「发表于知乎专栏《移动端算法优化》」
本文首先对 GPU 进行了概述,然后着重地对移动端的 GPU 进行了分析,随后我们又详细地介绍了 OpenCL 的背景知识和 OpenCL 的四大编程模型。希望能帮助大家更好地进行移动端高性能代码的开发。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、概述
二、从 GPU 到 GPGPU
2.1 GPU 简介
2.2 从 GPU 到 GPGPU
三、GPU 硬件介绍
3.1 GPU与CPU的比较
3.2 Qualcomm Adreno GPU
3.3 ARM Mali GPU
四、OpenCL 介绍
4.1 什么是OpenCL?
4.2 OpenCL的诞生与发展
4.3 OpenCL的四大模型
五、总结
一、概述
如今的时代是一个数据爆炸的时代,如何处理海量的数据是各行各业不得不面临的一个重要问题。随着摩尔定律的失效,支持大量并行计算的异构处理器开始大放异彩。其中,无论是在 PC 端还是移动端,GPU 无疑是其中最璀璨的明星。
接下来,我们首先会对 GPU 的发展历史和硬件架构(移动端)进行简单地介绍,随后对 OpenCL 编程框架进行详细的介绍。
二、从 GPU 到 GPGPU
2.1 GPU 简介

GPU 简介
GPU (Graphics Processing Unit) 图形处理器,又称为显示核心、视觉处理器、显示芯片, 是一种专门在个人电脑、工作站、游戏机和移动设备(平板电脑、手机)上做图像和图形相关相关运算工作的微处理器。
GPU 通常可以分为如下几类:
| 独立 GPU | 封装在独立的电路板,专用的显存(显示储存器) | 性能高,功耗大 |
|---|---|---|
| 集成 GPU | 内嵌到主板上,共享系统内存 | 性能中等,功耗中等 |
| 移动端 GPU | 嵌在 SoC(System On Chip)中,共享系统内存 | 性能低,功耗低 |
2.2 从 GPU 到 GPGPU
在 GPU 发展早期,由于其主要面向图形绘制等操作,功能相对来说比较单一。后来,NVIDIA公司发展了一种可编程的着色器,每个像素经过一段“简短”的程序计算,然后在将结果投到屏幕上。2007年,NVIDIA更进一步地提出了CUDA(Compute Unified Device Architecture,统一计算架构)用于通用计算领域。
此后,专注于通用并行计算能力的 GPU 也有了新的名称:GPGPU(General-Purpose computing on Graphics Processing Units)。
近年来,AI、区块链等技术的蓬勃发展对算力的需求愈发强烈,GPU 也受到了前所未有的关注。在 PC 端,NVIDIA 和 AMD 瓜分了几乎整个市场。而在移动端,则主要以高通的 Adreno GPU和 ARM 的 Mali GPU 占主导。
三、GPU 硬件介绍
3.1 GPU与CPU的比较

GPU 与 CPU 的硬件比较
| CPU | GPU | |
|---|---|---|
| 数据吞吐量 | 小 | 大 |
| 计算核心数量 | 少 | 非常多 |
| 控制单元 | 可以进行复杂的逻辑判断 | 简单的逻辑判断 |
| 算术逻辑单元 | 计算快,延迟低 | 计算较慢,延迟较高 |
| 缓存 | 大 | 小 |
从上面可以看出,与CPU相比,GPU更擅长处理逻辑判断较简单、数据量大的可并行计算任务。
3.2 Qualcomm Adreno GPU
3.2.1 Adreno GPU 简介
高通 Adreno GPU,其前身是 AMD 的移动 GPU Imageon 系列,在 2009 年被高通收购,并改名为 Adreno GPU。每一代的高通骁龙 SoC 也都无一例外地集成了 Adreno GPU。
下面是对部分 Adreno GPU 信息的整理:

Adreno GPU 信息列表
3.3 ARM Mali GPU
3.3.1 Mali GPU简介:
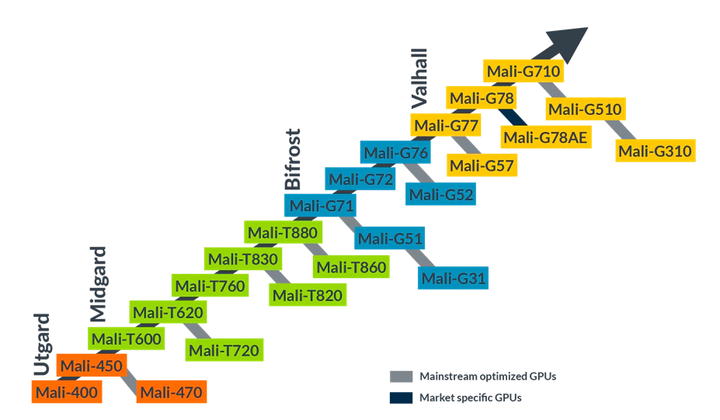
Mali GPU的架构发展
Mali 是一款由 ARM Holdings 研发设计的 移动GPU系列。Mali GPUs 是由 Falanx Microsystems A/S 发展而来,其最初是挪威科技大学孵化的一个研究项目。2006年,Falanx Microsystems A/S 被 ARM Holdings 收购后改名为ARM Norway,并继续负责 ARM Mali GPU 系列的研发设计。
Mali 的架构一共经历了四个架构的更迭,分别为 Utgard、Midgard、Bifrost、Valhall。2021年,Valhall 架构已经更新到了第三代,以 Mali-G710、Mali-G510、Mali-G310 为代表。
下面我们列举一些具体的 Mali GPU 的信息:

Mali GPU 信息列表
3.3.2 Mali-G710的硬件架构介绍:
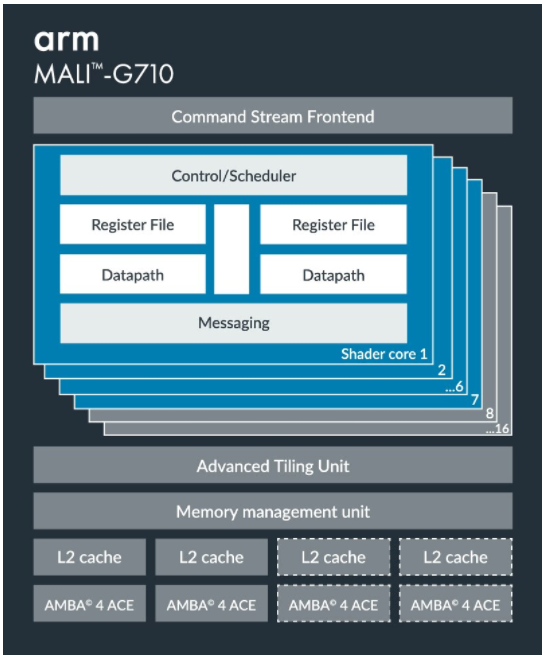
Mali-G710 示意图
Mali GPU 的基本处理单元为 Shader Core(类似于 Adreno GPU 中的 SP)。每个 Shader Core 中有自己的指令缓存、调度器、寄存器资源、缓存和运算单元。
但值得注意的是,Mali GPU 并没有像其他 GPU 一样内嵌到片上的 Local Memory 和 Private Memory,而是通过 Global Memory + Cache 的方法来代替。这意味着每当你使用 OpenCL 申请 Local Memory 或者 Private Memory 的时候,你实际上申请的是 Global Memory。将数据从 Global Memory 拷贝到 Local Memory 也并不会对性能有任何提高。
截止到 2021 年 12 月,基于 Valhall 架构的第三代 GPU Mali-G710 是性能最高的 Arm GPU。相较前一代,G710 在性能上和能效上均提升了 20%,且对于机器学习的性能也有 35% 的提升。可选核心数量为 7~16,L2 Cache 在 512KB 到 2MB 之间。
四、OpenCL 介绍
4.1 什么是OpenCL?
OpenCL(Open Computing Language, 开放设计语言) 是一个为异构平台(CPU/GPU/DSP/FPGA等等)编程设计的框架。OpenCL 由一门编写 kernel 的语言(基于C99)和一组用于定义和控制平台的 API 来组成,主要用于并行运算方面。
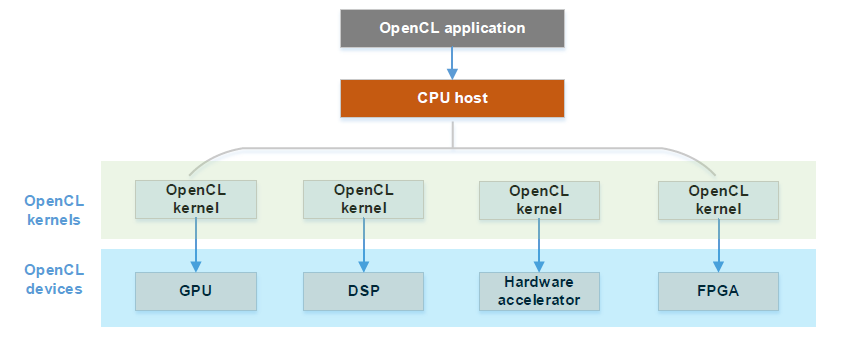
OpenCL - 异构计算框架
4.2 OpenCL的诞生与发展
由于各个硬件厂家在 GPU 硬件设计上存在着较大差别,为了降低跨平台的开发难度,人们迫切需要一套能够兼容各类硬件设备的计算框架。
OpenCL 最初由苹果公司开发,拥有其商标权。2008 年,苹果公司向 Khronos Group 提交了一份关于跨平台计算框架 (OpenCL) 的草案,随后与 AMD、IBM、Intel、和 NVIDIA 公司合作逐步完善,其接口大量借鉴了 CUDA。后续,OpenCL 的管理权移交给了非盈利组织 Khronos Group,且于2008年12月发布了 OpenCL 1.0。最新的OpenCL 3.0 于 2020 年 9 月发布。

OpenCL各版本的发布时间
为了更好地适用于不同处理器,OpenCL 抽象出了如下四大模型:
- 平台模型:对不同硬件及软件实现抽象,方便应用于不同设备;
- 存储模型:对硬件的各种存储器进行了抽象;
- 执行模型:程序是如何在硬件上执行的(任务划分 & 计算流程管理);
- 编程模型:数据并行和任务并行。
我们接下来将对这四种模型进行详细讲解。
4.3 OpenCL的四大模型
4.3.1 平台模型

OpenCL 平台模型图示
在 OpenCL 中,我们首先需要一个主机处理器(Host),一般是 CPU。而其他的硬件处理器(多核CPU/GPU/DSP 等)被抽象成 OpenCL 设备(Device)。每个设备包含多个计算单元(Compute Unit),每个计算单元又包含多个处理单元(Processing Element)。
Device 对应我们上面提到的 Adreno GPU 和 Mali GPU,计算单元 CU 对应 Adreno GPU 中的 SP 和 Mali GPU 中的 Shader Core,而处理单元 PE 可以对应 SP 和 Shader Core 中的运算单元。
在执行中,主要的流程为 Host 端发送数据和任务给 Device 端,Device 端进行计算,最后在 Host 端进行同步。
4.3.2 存储器模型
OpenCL 异构平台由主机端和设备端构成,存储器区域包含主机与设备的存储。
在 OpenCL 中具体定义了下面几种不同的存储区域:
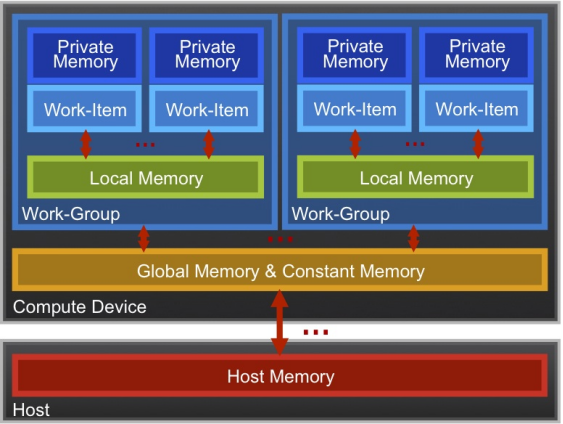
OpenCL 储存器模型示意图
- 主机存储(Host Memory):主机可用的存储,通常对应主机 (Host) 端的内存,可以通过直接传输/共享内存的方式与设备端进行数据传输;
- 全局存储 (Global Memory):通常指显存,允许上下文中任何设备上工作组 (Work Group) 中的所有工作项 (Work Item) 读写;
- 常量存储(Constant Memory):片上特殊内存,只读,在内核执行期间数据保持不变;
- 局部存储(Local Memory):对整个工作组内部所有的工作项可见,用于同一工作组内部工作项之间的数据共享;
- 私有存储 (Private Memory):工作项的私有区域,对其它工作项不可见,在硬件实现上通常映射为寄存器。
在 OpenCL 中,全局存储器中的数据内容通过存储对象来表示(Memory Object),在 OpenCL 中较为常用的两个存储对象为:Buffer Objects 和 Image Objects
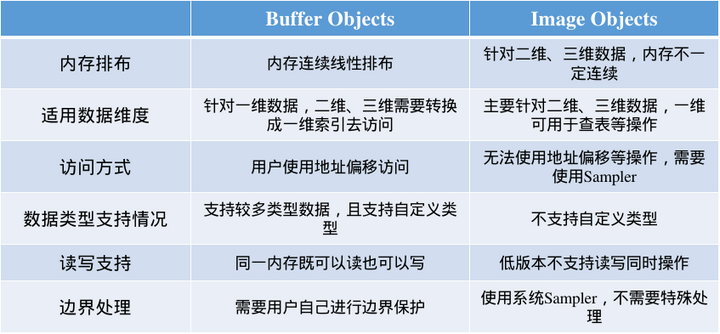
Buffer Object 与 Image Object
4.3.3 执行模型
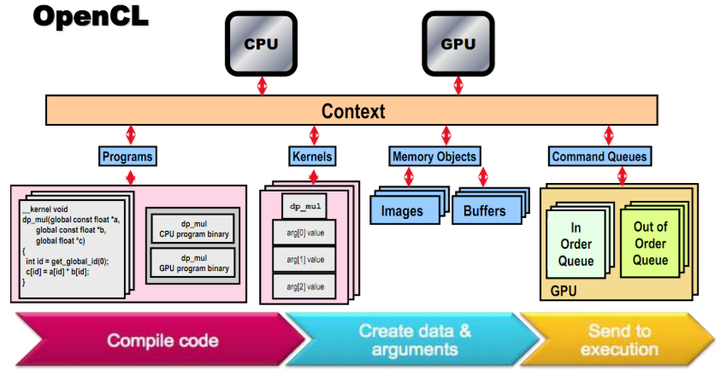
OpenCL 执行模型图示
在理解 OpenCL 的执行模型时,我们需要知道如下几个概念:
- Context(上下文):每个device对应一个Context,Host端通过Context与Device端进行交互和管理;
- Command Queue(命令队列):Host 端对计算设备进行控制的通道,推送一系列的命令让Device端去执行,包括数据传输、执行计算任务等。一个命令队列只能管理一个设备,可以顺序执行也可以乱序执行;
- Kernel Objects (内核对象):OpenCL 计算的核心部分,表现为一段C风格的代码。在需要设备执行计算任务时,数据会被推送到Device端,然后 Device 端的多个计算单元会并发地执行内核程序,完成预定的计算过程;
- Program Objects(程序对象):内核对象的集合,在 OpenCL 中使用 cl_program 表示程序对象,可以使用源代码文本或者使用二进制数据来创建。
那么,如何更好地控制多核之间的并行计算呢?OpenCL 会对任务进行划分,可以分割成一维、二维和三维的任务网格,一般为二维。这里,我们以二维来举例:
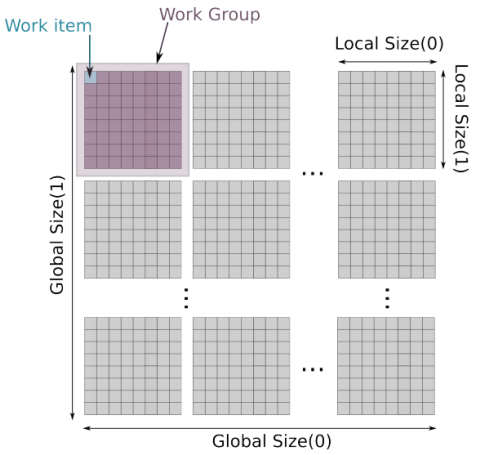
OpenCL的任务划分网格
- 首先,需要用户自定义总的工作项网格 [G0 x G1] 作为Global Size;
- 然后,用户定义一个更小的网格 [L0 x L1] 作为Local Size(一般来说G0/G1是L0/L1的倍数);
- 同一个Local Size中的运算任务会被打包给到一个Work Group中,其中的每个Work Item并发地执行。
- 这样,每个Work Item在Global Size中会有一个唯一的全局索引(Gx, Gy);同时,也有一个对应的局部索引(Lx, Ly)。通过可以利用这些索引,可以让我们更加灵活地设计内核函数。
4.3.4 编程模型
OpenCL 定义了两种不同的编程模型:任务并行和数据并行。
- 数据并行模式中,划分计算数据,分配给不同的计算单元进行同时计算,适用于数据相互独立的计算任务。
- 任务并行是指,计算步骤的每一个步骤有前后依赖,这使得我们无法将计算任务并行执行。于是,我们只能对每一个步骤的数据进行并行,之后将整个流程进行异步/同步串行执行,为了协调整个流程的先后关系,OpenCL 提供了Event 机制用来进行流程同步控制。
五、总结
本文首先对 GPU 进行了概述,然后着重地对移动端的 GPU 进行了分析,随后我们又详细地介绍了 OpenCL 的背景知识和 OpenCL 的四大编程模型。希望能帮助大家更好地进行移动端高性能代码的开发。
参考资料
- https://en.wikipedia.org/wiki/Adreno
- https://en.wikipedia.org/wiki/Mali_(GPU)
- https://developer.arm.com/ip-products/graphics-and-multimedia/mali-gpus
- https://www.qualcomm.com/products/features/adreno
- https://developer.arm.com/documentation/100614/0314/OpenCL-concepts
- 「发表于知乎专栏《移动端算法优化》」
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!