前言
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程,根据我在网上的了解,相比于Tensorflow,Pytorch简介易用。
一、为什么选择Pytorch
简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
速度:PyTorch 的灵活性不以速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras(这个年代比较久了) 等框架。
易用:PyTorch 是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称。
生态丰富:PyTorch 提供了完整的文档,循序渐进的指南,此外,相关社区还在逐渐壮大。
二、Pytorch的基本使用
2-0、张量的定义
张量:张量是一种特殊的数据结构,与Numpy中的arrays非常相似,在Pytorch中,我们使用张量对模型的输入和输出以及模型的参数进行编码。
注意:Tensors和Numpy中的数组具有底层内存共享,意味着不需要进行复制直接就可以相互转化。
2-1、直接创建张量
2-1-1、torch.Tensor()
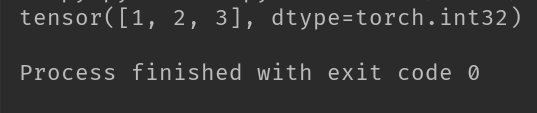
import torch
torch.Tensor([1, 2, 3])
print(T)
# 涉及到的参数
# data:data的数据类型可以是列表list、元组tuple、numpy数组ndarray、纯量scalar(又叫标量)和其他的一些数据类型。
# dtype:该参数可选参数,默认为None,如果不进行设置,生成的Tensor数据类型会拷贝data中传入的参数的数据类型,比如data中的数据类型为float,则默认会生成数据类型为torch.FloatTensor的Tensor。
# device:该参数可选参数,默认为None,如果不进行设置,会在当前的设备上为生成的Tensor分配内存。
# requires_grad:该参数为可选参数,默认为False,在为False的情况下,创建的Tensor不能进行梯度运算,改为True时,则可以计算梯度。
# pin_memory:该参数为可选参数,默认为False,如果设置为True,则在固定内存中分配当前Tensor,不过只适用于CPU中的Tensor。
输出:

2-1-2、torch.from_numpy()
# notice: 当然我们也可以直接将numpy数组直接转化为Tensor
import torch
import numpy as np
t1 = [1, 2, 3]
np_array = np.array(t1)
data = torch.from_numpy(np_array)
print(data)
输出:
2-2、创建数值张量
2-2-1、torch.ones()
# 创建全1张量。
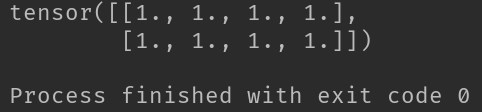
import torch
T = torch.ones((2,4))
print(T)输出:
2-2-2、torch.full()
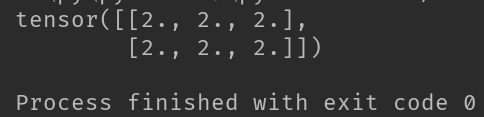
import torch
T = torch.full([2,3],2.0)
print(T)
# 参数:
# size: 定义了输出张量的形状。
# full_value: 定义填充的值。
输出:
2-2-3、torch.arange()
import torch
T = torch.arange(0, 10, 2)
print(T)
# 创建等差数列
# 参数:
# start: 等差数列开始。
# end: 等差数列结束。
# steps: 等差数列的差是多少。输出:

2-2-4、torch.linespace()
import torch
T = torch.linspace(2, 10, 5)
print(T)
# 创建线性间距向量
# 参数:
# start: 起始位置
# end: 结束位置
# steps: 步长
# out: 结果张量输出:

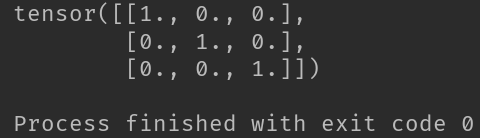
2-2-5、torch.eye()
import torch
T = torch.eye(3,3)
print(T)
# 创建对角矩阵
# 即生成对角线全为1,其余部分全为0的二维数组
# 参数:
# n: 行数
# m: 列数
# out: 输出类型,即输出到哪个矩阵。输出:
2-3、根据概率创建张量
2-3-1、torch.randn()
import torch
T = torch.randn(4)
print(T)
# 创建随机值
# 与rand不同的是,它创建的是包含了从标准正态分布(均值为0,方差为1)中取出的一组随机值。
# 参数
# size: 定义了输出张量的形状
# out: 结果张量输出:

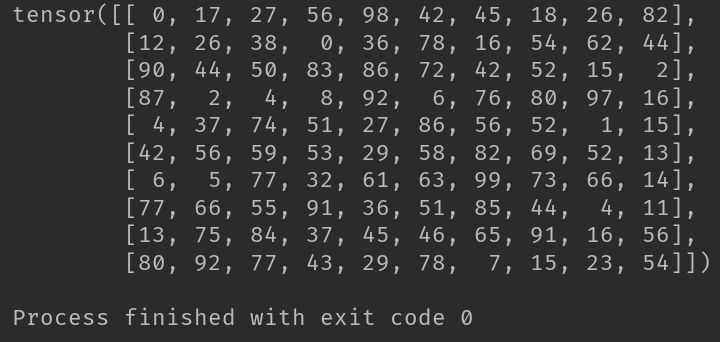
2-3-2、torch.randint()
import torch
T = torch.randint(100, size=(10, 10))
print(T)
# 返回一个填充了随机整数的张量,这些整数在low和high之间均匀生成。张量的shape由参数size定义。
# 参数说明:
# 常用参数:
# low ( int , optional ) – 要从分布中提取的最小整数。默认值:0。
# high ( int ) – 高于要从分布中提取的最高整数。
# size ( tuple ) – 定义输出张量形状的元组。
# 关键字参数:
# generator ( torch.Generator, optional) – 用于采样的伪随机数生成器
# out ( Tensor , optional ) – 输出张量。
# dtype ( torch.dtype , optional) – 如果是None,这个函数返回一个带有 dtype 的张量torch.int64。
# layout ( torch.layout, optional) – 返回张量的所需布局。默认值:torch.strided。
# device ( torch.device, optional) – 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(请参阅torch.set_default_tensor_type())。device将是 CPU 张量类型的 CPU 和 CUDA 张量类型的当前 CUDA 设备。
# requires_grad ( bool , optional ) – 如果 autograd 应该在返回的张量上记录操作。默认值:False。输出:
2-3-3、torch.rand()
import torch
T = torch.rand(4)
print(T)
# 创建随机值,包含了从区间(0,1)的均匀分布中抽取的一组随机数
# 均匀分布
# torch.rand(*sizes, out=None)输出:

2-3-4、torch.normal()
torch.normal: 生成正态分布
四种模式:
1、mean为标量,std为标量。
2、mean为标量,std为张量。
3、mean为张量,std为标量。
4、mean为张量,std为张量。
import torch
T = torch.normal(0, 1, size=(3,4))
print(T)
# mean为标量,std为标量,这种模式必须加size参数
输出:

2-4、张量的一些操作:拼接、切分索引变换
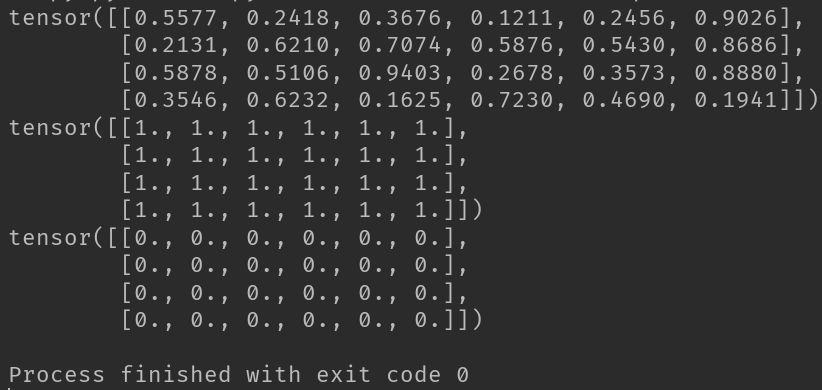
2-4-1、torch.ones_like函数和torch.zeros_like函数
import torch
input = torch.rand(4, 6)
print(input)
# 生成与input形状相同、元素全为1的张量
a = torch.ones_like(input)
print(a)
# 生成与input形状相同、元素全为0的张量
b = torch.zeros_like(input)
print(b)
输出:
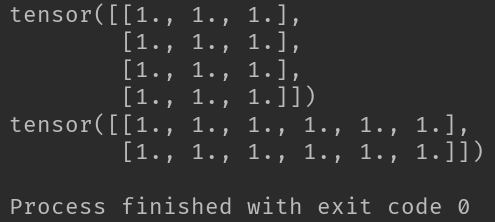
2-4-2、torch.cat函数
import torch
# 生成一个两行三列的全1张量。
t = torch.ones((2,3))
# 拼接函数cat
# 在给定维度上对输入的张量进行连接操作
T = torch.cat([t,t], dim=0)
print(T)
T1 = torch.cat([t,t], dim=1)
print(T1)
# 参数
# inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列
# dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
输出:
2-4-3、torch.stack函数
import torch
# 生成一个两行三列的全1张量。
t = torch.ones((2,3))
# 拼接函数stack
# 与cat不同的是,stack会增加维度。 简单来说就是增加新的维度进行堆叠。
# 扩维拼接!
T = torch.stack([t,t], dim=1)
print(T)
# 参数
# inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列
# dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
输出:
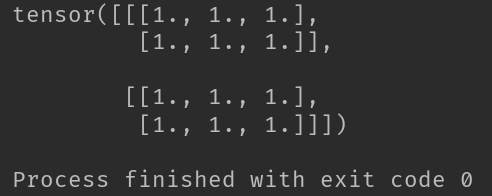
2-4-4、torch.chunk函数
import torch
# 生成一个两行五列的全1张量。
t = torch.ones((2,5))
# 在给定维度上将输入张量进行分块
T = torch.chunk(t, dim=0, chunks=5)
# input:被分块的张量。
# chunks:要切的份数。
# dim:在哪个维度上切分。
print(T)
T1 = torch.chunk(t, dim=1, chunks=5)
# input:被分块的张量。
# chunks:要切的份数。
# dim:在哪个维度上切分。
print(T1)
输出:
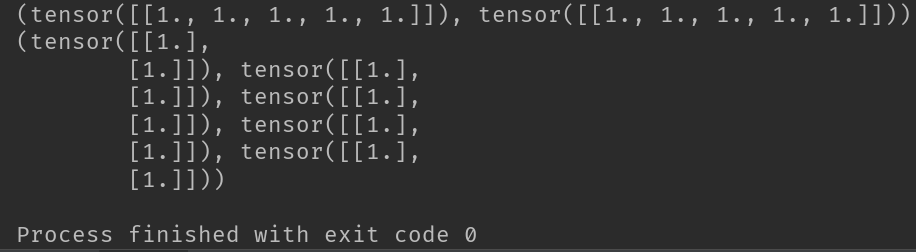
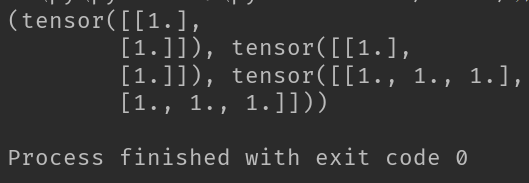
2-4-5、torch.split函数
import torch
# 生成一个两行五列的全1张量。
t = torch.ones((2,5))
# 将tensor分成块结构
T = torch.split(t, [1,1,3], dim=1)
# input:待输入张量
# split_size_or_sections: 需要切分的大小,可以为列表或者数字。
# dim:切分维度
print(T)
输出:
三、有关于Pytroch的其他知识
3-1、叶子节点
叶子节点:用户创建的节点被称之为叶子节点。(即Tensor有一个属性,叫is_leaf。) 所以可以Tensor调用is_leaf属性来判断是否为叶子节点,只有叶子节点才有梯度。非叶子节点的梯度在运行后会被直接释放掉。依赖于叶子节点的节点 requires_grad默认为True。
requires_grad:即是否需要计算梯度,当这个值为True时,我们将会记录tensor的运算过程并为自动求导做准备。,但是并不是每个requires_grad()设为True的值都会在backward的时候得到相应的grad.它还必须为leaf。只有是叶子张量的tensor在反向传播时才会将本身的grad传入到backward的运算中,如果想得到其他tensor在反向传播时的grad,可以使用retain_grad()这个属性。
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
print(w)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
# last 计算w的梯度
print(w.grad)
# tensor([5.])
3-2、动态图与静态图
1、动态图:运算与搭建同时进行,容易调节。 Pytorch采用动态图机制。
2、静态图:先搭建图,后运算,高效,但是不灵活。 Tensorflow采用静态图机制。
3-3、自动求梯度(autograd)
前言:神经网络通常依赖反向传播求梯度来更新网络参数,深度学习框架可以帮助我们自动地完成这种梯度运算。 Pytorch一般通过反向传播方法backward来实现梯度计算。除此以外,也可以调用torch.autograd.grad函数来实现梯度计算。
注意:backward方法通常在一个标量张量上调用,该方法求得的梯度将存在对应自变量张量的grad属性下。如果调用的张量非标量,则要传入一个和它同形状的gradient参数张量。相当于用该gradient参数张量与调用张量作向量点乘,得到的标量结果再反向传播。
案例一:backward方法在一个标量张量上调用。
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
# last 计算w的梯度
w.grad
# tensor([5.])
案例二:backward方法在非标量的反向传播
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c
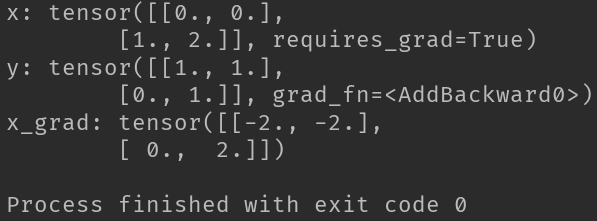
x = torch.tensor([[0.0,0.0],[1.0,2.0]],requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
gradient = torch.tensor([[1.0,1.0],[1.0,1.0]])
print("x:",x)
print("y:",y)
y.backward(gradient = gradient)
x_grad = x.grad
print("x_grad:",x_grad)
输出:
案例三:使用autograd.grad方法来求导数。
torch.autograd.backward: 求梯度。
参数:
outputs:用于求导的张量
inputs:需要梯度的张量
create_graph: 创建导数计算图,用于高阶求导
retain_graph: 保存计算图
grad_outputs: 多梯度权重
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的导数
x = torch.tensor(0.0,requires_grad = True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a*torch.pow(x,2) + b*x + c
# create_graph 设置为 True 将允许创建更高阶的导数
dy_dx = torch.autograd.grad(y,x,create_graph=True)[0]
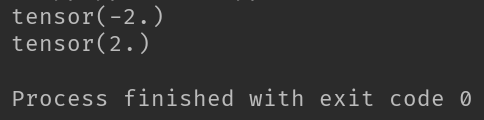
print(dy_dx.data)
# 求二阶导数
dy2_dx2 = torch.autograd.grad(dy_dx,x)[0]
print(dy2_dx2.data)
输出:
四、数据读取机制Dataloader与Dataset
Dataloader方法:
# torch.utils.data.DataLoader
# 参数:
# dataset: Dataset类,决定数据从哪读取以及如何读取
# batchsize:批大小
# num_works: 是否多进程读取数据
# shuffle: 每个epoch是否乱序
# drop_last: 当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch、Iteration、Batchsize的含义:
# Epoch:所有训练样本都输入到模型中,称为一个Epoch
# Iteration: 一批样本输入到模型中,称之为一个Iteration
# Batchsize: 批大小,决定一个Epoch有多少个Iteration
五、数据预处理transforms模块机制
transforms: 图像预处理模块,对数据进行增强,即对训练集进行变换,使得模型的泛化能力更强。
# torchvision.transforms: 图像预处理模块
# torchvision.datasets: 常用数据集的dataset实现
# torchvision.model: 常用的模型与训练
# transforms: 数据中心化、标准化、缩放、裁剪、旋转、翻转、填充、噪声添加、灰度变换、线性变换、仿射变换、亮度、饱和度以及对比度变换。
# transforms.ToTensor(): 用于对载入的图片数据进行类型转换,把之前构成PIL图片的数据转换成Tensor数据类型的变量,让Pytorch能够对其进行计算和处理。
# transforms.Compose():可以被看做是一种容器,将数据处理方法组合到一起
# transforms.RandomCrop(): 随机裁剪,对于载入的图片按照我们需要的大小进行随机裁剪。如果传入的是一个整型数据,那么裁剪的长和宽都是这个数值。
# transforms.Normalize(): 数据标准化,这里使用的是标准正态分布变换,这种方法需要使用原始数据的均值(Mean)和标准差(Standard Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布。
# 功能:逐channel的对图像进行标准化
# output = (input - mean) /std
# mean: 各通道的均值
# std: 各通道的标准差
# inplace: 是否原地操作
六、如何使用CIFAR10数据集
更多Transform模块方法详见博客。
Pytorch:transforms二十二种数据预处理方法及自定义transforms方法.
参考:https://blog.csdn.net/weixin_42475060/article/details/126175837