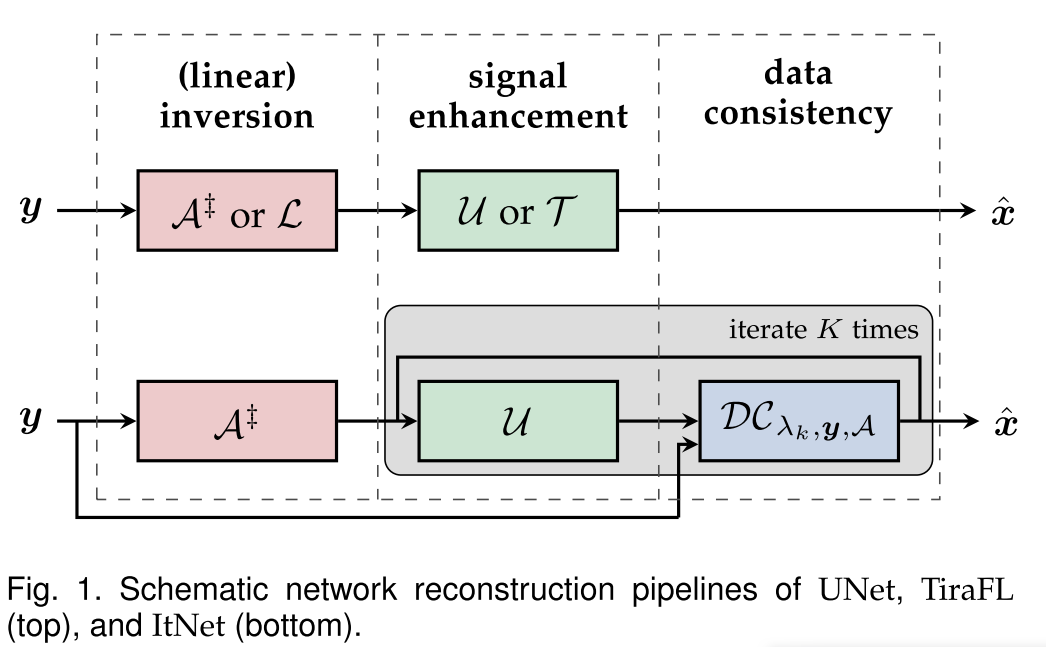
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
介绍物体检测
为训练创建边界框ground truth
安装图片标注工具
了解区域提案
利用 SelectiveSearch 生成区域建议
实施 SelectiveSearch 以生成区域建议
了解 IoU
非最大抑制(Non-max suppression)
平均平均精度
训练基于 R-CNN 的自定义对象检测器
R-CNN的工作细节
在自定义数据集上实现 R-CNN 进行对象检测
下载数据集
准备数据集
获取区域建议和偏移量的基本事实
创建训练数据
R-CNN 网络架构
预测新图像
训练基于 Fast R-CNN 的自定义对象检测器
Fast R-CNN 的工作细节
在自定义数据集上实现 Fast R-CNN 以进行对象检测
概括
问题
到目前为止,在前面的章节中,我们学习了执行图像分类。想象一下我们将计算机视觉用于自动驾驶汽车的场景。不仅需要检测道路图像是否包含车辆、人行道和行人的图像,识别这些物体的位置也很重要。我们将在本章和下一章学习的各种对象检测技术将在这种情况下派上用场。
在本章和下一章中,我们将学习一些用于执行对象检测的技术。我们将首先学习基础知识——使用名为 的工具标记边界框对象的基本事实,ybat使用该方法提取区域建议,并使用交并比( IoU ) 度量和均值selectivesearch定义边界框预测的准确性平均精度指标。在此之后,我们将了解两个基于区域提议的网络——R-CNN 和 Fast R-CNN,首先了解它们的工作细节,然后在包含卡车和公共汽车图像的数据集上实现它们。
本章将涵盖以下主题:
- 介绍物体检测
- 为训练创建边界框ground truth
- 了解区域提案
- 了解 IoU、非最大抑制和平均平均精度
- 训练基于 R-CNN 的自定义对象检测器
- 训练基于 Fast R-CNN 的自定义对象检测器
介绍物体检测
随着自动驾驶汽车、面部检测、智能视频监控和人数统计解决方案的兴起,对快速准确的物体检测系统的需求量很大。这些系统不仅包括来自图像的对象分类,还包括通过在对象周围绘制适当的边界框来定位每个对象。这(绘制边界框和分类)使对象检测比其传统的计算机视觉前身图像分类更难。
要了解物体检测的输出是什么样的,让我们看一下下图:

在上图中,我们可以看到,虽然典型的对象分类仅提及图像中存在的对象类别,但对象定位在图像中存在的对象周围绘制了一个边界框。另一方面,对象检测将涉及在图像中的单个对象周围绘制边界框,以及在图像中存在的多个对象的边界框中识别对象的类别。
在我们了解对象检测的广泛用例之前,让我们了解它如何添加到我们在上一章中介绍的对象分类任务中。
想象一个场景,您的图像中有多个对象。我要求您预测图像中存在的对象类别。例如,假设图像包含猫和狗。你会如何对这些图像进行分类?对象检测在这种情况下派上用场,它不仅可以预测其中存在的对象(边界框)的位置,还可以预测各个边界框中存在的对象类别。
利用对象检测的一些不同用例包括以下内容:
- 安全性:这对于识别入侵者很有用。
- 自动 驾驶汽车:这有助于识别道路图像上的各种物体。
- 图像搜索:这可以帮助识别包含感兴趣对象(或人)的图像。
- 汽车:这有助于识别汽车图像中的车牌。
在上述所有情况下,都利用对象检测在图像中存在的各种对象周围绘制边界框。
在本章中,我们将学习预测对象的类别以及在图像中的对象周围有一个紧密的边界框,这就是定位任务。我们还将学习检测图片中多个对象对应的类别,以及每个对象周围的边界框,这就是对象检测任务。
训练一个典型的物体检测模型包括以下步骤:
- 创建包含与图像中存在的各种对象相对应的边界框和类的标签的地面实况数据。
- 提出 扫描图像以识别可能包含对象的区域(区域建议)的机制。在本章中,我们将学习如何利用一种名为选择性搜索的方法生成的区域建议。在下一章中,我们将学习如何利用锚框来识别包含对象的区域。在关于结合计算机视觉和 NLP 技术的章节(第 15 章)中,我们将学习如何利用变换器中的位置嵌入来帮助识别包含对象的区域。
- 使用 IoU 指标创建目标类变量。
- 创建目标边界框偏移变量以修正第二步中的区域提议的位置。
- 构建一个模型,该模型可以预测对象的类别以及与区域提议相对应的目标边界框偏移量。
- 使用平均平均精度( mAP )测量对象检测的准确度。
现在我们已经对训练对象检测模型要做什么有了一个高层次的概述,我们将在下一节中学习为边界框创建数据集(这是构建对象检测模型的第一步) .
为训练创建边界框ground truth
我们已经了解到,对象检测为我们提供了一个边界框围绕图像中感兴趣的对象的输出。为了构建一种算法来检测图像中对象周围的边界框,我们必须创建输入-输出组合,其中输入是图像,输出是给定图像中对象周围的边界框,以及对象对应的类。
要训练提供边界框的模型,我们需要图像,以及图像中所有对象的相应边界框坐标。在本节中,我们将了解一种创建训练数据集的方法,其中图像是输入,相应的边界框和对象类存储在 XML 文件中作为输出。我们将使用该ybat工具来注释边界框和相应的类。
让我们了解安装和使用ybat以在图像中的对象周围创建(注释)边界框。此外,我们还将在下一节中检查包含带注释的类和边界框信息的 XML 文件。
安装图片标注工具
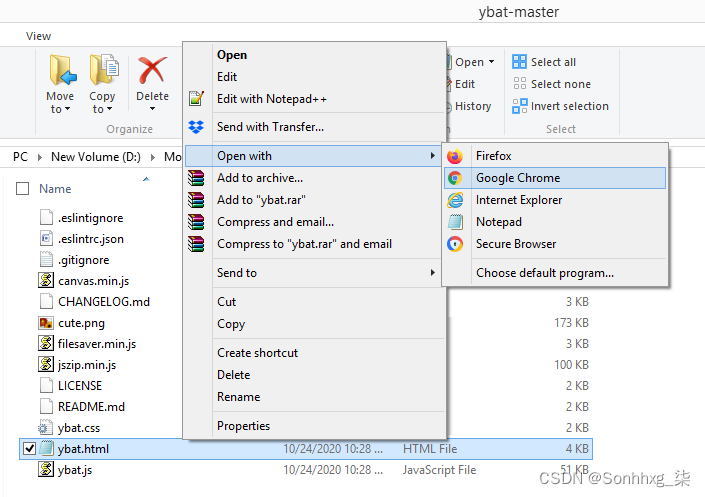
让我们ybat-master.zip从以下 GitHub 链接GitHub - drainingsun/ybat: Ybat - YOLO BBox Annotation Tool下载并解压缩它。解压后,将其存储在您选择的文件夹中。使用您选择的浏览器打开ybat.html,您将看到一个空白页面。以下屏幕截图显示了文件夹的外观以及如何打开ybat.html文件的示例:
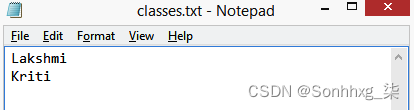
在我们开始创建对应于图像的基本事实之前,让我们指定我们想要跨图像标记并存储在classes.txt文件中的所有可能类,如下所示:
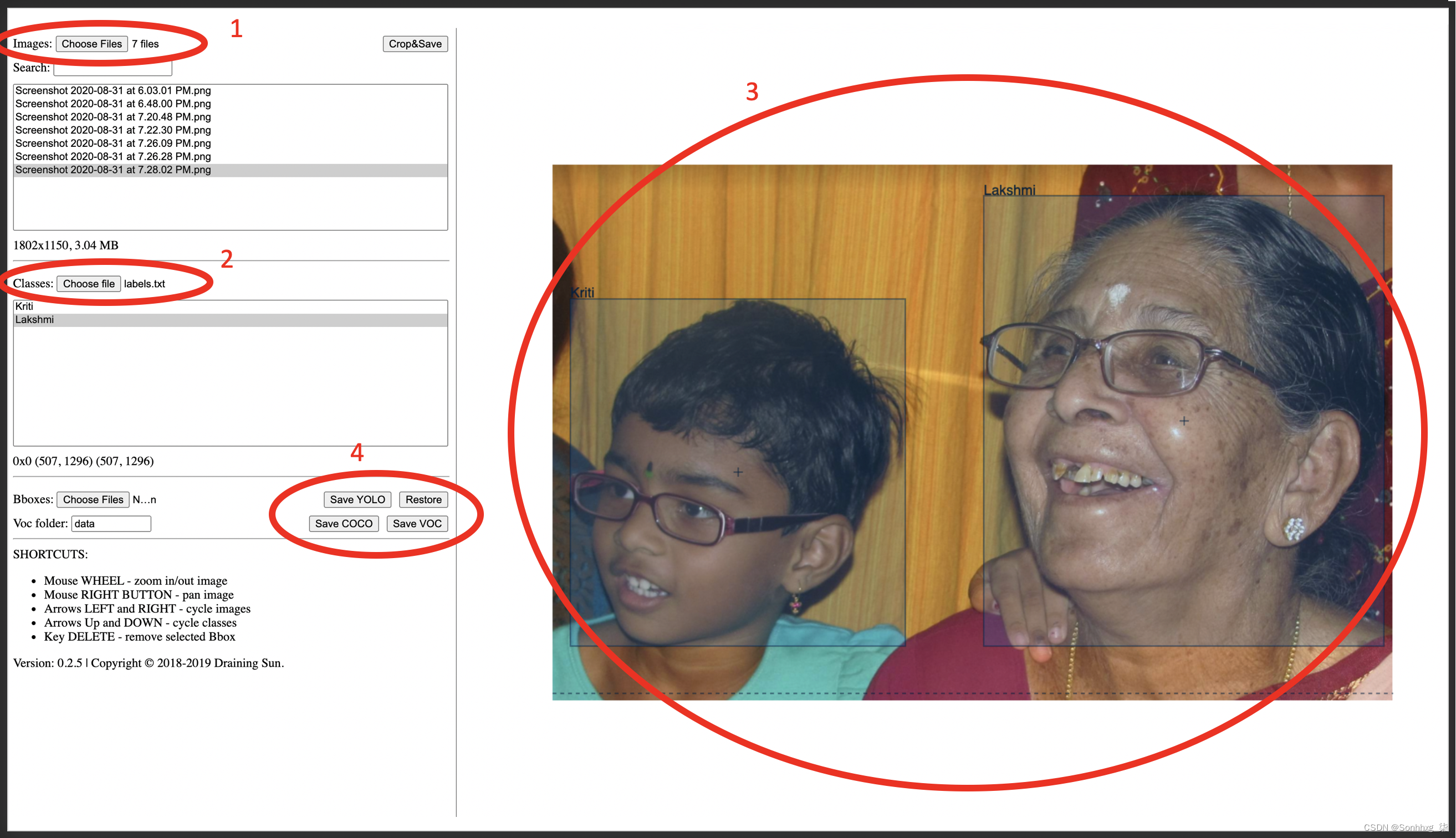
现在,让我们准备对应于图像的基本事实。这涉及在对象(下图中的人)周围绘制一个边界框,并在以下步骤中为图像中存在的对象分配标签/类:
- 上传您要注释的所有图像(下图中的步骤 1)。
- 上传classes.txt文件(下图中的步骤 2)。
- 首先选择文件名,然后在要标记的每个对象周围画一个十字准线来标记每个图像(下图中的步骤 3)。在绘制十字准线之前,请确保在类区域中选择了正确的类(下图中第二个椭圆下方的类窗格)。
- 以所需格式保存数据转储(下图中的步骤 4)。每种格式都是由不同的研究团队独立开发的,并且都同样有效。基于它们的受欢迎程度和便利性,每个实现都喜欢不同的格式。
使用下图可以更好地表示所有这些步骤:
例如,当我们下载 PascalVOC 格式时,它会下载 XML 文件的 zip。绘制矩形边界框后的 XML 文件截图如下:
从前面的屏幕截图中,请注意,该字段包含与图像中感兴趣的对象对应的x和ybndbox坐标的最小值和最大值的坐标。我们还应该能够使用该字段提取与图像中的对象对应的类。name
现在我们了解了如何创建图像中存在的对象(类标签和边界框)的基本事实,在接下来的部分中,我们将深入研究识别图像中对象的构建块。首先,我们将讨论有助于突出图像中最有可能包含对象的部分的区域建议。
了解区域提案
想象一个假设场景,其中感兴趣的图像在背景中包含人和天空。此外,对于这种情况,我们假设背景(天空)的像素强度变化不大,而前景(人)的像素强度变化很大。
仅从前面的描述本身,我们可以得出结论,这里有两个主要区域——一个是人的,另一个是天空的。此外,在人的图像区域内,对应于头发的像素与对应于面部的像素具有不同的强度,从而确定一个区域内可以存在多个子区域。
区域提议是一种有助于识别像素彼此相似的区域岛屿的技术。
生成区域提议对于对象检测非常方便,我们必须识别图像中存在的对象的位置。此外,给定区域建议会生成该区域的建议,它有助于对象定位,其中任务是识别与图像中的对象完全吻合的边界框。我们将在后面关于训练基于 R-CNN 的自定义对象检测器的部分中了解区域提议如何帮助对象定位和检测,但让我们首先了解如何从图像生成区域提议。
利用 SelectiveSearch 生成区域建议
SelectiveSearch 是一种用于对象定位的区域建议算法,它生成可能根据像素强度组合在一起的区域建议。SelectiveSearch 根据相似像素的分层分组对像素进行分组,进而利用图像中内容的颜色、纹理、大小和形状兼容性。
最初, SelectiveSearch 通过根据前面的属性对像素进行分组来过度分割图像。接下来,它遍历这些过度分割的组,并根据相似性对它们进行分组。在每次迭代中,它将较小的区域组合成一个较大的区域。
让我们通过下面的例子来理解这个selectivesearch 过程:
1.安装所需的软件包:
!pip install selectivesearch
!pip install torch_snippets
from torch_snippets import *
import selectivesearch
from skimage.segmentation import felzenszwalb2.获取并加载所需的图像:
!wget https://www.dropbox.com/s/l98leemr7r5stnm/Hemanvi.jpeg
img = read('Hemanvi.jpeg', 1)3.从图像中提取felzenszwalb片段(根据图像中内容的颜色、纹理、大小和形状兼容性获得):
segment_fz = felzenszwalb(img, scale=200)请注意,在该felzenszwalb方法中,scale表示可以在图像片段内形成的簇数。的值越高scale,保留的原始图像的细节越多。
4.绘制原始图像和带有分割的图像:
subplots([img, segments_fz], \
titles=['Original Image',\
'Image post\nfelzenszwalb segmentation'],\
sz=10, nc=2)前面的代码产生以下输出:
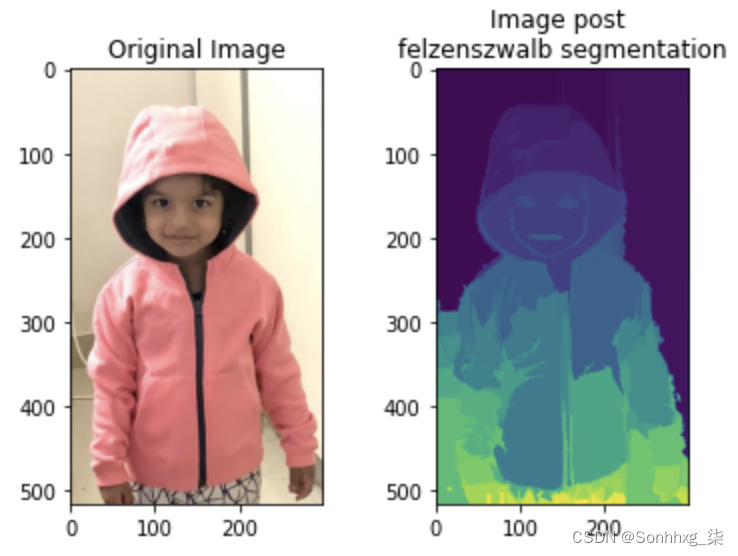
从前面的输出中,请注意属于同一组的像素具有相似的像素值。
现在我们了解了 SelectiveSearch 的作用,让我们实现该selectivesearch函数来获取给定图像的区域建议。
实施 SelectiveSearch 以生成区域建议
在本节中,我们将定义extract_candidates函数 usingselectivesearch以便在后续训练基于 R-CNN 和 Fast R-CNN 的自定义对象检测器的部分中使用它:
1.定义extract_candidates从图像中获取区域建议的函数:
- 定义将图像作为输入参数的函数:
def extract_candidates(img):- selective_search使用包中提供的方法获取图像中的候选区域selectivesearch:
img_lbl, regions = selectivesearch.selective_search(img, \
scale=200, min_size=100)- 计算图像区域并初始化一个列表(候选者),我们将使用该列表来存储通过定义阈值的候选者:
img_area = np.prod(img.shape[:2])
candidates = []- 仅获取那些超过图像总面积 5% 且小于或等于图像面积 100% 的候选(区域)并返回它们:
for r in regions:
if r['rect'] in candidates: continue
if r['size'] < (0.05*img_area): continue
if r['size'] > (1*img_area): continue
x, y, w, h = r['rect']
candidates.append(list(r['rect']))
return candidates2.导入相关包并获取图像:
!pip install selectivesearch
!pip install torch_snippets
from torch_snippets import *
import selectivesearch
!wget https://www.dropbox.com/s/l98leemr7r5stnm/Hemanvi.jpeg
img = read('Hemanvi.jpeg', 1)3.提取候选对象并将它们绘制在图像上:
candidates = extract_candidates(img)
show(img, bbs=candidates)上述代码生成以下输出:

上图中的网格表示来自该selective_search方法的候选区域(区域建议)。
现在我们了解了区域提案的生成,还有一个问题没有得到解答。我们如何利用区域建议进行对象检测和定位?
与感兴趣图像中对象的位置(ground truth)相交高的区域提议被标记为包含该对象的区域,相交低的区域提议被标记为背景。
在下一节中,我们将了解如何计算候选区域与地面实况边界框的交集,以了解构成构建对象检测模型的各种技术。
了解 IoU
想象一个场景,我们提出了一个对象边界框的预测。我们如何衡量我们预测的准确性?Intersection over Union ( IoU )的概念在这种情况下会派上用场。
Intersection over Union术语中的Intersection测量预测的边界框和实际边界框的重叠程度,而Union测量可能重叠的整体空间。IoU 是两个边界框之间的重叠区域与两个边界框的组合区域的比率。
这可以在图表中表示如下:
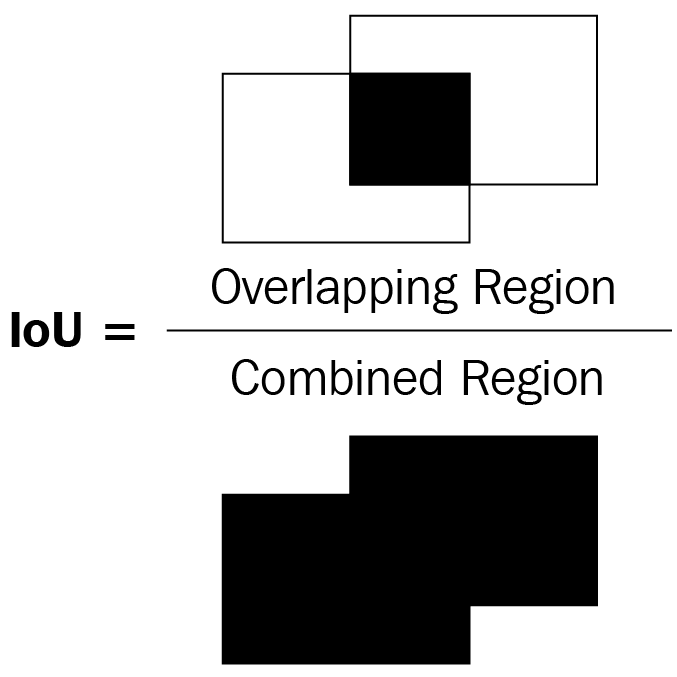
在前面两个边界框(矩形)的图表中,让我们将左边界框视为地面实况,将右边界框视为对象的预测位置。作为度量的 IoU 是两个边界框之间的重叠区域与组合区域的比率。
在下图中,您可以观察到 IoU 指标的变化,因为边界框之间的重叠发生了变化:
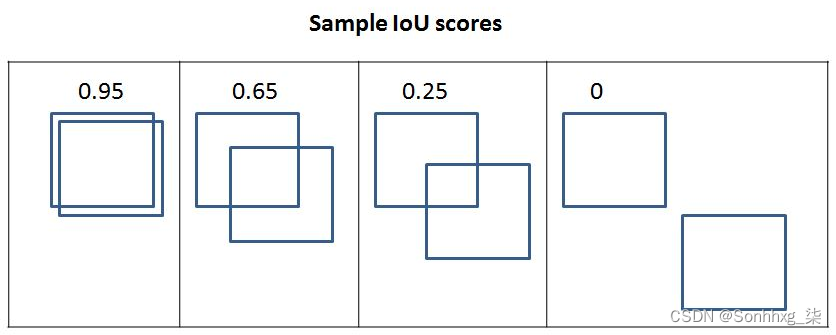
从上图中,我们可以看到随着重叠减少,IoU 减少,在最后一个没有重叠的地方,IoU 度量为 0。
现在我们有了测量 IoU 的直觉,让我们在代码中实现它并创建一个计算 IoU 的函数,因为我们将在训练 R-CNN 和训练 Fast R-CNN 的部分中利用它。
让我们定义一个函数,它将两个边界框作为输入并返回 IoU 作为输出:
1.指定将和作为输入的get_iou函数,其中和是两个不同的边界框(您可以将其视为地面实况边界框和区域提议):boxAboxBboxAboxB boxAboxB
def get_iou(boxA, boxB, epsilon=1e-5):我们定义epsilon参数以解决两个框之间的并集为 0 时的罕见情况,从而导致除以零错误。请注意,在每个边界框中,将有四个值对应于边界框的四个角。
2.计算相交框的坐标:
x1 = max(boxA[0], boxB[0])
y1 = max(boxA[1], boxB[1])
x2 = min(boxA[2], boxB[2])
y2 = min(boxA[3], boxB[3])请注意,这是在两个边界框之间x1存储最左侧x值的最大值。类似地,y1存储最上面的y值和x2存储y2最右边的x值和最底部的y值,分别对应于相交部分。
3.计算width和height对应的交叉区域(重叠区域):
width = (x2 - x1)
height = (y2 - y1)4.计算重叠面积 ( area_overlap):
if (width<0) or (height <0):
return 0.0
area_overlap = width * height注意,在前面的代码中,我们指定如果重叠区域对应的宽度或高度小于0,则相交的面积为0。否则,我们计算重叠(相交)的面积类似于矩形的计算计算面积 - 宽度乘以高度。
5.计算两个bounding box对应的组合面积:
area_a = (boxA[2] - boxA[0]) * (boxA[3] - boxA[1])
area_b = (boxB[2] - boxB[0]) * (boxB[3] - boxB[1])
area_combined = area_a + area_b - area_overlap在前面的代码中,我们计算了两个边界框的合并面积 -area_a和area_b,然后在计算时减去重叠区域,计算area_combined两次area_overlap,计算时一次,计算area_a时一次area_b。
6.计算 IoU 并返回:
iou = area_overlap / (area_combined+epsilon)
return iou在前面的代码中,我们计算iou了重叠area_overlap面积 ( ) 与组合区域面积( ) 的比率area_combined并将其返回。
到目前为止,我们已经了解了如何创建 ground truth 和计算 IoU,这有助于准备训练数据。接下来,对象检测模型将在检测图像中的对象时派上用场。最后,我们将计算模型性能并推断新图像。
我们将推迟构建模型,直到接下来的部分,因为训练模型涉及更多内容,而且在训练之前我们还必须学习更多组件。在下一节中,我们将学习非最大抑制,它有助于在使用经过训练的模型在新图像上进行推断时,从对象周围不同的可能预测边界框中筛选出候选名单。
非最大抑制(Non-max suppression)
想象一个场景,其中生成了多个区域提案并且彼此显着重叠。本质上,所有预测的边界框坐标(区域建议的偏移量)彼此显着重叠。例如,让我们考虑下图,其中为图像中的人生成了多个区域建议:

在上图中,我要求您在我们将考虑为包含对象的许多区域建议中识别框以及我们将丢弃的框。在这种情况下,非最大抑制会派上用场。让我们解开术语“非最大抑制”。
非最大是指不包含最高概率包含对象的框,抑制是指我们丢弃那些不包含最高概率包含对象的框。在非最大抑制中,我们识别具有最高概率的边界框,并丢弃所有其他 IoU 大于某个阈值的边界框,该框包含包含对象的最高概率。
在 PyTorch 中,使用模块中的nms 函数执行非最大抑制torchvision.ops。该nms 函数通过边界框坐标、物体在边界框中的置信度和边界框之间的IoU阈值来识别要保留的边界框。您将分别在步骤 19和16中的基于训练 R-CNN 的自定义对象检测器和基于训练快速 R-CNN 的自定义对象检测器nms部分中预测新图像中的对象类别和对象边界框时利用该功能.
平均平均精度
到目前为止,我们已经看到了一个输出,该输出包括图像中每个对象周围的边界框以及与边界框中的对象对应的类。现在来了下一个问题:我们如何量化来自我们模型的预测的准确性?
在这种情况下,mAP 就派上用场了。在我们尝试理解 mAP 之前,让我们先理解精度,然后是平均精度,最后是 mAP:
- 精度(Precision):通常,我们计算精度为:
![]()
真正的肯定是指预测正确类别的对象并且具有大于特定阈值的地面实况的 IoU 的边界框。误报是指边界框对类别的预测不正确或与基本事实的重叠小于定义的阈值。此外,如果为同一个 ground truth 边界框识别出多个边界框,则只有一个框可以成为真阳性,而其他所有框都成为假阳性。
- 平均精度(Average Precision):平均精度是在各种 IoU 阈值下计算的精度值的平均值。
- mAP: mAP 是在数据集中存在的所有对象类别中以各种 IoU 阈值计算的精度值的平均值。
到目前为止,我们已经了解了如何为我们的模型准备训练数据集、对模型的预测执行非最大抑制以及计算其准确性。在以下部分中,我们将学习如何训练模型(基于 R-CNN 和基于 Fast R-CNN)来检测新图像中的对象。
训练基于 R-CNN 的自定义对象检测器
R-CNN 代表基于区域的卷积神经网络。R-CNN 中基于区域的代表区域建议。区域提议用于识别图像中的对象。请注意,R-CNN 有助于识别图像中存在的对象以及图像中对象的位置。
在以下部分中,我们将了解 R-CNN 的工作细节,然后再在我们的自定义数据集上进行训练。
R-CNN的工作细节
让我们使用下图从高层次上了解基于 R-CNN 的对象检测:
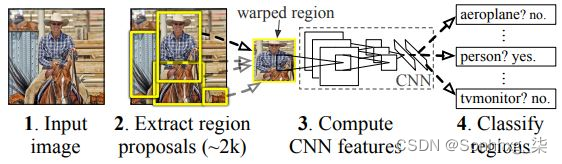
在利用 R-CNN 技术进行对象检测时,我们执行以下步骤:
1.从图像中提取区域建议:
- 确保我们提取大量提案,以免错过图像中的任何潜在对象。
2.调整(扭曲)所有提取区域的大小以获得相同大小的图像。
3.通过网络传递调整大小的区域提案:
- 通常,我们通过预训练模型(例如 VGG16 或 ResNet50)传递调整大小的区域提案,并在全连接层中提取特征。
4.为模型训练创建数据,其中输入是通过将区域提议通过预训练模型提取的特征,输出是与每个区域提议对应的类以及区域提议与图像对应的地面实况的偏移量:
- 如果区域提议与对象的 IoU 大于某个阈值,我们准备训练数据的方式是,该区域负责预测与其重叠的对象类别以及区域提议与地面实况的偏移量包含感兴趣对象的边界框。
为区域提议创建边界框偏移和地面实况类的结果示例如下:

在上图中,o(红色)表示区域提议的中心(虚线边界框),x 表示对应于猫类的 ground truth 边界框(实心边界框)的中心。我们将 region proposal 边界框和 ground truth 边界框之间的偏移量计算为两个边界框的中心坐标 (dx, dy) 与边界框的高度和宽度之间的差值 (dw, dh )。
5.将两个输出头连接起来,一个对应于图像的类别,另一个对应于区域提议的偏移量与ground truth边界框,以提取对象上的精细边界框:
- 这个练习类似于我们基于上一章中的人脸图像。
6.训练模型帖子,编写自定义损失函数,以最小化对象分类误差和边界框偏移误差。
请注意,我们将最小化的损失函数与原始论文中优化的损失函数不同。我们这样做是为了降低与从头开始构建 R-CNN 和 Fast R-CNN 相关的复杂性。一旦读者熟悉了模型的工作原理并可以使用以下代码构建模型,我们强烈鼓励他们从头开始实现原始论文。
在下一节中,我们将学习获取数据集和创建训练数据。在之后的部分中,我们将学习如何设计模型并在预测新图像中存在的对象类别及其边界框之前对其进行训练。
在自定义数据集上实现 R-CNN 进行对象检测
到目前为止,我们对 R-CNN 的工作原理有了理论上的了解。在本节中,我们将学习如何为训练创建数据。此过程涉及以下步骤:
1.下载数据集
2.准备数据集
3.定义区域提议提取和 IoU 计算函数
4.创建训练数据
- 为模型创建输入数据
- 调整区域提案的大小
- 将它们传递给预训练模型以获取完全连接的层值
- 为模型创建输出数据
- 使用类别或背景标签标记每个区域提案
- 如果区域提议对应于对象而不是背景,则定义区域提议与地面实况的偏移量
5.定义和训练模型
6.预测新图像
让我们开始在以下部分中进行编码。
下载数据集
对于目标检测场景,我们将从 Google Open Images v6 数据集(可在https://storage.googleapis.com/openimages/v5/test-annotations-bbox.csv获得)下载数据。但是,在代码中,我们将只处理公共汽车或卡车的图像,以确保我们可以训练图像(因为您很快就会注意到与使用相关的内存问题selectivesearch)。我们将扩大我们将在第 10 章“对象检测和分割的应用”中训练的课程数量(除了公共汽车和卡车之外的更多课程)。
1.导入相关包以下载包含图像及其基本事实的文件:
!pip install -q --upgrade selectivesearch torch_snippets
from torch_snippets import *
import selectivesearch
from google.colab import files
files.upload() # upload kaggle.json file
!mkdir -p ~/.kaggle
!mv kaggle.json ~/.kaggle/
!ls ~/.kaggle
!chmod 600 /root/.kaggle/kaggle.json
!kaggle datasets download -d sixhky/open-images-bus-trucks/
!unzip -qq open-images-bus-trucks.zip
from torchvision import transforms, models, datasets
from torch_snippets import Report
from torchvision.ops import nms
device = 'cuda' if torch.cuda.is_available() else 'cpu'一旦我们执行了前面的代码,我们就会将图像及其相应的基本事实存储在一个可用的 CSV 文件中。
准备数据集
现在我们已经下载了数据集,我们将准备数据集。这涉及以下步骤:
1.获取每个图像及其对应的类和边界框值
2.获取每个图像中的区域建议,它们对应的 IoU,以及区域建议相对于地面实况进行校正的增量
3.为每个类分配数字标签(我们有一个额外的背景类(除了公共汽车和卡车类),其中与地面实况边界框的 IoU 低于阈值)
4.将每个区域提案的大小调整为通用大小,以便将它们传递给网络
在本练习结束时,我们将调整区域建议的大小,同时为每个区域建议分配地面实况类,并计算区域建议相对于地面实况边界框的偏移量。我们将从上一节中停止的地方继续编码:
1.指定图像的位置并阅读我们下载的 CSV 文件中存在的基本事实:
IMAGE_ROOT = 'images/images'
DF_RAW = pd.read_csv('df.csv')
print(DF_RAW.head())上述数据帧的示例如下:

请注意,XMin、XMax、YMin和YMax对应于图像边界框的基本事实。此外,LabelName提供图像的类别。
2.定义一个类,该类返回图像及其对应的类和基本事实以及图像的文件路径:
- 将数据框 ( df) 和包含图像的文件夹的路径( image_folder)作为输入传递给该方法,并获取数据框 ( )中存在__init__的唯一ImageID值。self.unique_images我们这样做,因为图像可以包含多个对象,因此多行可以对应于相同的ImageID值:
class OpenImages(Dataset):
def __init__(self, df, image_folder=IMAGE_ROOT):
self.root = image_folder
self.df = df
self.unique_images = df['ImageID'].unique()
def __len__(self): return len(self.unique_images)- 定义__getitem__方法,我们获取与image_id索引( )对应的图像( ix),获取其边界框坐标(boxes)classes,并返回图像、边界框、类和图像路径:
def __getitem__(self, ix):
image_id = self.unique_images[ix]
image_path = f'{self.root}/{image_id}.jpg'
# Convert BGR to RGB
image = cv2.imread(image_path, 1)[...,::-1]
h, w, _ = image.shape
df = self.df.copy()
df = df[df['ImageID'] == image_id]
boxes = df['XMin,YMin,XMax,YMax'.split(',')].values
boxes = (boxes*np.array([w,h,w,h])).astype(np.uint16)\
.tolist()
classes = df['LabelName'].values.tolist()
return image, boxes, classes, image_path3.检查样本图像及其对应的类和边界框基本事实:
ds = OpenImages(df=DF_RAW)
im, bbs, clss, _ = ds[9]
show(im, bbs=bbs, texts=clss, sz=10)前面的代码结果如下:

4.定义extract_iou和extract_candidates函数:
def extract_candidates(img):
img_lbl,regions = selectivesearch.selective_search(img, \
scale=200, min_size=100)
img_area = np.prod(img.shape[:2])
candidates = []
for r in regions:
if r['rect'] in candidates: continue
if r['size'] < (0.05*img_area): continue
if r['size'] > (1*img_area): continue
x, y, w, h = r['rect']
candidates.append(list(r['rect']))
return candidates
def extract_iou(boxA, boxB, epsilon=1e-5):
x1 = max(boxA[0], boxB[0])
y1 = max(boxA[1], boxB[1])
x2 = min(boxA[2], boxB[2])
y2 = min(boxA[3], boxB[3])
width = (x2 - x1)
height = (y2 - y1)
if (width<0) or (height <0):
return 0.0
area_overlap = width * height
area_a = (boxA[2] - boxA[0]) * (boxA[3] - boxA[1])
area_b = (boxB[2] - boxB[0]) * (boxB[3] - boxB[1])
area_combined = area_a + area_b - area_overlap
iou = area_overlap / (area_combined+epsilon)
return iou到目前为止,我们已经定义了准备数据和初始化数据加载器所需的所有函数。在下一节中,我们将获取区域建议(模型的输入区域)和边界框偏移的基本事实以及对象类别(预期输出)。
获取区域建议和偏移量的基本事实
在本节中,我们将学习如何创建与我们的模型相对应的输入和输出值。输入构成使用该selectivesearch方法提取的候选对象,输出构成与候选对象相对应的类以及候选对象相对于与其重叠最多的边界框的偏移量(如果候选对象包含对象)。我们将从上一节结束的地方继续编码:
1.初始化空列表以存储文件路径FPATHS(真相():GTBBSCLSSDELTASROISIOUS
FPATHS, GTBBS, CLSS, DELTAS, ROIS, IOUS = [],[],[],[],[],[]2.循环遍历数据集并填充上面初始化的列表:
- 对于本练习,我们可以使用所有数据点进行训练或仅使用前 500 个数据点进行说明。您可以在两者之间进行选择,这决定了训练时间和训练准确度(数据点越大,训练时间和准确度越高):
N = 500
for ix, (im, bbs, labels, fpath) in enumerate(ds):
if(ix==N):
break在前面的代码中,我们指定我们将处理 500 个图像。
- 使用im函数从每个图像XMin( Xmax_ w,h) 系统到 (x,y,x+w,y+h) 系统:YMinYMaxextract_candidates
H, W, _ = im.shape Candidates
= extract_candidates(im)
Candidates = np.array([(x,y,x+w,y+h) \
for x,y,w,h in Candidates])- ious将、rois、deltas和初始化clss为存储iou每个候选者、区域提议位置、边界框偏移量以及与每个图像的每个候选者对应的类的列表。我们将遍历来自 SelectiveSearch 的所有提案,并将那些具有高 IOU 的提案存储为公共汽车/卡车提案(以标签中的类别为准),其余作为背景提案:
ious, rois, clss, deltas = [], [], [], []- 存储所有候选者相对于所有 ground truth 的 IoU,其中bbs是图像中存在的不同对象的 ground truth 边界框,candidates是上一步中获得的候选区域:
ious = np.array([[extract_iou(candidate, _bb_) for \
Candidate in Candidates] for _bb_ in bbs]).T- 循环遍历每个候选并存储候选的 XMin ( cx)、YMin ( cy)、XMax ( cX) 和 YMax ( cY) 值:
for jx, candidate in enumerate(candidates):
cx,cy,cX,cY = candidate- 在获取 的列表时,针对所有已计算的地面实况边界框,提取与候选者对应的 IoU ious:
candidate_ious = ious[jx]- best_iou_at找到具有最高 IoU 和相应基本事实 ( )的候选者 ( ) 的索引best_bb:
best_iou_at = np.argmax(candidate_ious)
best_iou = Candidate_ious[best_iou_at]
best_bb = _x,_y,_X,_Y = bbs[best_iou_at]- 如果 IoU (· best_iou) 大于阈值 (0.3),我们分配与候选者对应的类别标签,否则为背景:
if best_iou > 0.3: clss.append(labels[best_iou_at])
else : clss.append('background')- 获取所需的偏移量delta(best_bb调整当前提案,使其与best_bb基本事实完全一致:
delta = np.array([_x-cx, _y-cy, _X-cX, _Y-cY]) /\
np.array([W,H,W,H])
deltas.append(delta)
rois.append(candidate / np.array([W,H,W,H]))- 附加文件路径、IoU、roi、类增量和地面实况边界框:
FPATHS.append(fpath)
IOUS.append (ious)
ROIS.append(rois)
CLSS.append(clss)
DELTAS.append(deltas)
GTBBS.append(bbs)- 获取图像路径名称并将获得的所有信息 , FPATHS , IOUS, ROIS, CLSS,DELTAS和GTBBS, 存储在列表列表中:
FPATHS = [f'{IMAGE_ROOT}/{stem(f)}.jpg' for f in FPATHS]
FPATHS, GTBBS, CLSS, DELTAS, ROIS = [item for item in \
[FPATHS, GTBBS, \
CLSS, DELTAS, ROIS]]请注意,到目前为止,类可用作类的名称。现在,我们将它们转换成它们对应的索引,这样背景类的类索引为 0,公共汽车类的类索引为 1,卡车类的类索引为 2。
3.为每个类分配索引:
targets = pd.DataFrame(flatten(CLSS), columns=['label'])
label2target = {l:t for t,l in \
enumerate(targets['label'].unique())}
target2label = {t:l for l,t in label2target.items()}
background_class = label2target['background']到目前为止,我们已经为每个区域提案分配了一个类,并且还创建了边界框偏移的另一个基本事实。在下一节中,我们将获取与获得的信息相对应的数据集和数据加载器(FPATHS、IOUS、ROIS、CLSS、DELTAS和GTBBS)。
创建训练数据
到目前为止,我们已经获取了所有图像中的数据、区域提议,准备了每个区域提议中存在的对象类别的基本事实,以及与每个区域提议相对应的偏移量,这些区域提议与目标区域中的对象具有高度重叠 (IoU)。对应的图像。
在本节中,我们将根据在步骤 8结束时获得的区域建议的基本事实准备一个数据集类,并从中创建数据加载器。接下来,我们将通过将每个区域提案调整为相同的形状并缩放它们来规范化它们。我们将从上一节中停止的地方继续编码:
1.定义对图像进行归一化的函数:
normalize= transforms.Normalize(mean=[0.485, 0.456, 0.406], \
std=[0.229, 0.224, 0.225])2.定义一个函数preprocess_image(img
def preprocess_image(img):
img = torch.tensor(img).permute(2,0,1)
img = normalize(img)
return img.to(device).float()- 定义类decode预测的函数:
def decode(_y):
_, preds = _y.max(-1)
return preds3.使用预处理的区域建议以及在上一步(步骤 7RCNNDataset )中获得的基本事实定义数据集():
class RCNNDataset(Dataset):
def __init__(self, fpaths, rois, labels, deltas, gtbbs):
self.fpaths = fpaths
self.gtbbs = gtbbs
self.rois = rois
self.labels = labels
self.deltas = deltas
def __len__(self): return len(self.fpaths)- 根据区域建议获取作物,以及与类和边界框偏移相关的其他基本事实:
def __getitem__(self, ix):
fpath = str(self.fpaths[ix])
image = cv2.imread(fpath, 1)[...,::-1]
H, W, _ = image.shape
sh = np.array([W,H,W,H])
gtbbs = self.gtbbs[ix]
rois = self.rois[ix]
bbs = (np.array(rois)*sh).astype(np.uint16)
labels = self.labels[ix]
deltas = self.deltas[ix]
crops = [image[y:Y,x:X] for (x,y,X,Y) in bbs]
return image,crops,bbs,labels,deltas,gtbbs,fpath- 定义,它执行裁剪图像的collate_fn大小调整和规范化 ( ):preprocess_image
def collate_fn(self, batch):
input, rois, rixs, labels, deltas =[],[],[],[],[]
for ix in range(len(batch)):
image, crops, image_bbs, image_labels, \
image_deltas, image_gt_bbs, \
image_fpath = batch[ix]
crops = [cv2.resize(crop, (224,224)) \
for crop in crops]
crops = [preprocess_image(crop/255.)[None] \
for crop in crops]
input.extend(crops)
labels.extend([label2target[c] \
for c in image_labels])
deltas.extend(image_deltas)
input = torch.cat(input).to(device)
labels = torch.Tensor(labels).long().to(device)
deltas = torch.Tensor(deltas).float().to(device)
return input, labels, deltas4.创建训练和验证数据集和数据加载器:
n_train = 9*len(FPATHS)//10
train_ds = RCNNDataset(FPATHS[:n_train], ROIS[:n_train], \
CLSS[:n_train], DELTAS[:n_train], \
GTBBS[:n_train])
test_ds = RCNNDataset(FPATHS[n_train:], ROIS[n_train:], \
CLSS[n_train:], DELTAS[n_train:], \
GTBBS[n_train:])
from torch.utils.data import TensorDataset, DataLoader
train_loader = DataLoader(train_ds, batch_size=2, \
collate_fn=train_ds.collate_fn, \
drop_last=True)
test_loader = DataLoader(test_ds, batch_size=2, \
collate_fn=test_ds.collate_fn, \
drop_last=True)到目前为止,我们已经了解了准备数据。接下来,我们将学习定义和训练模型,该模型预测要对区域提议进行的类别和偏移,以适应图像中对象周围的紧密边界框。
R-CNN 网络架构
现在我们已经准备好数据,在本节中,我们将学习如何构建一个模型,该模型可以预测区域提议的类别和与其对应的偏移量,以便在图像中的对象周围绘制一个紧密的边界框。我们采用的策略如下:
1.定义 VGG 主干。
2.通过预训练模型获取经过归一化裁剪后的特征。
3.将具有 sigmoid 激活的线性层附加到 VGG 主干,以预测与区域提议对应的类。
4.附加一个额外的线性层来预测四个边界框偏移量。
5.为两个输出中的每一个定义损失计算(一个用于预测类别,另一个用于预测四个边界框偏移量)。
6.训练预测区域建议类别和四个边界框偏移量的模型。
执行以下代码。我们将从上一节结束的地方继续编码:
1.定义一个 VGG 主干:
vgg_backbone = models.vgg16(pretrained=True)
vgg_backbone.classifier = nn.Sequential()
for param in vgg_backbone.parameters():
param.requires_grad = False
vgg_backbone.eval().to(device)2.定义RCNN网络模块:
- 定义类:
class RCNN(nn.Module):
def __init__(self):
super().__init__()- 定义主干(self.backbone)以及我们如何计算类分数(self.cls_score)和边界框偏移值(self.bbox):
feature_dim = 25088
self.backbone = vgg_backbone
self.cls_score = nn.Linear(feature_dim, \
len(label2target))
self.bbox = nn.Sequential(
nn.Linear(feature_dim, 512),
nn.ReLU(),
nn.Linear(512, 4),
nn.Tanh(),
)- 定义对应于类预测 ( self.cel) 和边界框偏移回归 ( self.sl1)的损失函数:
self.cel = nn.CrossEntropyLoss()
self.sl1 = nn.L1Loss()- 定义前馈方法,我们将图像通过 VGG 主干 ( self.backbone) 以获取特征 ( feat),这些特征进一步通过与分类和边界框回归相对应的方法以获取跨类的概率 ( cls_score) 和边界框偏移( bbox) :
def forward(self, input):
feat = self.backbone(input)
cls_score = self.cls_score(feat)
bbox = self.bbox(feat)
return cls_score, bbox- 定义计算损失的函数 ( calc_loss)。请注意,如果实际类属于背景,我们不会计算与偏移量对应的回归损失:
def calc_loss(self, probs, _deltas, labels, deltas):
detection_loss = self.cel(probs, labels)
ixs, = torch.where(labels != 0)
_deltas = _deltas[ixs]
deltas = deltas[ixs]
self.lmb = 10.0
if len(ixs) > 0:
regression_loss = self.sl1(_deltas, deltas)
return detection_loss + self.lmb *\
regression_loss, detection_loss.detach(), \
regression_loss.detach()
else:
regression_loss = 0
return detection_loss + self.lmb *\
regression_loss, detection_loss.detach(), \
regression_loss有了模型类,我们现在定义函数来训练一批数据并预测验证数据。
3.定义train_batch函数:
def train_batch(inputs, model, optimizer, criterion):
input, clss, deltas = inputs
model.train()
optimizer.zero_grad()
_clss, _deltas = model(input)
loss, loc_loss, regr_loss = criterion(_clss, _deltas, \
clss, deltas)
accs = clss == decode(_clss)
loss.backward()
optimizer.step()
return loss.detach(), loc_loss, regr_loss, \
accs.cpu().numpy()4.定义validate_batch函数:
@torch.no_grad()
def validate_batch(inputs, model, criterion):
input, clss, deltas = inputs
with torch.no_grad():
model.eval()
_clss,_deltas = model(input)
loss,loc_loss,regr_loss = criterion(_clss, _deltas, \
clss, deltas)
_, _clss = _clss.max(-1)
accs = clss == _clss
return _clss,_deltas,loss.detach(),loc_loss, regr_loss, \
accs.cpu().numpy()5.现在,让我们创建一个模型对象,获取损失标准,然后定义优化器和 epoch 数:
rcnn = RCNN().to(device)
criterion = rcnn.calc_loss
optimizer = optim.SGD(rcnn.parameters(), lr=1e-3)
n_epochs = 5
log = Report(n_epochs)6.我们现在在越来越多的时期训练模型:
for epoch in range(n_epochs):
_n = len(train_loader)
for ix, inputs in enumerate(train_loader):
loss, loc_loss,regr_loss,accs = train_batch(inputs, \
rcnn, optimizer, criterion)
pos = (epoch + (ix+1)/_n)
log.record(pos, trn_loss=loss.item(), \
trn_loc_loss=loc_loss, \
trn_regr_loss=regr_loss, \
trn_acc=accs.mean(), end='\r')
_n = len(test_loader)
for ix,inputs in enumerate(test_loader):
_clss, _deltas, loss, \
loc_loss, regr_loss, \
accs = validate_batch(inputs, rcnn, criterion)
pos = (epoch + (ix+1)/_n)
log.record(pos, val_loss=loss.item(), \
val_loc_loss=loc_loss, \
val_regr_loss=regr_loss, \
val_acc=accs.mean(), end='\r')
# 绘制训练和验证指标
log.plot_epochs('trn_loss,val_loss'.split(','))训练和验证数据的整体损失图如下:
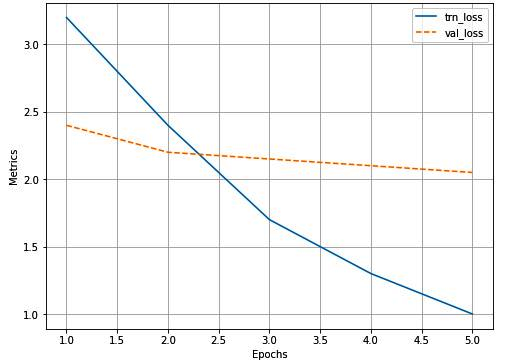
现在我们已经训练了一个模型,我们将在下一节中使用它来预测新图像。
预测新图像
在本节中,我们将利用迄今为止训练的模型来预测和绘制对象周围的边界框以及新图像上预测的边界框内的相应对象类别。我们采用的策略如下:
1.从新图像中提取区域建议。
2.调整每个作物的大小并标准化。
3.前馈处理后的作物以预测类别和偏移量。
4.执行非最大抑制以仅获取那些对包含对象具有最高置信度的框。
我们通过一个将图像作为输入和一个地面实况边界框的函数执行上述策略(这仅用于比较地面实况和预测边界框)。我们将从上一节中停止的地方继续编码:
1.定义在新图像上预测的test_predictions 函数:
- 该函数filename作为输入:
def test_predictions(filename, show_output=True):- 读取图像并提取候选者:
img = np.array(cv2.imread(filename, 1)[...,::-1])
candidates = extract_candidates(img)
candidates = [(x,y,x+w,y+h) for x,y,w,h in candidates]- 循环遍历候选对象以调整图像大小和预处理图像:
input = []
for candidate in candidates:
x,y,X,Y = candidate
crop = cv2.resize(img[y:Y,x:X], (224,224))
input.append(preprocess_image(crop/255.)[None])
input = torch.cat(input).to(device)- 预测类和偏移量:
with torch.no_grad():
rcnn.eval()
probs, deltas = rcnn(input)
probs = torch.nn.functional.softmax(probs, -1)
confs, clss = torch.max(probs, -1)- 提取不属于背景类的候选者,并将候选者与预测的边界框偏移值相加:
candidates = np.array(candidates)
confs,clss,probs,deltas =[tensor.detach().cpu().numpy() \
for tensor in [confs, \
clss, probs, deltas]]
ixs = clss!=background_class
confs, clss,probs,deltas,candidates = [tensor[ixs] for \
tensor in [confs,clss, probs, deltas,candidates]]
bbs = (candidates + deltas).astype(np.uint16)- 使用非最大抑制nms来消除近似重复的边界框(在这种情况下,IoU 大于 0.05 的框对被认为是重复的)。在重复的盒子中,我们选择置信度最高的盒子并丢弃其余的盒子:
ixs = nms(torch.tensor(bbs.astype(np.float32)), \
torch.tensor(confs), 0.05)
confs,clss,probs,deltas,candidates,bbs = [tensor[ixs] \
for tensor in \
[confs, clss, probs, deltas, \
candidates, bbs]]
if len(ixs) == 1:
confs, clss, probs, deltas, candidates, bbs = \
[tensor[None] for tensor in [confs, clss,
probs, deltas, candidates, bbs]]- 获取置信度最高的边界框:
if len(confs) == 0 and not show_output:
return (0,0,224,224), 'background', 0
if len(confs) > 0:
best_pred = np.argmax(confs)
best_conf = np.max(confs)
best_bb = bbs[best_pred]
x,y,X,Y = best_bb- 将图像与预测的边界框一起绘制:
_, ax = plt.subplots(1, 2, figsize=(20,10))
show(img, ax=ax[0])
ax[0].grid(False)
ax[0].set_title('Original image')
if len(confs) == 0:
ax[1].imshow(img)
ax[1].set_title('No objects')
plt.show()
return
ax[1].set_title(target2label[clss[best_pred]])
show(img, bbs=bbs.tolist(),
texts=[target2label[c] for c in clss.tolist()],
ax=ax[1], title='predicted bounding box and class')
plt.show()
return (x,y,X,Y),target2label[clss[best_pred]],best_conf2.在新图像上执行上述函数:
image, crops, bbs, labels, deltas, gtbbs, fpath = test_ds[7]
test_predictions(fpath)上述代码生成以下图像:

从上图可以看出,图像类别的预测准确,边界框预测也不错。请注意,为前面的图像生成预测大约需要 1.5 秒。
所有这些时间都用于生成区域提议、调整每个区域提议的大小、将它们传递给 VGG 主干,以及使用定义的模型生成预测。然而,大部分时间都花在通过 VGG 主干传递每个提案。在下一节中,我们将学习如何使用基于 Fast R-CNN 架构的模型来解决“将每个提案传递给 VGG”的问题。
训练基于 Fast R-CNN 的自定义对象检测器
R-CNN 的主要缺点之一是生成预测需要相当长的时间,因为为每个图像生成区域建议、调整区域的裁剪以及提取与每个裁剪对应的特征(区域建议)构成了瓶颈。
Fast R-CNN 通过将整个图像selectivesearch传递给预训练模型以提取特征,然后获取与原始图像的区域提议(从 获得)相对应的特征区域,从而解决了这个问题。在以下部分中,我们将了解 Fast R-CNN 的工作细节,然后再在我们的自定义数据集上进行训练。
Fast R-CNN 的工作细节
让我们通过下图来了解 Fast R-CNN :
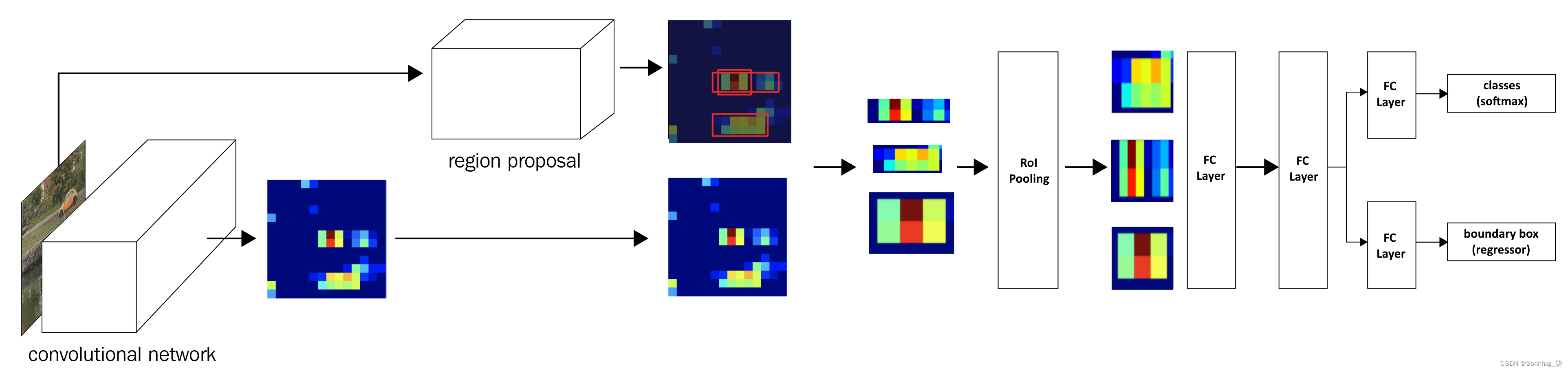
让我们通过以下步骤来理解上图:
1.将图像通过预训练模型以在展平层之前提取特征;让我们将输出称为特征图。
2.提取与图像对应的区域建议。
3.提取与区域提议相对应的特征图区域(注意,当图像通过 VGG16 架构时,由于执行了 5 次池化操作,图像在输出处缩小了 32。因此,如果存在带有边界框的区域(40,32,200,240)在原始图像中,对应于(5,4,25,30)的边界框的特征图将对应于完全相同的区域)。
4.通过 RoI(Region of Interest)池化层一次传递一个与 region proposal 对应的特征图,使 region proposal 的所有特征图都具有相似的形状。这是在 R-CNN 技术中执行的变形的替代品。
5.通过全连接层传递 RoI 池化层输出值。
6.训练模型以预测每个区域提案对应的类别和偏移量。
现在了解了 Fast R-CNN 的工作原理,在下一节中,我们将使用我们在 R-CNN 部分中使用的相同数据集来构建模型。
在自定义数据集上实现 Fast R-CNN 以进行对象检测
在本节中,我们将努力使用 Fast R-CNN 训练我们的自定义对象检测器。此外,为了保持简洁,我们在本节中仅提供附加或更改的代码(您应该运行所有代码,直到R-CNN 上一节的创建训练数据子节中的第2 步):
1.创建一个FRCNNDataset类,该类返回图像、标签、ground truth、区域建议以及与每个区域建议相对应的增量:
class FRCNNDataset(Dataset):
def __init__(self, fpaths, rois, labels, deltas, gtbbs):
self.fpaths = fpaths
self.gtbbs = gtbbs
self.rois = rois
self.labels = labels
self.deltas = deltas
def __len__(self): return len(self.fpaths)
def __getitem__(self, ix):
fpath = str(self.fpaths[ix])
image = cv2.imread(fpath, 1)[...,::-1]
gtbbs = self.gtbbs[ix]
rois = self.rois[ix]
labels = self.labels[ix]
deltas = self.deltas[ix]
assert len(rois) == len(labels) == len(deltas), \
f'{len(rois)}, {len(labels)}, {len(deltas)}'
return image, rois, labels, deltas, gtbbs, fpath
def collate_fn(self, batch):
input, rois, rixs, labels, deltas = [],[],[],[],[]
for ix in range(len(batch)):
image, image_rois, image_labels, image_deltas, \
image_gt_bbs, image_fpath = batch[ix]
image = cv2.resize(image, (224,224))
input.append(preprocess_image(image/255.)[None])
rois.extend(image_rois)
rixs.extend([ix]*len(image_rois))
labels.extend([label2target[c] for c in \
image_labels])
deltas.extend(image_deltas)
input = torch.cat(input).to(device)
rois = torch.Tensor(rois).float().to(device)
rixs = torch.Tensor(rixs).float().to(device)
labels = torch.Tensor(labels).long().to(device)
deltas = torch.Tensor(deltas).float().to(device)
return input, rois, rixs, labels, deltas请注意,前面的代码与我们在R-CNN部分中学到的非常相似,唯一的变化是我们返回了更多信息(rois和rixs)。
该rois矩阵包含有关哪个 RoI 属于批次中的哪个图像的信息。请注意,它input包含多个图像,而rois是单个框列表。我们不知道有多少 rois 属于第一个图像,有多少属于第二个图像,依此类推。这就是ridx图片的来源。它是一个索引列表。列表中的每个整数都将相应的边界框与适当的图像相关联;例如,如果ridx是[0,0,0,1,1,2,3,3,3],那么我们知道前三个边界框属于批次中的第一个图像,接下来的两个属于批次中的第二个图像。
2.创建训练和测试数据集:
n_train = 9*len(FPATHS)//10
train_ds = FRCNNDataset(FPATHS[:n_train], ROIS[:n_train], \
CLSS[:n_train], DELTAS[:n_train], \
GTBBS[:n_train])
test_ds = FRCNNDataset(FPATHS[n_train:], ROIS[n_train:], \
CLSS[n_train:], DELTAS[n_train:], \
GTBBS[n_train:])
from torch.utils.data import TensorDataset, DataLoader
train_loader = DataLoader(train_ds, batch_size=2, \
collate_fn=train_ds.collate_fn, \
drop_last=True)
test_loader = DataLoader(test_ds, batch_size=2, \
collate_fn=test_ds.collate_fn, \
drop_last=True)3.定义要在数据集上训练的模型:
- 首先,导入类中RoIPool存在的方法torchvision.ops:
from torchvision.ops import RoIPool- 定义FRCNN网络模块:
class FRCNN(nn.Module):
def __init__(self):
super().__init__()- 加载预训练模型并冻结参数:
rawnet = torchvision.models.vgg16_bn(pretrained=True)
for param in rawnet.features.parameters():
param.requires_grad = True- 提取特征直到最后一层:
self.seq = nn.Sequential(*list(\
rawnet.features.children())[:-1])- 指定RoIPool将提取 7 x 7 输出。这里,spatial_scale是提案(来自原始图像)需要缩小的因素,以便每个输出在通过展平层之前具有相同的形状。图像大小为 224 x 224,而特征图大小为 14 x 14:
self.roipool = RoIPool(7, spatial_scale=14/224)- 定义输出头 -cls_score和bbox:
feature_dim = 512*7*7
self.cls_score = nn.Linear(feature_dim, \
len(label2target))
self.bbox = nn.Sequential(
nn.Linear(feature_dim, 512),
nn.ReLU(),
nn.Linear( 512, 4),
nn.Tanh(),
)- 定义损失函数:
self.cel = nn.CrossEntropyLoss()
self.sl1 = nn.L1Loss()- 定义forward方法,将图像、区域建议和区域建议的索引作为之前定义的网络的输入:
def forward(self, input, rois, ridx):- 将input图像通过预训练模型:
res = input
res = self.seq(res)- 创建一个矩阵rois作为 的输入self.roipool,首先ridx将第一列连接起来,接下来的四列是区域提议边界框的绝对值:
rois = torch.cat([ridx.unsqueeze(-1), rois*224], \
dim=-1)
res = self.roipool(res, rois)
feat = res.view(len(res), -1)
cls_score = self.cls_score(feat)
bbox=self.bbox(feat)#.view(-1,len(label2target),4)
return cls_score, bbox- 定义损失值计算 ( calc_loss),就像我们在R-CNN部分中所做的那样:
def calc_loss(self, probs, _deltas, labels, deltas):
detection_loss = self.cel(probs, labels)
ixs, = torch.where(labels != background_class)
_deltas = _deltas[ixs]
deltas = deltas[ixs]
self.lmb = 10.0
if len(ixs) > 0:
regression_loss = self.sl1(_deltas, deltas)
return detection_loss +\
self.lmb * regression_loss, \
detection_loss.detach(), \
regression_loss.detach()
else:
regression_loss = 0
return detection_loss + \
self.lmb * regression_loss, \
detection_loss.detach(), \
regression_loss4.就像我们在R-CNN部分中所做的那样,定义在批次上训练和验证的函数:
def train_batch(inputs, model, optimizer, criterion):
input, rois, rixs, clss, deltas = inputs
model.train()
optimizer.zero_grad()
_clss, _deltas = model(input, rois, rixs)
loss, loc_loss, regr_loss = criterion(_clss, _deltas, \
clss, deltas)
accs = clss == decode(_clss)
loss.backward()
optimizer.step()
return loss.detach(), loc_loss, regr_loss, \
accs.cpu().numpy()
def validate_batch(inputs, model, criterion):
input, rois, rixs, clss, deltas = inputs
with torch.no_grad():
model.eval()
_clss,_deltas = model(input, rois, rixs)
loss, loc_loss,regr_loss = criterion(_clss, _deltas, \
clss, deltas)
_clss = decode(_clss)
accs = clss == _clss
return _clss, _deltas,loss.detach(), loc_loss,regr_loss, \
accs.cpu().numpy()5.在越来越多的时期定义和训练模型:
frcnn = FRCNN().to(device)
criterion = frcnn.calc_loss
optimizer = optim.SGD(frcnn.parameters(), lr=1e-3)
n_epochs = 5
log = Report(n_epochs)
for epoch in range(n_epochs):
_n = len(train_loader)
for ix, inputs in enumerate(train_loader):
loss, loc_loss,regr_loss, accs = train_batch(inputs, \
frcnn, optimizer, criterion)
pos = (epoch + (ix+1)/_n)
log.record(pos, trn_loss=loss.item(), \
trn_loc_loss=loc_loss, \
trn_regr_loss=regr_loss, \
trn_acc=accs.mean(), end='\r')
_n = len(test_loader)
for ix,inputs in enumerate(test_loader):
_clss, _deltas, loss, \
loc_loss, regr_loss, accs = validate_batch(inputs, \
frcnn, criterion)
pos = (epoch + (ix+1)/_n)
log.record(pos, val_loss=loss.item(), \
val_loc_loss=loc_loss, \
val_regr_loss=regr_loss, \
val_acc=accs.mean(), end='\r')
# Plotting training and validation metrics
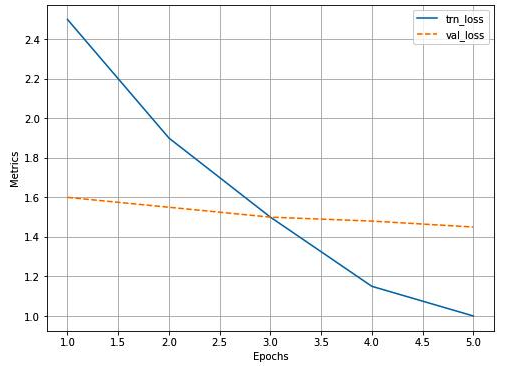
log.plot_epochs('trn_loss,val_loss'.split(','))整体损失的变化如下:
6.定义一个函数来预测测试图像:
- 定义将文件名作为输入的函数,然后读取文件并将其大小调整为 224 x 224:
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib.patches as mpatches
from torchvision.ops import nms
from PIL import Image
def test_predictions(filename):
img = cv2.resize(np.array(Image.open(filename)), \
(224,224))- 获取 region proposal 并将其转换为 (x1,y1,x2,y2) 格式(左上像素和右下像素坐标),然后将这些值转换为它们所在的宽高比,成正比图片:
candidates = extract_candidates(img)
candidates = [(x,y,x+w,y+h) for x,y,w,h in candidates]- 预处理图像并缩放感兴趣区域 ( rois):
input = preprocess_image(img/255.)[None]
rois = [[x/224,y/224,X/224,Y/224] for x,y,X,Y in \
Candidates]- 由于所有提案都属于同一图像,rixs因此将是一个零列表(与提案数量一样多):
rixs = np.array([0]*len(rois))- 前向传播输入并rois通过经过训练的模型,并获得每个提案的置信度和类别分数:
rois,rixs = [torch.Tensor(item).to(device) for item in \
[rois, rixs]]
with torch.no_grad():
frcnn.eval()
probs, deltas = frcnn(input, rois, rixs)
confs, clss = torch.max(probs, -1)- 过滤掉背景类:
candidates = np.array(candidates)
confs,clss,probs,deltas=[tensor.detach().cpu().numpy() \
for tensor in [confs, \
clss, probs, deltas]]
ixs = clss!=background_class
confs, clss, probs, deltas,candidates = [tensor[ixs] for \
tensor in [confs, clss, probs, deltas,candidates]]
bbs = candidates + deltas- 删除近乎重复的边界框并获取那些高度自信的模型是对象的建议的索引: nms
ixs = nms(torch.tensor(bbs.astype(np.float32)), \
torch.tensor(confs), 0.05)
confs, clss, probs,deltas,candidates,bbs = [tensor[ixs] \
for tensor in [confs,clss,probs, \
deltas, candidates, bbs]]
if len(ixs) == 1:
confs, clss, probs, deltas, candidates, bbs = \
[tensor[None] for tensor in [confs,clss, \
probs, deltas, candidates, bbs]]
bbs = bbs.astype(np.uint16)- 绘制获得的边界框:
_, ax = plt.subplots(1, 2, figsize=(20,10))
show(img, ax=ax[0])
ax[0].grid(False)
ax[0].set_title(filename.split ('/')[-1])
if len(confs) == 0:
ax[1].imshow(img)
ax[1].set_title('No objects')
plt.show()
return
else:
show( img,bbs=bbs.tolist(),texts=[target2label[c] for \
c in clss.tolist()],ax=ax[1])
plt.show()7.在测试图像上预测:
test_predictions(test_ds[29][-1])前面的代码结果如下:

上述代码执行时间为 0.5 秒,明显优于 R-CNN。但是,实时使用还是很慢的。这主要是因为我们仍在使用两种不同的模型,一种用于生成区域建议,另一种用于预测类别和修正。在下一章中,我们将学习使用单一模型进行预测,以便在实时场景中快速推理。
概括
在本章中,我们从学习如何为对象定位和检测过程创建训练数据集开始。接下来,我们了解了 SelectiveSearch,这是一种基于邻近像素相似度推荐区域的区域提议技术。接下来,我们学习了计算 IoU 度量,以了解图像中存在的对象周围的预测边界框的优劣。接下来,我们学习了执行非最大抑制以在图像中为每个对象获取一个边界框,然后再学习从头开始构建 R-CNN 和 Fast R-CNN 模型。此外,我们了解了 R-CNN 速度慢的原因,以及 Fast R-CNN 如何利用 RoI 池化并从特征图中获取区域建议来加快推理速度。最后,
在下一章中,我们将了解一些用于在更实时的基础上进行推理的现代目标检测技术。
问题
- 区域提议技术如何生成提议?
- 如果图像中有多个对象,IoU 是如何计算的?
- 为什么 R-CNN 需要很长时间才能生成预测?
- 为什么 Fast R-CNN 比 R-CNN 更快?
- 投资回报率池如何工作?
- 在预测边界框校正时,没有多层发布获得的特征图有什么影响?
- 为什么我们在计算整体损失时必须为回归损失分配更高的权重?
- 非最大抑制如何工作?