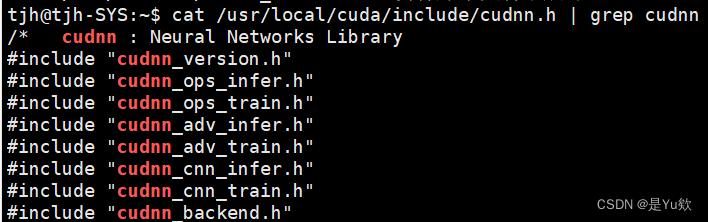
测试样例(如果是deb安装,并且才下载了测试案例才可以)
刚才有个包是cudnn自带的样例sample,运行测试一下
/usr/src/cudnn_samples_v7 中的mnistCUDNN sample
开始运行sample
cd NVIDIA_CUDA-11.3_Samples
cp -r /NVIDIA_CUDA-11.3_Samples/ $HOME
cd $HOME/cudnn_samples_v8/mnistCUDNN
make clean && make
./mnistCUDNN
如果出现 Test passed,说明安装成功
如果报错
如果编译时出现fatal error: FreeImage.h: No such file or directory错误,参考https://blog.csdn.net/xhw205/article/details/116297555
Anaconda
下载+安装
方法1:Anaconda3官网下载
方法2:清华大学开源软件镜像站下载
https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
里面有新旧版本,我下载的是Anaconda3-2021.05-Linux-x86_64.sh版本,如果大家需要其它版本,把这个后缀换成你想下的版本即可;
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.05-Linux-x86_64.sh
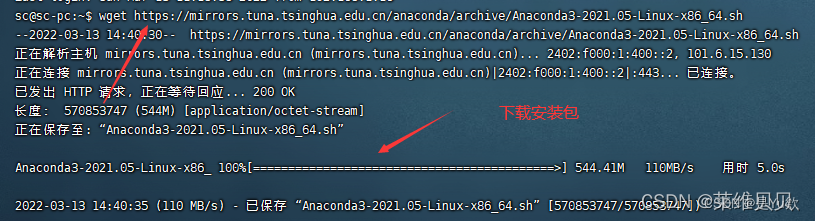

1、运行.sh文件
bash Anaconda3-2021.05-Linux-x86_64.sh
2.进入安装,输入yes
3.进入阅读注册手册,按 Enter 键
4.注册手册阅读完, 输入yes进行安装,然后会安装成功
环境配置
5.安装成功后,用vim打开环境变量:
sudo vim ~/.bashrc
添加下列语句,保存并退出
注意: “/home/sc/anaconda3/bin:$PATH” 的 sc是自己的用户名称,每个人都不一样,不知道可以看上面的打开的环境变量有个样本
export PATH="/home/sc/anaconda3/bin:$PATH"
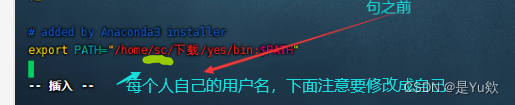

更新环境变量
在终端输入:
source ~/.bashrc
添加清华源
将anaconda换一下源(加入清华源)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes

为了保证用的是镜像站提供的索引,清除索引缓存,输入:
conda clean -i
此时,Anaconda3的基础设置弄完了
Pytorch
conda虚拟环境
创建一个虚拟环境,用来安装pytorch
conda create -n pytorch1.12_gpu
or,可以选择Python版本
conda create -n pytorch1.12_gpu python==3.8
这样就创建了一个名字为pytorch1.12_gpu,基于python版本3.8的一个虚拟环境了
激活环境
conda activate pytorch1.12_gpu
或
source activate pytorch1.12_gpu
安装一波依赖,顺便测试一下刚才的源,如果速度很快,那么就很棒棒,一会的Pytorch也会很顺利
conda install numpy mkl cffi
安装
进入官网,查看你的版本对应的安装命令
https://pytorch.org/get-started/locally/

在安装之前先添加下面这个源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
在刚才的虚拟环境里输入命令安装pytorch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
最新版GPU版本的:
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
(与上面一个,跑其中一个就可以了。示例:)
20.04 + pytorch 1.9.0 + cuda 11.3 的指令:
conda install pytorch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0 cudatoolkit=11.3 -c pytorch -c conda-forge
CPU-Only版本的:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
大家根据自己的情况从上面选一个
安装文件非常大,耐心等待即可,如果源切换成功了,这里下载会很快。
测试
进入虚拟环境,输入命令测试,大功告成!
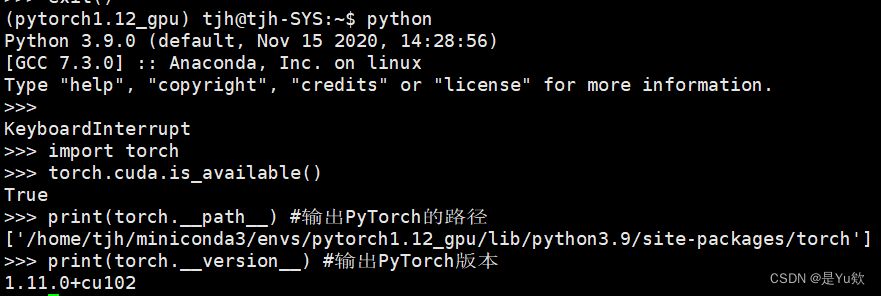
python3
import torch
torch.cuda.is_available()
print(torch.__version__) #输出PyTorch版本
print(torch.__path__) #输出PyTorch的路径
退出虚拟环境的命令:
conda deactivate
conda env list
cpu only测试
环境名称为pytorch11.3_cpu
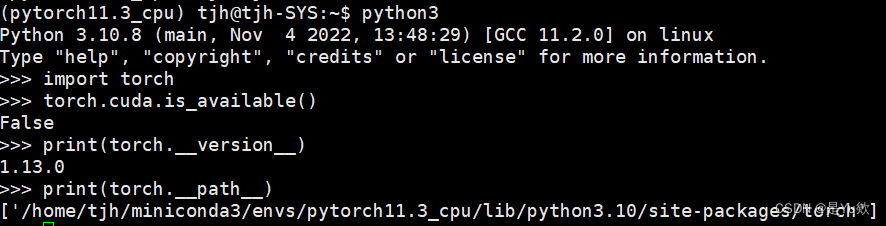
gpu测试
报错
参考:https://blog.csdn.net/qq_31878083/article/details/122069771
vi ~/.condarc
把channels里面的https改成http
这个是网络安全的原因,https协议是有安全性的ssl加密传输协议,是浏览器和服务器之间的通信加密,这样来确保传输的安全。
auto_activate_base: false
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
custom_channels:
conda-forge: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
为了保证用的是镜像站提供的索引,清除索引缓存,输入:
conda clean -i
根据不同要求得到命令后,要把-c pytorch去掉,才会去自己添加的镜像源下载
gpu下载成cpu
环境名称为pytorch11.3
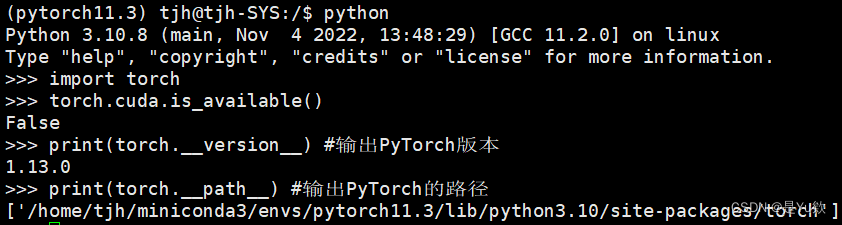
#查看torchvision 版本
conda list torchvision

重新下载把
重新安装gpu版本
参考:https://blog.csdn.net/ke996/article/details/112761228
torch下载:由于通过命令行下载的pytorch版本是cpu版本导致后期测试torch测试是否可以使用GPU 时,torch.cuda.is_available()一直返回False.
通过下载pytorch的whl文件,用pip install ******.whl来安装pytorch.
目前稳定版本为1.13.0

注意cu才是cpu版本,我是cuda11.3,所以选择了这个
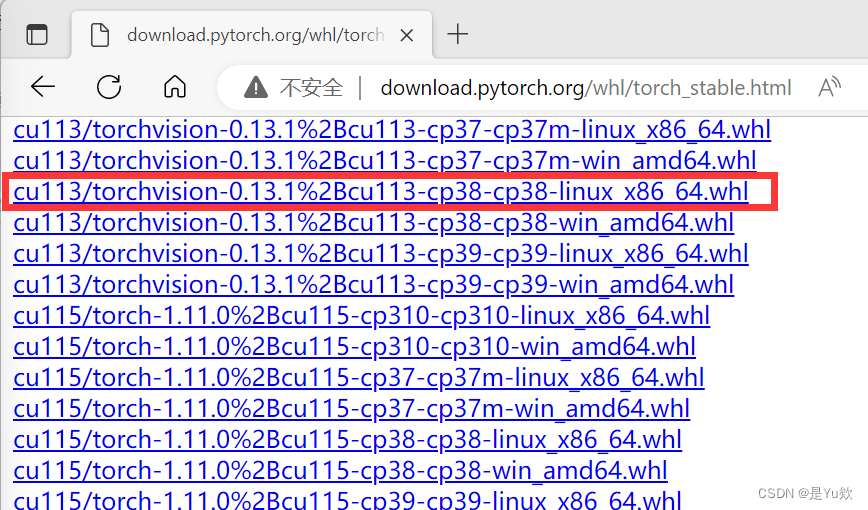
(我没下,因为我分了两个环境)特别重要的是cp后面跟着是python版本这个也要下载相应版本
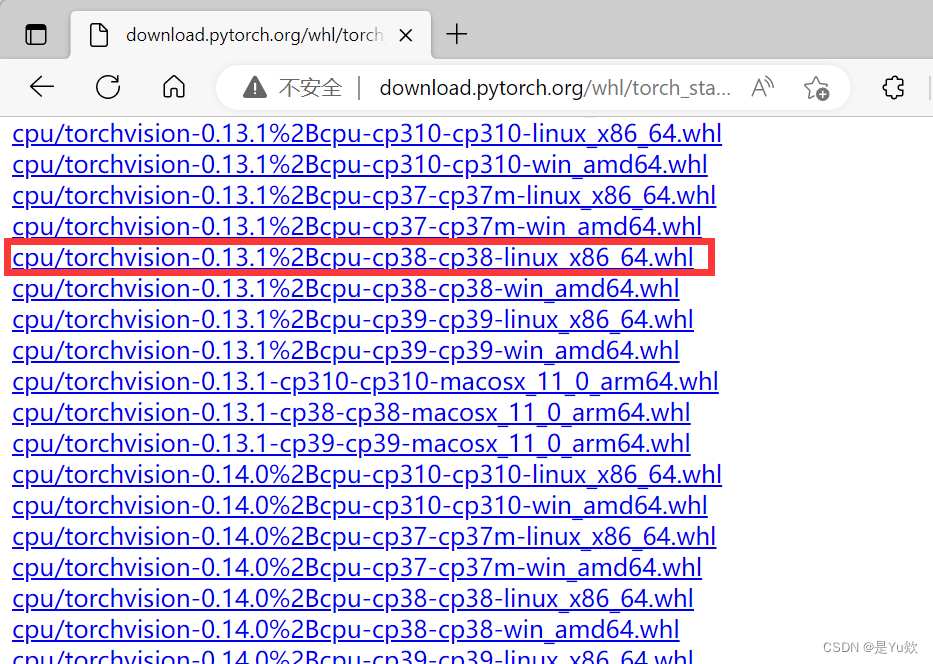
比如:torch-1.8.0+cu111-cp36-cp36m-win_amd64.whl
torchvision-0.9.0+cu111-cp36-cp36m-win_amd64.whl
CUDA 11.3
conda remove -n pytorch11.3(虚拟环境名称) --all
conda remove -n pytorch11.3 --all
删除包
参考:https://blog.csdn.net/weixin_46415031/article/details/114809650
conda install pytorch1.12.0 torchvision0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
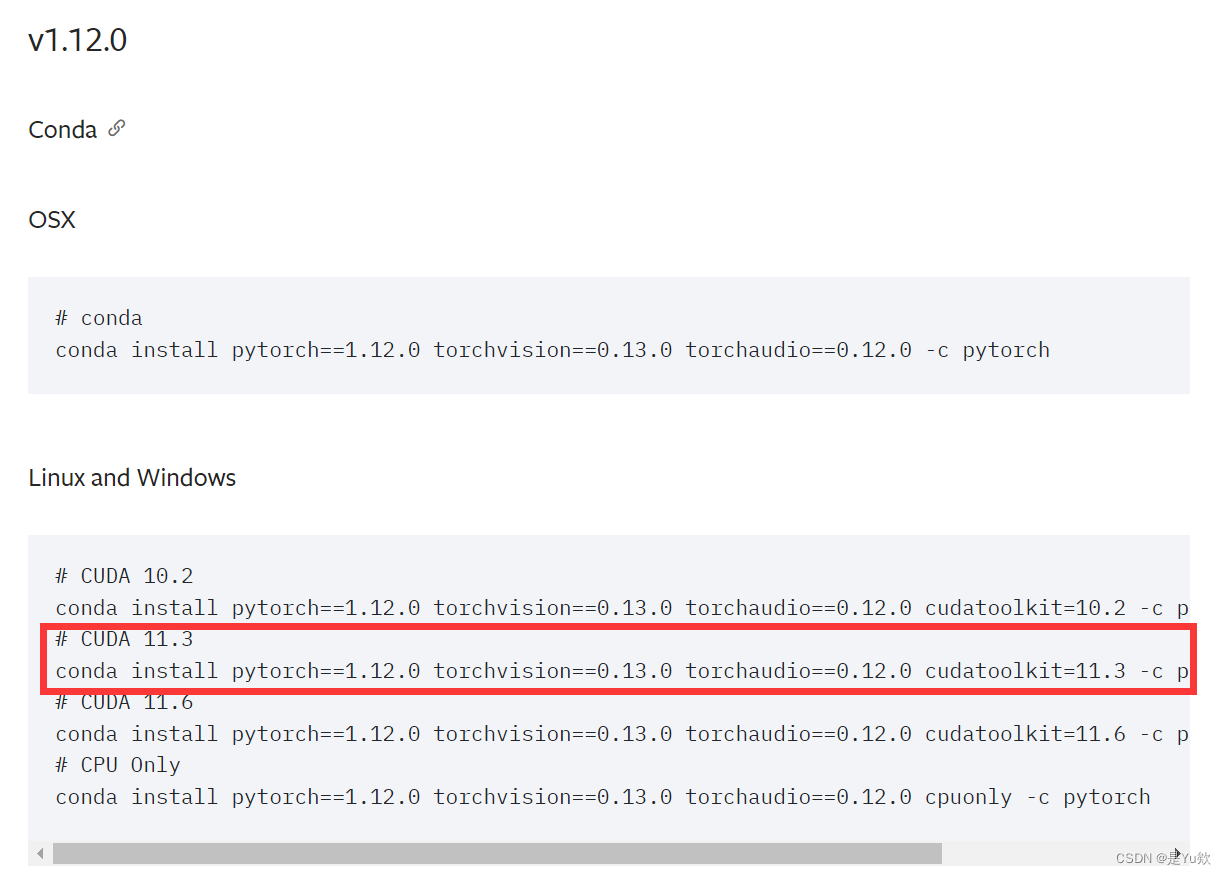
cu113/torchvision-0.13.0%2Bcu113-cp39-cp39-linux_x86_64.whl
cu113/torch-1.12.0%2Bcu113-cp39-cp39-linux_x86_64.whl
还是通过Xftp上传

下载到本地后:进入conda环境激活对应的python36
conda env list
conda activate pytorch1.12_gpu
下载python3.9
conda install python=3.9.0
pip install+ whl文件位置
比如:pip install torch-1.12.0+cu113-cp39-cp39-linux_x86_64.whl
pip install --no-index --find-links=file:/home/tjh/torch-1.12.0+cu113-cp39-cp39-linux_x86_64.whl
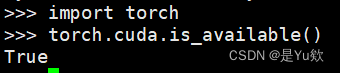
普天同庆
删除下载源
安装完记得删除下载源
输入sudo vim .condarc,修改该文件的内容(记得删除default那行):

conda install cudnn=8.2.1 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/linux-64/
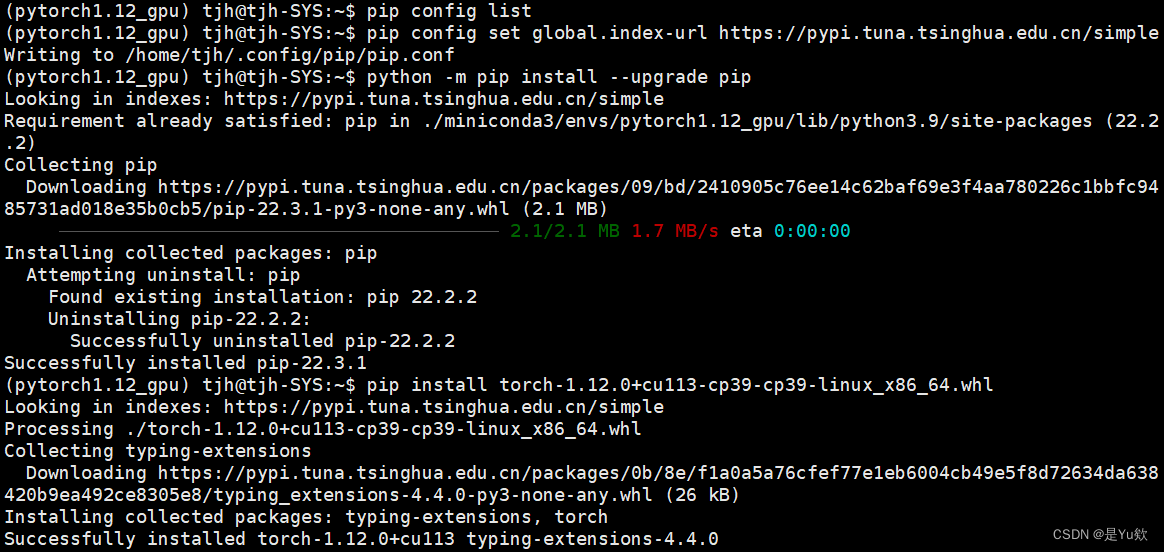
本机安装whl报错
pip install 本机的whl,报错网络不可达
进到那个目录了好像,pip升级也网络不可达
pip源和conda源是两个东西
检查pip源
pip config list
增加镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simpleWriting to /home/tjh/.config/pip/pip.conf
成功了!!!!