数据库表迁移是开发者必须要掌握的一种能力,对中高级开发者来说更是如此。工作中随着公司业务不断发展、系统架构的慢慢调整演化,迁移数据库表是不可避免的。由于数据是公司最最核心的资产,所以对生产环境数据库表的迁移并不是谁都可以去实施操作的,所以你会发现很多人其实对数据库表的迁移并没有相关思路,因为缺少实践的机会,初次承担这样的任务时会有些不太自信,因为不知道自己的处理流程是否安全可靠,毕竟数据上的问题一般都是很严重的。
本文以实际开发中的项目为背景,尽量全面的分享给你生产环境中数据库表的迁移思路及迁移实践。注意:数据库表迁移和你自己的业务有强关联性,比如业务的高低峰时间、业务可容忍的短时写不可用的程度,等等,自己负责迁移时必须具体问题具体分析。
OK,直奔主题~
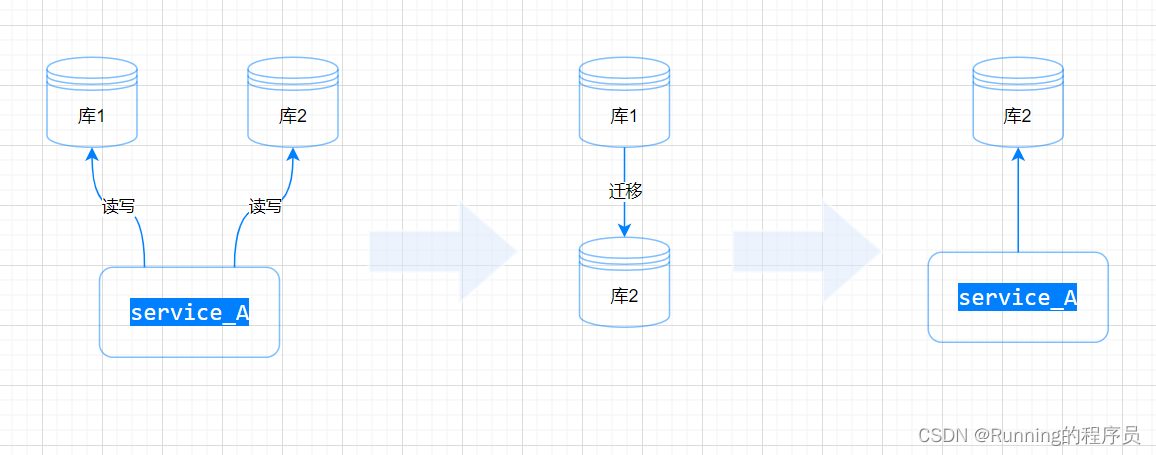
场景模型一:库1(源库)只有一个服务使用
之前负责的服务中有个老服务,这里我们称之为service_A,历史原因这个服务中
配置了两个数据源,连接了两个数据库。在公司微服务化的系统架构中,随着各服务各系统边界的清晰和稳定,service_A使用两个库就变得多余,浪费系统资源
同时也增加了维护成本。总之就是需要把service_A回归为使用单库。所以,自然就要把一个库表(这里我们称为库1)迁移到另一个库(这里我们称为库2),如下图:
OK,明白了我们的诉求之后,接下来说下生产环境中的迁移方法:
tips: 迁移请选在业务的低峰日的低峰时间去实施,迁移的核心是要保证数据的一致性!
迁移步骤:
迁移实施前的处理流程:
1.开发工程师在业务系统也就是微服务中catch数据库相关异常,如Java服务,那就在项目的统一切面中做处理:优点是不会侵入业务代码;或者添加开关:顾名思义要在业务逻辑所在的接口中添加,可能需要改动多处,并给出友好提示,比如如下的简单处理:
@Slf4j
@RestControllerAdvice
public class ExceptionAdvice {
@ExceptionHandler(MySQLSyntaxErrorException.class)
void exception(MySQLSyntaxErrorException ex) {
log.error(StringUtils.EMPTY, ex);
throw new RuntimeException("系统升级中请稍后再试");
}
@ExceptionHandler(BadSqlGrammarException.class)
void exception(BadSqlGrammarException ex) {
log.error(StringUtils.EMPTY, ex);
throw new RuntimeException("系统升级中请稍后再试");
}
@ExceptionHandler(BadSqlGrammarException.class)
void exception(CommunicationsException ex) {
log.error(StringUtils.EMPTY, ex);
throw new RuntimeException("系统升级中请稍后再试");
}
}
改完测试OK之后将代码发布到生产环境,本步骤本质是迁移前的
预处理阶段
2.通知测试提前造一些线上需要验证的数据,方便迁移时快速验证
迁移实施时的流程:
1.创建源库(库1)到目标库(库2)的实时同步的任务(全量+增量),如果你们公司用的是云厂商提供的RDS,可以用他们提供的DTS工具去做同步,如果是自建的IDC,那么可以通过canal等开源工具去做同步;请提前评估待同步的数据量,大数据量时可能耗时一周甚至更多(中大型公司,此步骤由DBA实施)
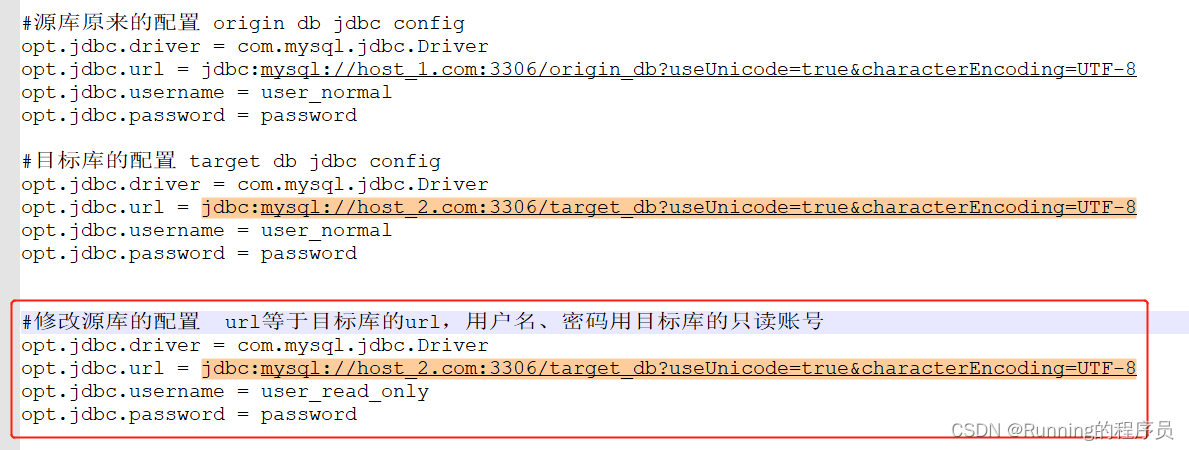
2.提供目标库的只读账号、密码(中大型公司,此步骤由DBA实施)
3.检查源库和目标库之间是否还有DTS同步任务(canal同步信息),且是否已经同步到最新,DBA将结果通知开发(中大型公司,此步骤由DBA实施)
4.在配置中心中如Apollo、nacos等将连接源库的url切换到目标库,
源库账号、密码替换为第二步目标库的只读账号、密码, 配置发布后,重启自己的服务。注意,服务重启之后系统对源库表的写操作已经不支持, 支持可读。若此时有零星的写操作打到系统中,我们系统就会提示我们前面给的提示信息:系统升级中,请稍后再试。本步骤示意图如下:
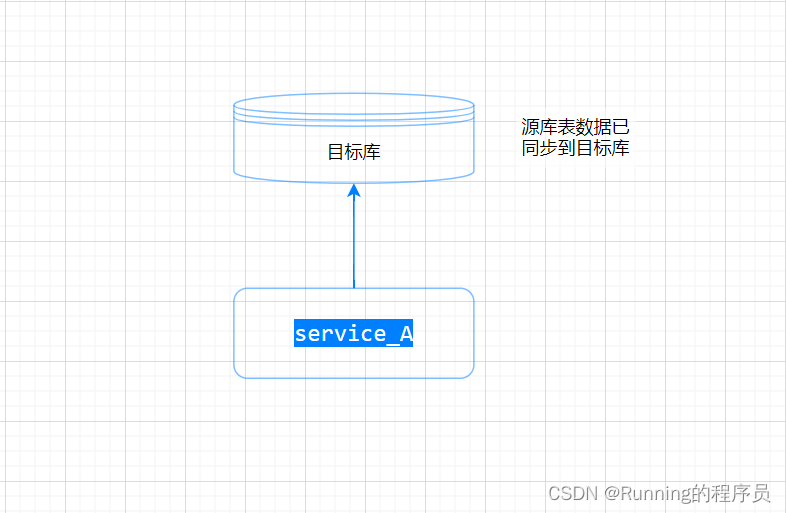
修改配置中心的数据库连接配置
5.再次检查源库流量(确保源库无流量,二次确认),然后关闭实时同步任务,DBA通知开发
6.修改配置中心中源库账号,使用目标库的账号(正常的读写账号),发布配置,重启服务,使用提前造好的测试数据验证迁移表的读写是否都正常;操做验证相关核心流程的读写都OK就可以了
7.数据迁移结束,可以睡觉了
迁移后续处理流程
迁移结束后,你可以排期进行如下的后续清理操作:
-
删除项目中关于源数据库的配置,服务回归单数据源,
-
删除配置中心上关于源数据库的配置
-
测试验证通过后,发布生产,结束
当然这个后续处理流程你也可以直接在步骤6中做掉,我习惯于拆解问题,分开处理。
迁移总结:
1.可以发现上述迁移过程对源库表是存在短暂停写的,步骤4执行之后写操作影响开始,步骤6执行之后恢复正常。整个过程前期演练好,实际上耗时很短,2分钟左右的时间
2.正因为方案有停写的操作,所以此方案不会存在迁移前后数据不一致的问题,
没有数据的一致性问题,是这个方案的优点
3.生产环境实施前,请在fat、uat等环境认真严格的演练
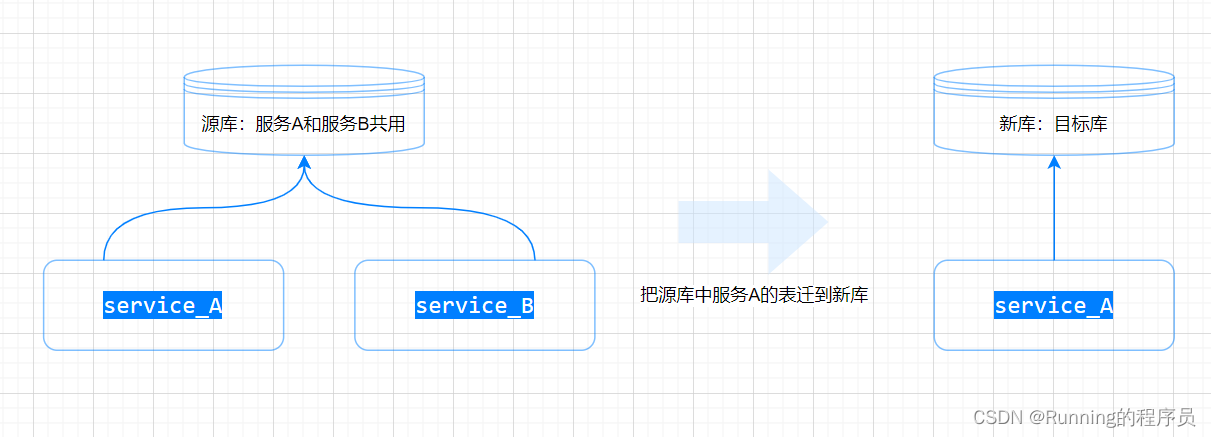
场景模型二:库中的表被两个不同的服务使用
库中的表被两个不同的服务使用,这是我们系统在不断演化中最常见的场景,
一服一库,总之我们一般都会进行库表分离,也就是库表迁移了
迁移步骤:
迁移实施前的处理流程:
1.项目中给出友好提示(具体描述请看场景一)
2.测试造测试数据(具体描述请看场景一)
3.DBA创建一个源库新的账号,修改服务A的配置中心的数据库连接的用户名。此步骤非常重要,我们要把服务A和服务B连接源库的账号分开,这样在迁移实施时我们才能确定源库中是否还有服务A的流量,用于判定是否可以关闭源库和目标库的
同步任务。如果服务A和B使用的账号一样,将无法确认,因为我们迁移时服务B始终是在正常工作的
我们可以通过这个命令查看库连接情况:SHOW PROCESSLIST;

迁移实施时的流程:
1.创建源库到目标库的实时同步任务(全量+增量)
2.提供目标库的只读账号、密码
3.检查源库和目标库之间是否还有DTS同步任务(canal同步信息),且是否已经同步到最新,DBA将结果通知开发
4.在配置中心中将连接源库的url切换到目标库,源库账号、密码替换为第二步目标库的只读账号、密码, 配置发布后,重启自己的服务。注意,服务重启之后系统对源库表的写操作已经不支持, 支持可读。若此时有零星的写操作打到系统中,我们系统就会提示我们前面给的提示信息:系统升级中,请稍后再试。
5.再次检查源库中服务A账号的流量(确保源库相关账号无流量,二次确认),然后关闭实时同步任务,DBA通知开发
6.修改服务A配置中心中源库账号,使用目标库的读写账号,发布配置,重启服务,
使用提前造好的测试数据验证迁移表的读写是否都正常;操做验证相关核心流程的读写都OK就可以了
迁移结束,睡觉...
迁移后续处理流程
后续可以将源库中服务A的表清理掉
迁移总结:
迁移总结同场景一
分析总结
上述两个方案基本可以解决我们日常大多数的迁移需求,优点就是简单易实施且不存在数据的一致性问题,可靠,不足就是存在短暂的不可写。在实际迁移时建议优先考虑这种方案,因为简单和可靠应该是我们的首选
双写方案
如果我们的系统完全不能接受停写(即使是在低峰期)那怎么办呢,需要我们怎么迁移库表?针对这种情况业界一般使用所谓的:双写方案。双写方案是指迁移中我们不会暂停系统的写入能力且同时写入源库和目标库,具体实施步骤如下:
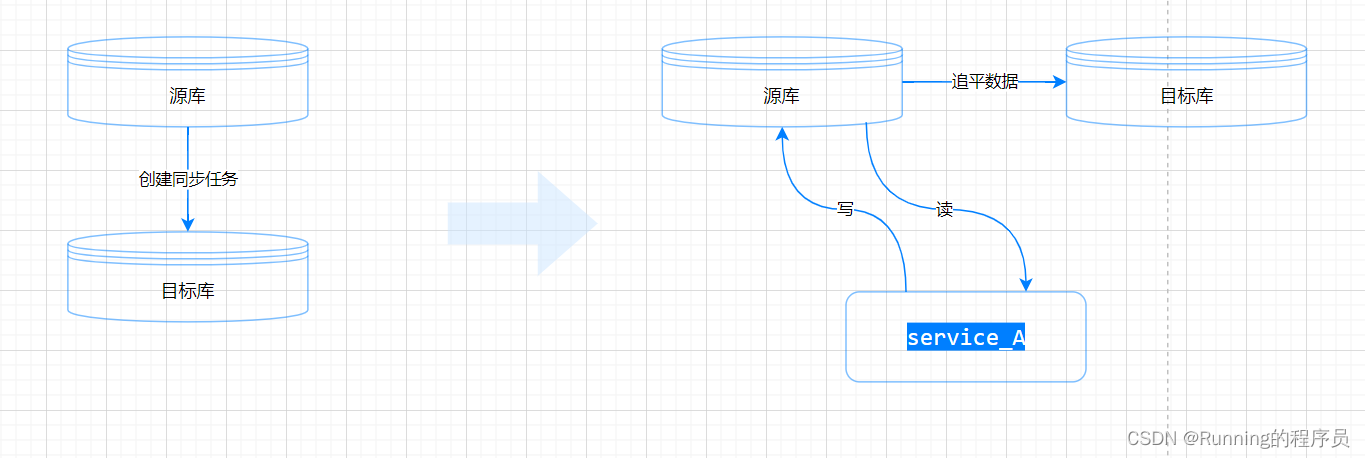
1.创建源库到目标库的同步任务,全量+增量,等待目标库追平源库表数据
2.项目改动,修改系统代码,支持写源库的同时也要写入目标库,写目标库可以使用异步的方式,建议使用MQ,mq异步、解耦的同时也具有重试的机制,当然重试之后仍然失败,那么需要保存失败记录,以便后续手动维护数据。同时系统中需要添加开关用于控制何时开始异步写入目标库,开关默认关闭
3.数据追平之后,在业务低峰时间开始实施迁移的核心操作,关闭源库到目标库的同步任务同时立即打开第二步中设置的开关,这样系统就开始同步写源库和目标库(异步方式)了;注意关闭同步任务并立即打开设置的开关这个地方虽然耗时
很短(秒级),但是可能也会造成源库和目标库数据的不一致。
4.系统的双写打开之后,接着需要我们检查源库表和目标库表中的数据是否一致,此步骤是重中之重,关系到迁移是否成功。发现有不一致的数据,需要我们手动维护使之一致。如果发现数据严重不一致,那就再关闭开关,迁移失败。
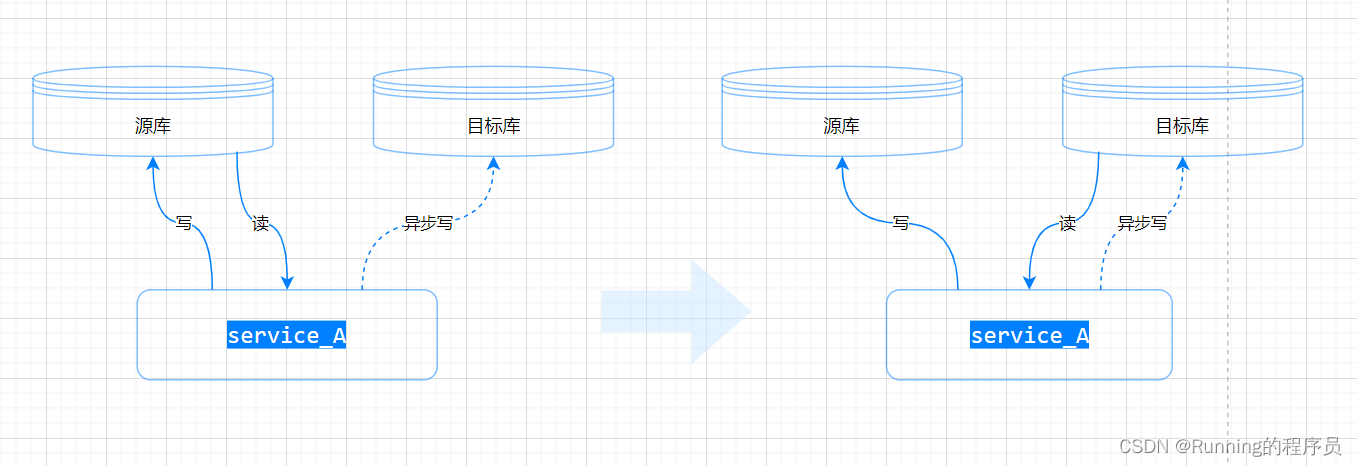
5.源库和目标库两边数据一致后,我们需要修改系统和配置中心的配置,让系统从目标库读,双写不变;由于是异步写目标库,所以此时读可能存在延时(一般为毫秒级)
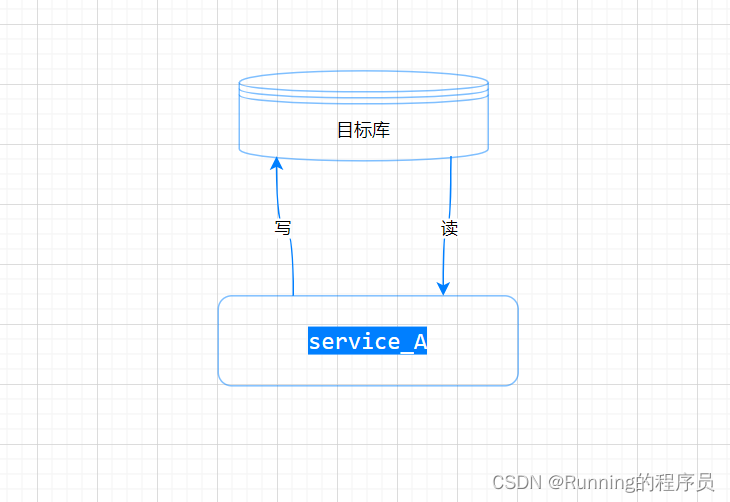
6.检查系统核心流程读写是否正常,然后修改系统代码、配置中心配置,使读写都走目标库,同时关闭异步写目标库
7.再次检查系统的读写是否正常,源库、目标库数据是否一致
结束
双写方案总结
1.迁移中没有停写的要求
2.正因为没有停写,所以可能导致源库和目标库数据的不一致,需要严格校验数据的一致性
3.代码改动会较多,且需考虑周到
4.若没有必须的理由建议不使用该方案
OK,结束,咱们回聊~



![[C++基础]-初识模板](https://img-blog.csdnimg.cn/b6aa563e84fe47acb989c952444f798d.png)