文章目录
- 一、消息追踪
- 1.1 Firehose功能
- 1.1.1 开启与关闭
- 1.1.2 测试
- 1.1.3 总结
- 1.2 rabbitmq_tracing 插件
- 1.2.1 定义trace规则
- 1.2.2 测试
- 1.2.2.1 与Firehose之间的优先级
- 二、Shovel插件
- 2.1 实现原理
- 2.1.1 从队列到交换器
- 2.1.2 从队列到队列
- 2.1.3 交换器到交换器
- 2.2 Shovel 插件使用
- 2.2.1 开启Shovel功能
- 2.2.2 定义Shovel link
- 2.2.3 效果测试
- 2.2.4 集群测试
- 2.3 命令创建
- 2.3.1 创建Shovel link
- 2.3.2 查看Shovel状态
一、消息追踪
- 当有消息异常丢失时,可以通过跟踪记录消息的投递过程,以此快速地定位问题。
- 消息丢失情况:
- 可能是生产者与 Broker 断开了连接并且也没有任何重试机制。
- 可能是消费者在处理消息时发生了异常,不过却提前进行了 ak。
- 可能是交换器没有与任何队列进行绑定,生产者感知不到或者没有采取相应的措施。
- 集群策略也有可能导致消息丢失。
1.1 Firehose功能
- 在rabbitmq中,Firehose 功能可以实现消息追踪。Firehose 可以记录每一次发送或者消费消息的记录,方便rabbitmq的使用者进行调试、排错等。
- Firehose原理:
- 是将生产者投递给rabbitmq的消息,或者rabbitmq投递给消费者的消息,按照指定格式发送到默认交换器上。
- 交换器: amq.rabbitmq.trace,是个topic 类型的交换器。
- 发送到这个交换器上的消息的绑定键为:publish.{exchangename}和deliver.{queuename}。
- exchangename:生产者投递消息的交换器名称。
- queuename: 消费者获取消息的队列名称。
1.1.1 开启与关闭
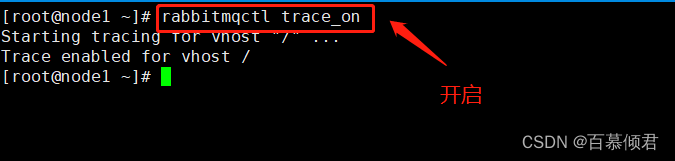
- 开启命令:rabbitmqctl trace_on [-p vhost]。
- 关闭命令: rabbitmqctl trace_off [-p vhost]。
- 注意事项:
- Firehose 默认情况下处于关闭状态,并且 Firehose 的状态也是非持久化的,会在rabbitmq服务重启的时候还原成默认的状态。
- Firehose 开启之后会影响rabbitmq整体服务的性能,因为它会引起额外的消息生成、路由和存储。
1.开启Firehose。
2.查看。开启之后在web页面可以看到默认交换器amq.rabbitmq.trace。
1.1.2 测试
- 测试工作需确保 Firehose 处于开启状态。
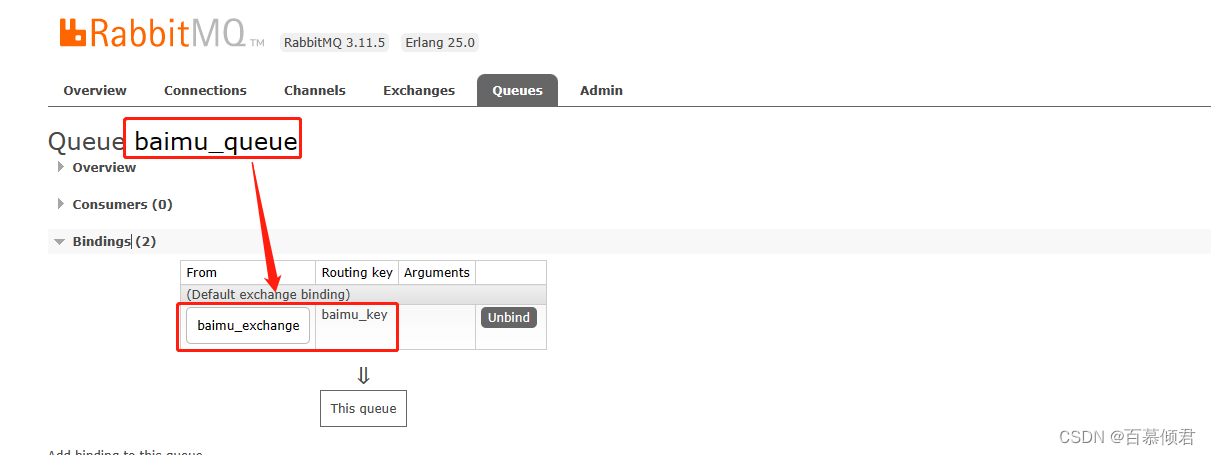
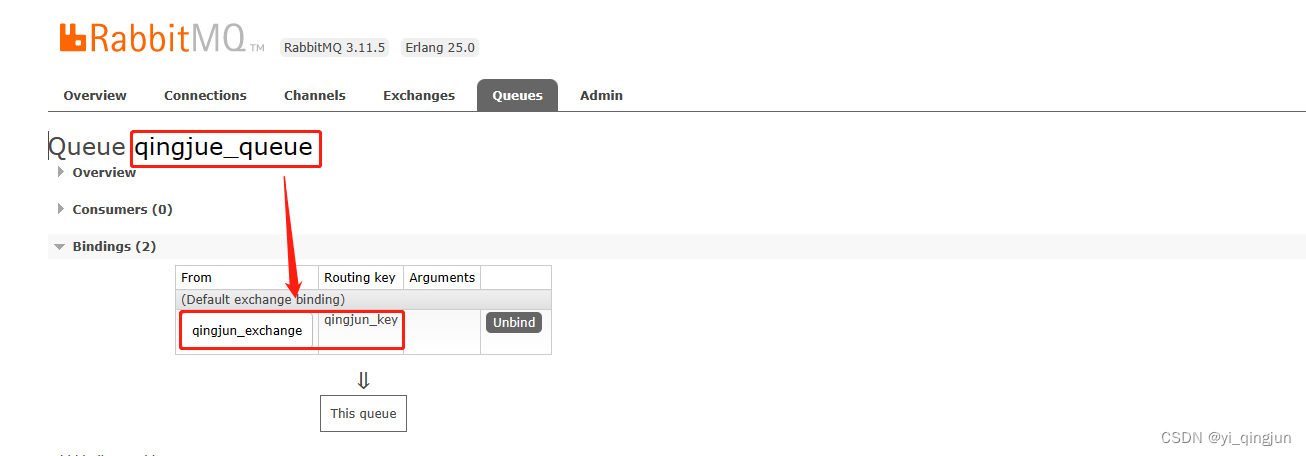
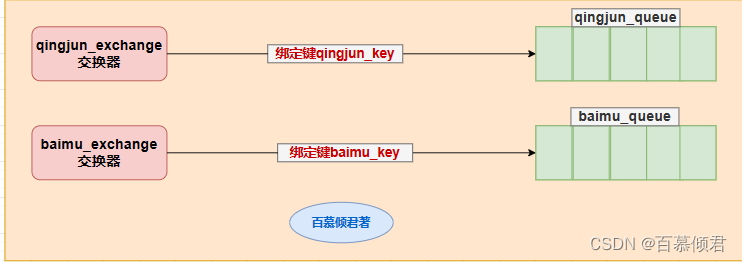
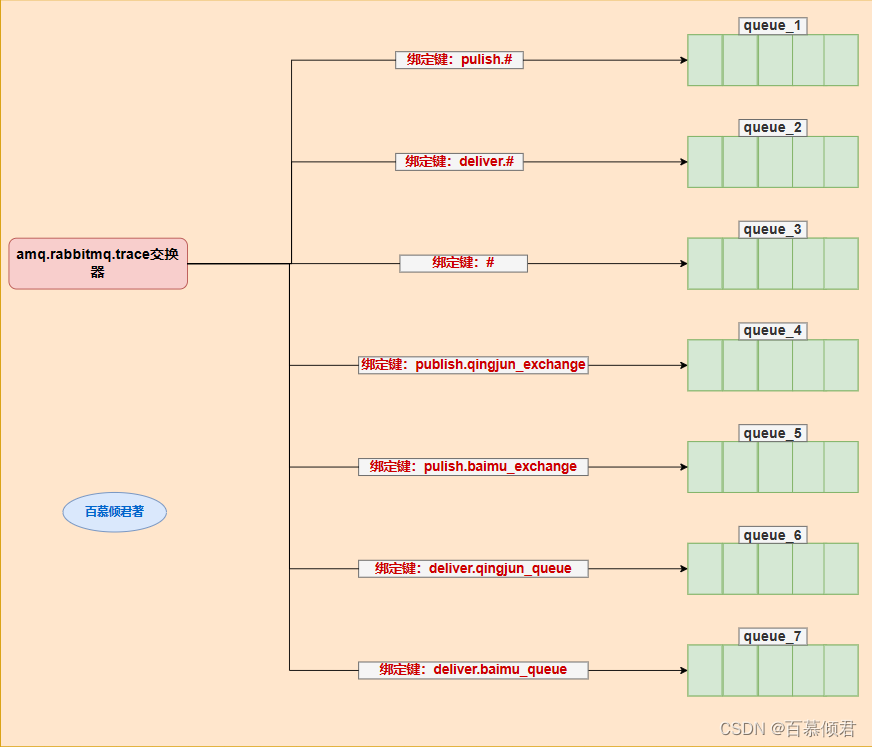
- 现有有两个交换器qingjun_exchange、baimu_exchange,分别通过绑定键qingjun_key、baimu_key和队列qingjun_queue、baimu_queue绑定。
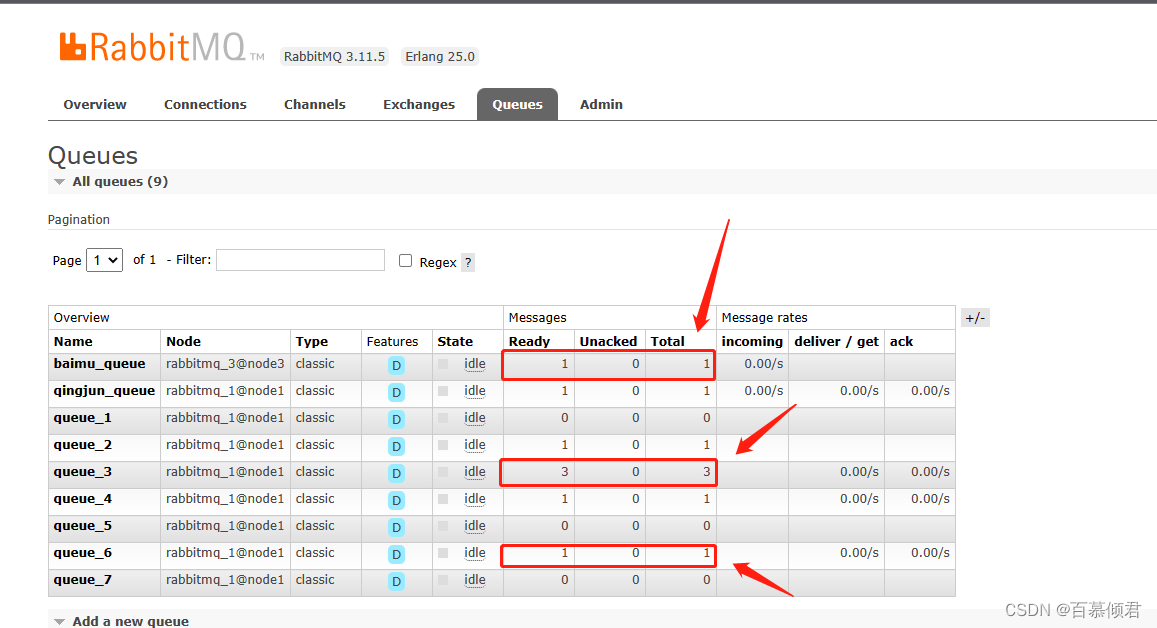
2. 创建5个队列与默认交换器amq.rabbitmq.trace绑定,用来接收生产者投递给交换器消息这个过程的监控数据消息和消费者消费队列里的消息这个过程的监控数据消息。
- 队列分别为:
- queue_1: 当生产者给qingjun_exchange、baimu_exchange交换器发送消息时,发送到其中任何一个交换器,则该队列就记录一条消息。
- queue_2:消费者消费qingjun_queue、baimu_queue队列里的消息时,消费其中任何一个队列消息,则该队列就记录一条消息。
- queue_3:接受所有消息。
- queue_4:当生产者给qingjun_exchange交换器发送消息时,则该队列就记录一条消息。
- queue_5:当生产者给baimu_exchange交换器发送消息时,则该队列就记录一条消息。
- queue_6:消费者消费qingjun_queue队列里的消息时,则该队列就记录一条消息。
- queue_7:消费者消费baimu_queue队列里的消息时,则该队列就记录一条消息。
- 绑定键分别为:pulish.#、deliver.#、#、publish.qingjun_exchange、pulish.baimu_exchange、deliver.qingjun_queue、deliver.baimu_queue。
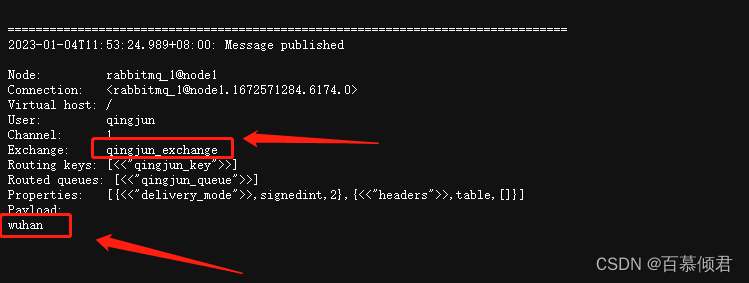
- 现在给qingjun_exchange交换器发送一条消息“wuhan”。
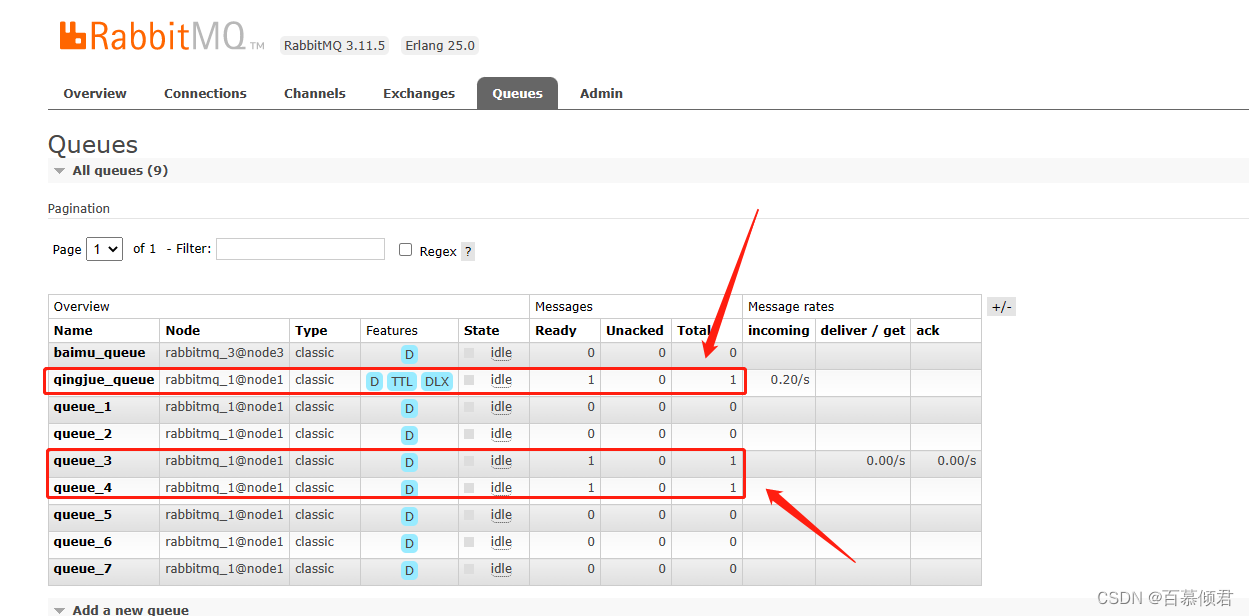
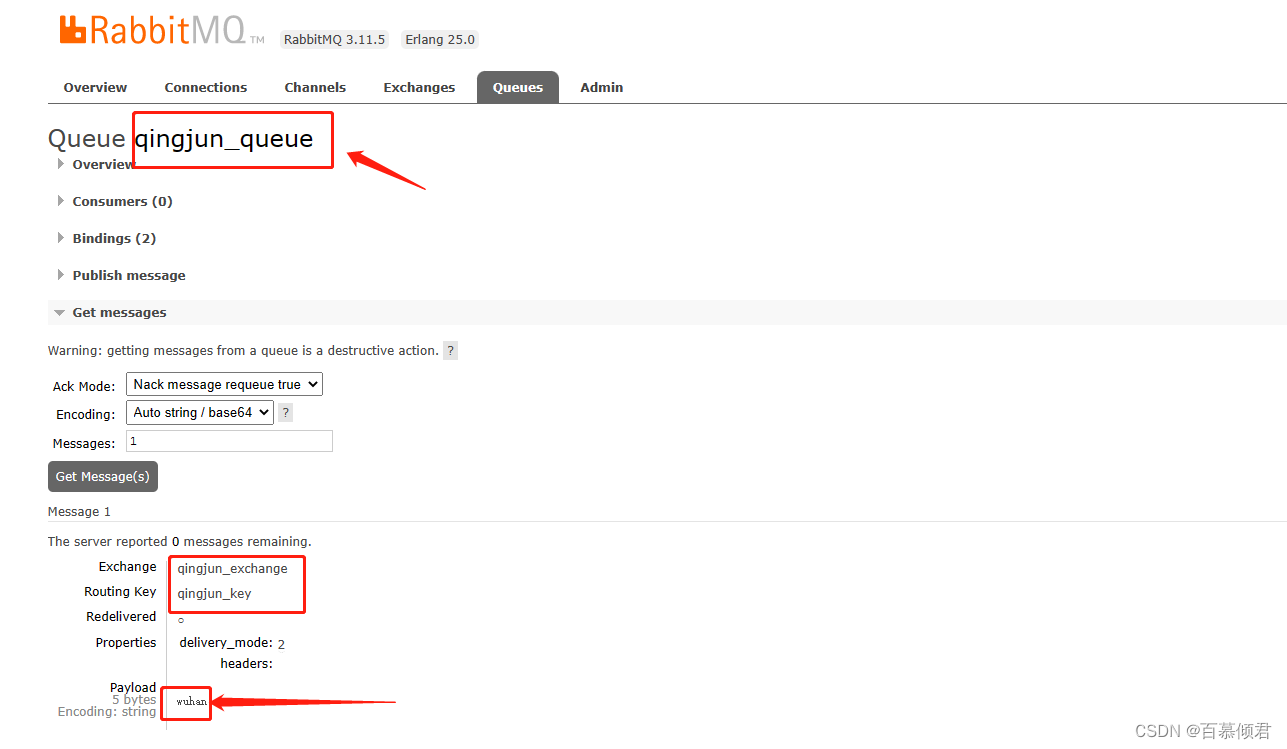
- qingjun_queue队列正常收到一条消息。
- queue_3接受所有消息,所以也有一条。
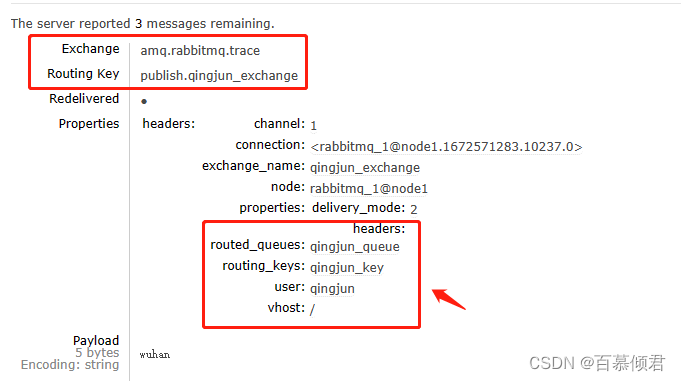
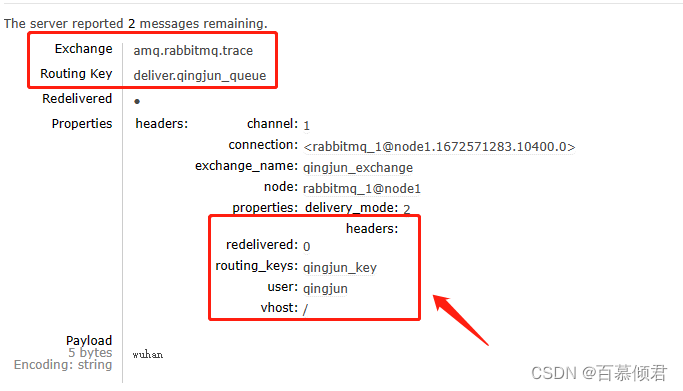
- headers 属性释义:
- exchange_name:表示发送此条消息的交换器。
- routing_keys:表示与exchange_name绑定的路由键。
- properties:表示消息本身的属性。比如delivery_mode 设置为 2,表示消息需要持久化处理。
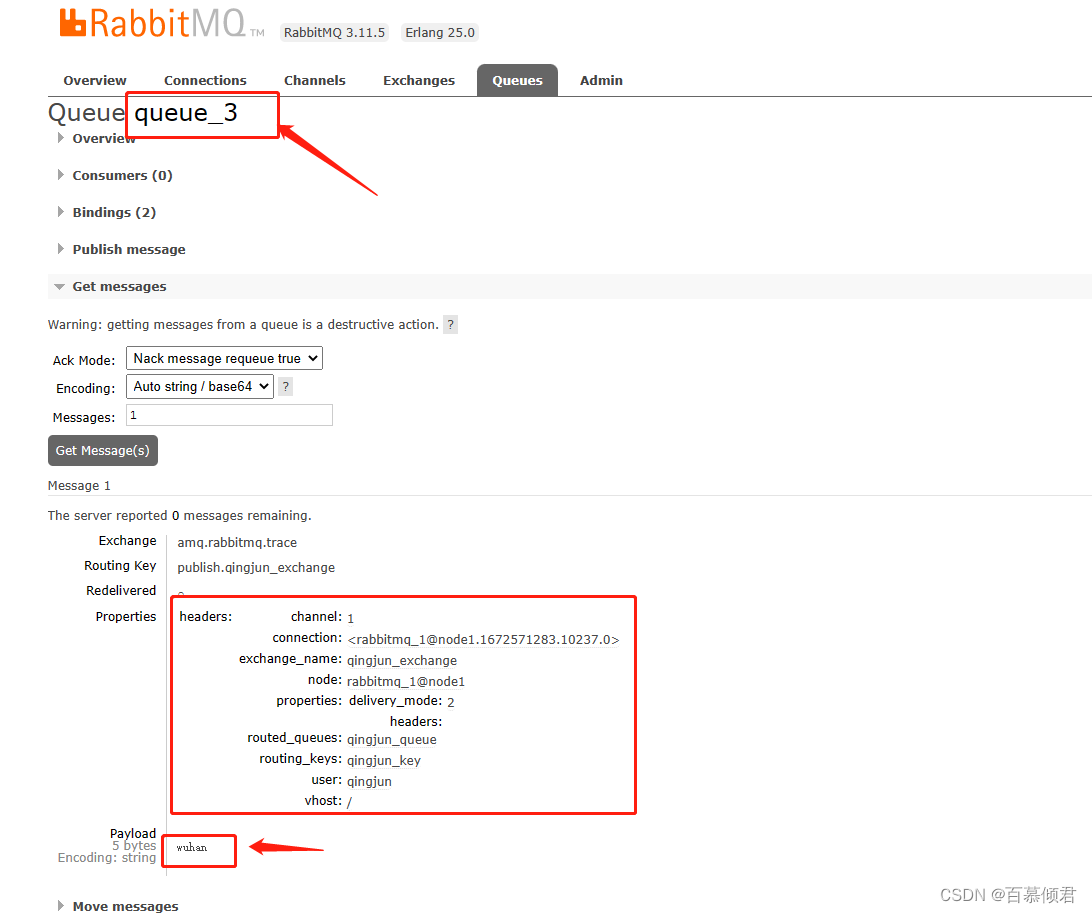
- queue_4接受生产者给qingjun_exchange交换器发送的消息,所以也有一条。
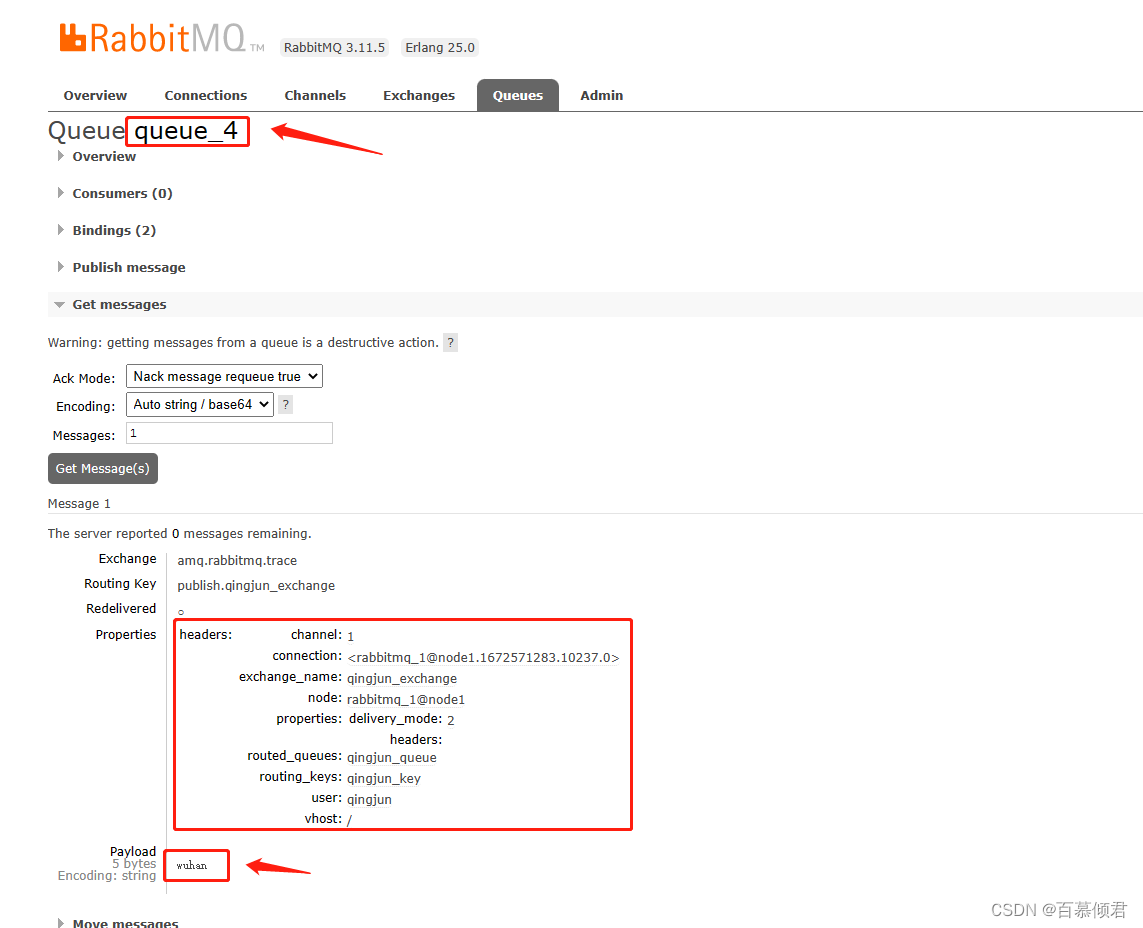
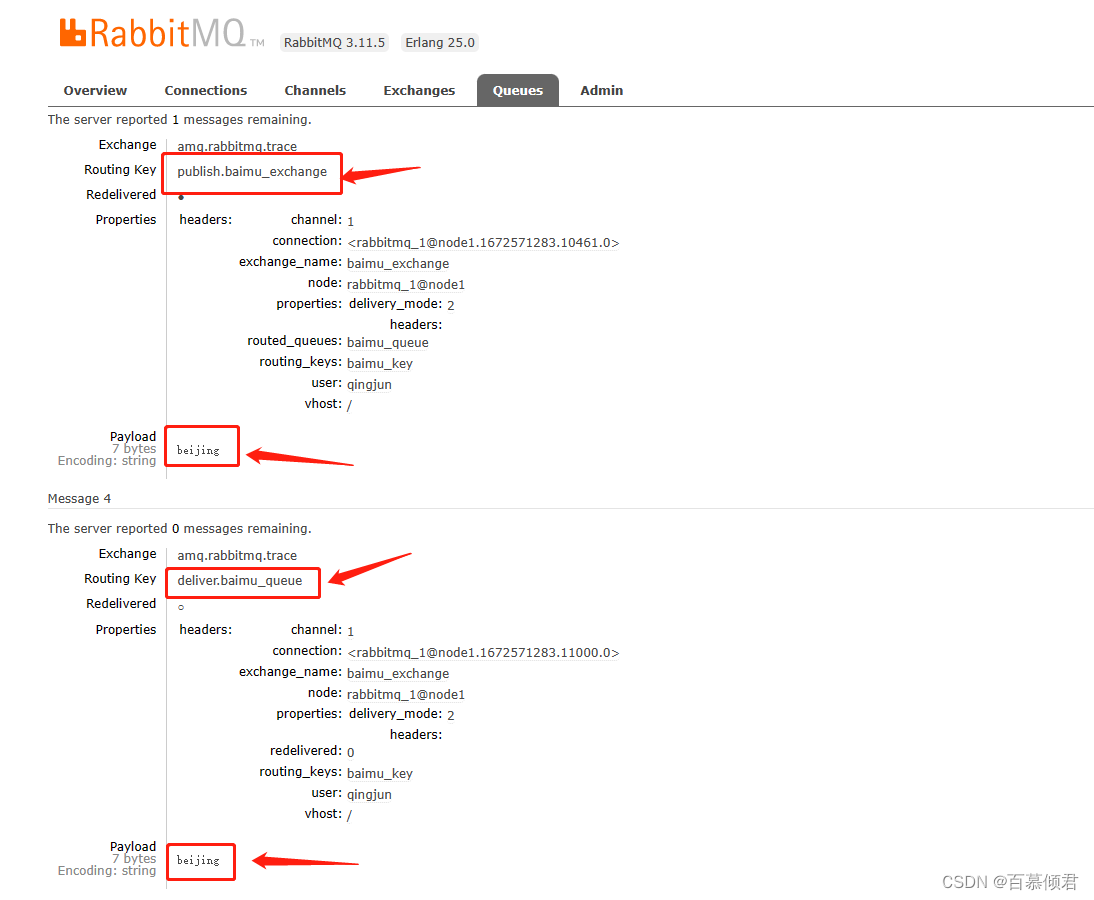
4. 现在给baimu_exchange交换器发送一条消息“beijing”,并消费此消息。
- baimu_queue队列正常收到一条消息。

- 消费baimu_queue里的一条消息,所以queue_7就有一条消息。
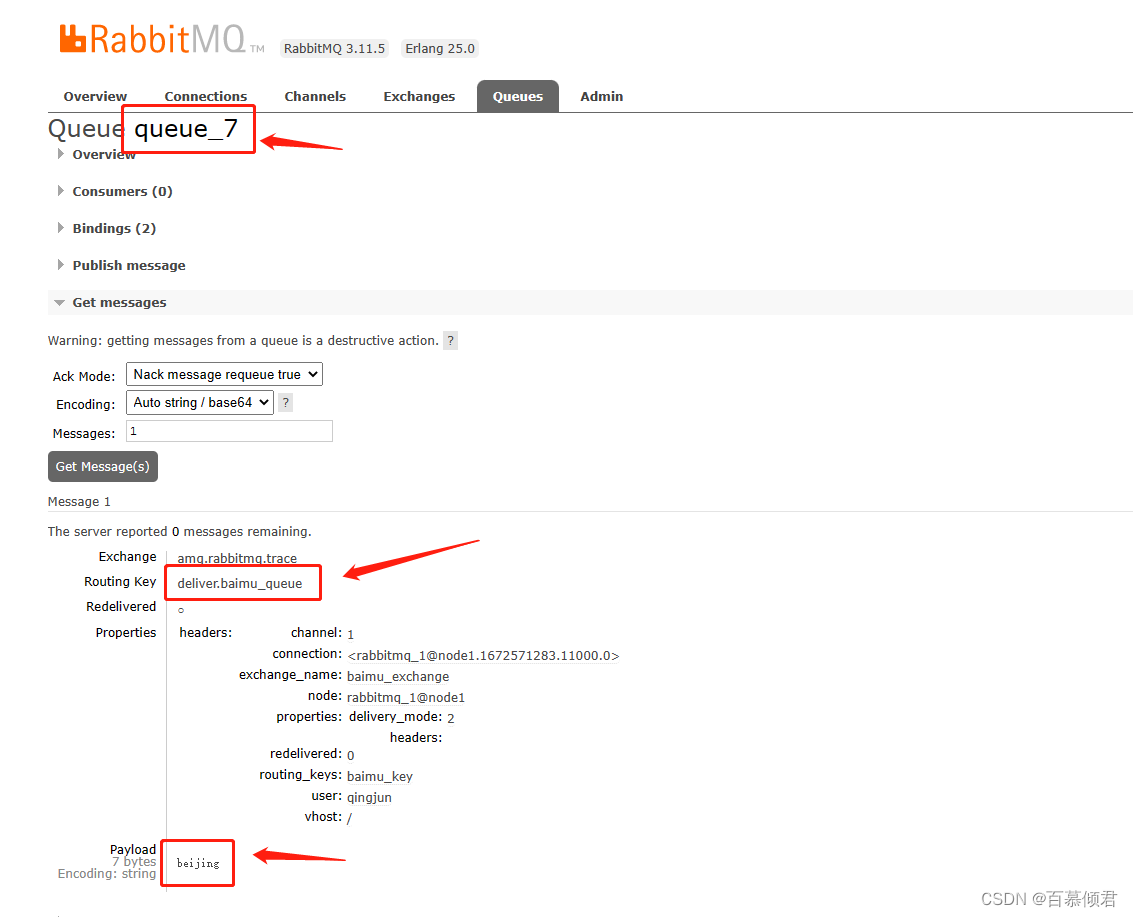
- queue_3接受所有消息。生产者给baimu_exchange发送一条消息时,queue_3队列接受一条;消费baimu_queue一条消息时,queue_3再接受一条,所以一共增长了2条。
1.1.3 总结
- 在 Firehose 开启状态下,当有客户端发送或者消费消息时,Firehose 会自动封装相应的消息体,并添加详细的 headers 属性。所以我们可以细读消息内容就可以判断出这条消息是哪儿来的。
- 生产者发送消息时,封装内容如下:
- 消费者消费消息时,封装内容如下:
1.2 rabbitmq_tracing 插件
- rabbitmg_tracing 插件是在 Firehose 基础上多了一层 GUI 的封装,两者作用差不多,会对流入流出的消息进行封装,然后将封装后的消息日志存入相应的 trace 文件之中。
- 命令使用:
- 开启插件:rabbitmq-plugins enable rabbitmq_tracing
- 关闭插件:rabbitmq-plugins disable rabbitmq_tracing
- 定义trac任务参数释义:
Name:自定义trace 任务名称。
Format:表示输出的消息日志格式,分Text 和JSON 两种。
- Text 格式的日志方便阅读。
- JSON 的格式方便程序解析。
- JSON 格式的 payload(消息体)默认会采用 Base64 进行编码,如上面的“trace test payload.会被编码“dHJhY2UgdGVzdCBwYXIsb2FkLg-=”
Tracer connection username :指定使用哪个用户创建tracing。默认使用guest用户来创建trace。
Tracer connection password:该账户的密码。
Max payload bytes:表示每条消息的最大限制,单位为 B。
- 比如设置了此值为 10,那么当有超过 10B 的消息经过 RabbitMQ 流转时,在记录到 trace 文件时会被截断。
Pattern: 设置匹配正则,和 Firehose 类似。
- “#”:匹配所有消息流入流出的情况,即当有客户端生产消息或者消费消息的时候,会把相应的消息日志都记录下来。
- “publish.#”:匹配所有消息流入的情况。
- “deliver.#”:匹配所有消息流出的情况。
- “#.amq.deliver”:追踪所有从以“.amq”结尾队列离开的消息。
- “#.myQueue”:追踪所有从“myQueue”队列离开的消息。
- 删除trace规则和日志:
- 点击trace旁边的Stop按钮就会关闭connection,并删除创建时建立的Queue。
- 点击Stop不会将trace的日志文件删除,需要再点击日志文件旁边的Delete按钮。
- 在Stop trace之前不要delete日志文件. 否则,trace仍会对消息进行追踪,但不会将消息落盘。
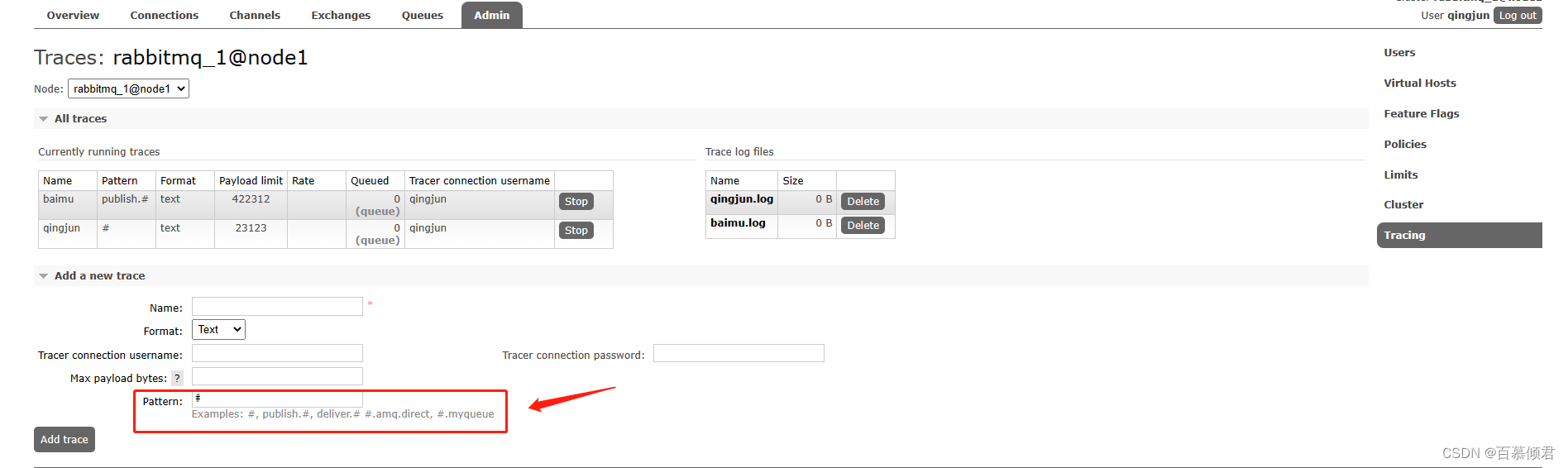
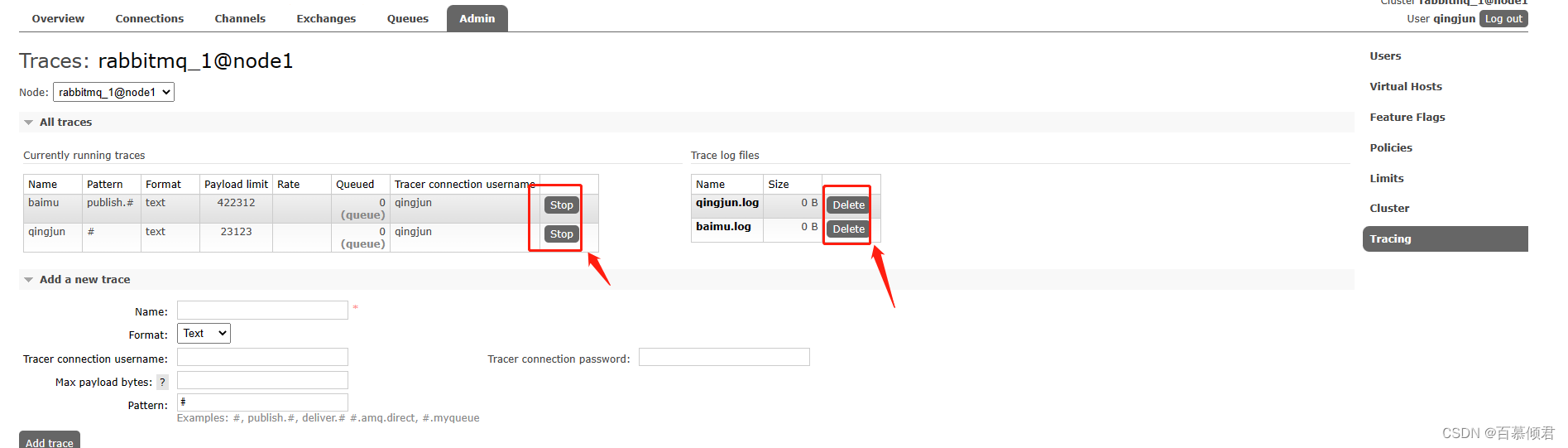
1.2.1 定义trace规则
- rabbitmq重启之后,trace规则会被删除,但是日志仍然存在。
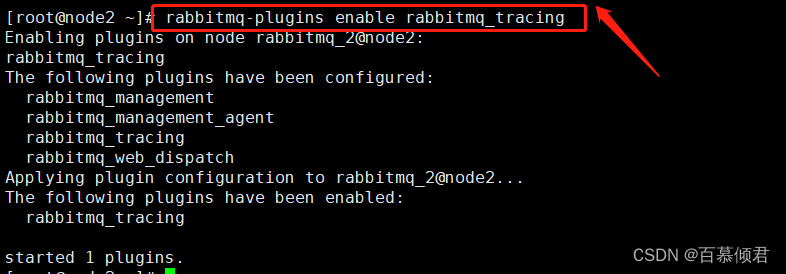
1.开启插件。集群每个节点都需要开启,节点之间不共享。
[root@node2 ~]# rabbitmq-plugins enable rabbitmq_tracing
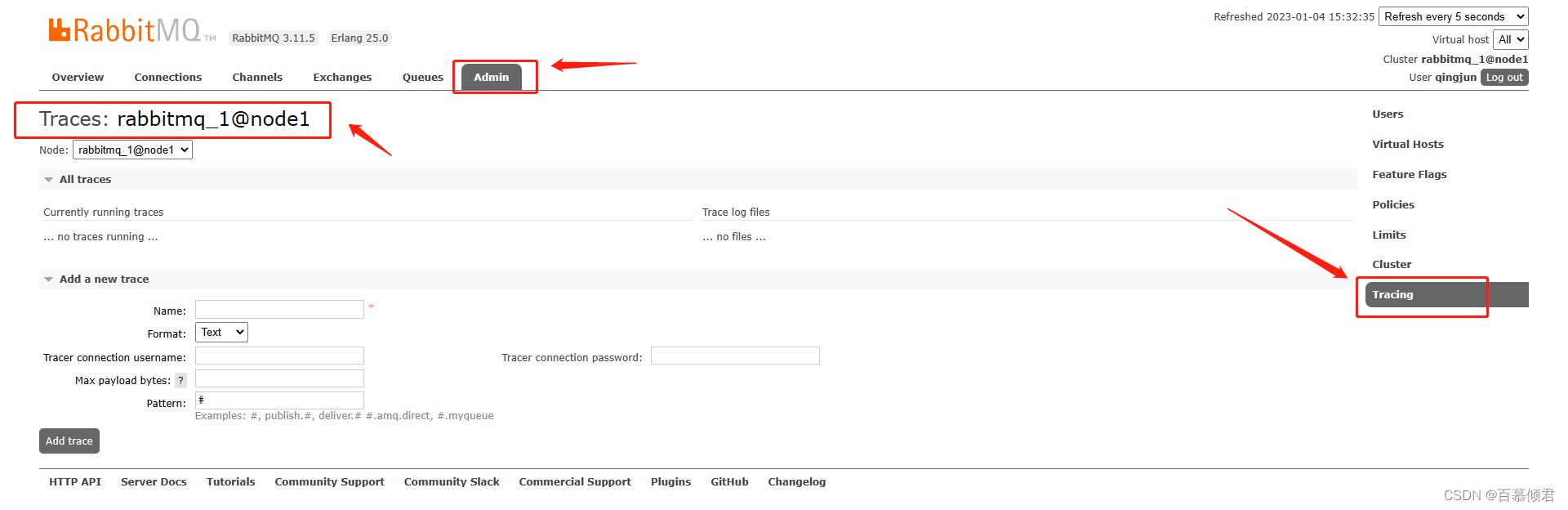
2.监控页面查看。在这里就可以定义规则了,版本的不同显示的选项也不同,在老版本中这里还有虚拟主机的选择。
3.定义一个tracing任务。生成之后就会有对应日志生成,默认存放路径在/var/tmp/rabbitmq-tracing,也可以通过配置文件修改该日志存放路径。
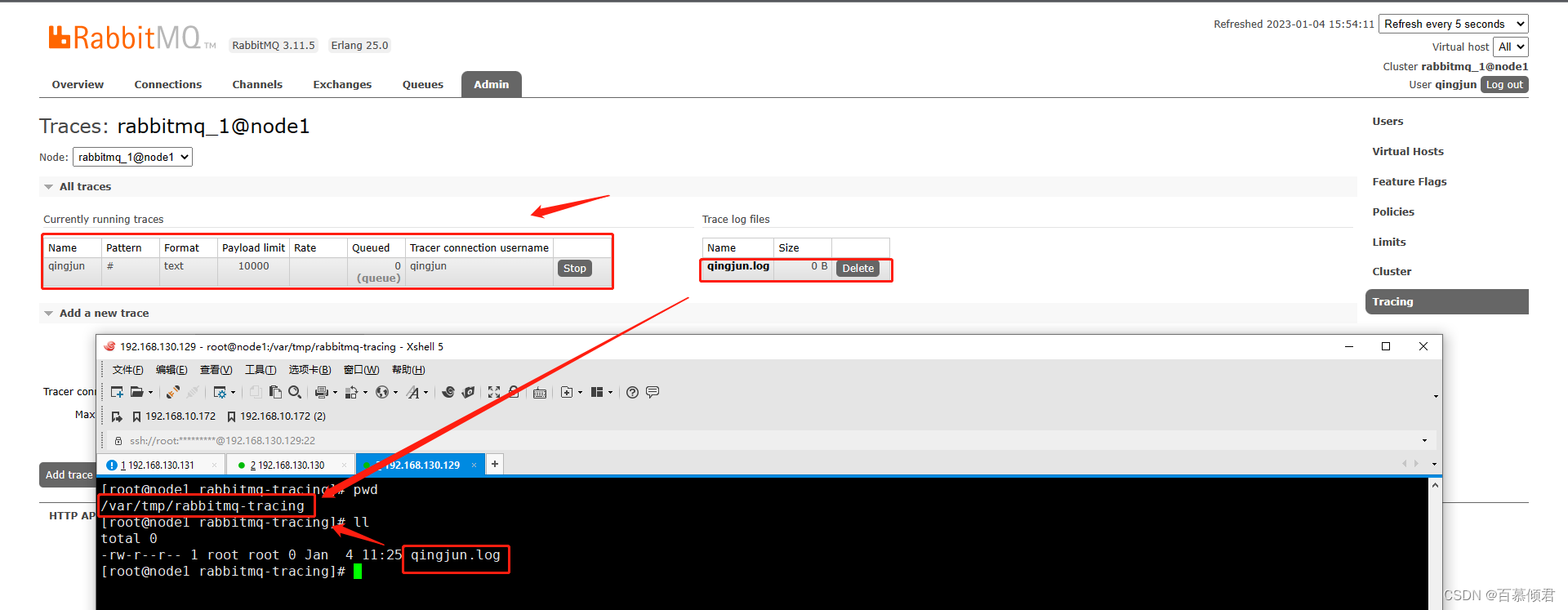
4.同时还会生成一个队列,自动与amq.rabbitmq.trace交换器绑定。每定义一个tracing任务就会多一个队列并与amq.rabbitmq.trace交换器绑定。我这里就定义了两个tracing任务,所以有两个队列。
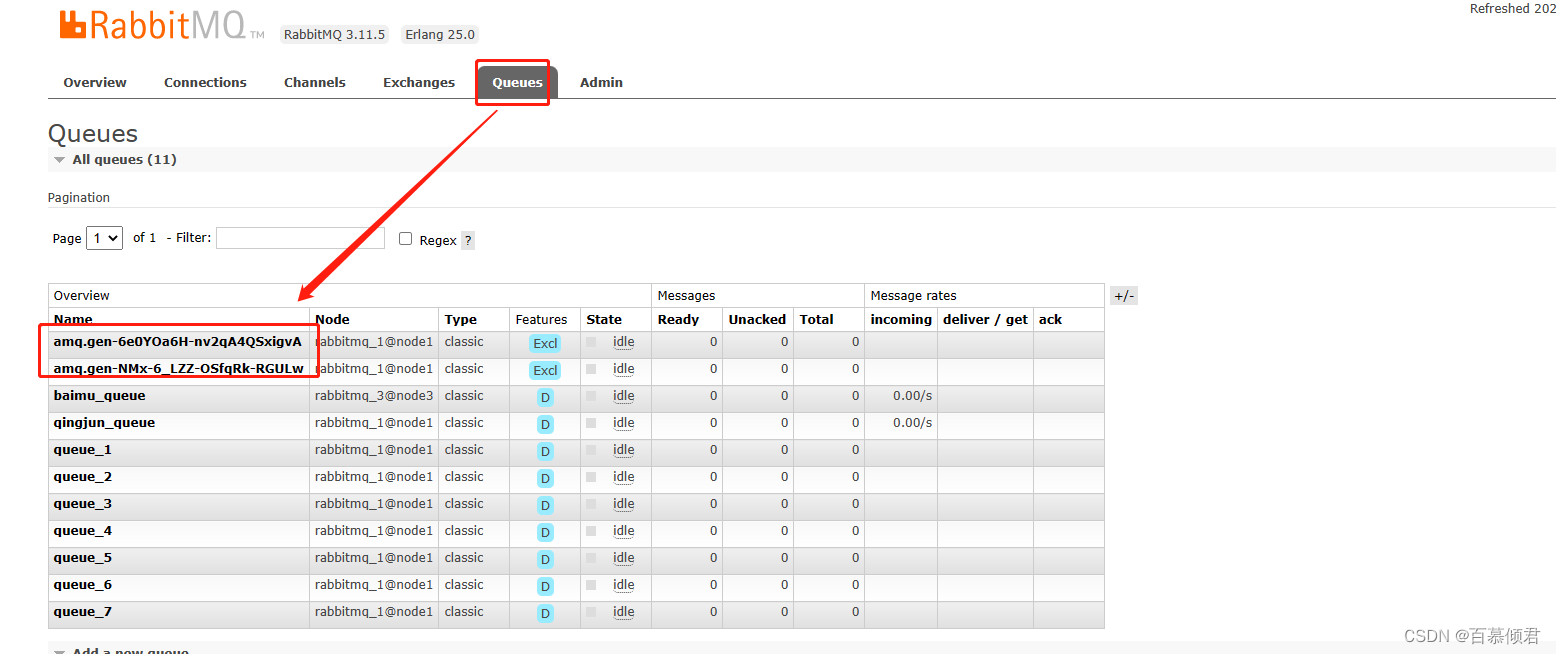
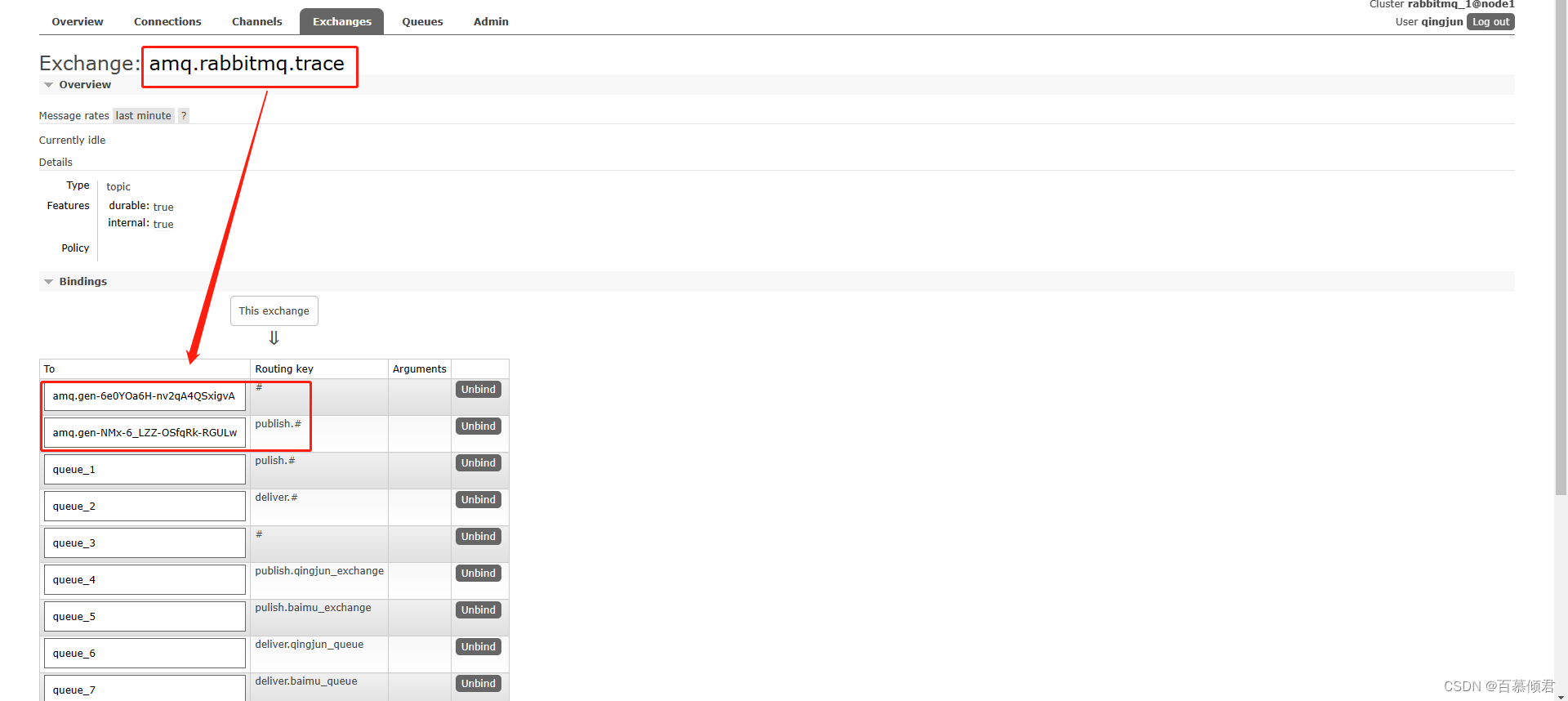
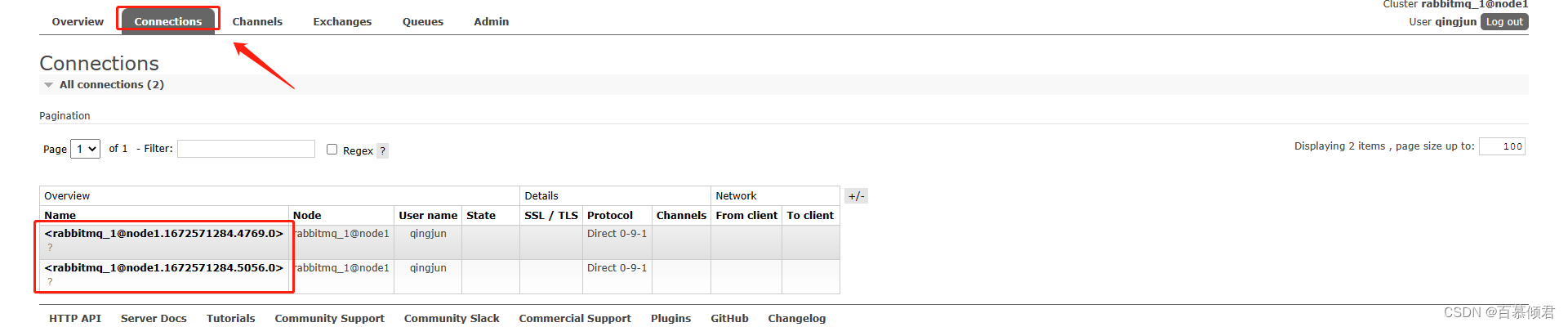
- 同时还会新增的connection(相应的会有一个consumer channel)。
1.2.2 测试
1.2.2.1 与Firehose之间的优先级
- 注意我这里的queue_1到queue_6这几个队列是用来测试前文的Firehose功能的。打那个Firehose功能和rabbitmq_tracing插件同时开启使用时,消息优先记录到Firehose定义的队列里,同时在trace日志也有记录。
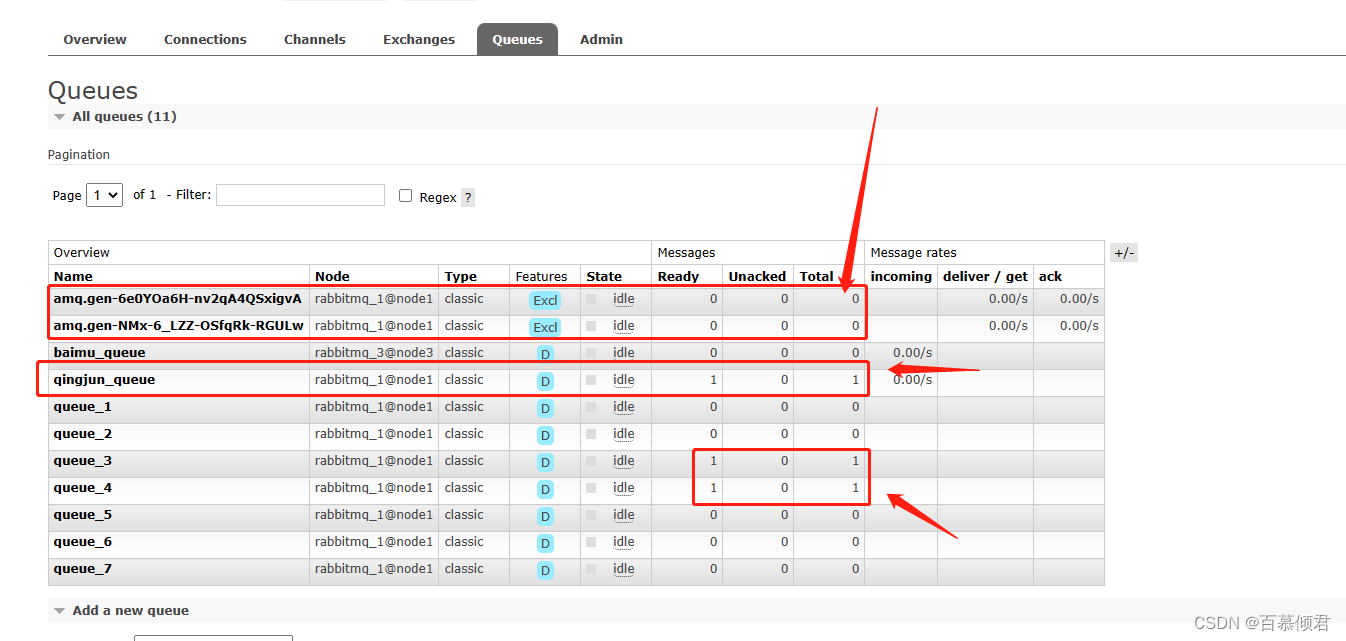
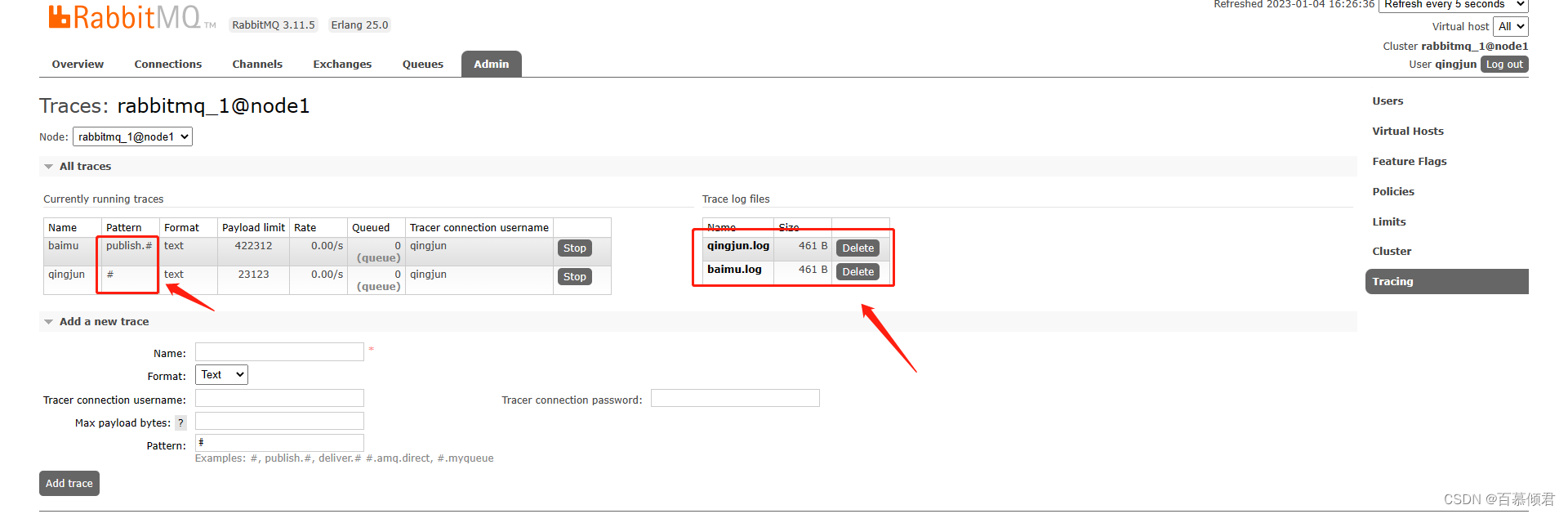
1.比如我给qingjun_exchange发送一条消息“武汉‘。queue_3和queue_4有消息进来,但是rabbitmq_tracing插件生成的队列并没有消息进来。
2.查看trace日志,有发送”wuhan“的记录。
二、Shovel插件
- 俗称”铲子“,和 Federation 插件具备类似的数据转发功能。
- Shovel 能够可靠、持续地从一个 Broker 中的队列(作为源端,即 source)拉取数据并转发至另一个 Broker 中的交换器(作为目的端,即 destination)。
- 作为源端的队列和作为目的端的交换器可以同时位于同一个 Broker 上,也可以位于不同的Broker 上。
- Shovel 主要优势:
- 松耦合。Shovel 可以移动位于不同管理域中的 Broker(或者集群)上的消息,这些 Broker(或者集群)可以包含不同的用户和 vhost,也可以使用不同的 RabbitMQ 和 Erlang版本。
- 支持广域网。Shovel 插件同样基于 AMQP 协议在 Broker 之间进行通信,被设计成可以容忍时断时续的连通情形,并且能够保证消息的可靠性。
- 高度定制。当 Shovel 成功连接后,可以对其进行配置以执行相关的 AMQP 命令。
2.1 实现原理
2.1.1 从队列到交换器
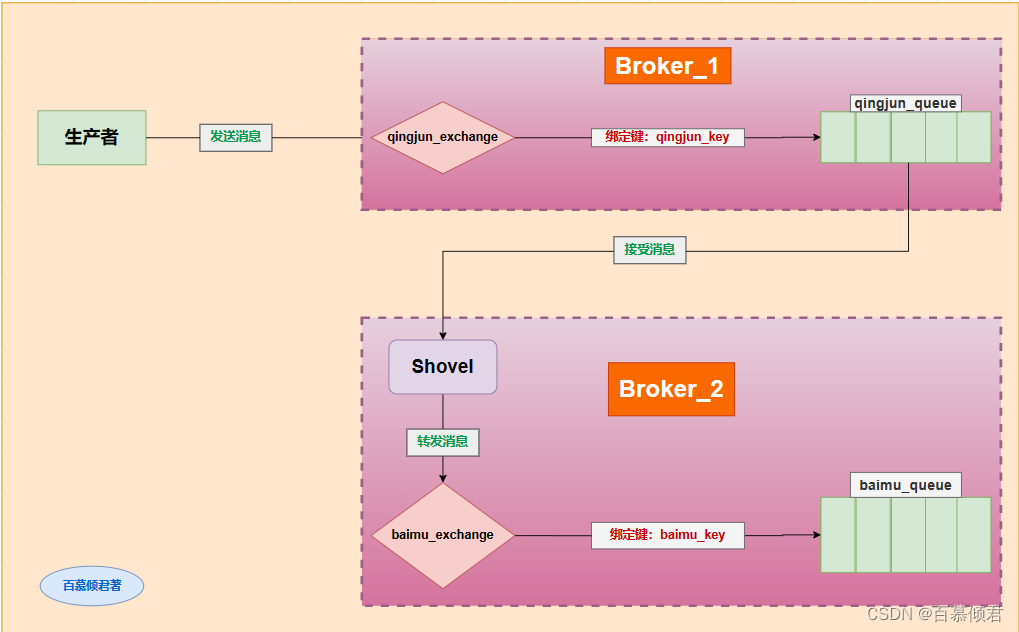
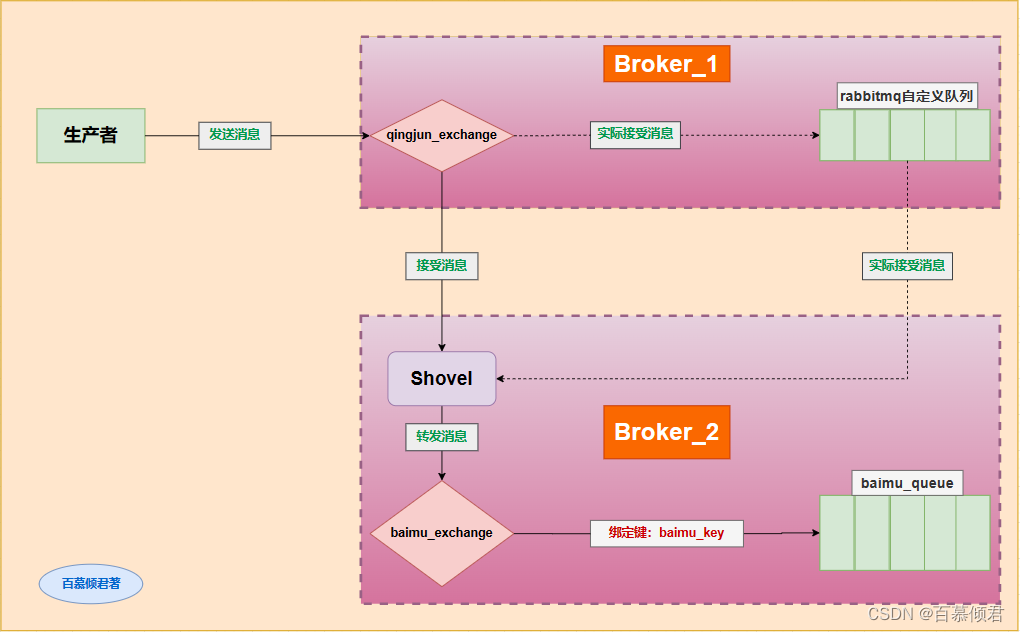
- 如图一共有两个Broker:
- Broker_1在192.168.130.129上,Broker_2在192.168.130.128上。
- Broker_1中有qingjun_exchange交换器,通过绑定键qingjun_key和qingjun_queue队列绑定。
- Broker_2中有baimu_exchange交换器,通过绑定键baimu_key和baimu_queue队列绑定。
- 开启Broker_2上的Shovel插件,配置一条Shovel link连接。
- 生产者发送消息到qingjun_exchange交换器上时,消息数据最终流转存储在baimu_queue队列中。
2.1.2 从队列到队列
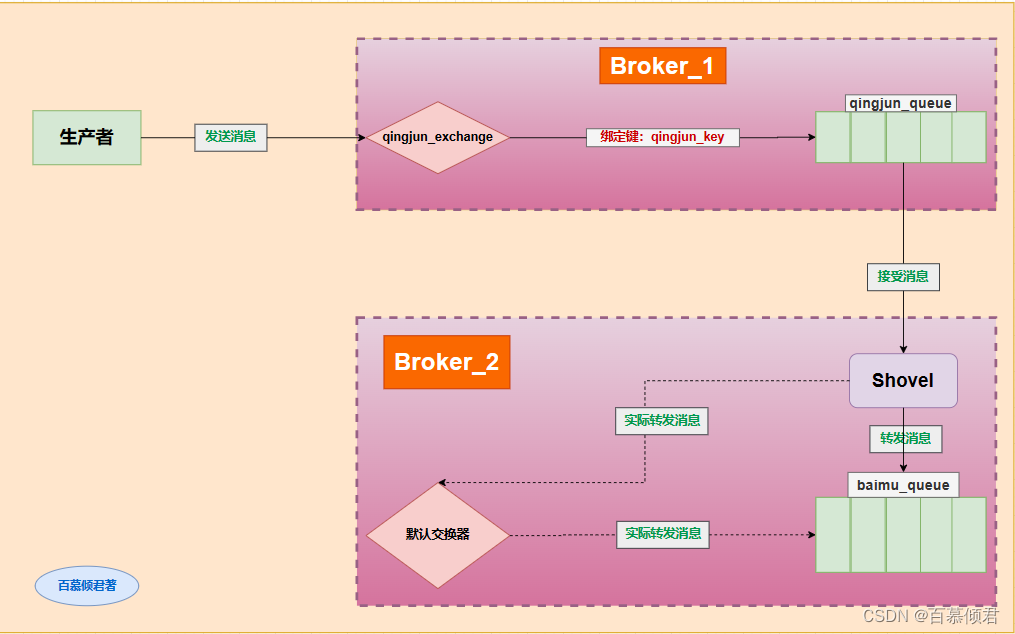
- 上图是一般配置,在使用 Shovel 插件时,以配置队列作为源端,交换器作为目的端。同样也可以将队列配置为目的端,如下图。
- 消息虽然是从qingjun_queue队列通过 Shovel link 连接到baimu_queue队列,但实际上是经由 Broker_2 的交换器转发,只不过这个交换器是默认的交换器而已。
2.1.3 交换器到交换器
- 同样也可以将交换器作为源端。
- 消息虽然是从qingjun_exchange交换器通过 Shove link 连接转发到 baimu_exchange交换器上。实际上rabbitmq会在 Broker_1 中新建一个队列并绑定 qingjun_exchange交换器,消息先从qingjun_exchange交换器存储在这个队列,然后 Shovel 再从这个队列中拉取消息进而转发至baimu_exchange交换器上。
- 注意事项:
- 如上图所示中的交换器和队列,可以在Broker开启插件之前创建,也可以在开启插件之后在创建。
- 当Broker中有集群时,可以配置所有节点地址,这样可以使得源端或者目的端的 Broker 失效后能够尝试重连到其他 Broker之上(随机挑选)。
- 还可以设置 reconnect_delay 参数,从而避免由于重连行为导致的网络泛洪,或者可以在重连失败后直接停止连接。针对源端和目的端的所有配置声明会在重连成功之后被重新发送。
2.2 Shovel 插件使用
- 现有两个rabbitmq服务,分别在192.168.130.128和192.168.130.129服务器上,元数据信息如下:
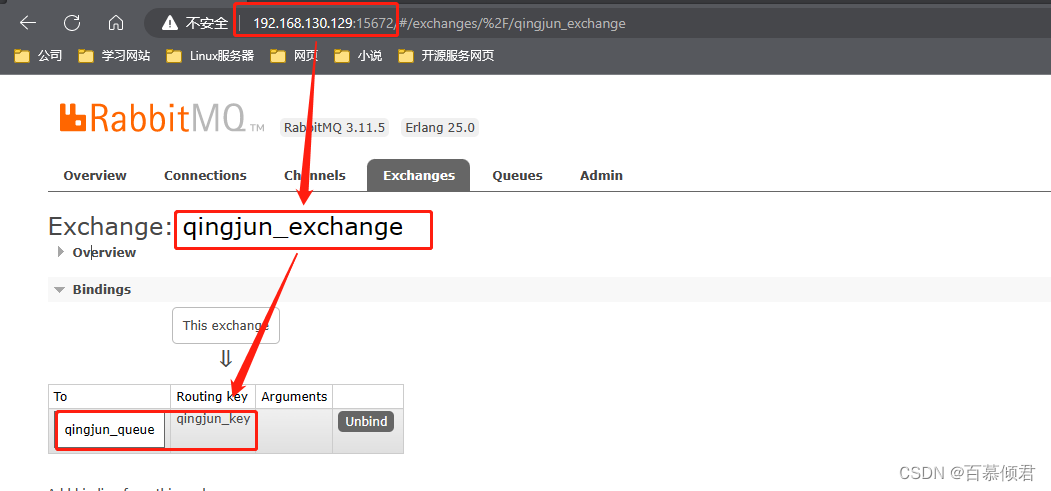
- 192.168.130.129上有qingjun_exchange交换器和qingjun_queue队列,绑定键为qingjun_key。
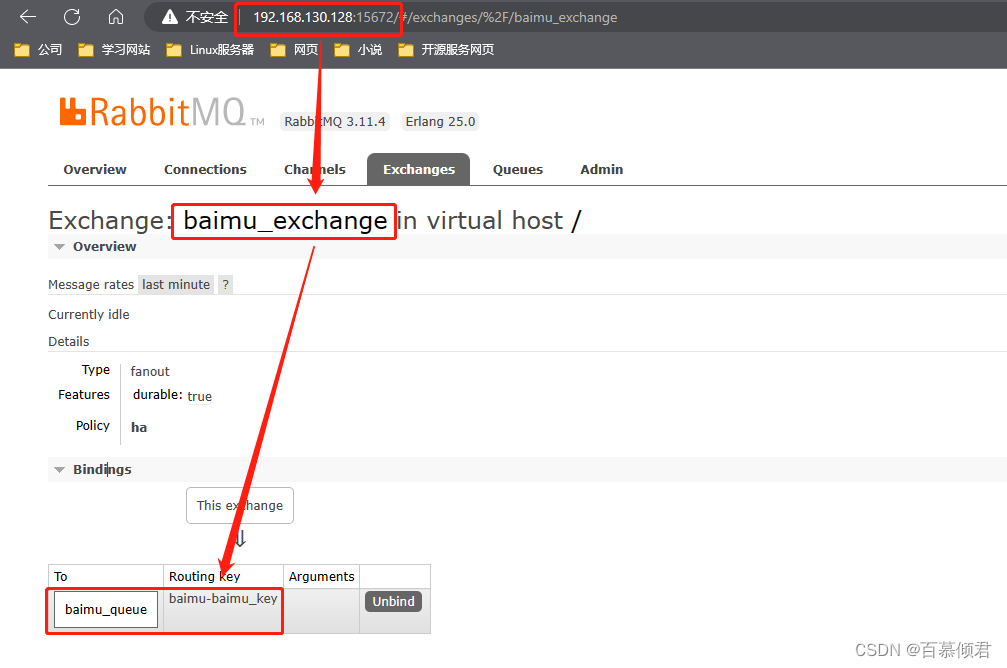
- 192.168.130.128上有baimu_exchange交换器和baimu_queue队列,绑定键为baimu_key。
- 现在需要把192.168.130.129qingjun_queue队列里的消息转发给192.168.130.129的baimu_queue队列。
2.2.1 开启Shovel功能
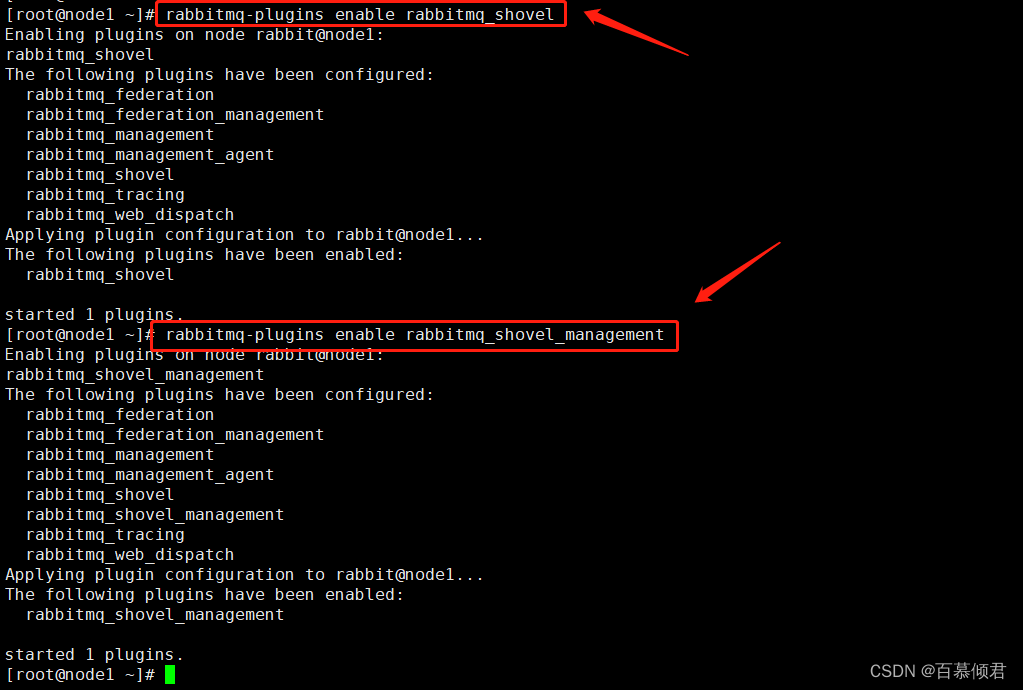
第一步,在192.168.130.128上开启Shovel功能和管理功能。
[root@node1 ~]# rabbitmq-plugins enable rabbitmq_shovel
[root@node1 ~]# rabbitmq-plugins enable rabbitmq_shovel_management
第二步,查看。开启管理功能之后右侧就多出“Shovel Status”和“Shovel Management”两个 Tab 页。
- rabbitmq_shovel_management 插件依附于 rabbitmq_management 插件,所以开启rabbitmq_shovel_management 插件的同时默认也会开启rabbitmq_management 插件。
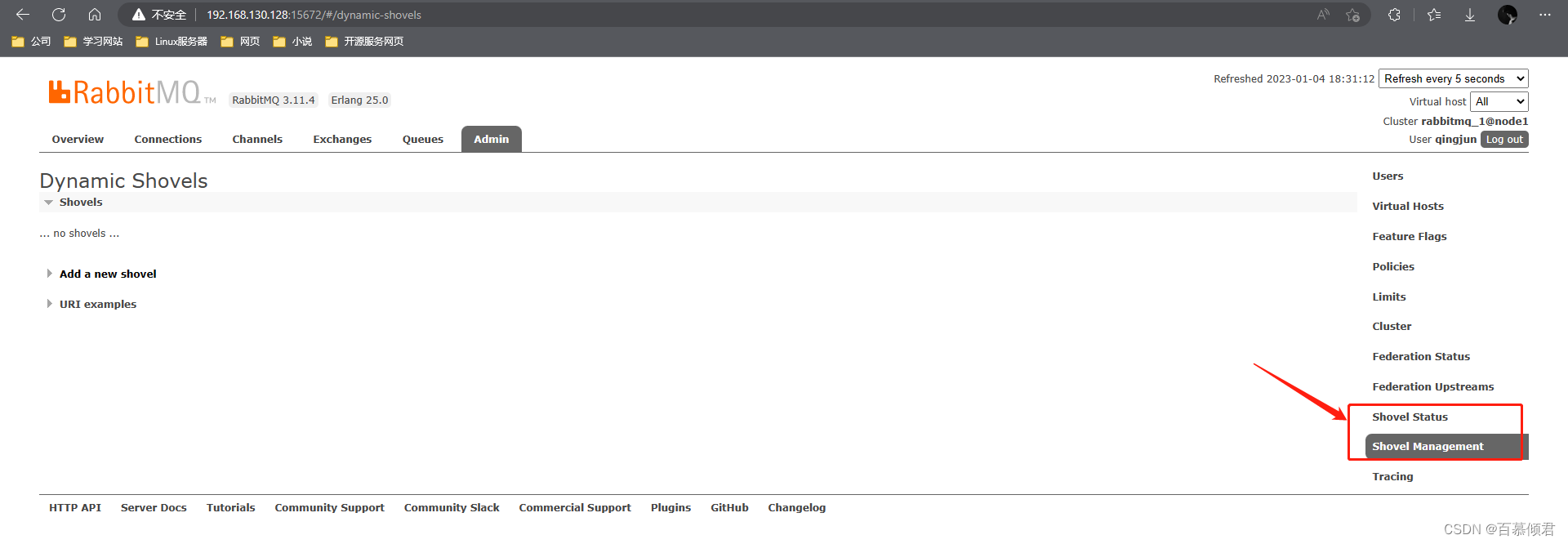
2.2.2 定义Shovel link
- 参数释义:
- Virtual host:选择本地虚拟主机,这个每个虚拟主机里的交换器和队列都不一样。
- Name:自定义Shovel link规则名称。
- Source:选择源端的AMQP版本,这个在之前都没有,官方优化了。
- URI:源端地址,格式为amqp://user:password@IP:5672。集群多节点填写时,用一个空格隔开。
- Queue/Exchange:选择从哪个队列或交换器里取消息,并填写其名称。
- Prefetch count:表示 Shovel 内部缓存的消息条数,可以参考 Federation 的相关参数。
- Auto-delete:有两个选项,Never或After。前者表示从来没有,永远不会自己删除,它将一直存在,直到显式删除;后者表示初始长度转移后,Slovel启动时会检查队列的长度,它会传输这么多消息,然后删除自己。
- Destination:选择目的地端的AMQP版本。
- URI:目的地端地址,格式为amqp://user:password@IP:5672。
- Queue/Exchange:选择接受消息的队列或交换器,并填写其名称。
- Add forwarding headers:默认为No,表示不给转走的消息添加头部信息,以指示它们从哪里被铲走和被铲到哪里。建议开启选择yes。
- Reconnect delay:表示在 Shovel link 失效时,重新建立连接前需要等待的时间。单位为秒。如果设置为 0,则不会进行重连动作,即 Shovel 会在首次连接失效时停止工作。reconnect delay 默认为5秒。
- Acknowledgement mode:表示在完成转发消息时的确认模式,共有三种取值:
- No ack:表示无须任何消息确认行为。
- Nn publish:表示 Shovel 会把每一条消息发送到目的端之后再向源端发送消息确认。
- On confirm:表示 Shovel 会使用 publisher confirm 机制,在收到目的端的消息确认之后再向源端发送消息确认。也是默认设置,并强烈建议使用该种模式,可靠性高。
第三步,定义Shovel link规则。注意这里一定不能填错,要取哪个交换器或队列的数据?给到目的地的交换器还是队列?地址格式,还是注意虚拟主机。
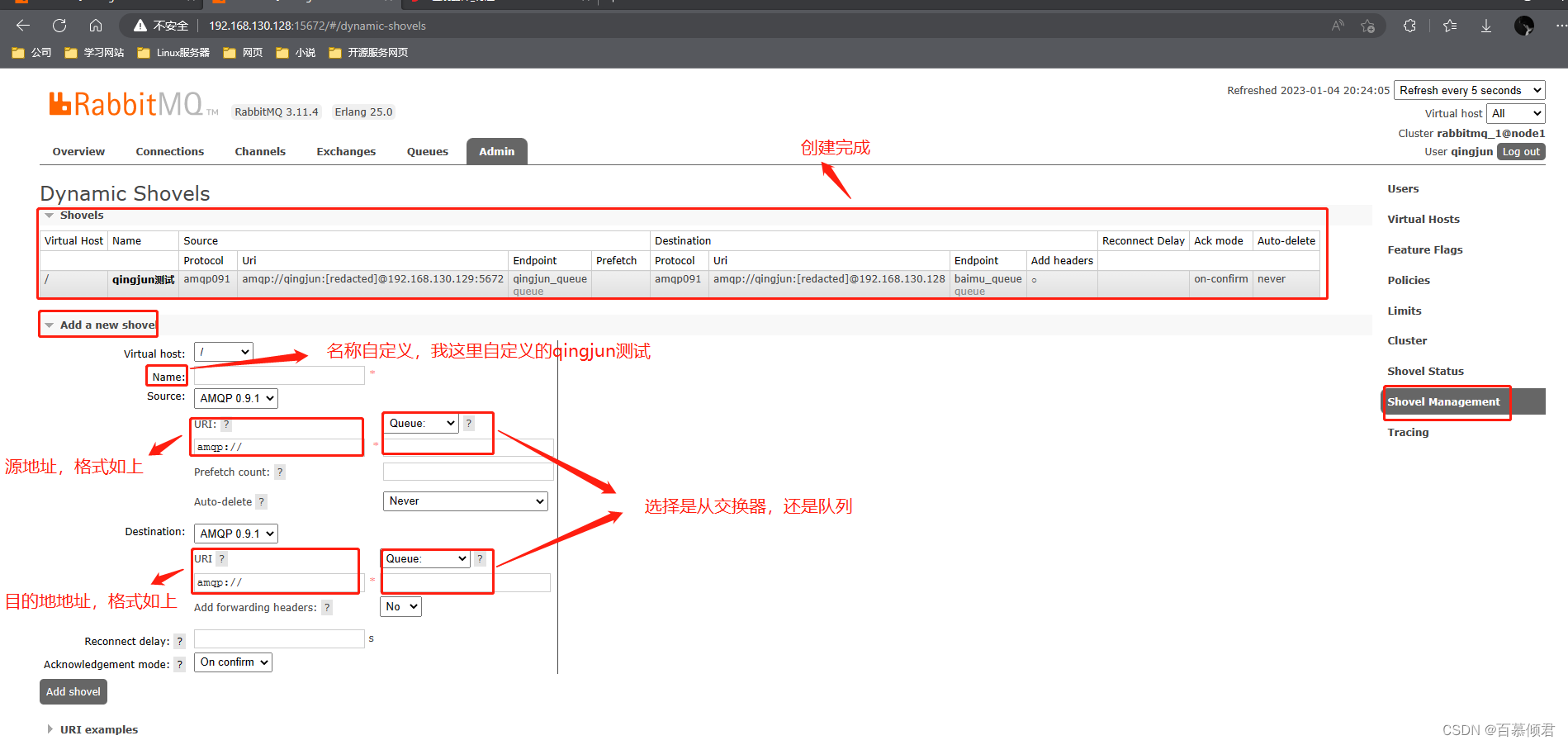
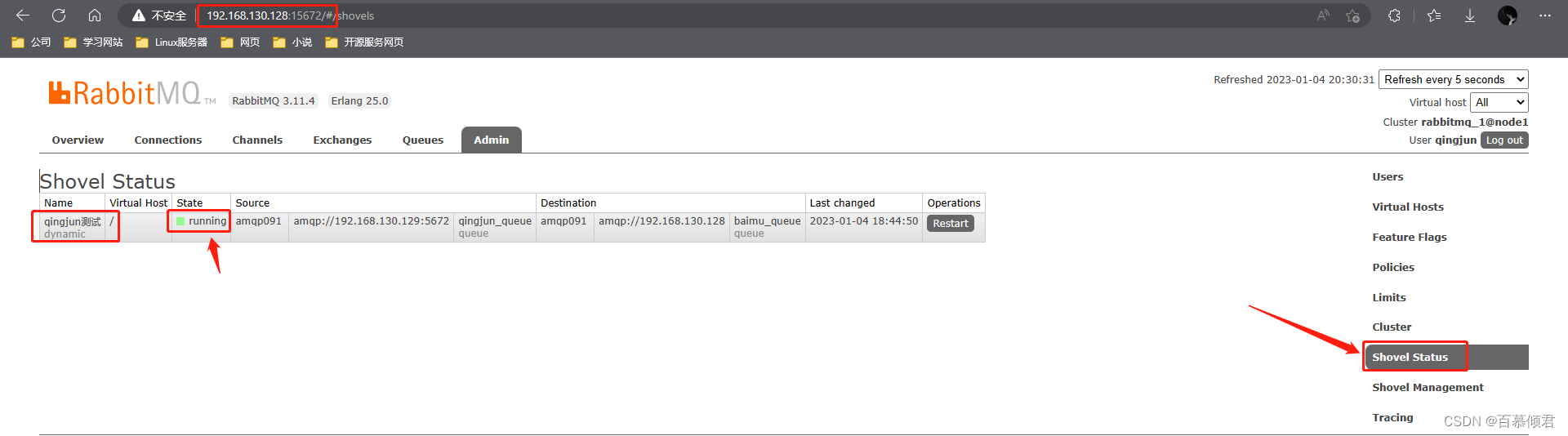
第四步,定义完了之后,可以查看状态,显示绿色代表已经接通,红色就是有问题。
2.2.3 效果测试
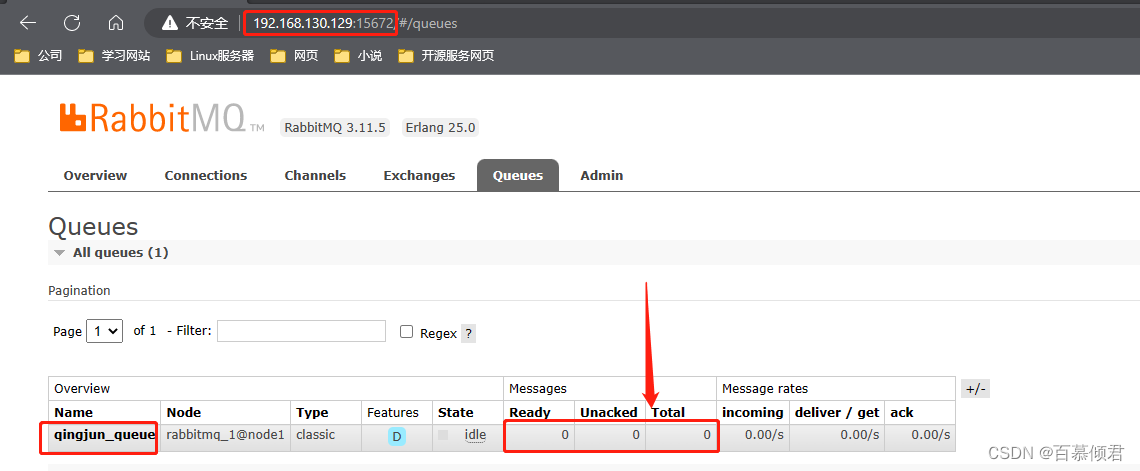
第五步,在源端qingjun_exchange交换器发送一条消息”wuhan“,查看qingjun_queue队列没有这条消息,消息已经转发给baimu_queue队列,查看此队列存在该条消息。
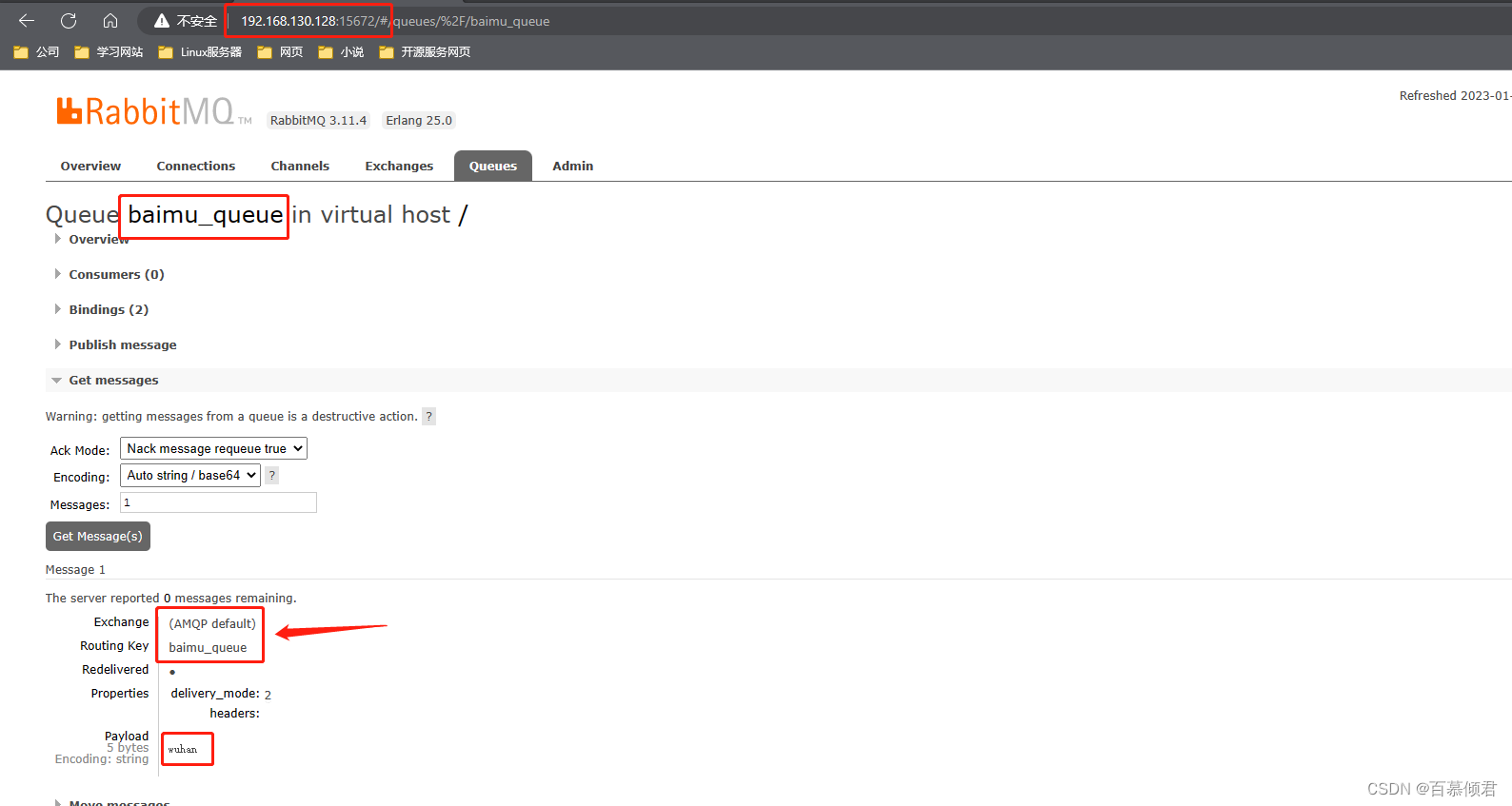
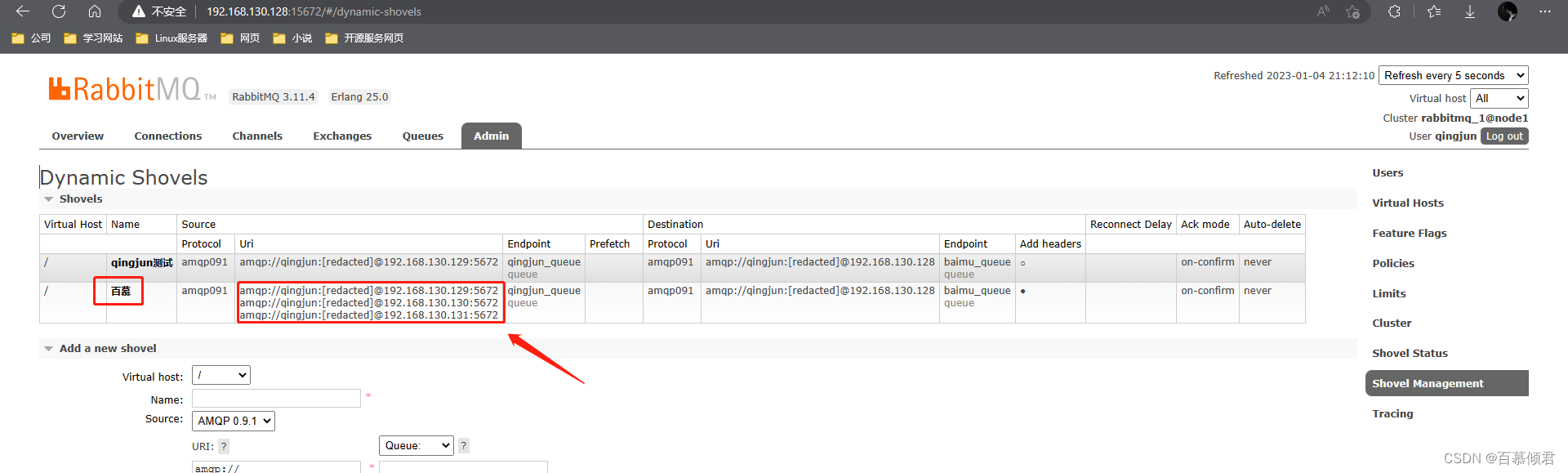
2.2.4 集群测试
1.如图,我配置了第二条Shovel link,相比单个来说就是多了几个源端地址,中间用一个空格隔开。
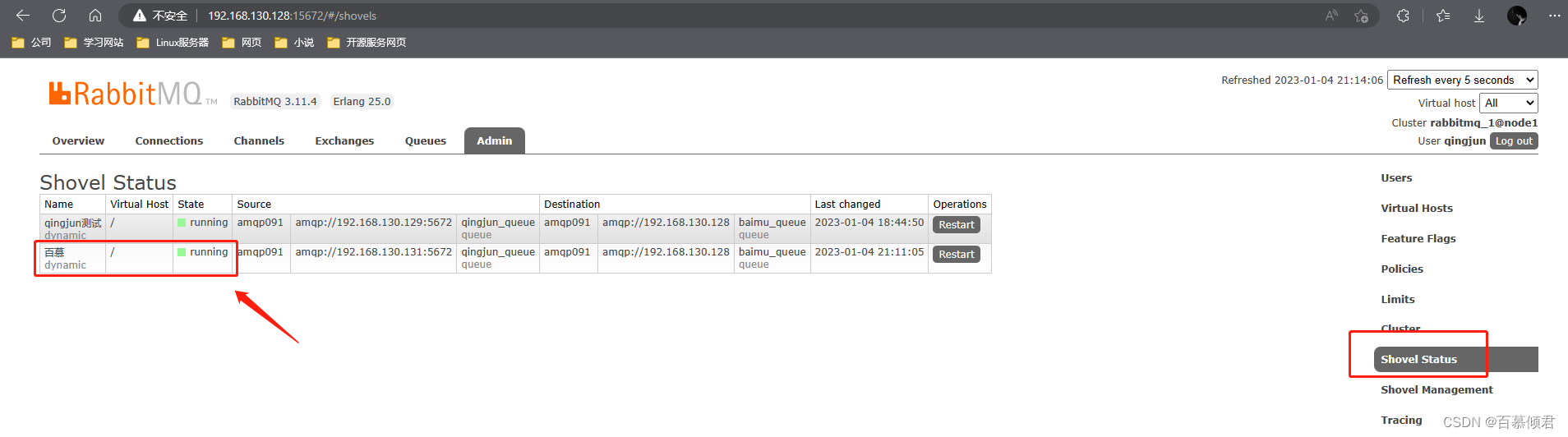
2.查看状态,绿色运行中,没问题。
3.给qingjun_exchange交换器发送第二条消息”beijing“,baimu_queue队列成功收到。

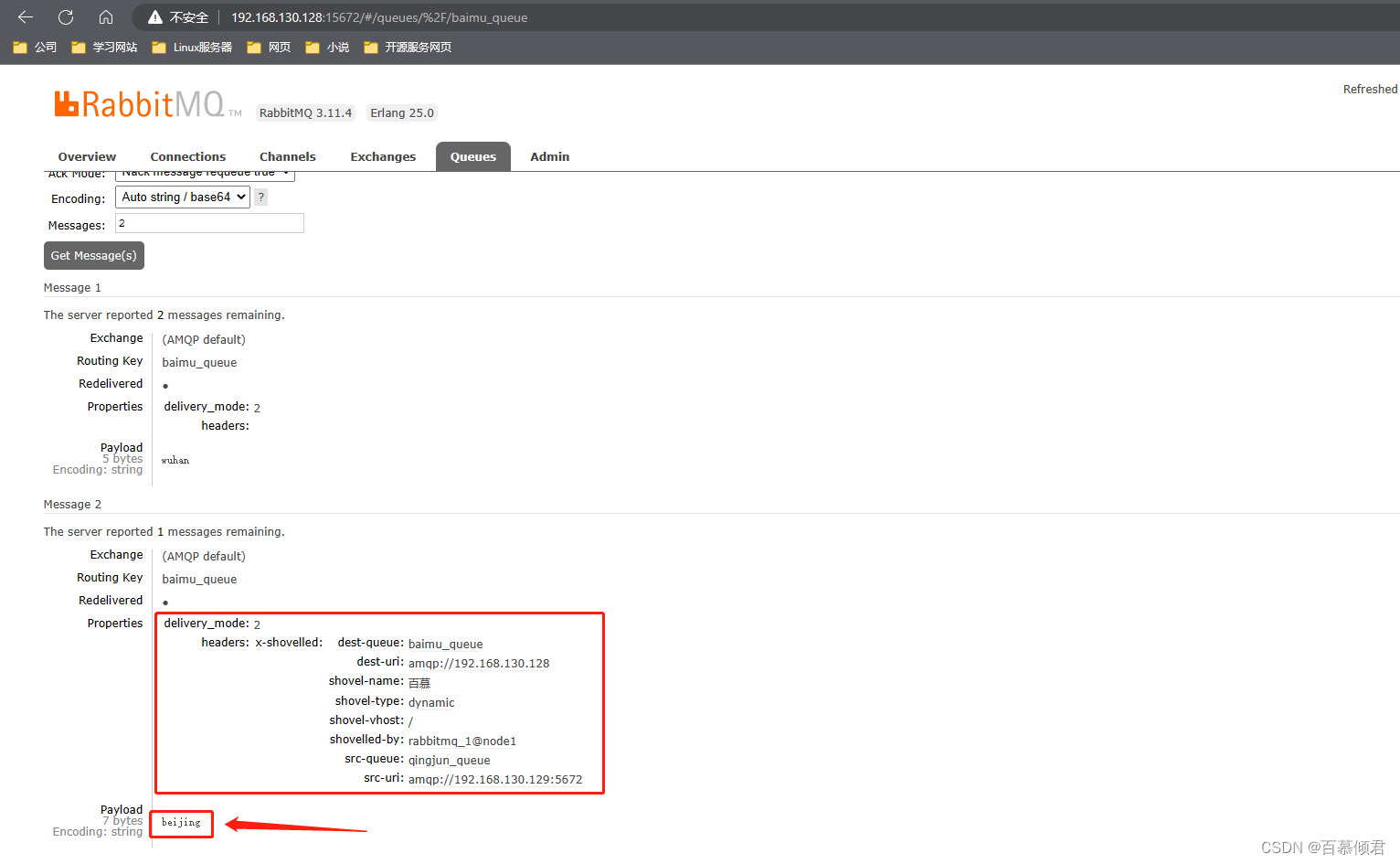
4.此时关闭192.168.130.130上的rabbitmq服务,模拟从节点异常,集群中的其他节点正常。注意不能时主节点,不然从节点是不能写的。
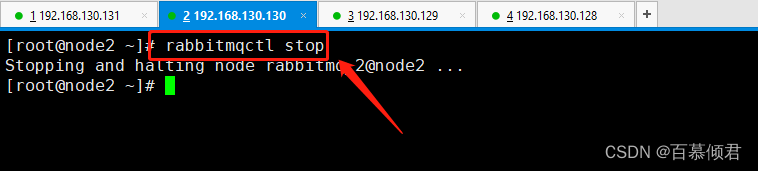
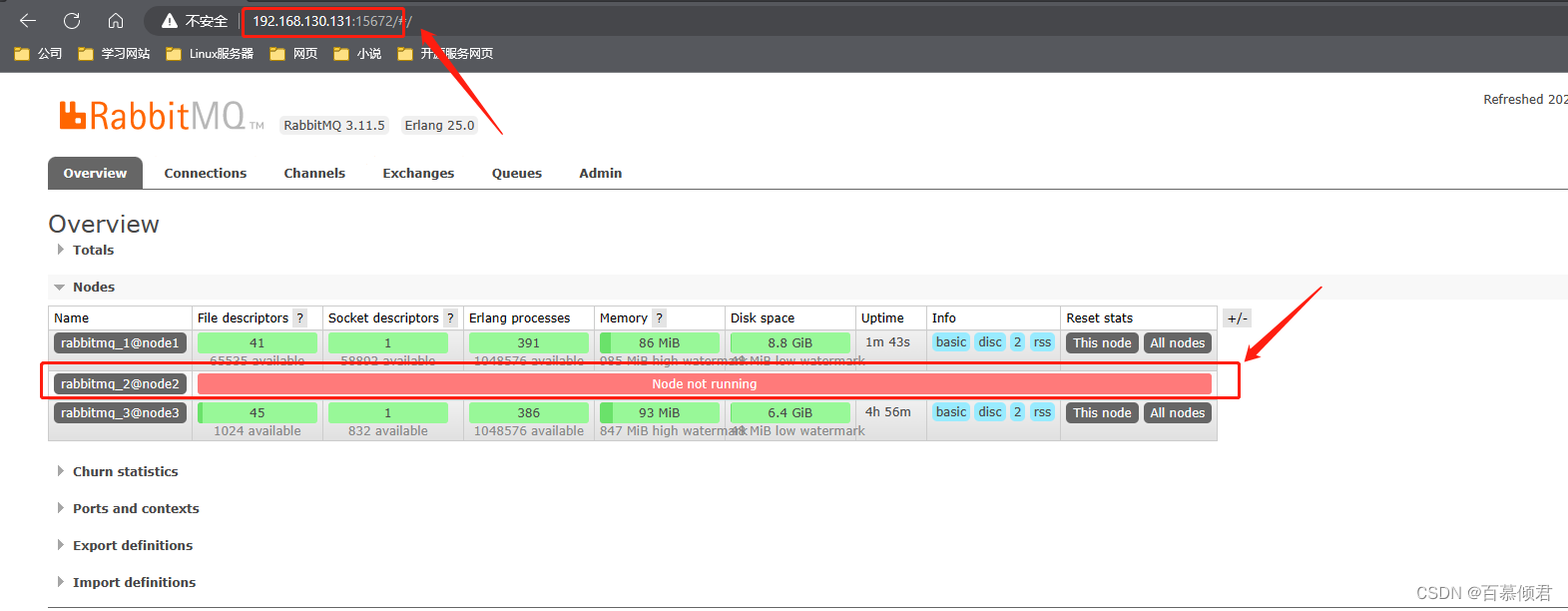
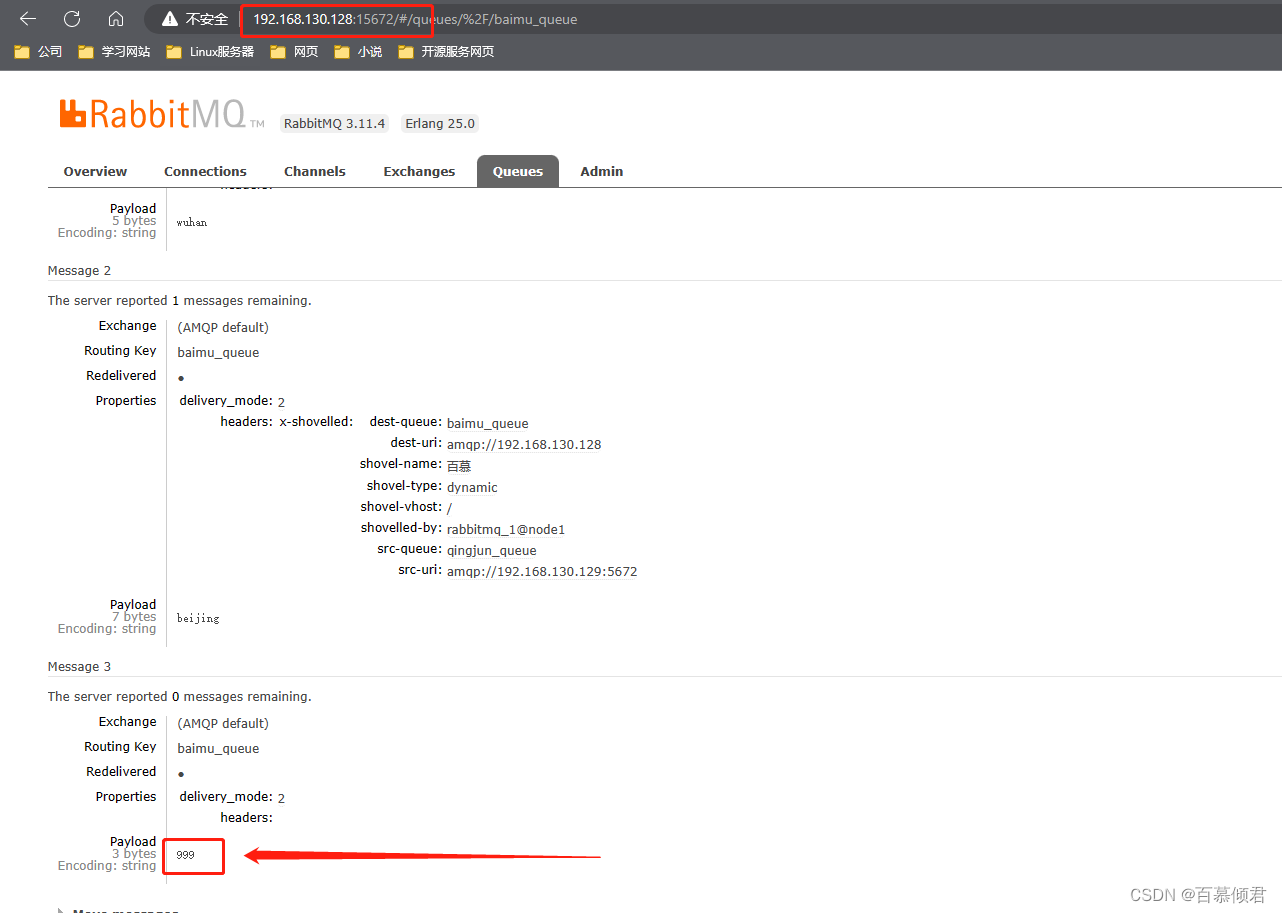
5.在第二个从节点192.168.130.131上发送第三条消息”999“,baimu_queue队列收到第三条消息,说明我们配置的第二个Shovel link目的已经达到。
2.3 命令创建
- 也可以通过rabbitmqctl命令来生成Shovel link。
- 相关参数:
- name:test_Shovel
- source-uri(源地址):amqp://user:password@ip:2576
- src-queue(源队列):qingjun_queue
- dest-uri(目的地址):amqp://user:password@ip:2576
- dest-queue(目的队列):wuhan_queue
- prefetch-count(内部缓存的消息条数):30
- reconnect-delay(shovel失效情况下,重新建立连接需要等待的秒数):5秒
- publish-properties(发往目的端需要设置的属性):空,代表不设置。
- ack-mode(转发消息时确认):on-confirm
2.3.1 创建Shovel link
1.添加一个Shovel link ,名称叫test_Shovel。
[root@node1 ~]# rabbitmqctl set_parameter shovel test_Shovel '{"src-uri":"amqp://qingjun:citms@192.168.130.129:5672","src-queue":"qingjun_queue","dest-uri":"amqp://qingjun:citms@192.168.130.128:5672","dest-queue":"wuhan_queue","prefetch-count":30,"reconnect-delay":5,"publish-properties":[],"ack-mode":"on-confirm"}'

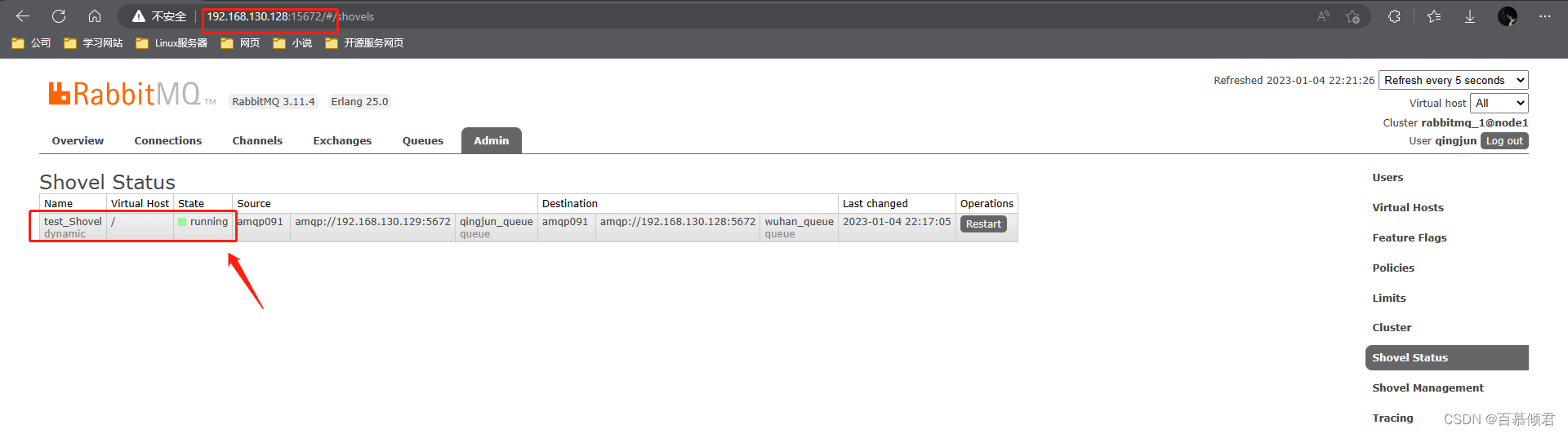
2.查看其状态。
3. 在源端发送一条消息“888”。
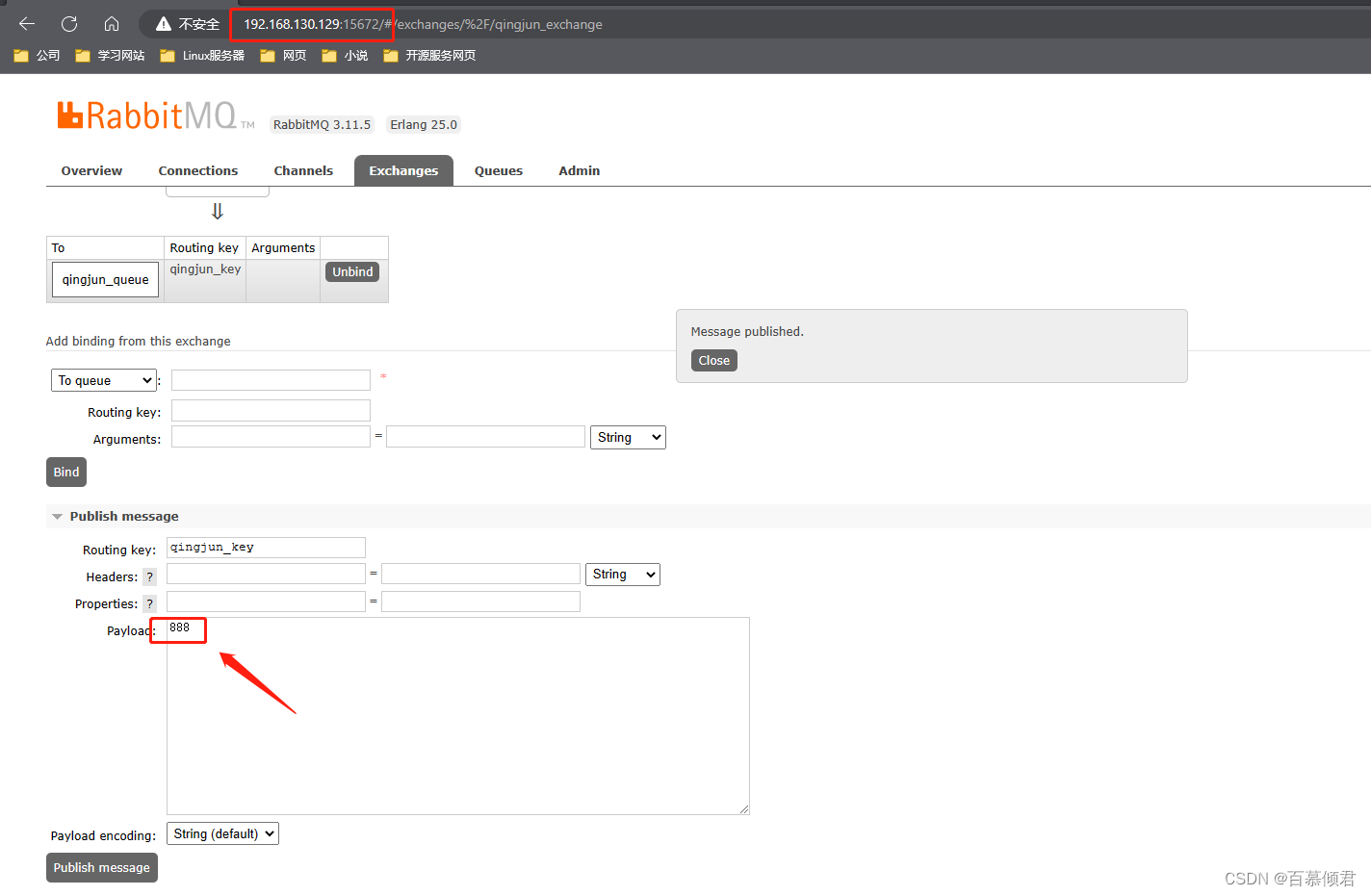
4.在目的地端查看结果。wuhan_queue已被创建,并收到消息。
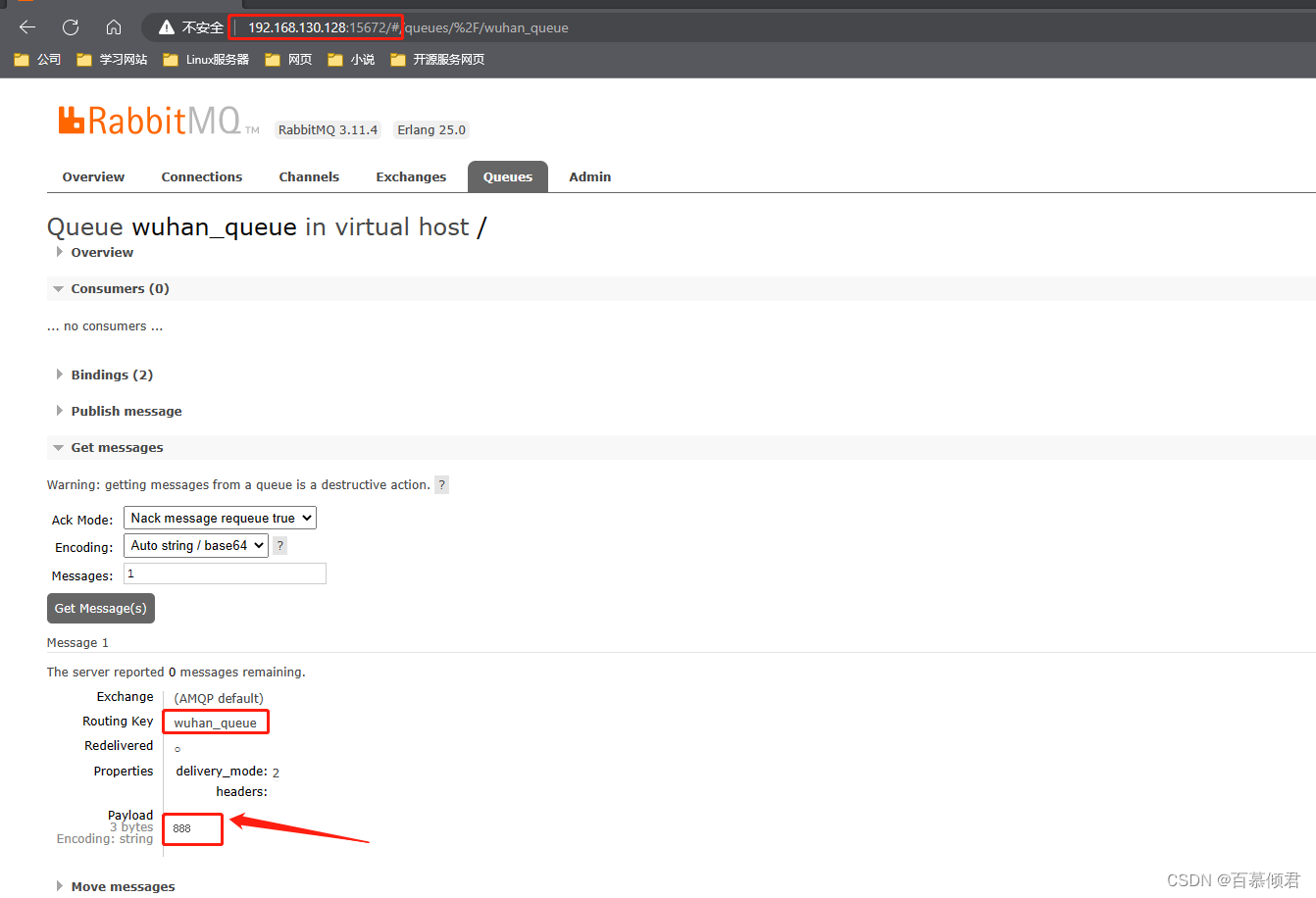
2.3.2 查看Shovel状态
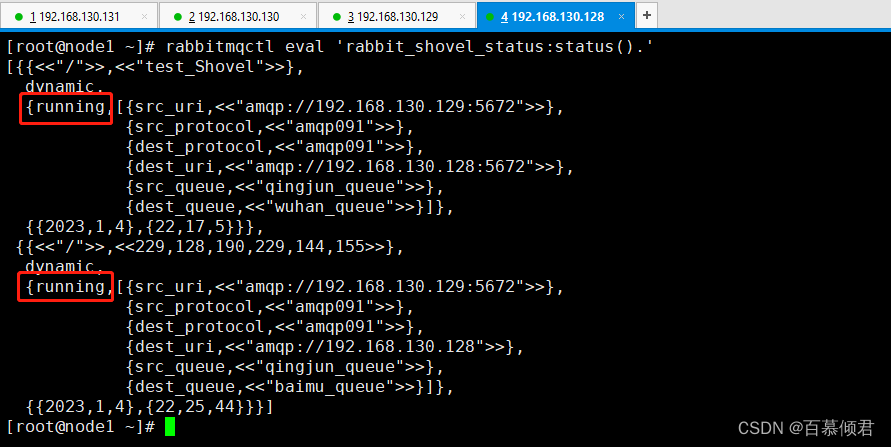
- 命令格式:rabbitmqctl eval ‘rabbit_shovel_status:status().’
- 参数释义:
- 第一行:显示该shovel link所在的虚拟空间和名称。名称是汉字则显示不出来。
- 第二行:运行状态和参数显示,状态有三种显示。
- 当 Shovel 处于启动、连接和创建资源时,显示starting。
- 当 Shovel 正常运行时,显示running。
- 当Shovel终止时时,显示terminated。
- 最后一行:时间戳显示,年月日,时分秒。
[root@node1 ~]# rabbitmqctl eval 'rabbit_shovel_status:status().'