real-world image and video super-resolution
文章目录
- real-world image and video super-resolution
- 1. Toward Real-World Single Image Super-Resolution:A New Benchmark and A New Model(2019)
- 1.1 real-world数据集制作
- 1.2 LP-KPN网络结构
- 1.3 拉普拉斯金字塔构造代码
- 2. Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme
- 2.1 一个预训练的weight应用到一个实际任务时候的表现
- 2.2 real-VSR dataset
- 2.3 损失函数
- 2.4 实验
- 3. real-basic vsr:Investigating Tradeoffs in Real-World Video Super-Resolution
- 3.1 在面对实际超分场景时,是各种各样的退化场景, non-blind model 不能很好的应对。
- 3.2 因此作者设计了一个clean 模块,放在 basicVSR前面
- 3.3 traing speed 和 performance 分析
- 3.4 batch size 和 sequence length的比较
- 3.5 videoLQ dataset
- 3.6 运行realbasic vsr官方代码跑的结果如下:
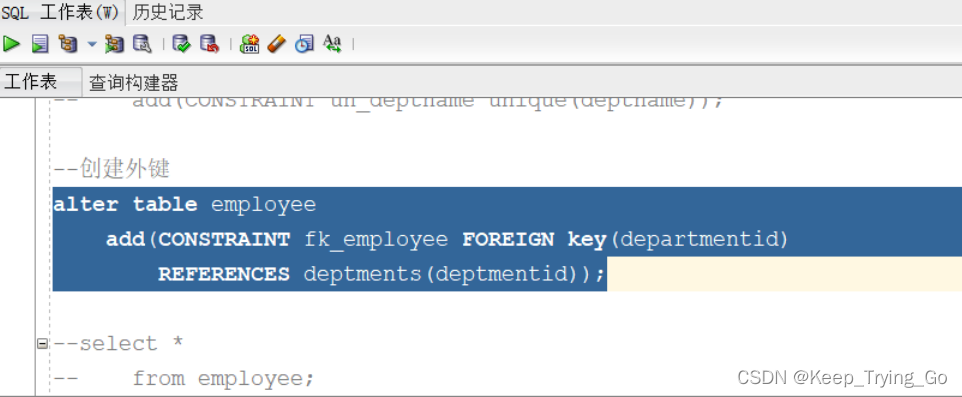
1. Toward Real-World Single Image Super-Resolution:A New Benchmark and A New Model(2019)
1.1 real-world数据集制作

如图所示,单反相机的简化成像模型

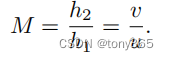
一般情况下,u > 3.0m, f最大时 105mm. u >> f
因此
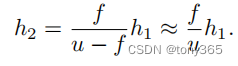
可见 h 2 h_2 h2 近似 与 f f f成正比, 通过增加 f f f, 可以得到更好的图像细节。
因此作者利用 105mm, 50mm, 35mm, 28mm四个焦距来制作数据对,其中105mm的数据用于生成ground-truth HR, 其他焦距生成对应LR。
整体框架如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8SPyCuvF-1666927501638)(20221024141334.png)]](https://img-blog.csdnimg.cn/3f1240ba560e495486179cb448f8909a.png)
同一个场景不同焦距的图像对,上面的图像肯定细节更多一些,首先进行畸变矫正,由于 图像边缘区域的畸变较大,作者使用photoshop中的方法无法完全得到完美的矫正,因此作者首先裁剪了中间的畸变较小的区域。
然后通过对 LR image进行裁剪和 迭代的方法进行像素级的配准,得到aligned LR image, 因此生成了一一对用的图像对。
作者利用 Canon 5D3和Nikon D810生成了 595个图像对。
关于本文介绍不同focus的像素级图像配准方法,是利用迭代的最小二乘方法,这里没有深入研究,有兴趣的可以参考官方提供的matlab源码。
1.2 LP-KPN网络结构
整体框图如下:

整体比较清晰,论文中的介绍也比较详细,可以参考代码理解
1.3 拉普拉斯金字塔构造代码
感觉这部分代码可以用于固定滤波核 的 滤波, 包括高斯滤波 和 高斯滤波上采样的写法
class GaussianBlur(nn.Module):
def __init__(self):
super(GaussianBlur, self).__init__()
kernel = np.array([[1./256., 4./256., 6./256., 4./256., 1./256.],
[4./256., 16./256., 24./256., 16./256., 4./256.],
[6./256., 24./256., 36./256., 24./256., 6./256.],
[4./256., 16./256., 24./256., 16./256., 4./256.],
[1./256., 4./256., 6./256., 4./256., 1./256.]])
kernel = torch.FloatTensor(kernel)
kernel = kernel.unsqueeze(0).unsqueeze(0).repeat(3,1,1,1)
self.gaussian = nn.Conv2d(3, 3, kernel_size=5, stride=1, padding=2,groups=3,bias=False)
self.gaussian.weight = nn.Parameter(kernel, requires_grad=False)
def forward(self, x):
x = self.gaussian(x)
return x
class GaussianBlur_Up(nn.Module):
def __init__(self):
super(GaussianBlur_Up, self).__init__()
kernel = np.array([[1./256., 4./256., 6./256., 4./256., 1./256.],
[4./256., 16./256., 24./256., 16./256., 4./256.],
[6./256., 24./256., 36./256., 24./256., 6./256.],
[4./256., 16./256., 24./256., 16./256., 4./256.],
[1./256., 4./256., 6./256., 4./256., 1./256.]])
kernel = kernel*4
kernel = torch.FloatTensor(kernel)
kernel = kernel.unsqueeze(0).unsqueeze(0).repeat(3,1,1,1)
self.gaussian = nn.Conv2d(3, 3, kernel_size=5, stride=1, padding=2,groups=3,bias=False)
self.gaussian.weight = nn.Parameter(kernel, requires_grad=False)
def forward(self, x):
x = self.gaussian(x)
return x
class Laplacian_pyramid(nn.Module):
def __init__(self, step=3):
super(Laplacian_pyramid, self).__init__()
self.Gau = GaussianBlur()
self.Gau_up = GaussianBlur_Up()
self.step = step
def forward(self, x):
Gaussian_lists = [x]
Laplacian_lists= []
size_lists = [x.size()[2:]]
for _ in range(self.step-1):
gaussian_down = self.Prdown(Gaussian_lists[-1])
Gaussian_lists.append(gaussian_down)
size_lists.append(gaussian_down.size()[2:])
Lap = Gaussian_lists[-2]-self.PrUp(Gaussian_lists[-1],size_lists[-2])
Laplacian_lists.append(Lap)
return Gaussian_lists, Laplacian_lists
def Prdown(self,x):
x_ = self.Gau(x)
x_ = x_[:,:,::2,::2]
return x_
def PrUp(self,x,sizes):
b, c, _, _ = x.size()
h,w = sizes
up_x = torch.zeros((b,c,h,w),device='cuda')
up_x[:,:,::2,::2]= x
up_x = self.Gau_up(up_x)
return up_x
2. Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme
2.1 一个预训练的weight应用到一个实际任务时候的表现

在Vimeo-90k上训练的模型应用在 iphone11上并没有大的改善,说明其实很多现有论文的pretrained weight 应用在实际数据集中是不可行的。
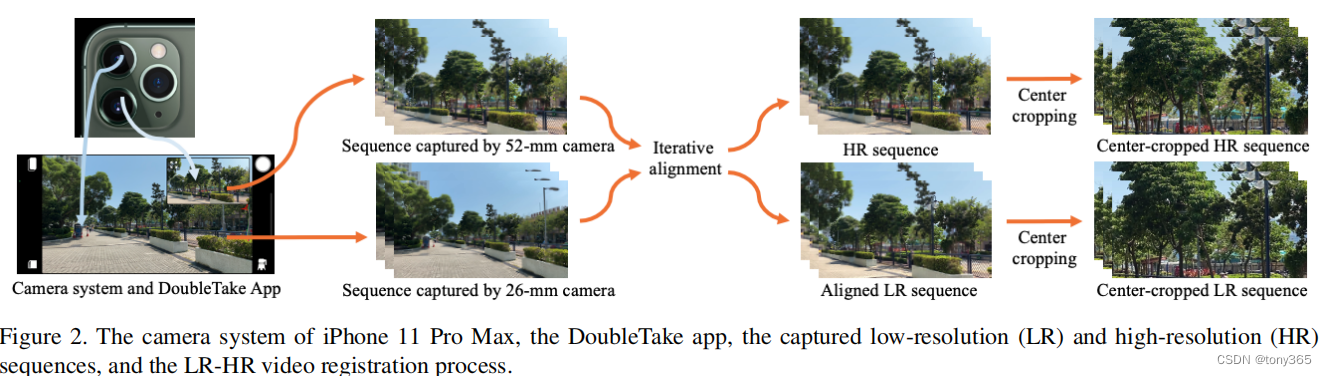
2.2 real-VSR dataset
配准方法和Toward Real-World Single Image Super-Resolution:A New Benchmark and A New Model(2019)方法类似
-
利用iphone的多摄像头系统和DoubleTake 软件采集 52mm等效焦距和26mm焦距分别生成 HR和LR序列。HR 是X2 LR
-
利用 Real-sr的方法进行配准
-
生成 500 LR-HR sequence pairs, each of which has 50 frames in length and 1024×512 pixels
2.3 损失函数
作者的目的是为了恢复图像细节,而不是全局的 luminance 和colors .
同样是分离为 Y, CbCr 通道。
Y通道的低频用SSIM,更加关注全局亮度

Y通道的高频用Charbonnier loss(类似L2)

CbCr通道用gradient weighted lss

整体框架如下图,此外作者还引入 GAN loss
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BSsfEJeC-1666927501640)(20221024175328.png)]](https://img-blog.csdnimg.cn/cd6a7573322e4750adc53f1eabc4b180.png)
2.4 实验
作者利用5个 VSR networks (RCAN, FSTRN,TOF, TDAN, EDVR),在 Vimeo-90k 和 RealVSR两个数据集上进行训练,得到10个模型, 再在作者提供的RealVSR test dataset上做测试,毫无疑问肯定是在 RealVSR 上训练效果好,能说明数据集好吗,不太能。
作者使用3个相邻帧去估计中间帧。
结果如下:可以看出各模型的泛化能力都很差,甚至不如bicubic

一些具体的细节对比:

3. real-basic vsr:Investigating Tradeoffs in Real-World Video Super-Resolution
3.1 在面对实际超分场景时,是各种各样的退化场景, non-blind model 不能很好的应对。

在non-blind vsr中序列越长,效果越好。但是对于实际场景并不是这样,因为序列太长可能会学到artifact.

3.2 因此作者设计了一个clean 模块,放在 basicVSR前面
1. 这样可以降低各种degradation对后续网络的影响,如下图:

cleaning 模块的输出是:
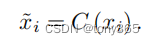
然后 进入 到 后续 VSRnet:
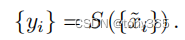
cleaning 模块的损失函数是:
其中d 表示低分辨率版本的gound-truth

网络末端的损失:

ρ \rho ρ 是 Charbonnier loss.
2. cleaning 模块是一个refinement 模块,可能被通过多次不断优化
停止条件是 相邻两次迭代的 差异 小于 θ \theta θ, θ \theta θ在non Gan-based model设为1.5,否则设为5。

3. cleaning 模块架构
cleaning 模块是 a stack of residual blocks。 作者提出也可以是其他任何结构,由于加入了cleaning mudule, 作者减少了 basic vsr net的 参数,将其中的redidual blocks从60减少到40.
代码中好像是20?
4. cleaning模块分析
4.1 不引入cleaning模块的loss 或者 引入循环网络代替 cleaning mudule,效果都不好。

4.2 refinement 迭代clean module可以更好的平衡 细节保留和不引入artifact。

θ
\theta
θ 可以确定 保留细节的程度
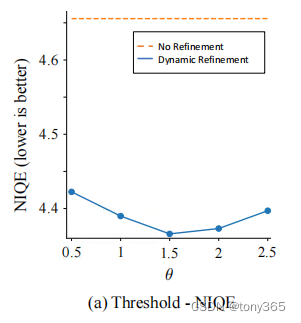
3.3 traing speed 和 performance 分析
在VSR中一般一个样本有L各图像组成图像序列,每个batch有 B个样本,因此每次训练需要载入 B x L 个图像,作者使用一个stochastic degradation(随机退化)方法可以减半 L的长度。
具体做法就是 对于 L / 2长度的序列,反转后得到 L长度,每个图像使用不同的 degradation 方法。
相比与 直接翻转(flip only),可以引入更多 variation。
方法和结果对比如下:

3.4 batch size 和 sequence length的比较
固定计算budget, 怎么选择 B 和 L呢?
序列长一些比较好。对于不同的模型不一定适用吧。

3.5 videoLQ dataset
covers a wide range of degradations, content, and resolution, 每个图像序列有100张图像。

3.6 运行realbasic vsr官方代码跑的结果如下:
是会清晰挺多,更加有棱有角,但是存在artifact,是否真实,和还原原图?