目录
🚀索引使用
🚀最左前缀法则
🚀范围查询
🚀索引失效情况
隐式类型转换是什么?
隐式类型转换的影响
举例说明
无隐式类型转换的情况
存在隐式类型转换的情况
总结
🚀模糊查询
🚀or连接条件
🚀数据分布影响
🚀索引使用
验证索引效率
案例:这是一张有1000w的记录的表 (此案例来自黑马,我觉得黑马的案例很详细)

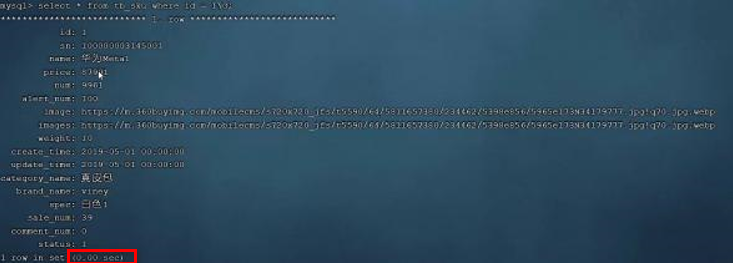
这张表中id为主键,有主键索引,而其他字段是没有建立索引的。先来查询其中的一条记录,看看里面的字段情况,执行如下SQL:
select * from tb_sku where id = 1\G;可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快0.00sec,因为主键id是有索引的。
接下来,我们再来根据 sn字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001 ';
我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索 引,而造成查询效率很低。
具体原因:首先,它没有使用索引。在没有索引的情况下,MySQL将扫描整个表来查找符合条件的行。这可能会导致性能下降,尤其是当表中的数据量很大时。

我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一 下查询耗时情况。
create index idx_sku_sn on tb_sku (sn) ;
然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT * FROM tb_sku WHERE sn = '100000003145001 ';
由此可以看出,建立了索引之后,查询的性能极大提升,因为MySQL可以使用索引来快速定位匹配的行,并进一步筛选符合额外条件的行。这将大大提高查询的效率,因为MySQL只需要访问少量的行来获取结果。

需要注意的是,索引并非在所有情况下都能提高查询性能。索引的选择和使用需要根据具体的数据和查询需求进行评估。过多或不必要的索引可能会增加写操作的开销,而且索引也需要占用额外的存储空间。因此,在设计和使用索引时,需要综合考虑查询频率、数据更新频率和存储成本等因素。
🚀最左前缀法则
show index from tb_user ; --显示tb_user表的索引如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始, 并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(即后面的字段索引失效)。
这些标记出来的是单链索引,主键id,phone,name,email
在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为: profession, age, status。
对于最左前缀法则指的是,查询时,最左变的列,也就是profession必须存在,否则索引全部失效。 而且中间不能跳过某一列,否则该列后面的字段索引将失效.
演示:
explain select * from tb_user where profession = '化工 ' and age = 38 and status
= '5 ';

explain select * from tb_user where profession = '化工 ' and age = 38;
explain select * from tb_user where profession = '化工 '; 
以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不 过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、 age 字段索引长度为2、 status字段索引长度为5。
explain select * from tb_user where age = 38 and status = '5 ';
explain select * from tb_user where status = '5 ';
而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引 最左边的列profession不存在。
explain select * from tb_user where profession = '化工 ' and status = '5 ';
上述的SQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条 件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索 引的长度就是47。
思考题:
当执行SQL语句 :
explain select * from tb_user where age = 38 and status = '0' and profession = '化工 '; 是否满足最左前缀法则,走不走上述的联合索引,索引长度是多少?(也就是顺序换了之后还成不成立了)

可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
注意 :最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是
第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关。
🚀范围查询
联合索引中,出现范围查询 (>,<),范围查询右侧的列索引失效。
explain select * from tb_user where profession = '化工 ' and age > 30 and status
= '5 ';

当范围查询使用> 或 < 时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字段是没有走索引的。
explain select * from tb_user where profession = '化工 ' and age >= 30 and
status = '5 ';

当范围查询使用>= 或 <= 时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引的。所以,在条件允许的情况下,尽可能的使用类似于 >= 或 <= 这类的范围查询,而避免使用 > 或 <
🚀索引失效情况
索引列运算
不要在索引列上进行运算操作,索引将失效
在tb_user表中,除了前面介绍的联合索引之外,还有一个索引,是phone字段的单列索引。

当根据phone字段进行等值匹配查询时, 索引生效。
explain select * from tb_user where phone = '17799990015 ';
当根据phone字段进行函数运算操作之后,索引失效。
explain select * from tb_user where substring (phone,10,2) = '15 ';
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
示例:加单引号与不加单引号的区别
explain select * from tb_user where profession = '化工 ' and age = 38 and status
= '5 ';

explain select * from tb_user where profession = '化工 ' and age = 38 and status
= 5 ;

explain select * from tb_user where phone = '17799990015 ';
explain select * from tb_user where phone = 17799990015;

经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数 据库存在隐式类型转换,索引将失效。
隐式类型转换是什么?
隐式类型转换是指在比较操作中,MySQL会自动将一个数据类型转换成另一个数据类型,以便进行比较。这种转换是在不明确指定的情况下自动发生的,用户不需要显式地进行类型转换操作。
隐式类型转换的影响
隐式类型转换可能导致索引失效,从而影响查询性能。当查询条件中的数据类型与列的数据类型不匹配时,MySQL会进行隐式类型转换,将查询条件的数据类型转换成列的数据类型进行比较。如果数据类型不匹配,MySQL可能无法充分利用索引,而是需要进行全表扫描来查找符合条件的行,导致性能下降。
举例说明
无隐式类型转换的情况
假设我们有一个名为
users的表,包含以下列:+----+---------+--------+ | id | name | age | +----+---------+--------+ | 1 | Alice | 25 | | 2 | Bob | 30 | | 3 | Charlie | 35 | | 4 | David | 40 | | 5 | Eve | 45 | +----+---------+--------+如果我们对
name列创建了索引,并执行以下查询:SELECT * FROM users WHERE name = 'Alice';由于查询条件中的数据类型与列的数据类型完全匹配,MySQL可以充分利用索引来快速定位和访问符合条件的数据,从而提高查询效率。
存在隐式类型转换的情况
现在假设我们对
age列创建了索引,并执行以下查询:SELECT * FROM users WHERE age = 30;在这个例子中,由于查询条件中的数据类型与列的数据类型完全匹配,MySQL可以充分利用索引。
但是,如果我们执行以下查询:
SELECT * FROM users WHERE age = '30';在这个例子中,查询条件中的数据类型是字符串,而列的数据类型是整数。MySQL将会进行隐式类型转换,将字符串转换成整数进行比较。这可能导致索引失效,从而影响查询性能。
总结
隐式类型转换可能导致索引失效,影响查询性能。为了避免这种情况,我们应该尽量确保查询条件中的数据类型与列的数据类型完全匹配,以充分利用索引提高查询效率。
🚀模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
接下来,我们来看一下这三条SQL语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据profession字段查询,符合最左前缀法则,联合索引是可以生效的, 我们主要看一下,模糊查询时,%加在关键字之前,和加在关键字之后的影响。
explain select * from tb_user where profession like '金属% ';
explain select * from tb_user where profession like '%材料 ';
explain select * from tb_user where profession like '%材% ';

经过上述的测试,我们发现,在like模糊查询中,在关键字后面加%,索引可以生效。而如果在关键字前面加了%,索引将会失效。
🚀or连接条件
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select * from tb_user where id = 6 or age = 33;
explain select * from tb_user where phone = '15377777775 ' or age = 27;

第二个指令输出的结果很明显,只有phone有索引,后面的age没有索引,所以涉及的索引都不会用到,由于age没有索引,所以即使id、 phone有索引,索引也会失效。所以需要针对于age也要建立索引。
然后,我们可以对age字段建立索引。
create index idx_user_age on tb_user (age);
建立了索引之后,我们再次执行上述的SQL语句,看看前后执行计划的变化。

最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
🚀数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
select * from tb_user where phone >= '17799990005 ';
select * from tb_user where phone >= '17799990015 ';


经过测试我们发现,相同的SQL语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为什么呢?
就是因为MySQL在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
我们再来看看 is null 与 is not null 操作是否走索引。
执行如下两条语句 :
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;

接下来,我们做一个操作将profession字段值全部更新为null
update tb_user set profession = null ;
然后,再次执行上述的两条SQL,查看SQL语句的执行计划

最终我们看到,一模一样的SQL语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象,这是和数据库的数据分布有关系,查询时MySQL会评估,走索引快,还是全表扫描快,如果全表 扫描更快,则放弃索引走全表扫描. 因此, is null 、is not null是否走索引,得具体情况具体分析,并不是固定的
希望对大家有帮助!