之前在博文中讲到了YOLOV5的运行,以及转tensorrt.
但是, 一个模型通常需要结合数据训练,才能得到更好的结果. 因此,我们有必要熟悉yolov5的训练过程.
执行训练的过程
Yolov5的github提供了官方的训练脚本.
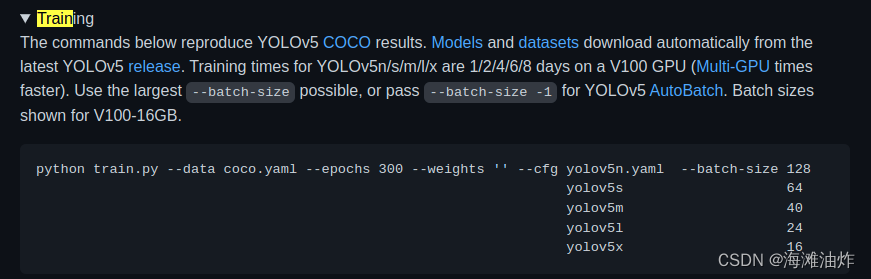
第一次运行,会自动下载数据集,然后会检测到你的gpu配置,如果不对,那么它会自动退出. 因此, 请确保你的电脑有GPU, 并且, 适配了cuda和pytorch.
相关的检验可以参考这篇博文
AssertionError: Torch not compiled with CUDA enabled解決方案_海滩油炸的博客-CSDN博客
开始进行训练后, 请注意设定batch-size, 第一次使用2080Ti训练的时候, batch-size设定为128, 内存直接爆炸.
然后重启电脑后, 根据官方建议,batch_size设定为 --batch-size -1 ,训练总算开始了.
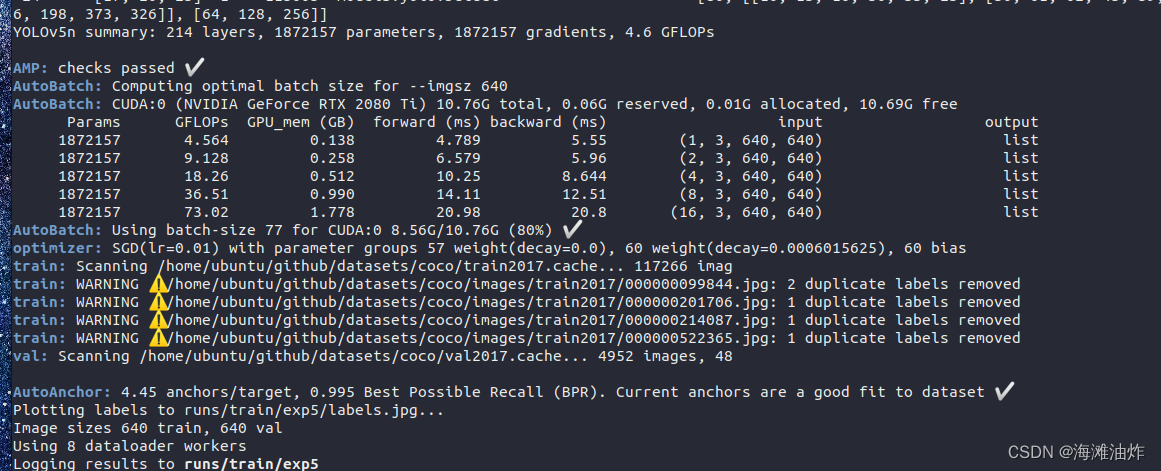
如上图截图可以看到
* 网络的参数总结(layers, paramters, gradients, GFLOPs)
根据GPU性能,自动适配了batch-size 77.
对应的在system monitor中也可以看到, gpu的占用率非常高.
![]()
然后,开始进行300个epoche的训练.训练开始时间是2023-1-2 9:00 AM
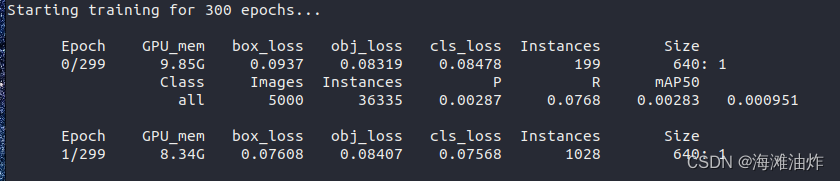
在2023-1-4 14:00左右,我完成了257个epoche的训练,然后,停电了...
为了有仪式感的经历完整的训练步骤, 我基于上次训练好的模型(通过参数 weights 修改),重新开始了训练,.只训练三个epoche.

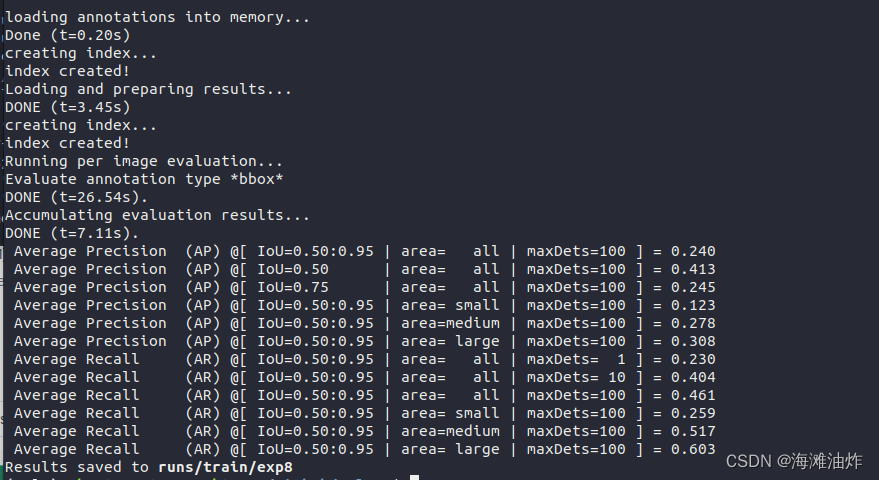
训练完成后,可以看到对于Average Precision 和 Average Recall的统计.









![[JavaEE] volatile与wait和notify](https://img-blog.csdnimg.cn/a2dc7f6dffe44804990bf63e22afa5ec.png)