1 DreamTalk介绍
DreamTalk:由清华大学、阿里巴巴和华中科大共同开发的一个基于扩散模型让人物头像说话的框架。 能够根据音频让人物头像照片说话、唱歌并保持嘴唇的同步和模仿表情变化。这一框架具有以下特点:
-
DreamTalk能够生成高质量的动画,使人物脸部动作看起来非常真实。
-
不仅嘴唇动作逼真,还能展现丰富的表情,使得动画更加生动。此外,DreamTalk还支持多种语言,无论是中文、英文还是其他语言,都能很好地同步。
-
DreamTalk还具有说话风格预测的功能,能够根据语音预测说话者的风格,并同步表情,使得动画更加贴近原始音频。
-
DreamTalk适用于多种场景,可以用于歌曲、不同类型的肖像,甚至在嘈杂环境中也能表现良好。
-
DreamTalk是一个具有创新技术的框架,能够为人物头像赋予说话和表情的能力,为多种领域带来更加生动和丰富的体验。
论文:https://arxiv.org/abs/2312.09767
GitHub:https://github.com/ali-vilab/dreamtalk
项目及演示:https://dreamtalk-project.github.io

2 DreamTalk工作原理
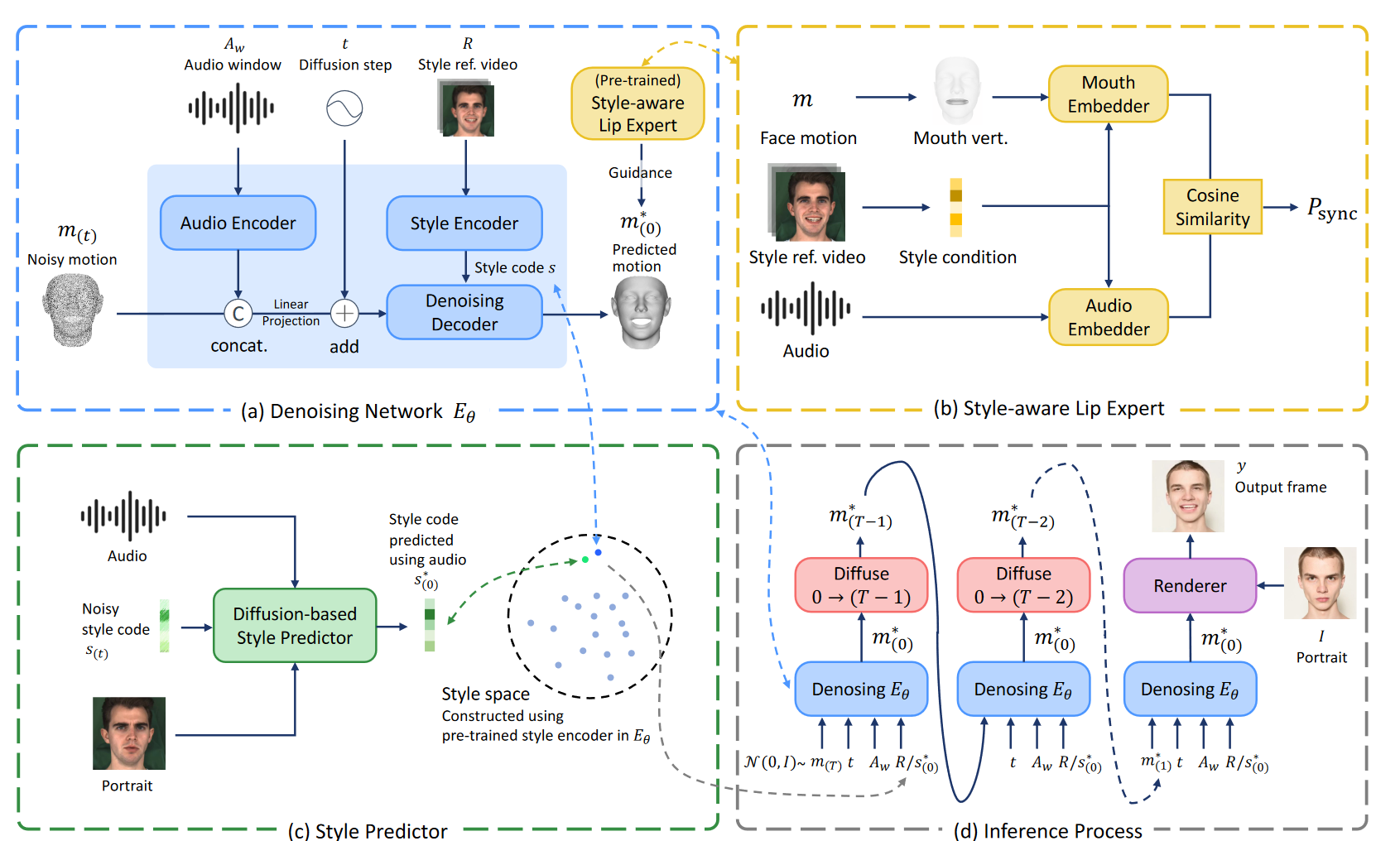
该项目在利用扩散模型在生成动态和表情丰富的说话头部方面取得突破。结合了以下几个关键组件来生成表情丰富的说话头部动画:
-
去噪网络:这是核心组件之一,负责生成音频驱动的面部动作。去噪网络使用扩散模型来逐步去除噪声,从而生成清晰、高质量的面部表情。这个过程涉及从带有噪声的数据中逐步恢复出清晰的面部动作。
-
风格感知的嘴唇专家:这个组件专注于提高嘴唇动作的表现力和准确性。它通过分析说话风格来引导嘴唇同步,确保生成的动画既自然又符合说话者的风格。
-
风格预测器:为了消除对表情参考视频或文本的依赖,DreamTalk引入了一个基于扩散的风格预测器。这个预测器可以直接从音频预测目标表情,无需额外的表情参考视频或文本。
-
音频和视频处理:处理音频输入,提取关键的音频特征,并将这些特征用于驱动面部动画。同时,它还能处理视频输入,以提取和模仿特定的表情和风格。
-
数据和模型训练:为了实现这些功能,DreamTalk需要大量的数据来训练其模型,包括不同表情和说话风格的面部动画数据。通过这些数据,模型学习如何准确地生成与输入音频匹配的面部动作。
DreamTalk不仅能够处理和生成它在训练过程中见过的面部类型和表情,还能有效处理和生成它之前未见过的、来自不同数据集的面部类型和表情。 包括不同种族、年龄、性别的人物肖像,以及各种不同的表情和情绪。
3 DreamTalk部署及使用
3.1 conda环境准备
conda环境准备详见:annoconda
3.2 运行环境构建
git clone https://github.com/ali-vilab/dreamtalk
cd dreamtalk/
conda create -n dreamtalk python=3.9
conda activate dreamtalk
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
conda update ffmpeg
pip install urllib3==1.26.6
pip install transformers==4.28.1
pip install dlib3.3 预训练模型下载
模型下载地址:dreamtalk/files

下载完成后,存入根目录的checkpoints目录,如下所示:
(dreamtalk) [root@localhost dreamtalk]# ll checkpoints/
总用量 374212
-rw-r--r-- 1 root root 47908943 1月 22 16:02 denoising_network.pth
-rw-r--r-- 1 root root 335281551 1月 22 16:08 renderer.ptwav2vec2-large-xlsr-53-english下载:wav2vec2-large-xlsr-53-english
下载完成后,存入jonatasgrosman目录下,如下所示:
(dreamtalk) [root@localhost dreamtalk]# ll jonatasgrosman/wav2vec2-large-xlsr-53-english/
总用量 1232504
-rw-r--r-- 1 root root 1531 1月 22 18:32 config.json
-rw-r--r-- 1 root root 262 1月 22 18:32 preprocessor_config.json
-rw-r--r-- 1 root root 1262069143 1月 22 18:34 pytorch_model.bin
-rw-r--r-- 1 root root 300 1月 22 18:34 vocab.json3.4 模型运行
运行中文示例:
python inference_for_demo_video.py --wav_path data/audio/acknowledgement_chinese.m4a --style_clip_path data/style_clip/3DMM/M030_front_surprised_level3_001.mat --pose_path data/pose/RichardShelby_front_neutral_level1_001.mat --image_path data/src_img/cropped/zp1.png --disable_img_crop --cfg_scale 1.0 --max_gen_len 30 --output_name output01运行结果如下所示:
运行过程显示:
(dreamtalk) [root@localhost dreamtalk]# python inference_for_demo_video.py --wav_path data/audio/acknowledgement_chinese.m4a --style_clip_path data/style_clip/3DMM/M030_front_surprised_level3_001.mat --pose_path data/pose/RichardShelby_front_neutral_level1_001.mat --image_path data/src_img/cropped/zp1.png --disable_img_crop --cfg_scale 1.0 --max_gen_len 30 --output_name output01
ffmpeg version 4.3 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 7.3.0 (crosstool-NG 1.23.0.449-a04d0)
configuration: --prefix=/opt/conda/conda-bld/ffmpeg_1597178665428/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placeh --cc=/opt/conda/conda-bld/ffmpeg_1597178665428/_build_env/bin/x86_64-conda_cos6-linux-gnu-cc --disable-doc --disable-openssl --enable-avresample --enable-gnutls --enable-hardcoded-tables --enable-libfreetype --enable-libopenh264 --enable-pic --enable-pthreads --enable-shared --disable-static --enable-version3 --enable-zlib --enable-libmp3lame
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'data/audio/acknowledgement_chinese.m4a':
Metadata:
major_brand : M4A
minor_version : 0
compatible_brands: M4A isommp42
creation_time : 2023-12-20T14:55:37.000000Z
iTunSMPB : 00000000 00000840 00000000 00000000000CBFC0 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
Duration: 00:00:17.41, start: 0.044000, bitrate: 246 kb/s
Stream #0:0(und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, mono, fltp, 244 kb/s (default)
Metadata:
creation_time : 2023-12-20T14:55:37.000000Z
handler_name : Core Media Audio
Stream mapping:
Stream #0:0 -> #0:0 (aac (native) -> pcm_s16le (native))
Press [q] to stop, [?] for help
-async is forwarded to lavfi similarly to -af aresample=async=1:min_hard_comp=0.100000:first_pts=0.
Output #0, wav, to 'tmp/output01/output01_16K.wav':
Metadata:
major_brand : M4A
minor_version : 0
compatible_brands: M4A isommp42
iTunSMPB : 00000000 00000840 00000000 00000000000CBFC0 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
ISFT : Lavf58.45.100
Stream #0:0(und): Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/s (default)
Metadata:
creation_time : 2023-12-20T14:55:37.000000Z
handler_name : Core Media Audio
encoder : Lavc58.91.100 pcm_s16le
size= 544kB time=00:00:17.40 bitrate= 256.0kbits/s speed= 581x
video:0kB audio:544kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.014003%
Some weights of the model checkpoint at jonatasgrosman/wav2vec2-large-xlsr-53-english were not used when initializing Wav2Vec2Model: ['lm_head.weight', 'lm_head.bias']
- This IS expected if you are initializing Wav2Vec2Model from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing Wav2Vec2Model from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
/root/anaconda3/envs/dreamtalk/lib/python3.9/site-packages/torch/nn/functional.py:4227: UserWarning: Default grid_sample and affine_grid behavior has changed to align_corners=False since 1.3.0. Please specify align_corners=True if the old behavior is desired. See the documentation of grid_sample for details.
warnings.warn(
ffmpeg version 4.3 Copyright (c) 2000-2020 the FFmpeg developers
built with gcc 7.3.0 (crosstool-NG 1.23.0.449-a04d0)
configuration: --prefix=/opt/conda/conda-bld/ffmpeg_1597178665428/_h_env_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placehold_placeh --cc=/opt/conda/conda-bld/ffmpeg_1597178665428/_build_env/bin/x86_64-conda_cos6-linux-gnu-cc --disable-doc --disable-openssl --enable-avresample --enable-gnutls --enable-hardcoded-tables --enable-libfreetype --enable-libopenh264 --enable-pic --enable-pthreads --enable-shared --disable-static --enable-version3 --enable-zlib --enable-libmp3lame
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'output_video/output01.mp4-no_watermark.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf58.45.100
Duration: 00:00:17.47, start: 0.000000, bitrate: 343 kb/s
Stream #0:0(und): Video: mpeg4 (Simple Profile) (mp4v / 0x7634706D), yuv420p, 256x256 [SAR 1:1 DAR 1:1], 270 kb/s, 25 fps, 25 tbr, 12800 tbn, 25 tbc (default)
Metadata:
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 16000 Hz, mono, fltp, 70 kb/s (default)
Metadata:
handler_name : SoundHandler
Stream mapping:
Stream #0:0 -> #0:0 (mpeg4 (native) -> mpeg4 (native))
Stream #0:1 -> #0:1 (aac (native) -> aac (native))
Press [q] to stop, [?] for help
[png @ 0x55ae8befb180] Application has requested 49 threads. Using a thread count greater than 16 is not recommended.
Output #0, mp4, to 'output_video/output01.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf58.45.100
Stream #0:0(und): Video: mpeg4 (mp4v / 0x7634706D), yuv420p, 256x256 [SAR 1:1 DAR 1:1], q=2-31, 200 kb/s, 25 fps, 12800 tbn, 25 tbc (default)
Metadata:
handler_name : VideoHandler
encoder : Lavc58.91.100 mpeg4
Side data:
cpb: bitrate max/min/avg: 0/0/200000 buffer size: 0 vbv_delay: N/A
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 16000 Hz, mono, fltp, 69 kb/s (default)
Metadata:
handler_name : SoundHandler
encoder : Lavc58.91.100 aac
[Parsed_movie_0 @ 0x55ae8bb43e40] EOF timestamp not reliable
frame= 435 fps=0.0 q=3.2 Lsize= 755kB time=00:00:17.40 bitrate= 355.3kbits/s speed=53.1x
video:596kB audio:150kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 1.199288%
[aac @ 0x55ae8b8a5240] Qavg: 166.775
(dreamtalk) [root@localhost dreamtalk]# 运行英文示例:
python inference_for_demo_video.py --wav_path data/audio/acknowledgement_english.m4a --style_clip_path data/style_clip/3DMM/M030_front_neutral_level1_001.mat --pose_path data/pose/RichardShelby_front_neutral_level1_001.mat --image_path data/src_img/uncropped/male_face.png --cfg_scale 1.0 --max_gen_len 30 --output_name acknowledgement_english@M030_front_neutral_level1_001@male_face