Oracle行转列函数,列转行函数
Oracle 可以通过
PIVOT,UNPIVOT,分解一行里面的值为多个列,及来合并多个列为一行。
PIVOT
PIVOT是用于将行数据转换为列数据的查询操作(类似数据透视表)。通过使用PIVOT,您可以按照特定的列值将数据进行汇总,并将其转换为新的列。
语法
pivot(
聚合函数for需要转为列的字段名in(需要转为列的字段值))
SELECT *
FROM (
-- 源数据查询
SELECT column1, column2, ..., pivot_column, value_column
FROM your_source_table
)
PIVOT (
-- 聚合函数和列定义
aggregate_function(value_column)
FOR pivot_column IN (value1 AS alias1, value2 AS alias2, ..., valuen AS aliasn)
);
-
aggregate_function:指定用于对value_column进行聚合操作的函数,如SUM、AVG等。(FOR关键字前面的部分只能使用聚合函数) -
value_column: 指定要聚合的源数据列。 -
pivot_column: 指定要透视的列,其唯一值将被用作新列的列头。且源数据查询的select中必须包含这个字段,以便PIVOT函数可以使用到它。(可以理解为用这个字段来进行group by) -
value1 AS alias1, value2 AS alias2, ..., valuen AS aliasn: 为透视列的每个唯一值指定一个别名,这些别名将成为新列的列头。遗憾的是这里不是使用子查询。
准备
CREATE TABLE sales_data (
product_name VARCHAR2(100),
region VARCHAR2(50),
sale_month VARCHAR2(10),
sale_amount NUMBER
);
-- 商品 A 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-01', 5000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-01', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-01', 4500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-02', 8000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-02', 7500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-02', 6000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'North', '2024-03', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'South', '2024-03', 8500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product A', 'West', '2024-03', 6200);
-- 商品 B 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-01', 6000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-01', 8000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-01', 5500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-02', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-02', 9000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-02', 6500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'North', '2024-03', 7800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'South', '2024-03', 9200);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product B', 'West', '2024-03', 6900);
-- 商品 C 在不同地区的销售数据
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-01', 5500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-01', 6000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-01', 4800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-02', 6500);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-02', 7000);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-02', 5800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'North', '2024-03', 7200);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'South', '2024-03', 7800);
INSERT INTO sales_data (product_name, region, sale_month, sale_amount) VALUES ('Product C', 'West', '2024-03', 6000);
样例一
-- 每个商品在不同的地区的总销售额
SELECT
product_name,
region,
sum( SALE_AMOUNT )
FROM
sales_data
GROUP BY
product_name,
region
ORDER BY
product_name,
region
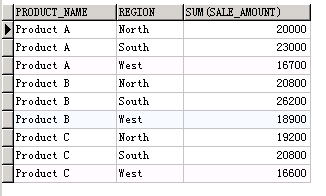
这样是一行一行显示的,我们来转换为一列一列的显示。
-- 以商品为行 地区为列
SELECT
*
FROM
( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) FOR region IN ( 'North', 'South', 'West' ) ) ORDER BY product_name
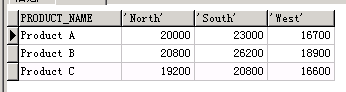
-- 已地区为行 商品为列
SELECT
*
FROM
( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region
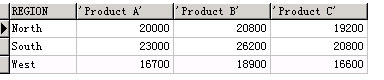
多个聚合函数
每个商品在不同地区的销售总额,每个商品在不同地区的销售平均值
SELECT
*
FROM
( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ),avg( SALE_AMOUNT ) FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region ;
-- > ORA-00918: 未明确定义列
-- 这样直接写两个聚合函数在pivot里面是会报错。是因为两个聚合函数都没有使用,默认是使用in里面的值作为列名。
-- 所以当我们在使用多个聚合函数的时候需要至少一个为聚合函数指定 as
SELECT
*
FROM
( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT ( sum( SALE_AMOUNT ) as sum,avg( SALE_AMOUNT )as avg FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) ) ORDER BY region ;

注意
我这里用了
select再给嵌套了一层,并且去掉了Name字段。为什么?
我们使用
select*试试。
SELECT
*
FROM
sales_data PIVOT ( sum( SALE_AMOUNT ) AS sum, avg( SALE_AMOUNT ) AS avg FOR product_name IN ( 'Product A', 'Product B', 'Product C' ) )
ORDER BY
region
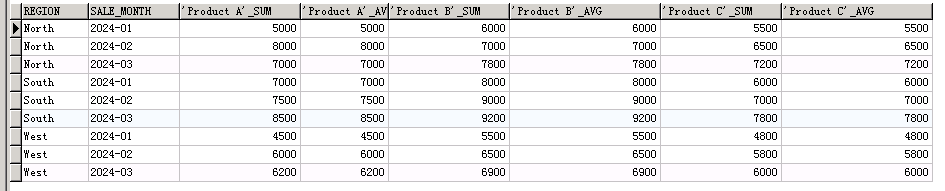
会发现想象的不太一样。😂
其实,这是因为
pivot会以移出pivot_column和value_column后的字段组合当成唯一键(就类似以那几个字段group by)。所以
直接使用 pivot这个查询翻译成自然语言就是:查询每个地区,每个月的,商品的销售额。
多个FOR
也就是自己查询 对于product_name,region,销售额的总和。直接用列显示
SELECT
*
FROM
( SELECT product_name, region, SALE_AMOUNT FROM sales_data ) PIVOT (
sum( SALE_AMOUNT ) AS sum FOR ( product_name, region ) IN (
( 'Product A', 'North' ) AS result1,
( 'Product A', 'South' ) AS result2,
( 'Product A', 'West' ) AS result3,
( 'Product B', 'North' ) AS result4,
( 'Product B', 'South' ) AS result5,
( 'Product B', 'West' ) AS result16,
( 'Product C', 'North' ) AS result7,
( 'Product C', 'South' ) AS result8,
( 'Product C', 'West' ) AS result9
)
)

总结
pivot函数是写在表名后面的,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。
pivot会以移出pivot_column与value_column剩下的字段组合成唯一键,每个唯一值占一行,查询每一组满足唯一键的聚合函数的值。
pivot当使用多个聚合函数的时候至少需要指定一个as
pivot的in中是不支持使用子查询的,这是个缺点,但是也可以使用动态拼接的方式把想要转换为列的值拼接到这。
UNPIVOT
UNPIVOT是PIVOT的相反操作。它用于将列数据转换为行数据。将多列合并多为一列,合并为一列后自然需要多行才能展示全数据
语法
UNPIVOT(
被合并列的列名for合并后的列名in (被合并的列(),…))
SELECT
*
FROM
tableName UNPIVOT ( fieldValueName FOR fieldName IN ( filedValue,... ))
- fieldValueName:被合并列的列名,可以随便起名称。
- fieldName:合并后的列名,可以随便起名称。
- filedValue:被合并的列。可以有多个。
准备
CREATE TABLE sales_by_region (
product_name VARCHAR2(100), -- 商品
region_name VARCHAR2(50), -- 地区
sales_q1 NUMBER, -- 第一季度
sales_q2 NUMBER, -- 第二季度
sales_q3 NUMBER, -- 第三季度
sales_q4 NUMBER -- 第四季度
);
-- 商品 A 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'North', 5000, 8000, 7000, 9000);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'South', 7000, 7500, 8500, 9200);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product A', 'West', 4500, 6000, 6200, 6900);
-- 商品 B 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'North', 6000, 7000, 7800, 8000);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'South', 8000, 9000, 9200, 9500);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product B', 'West', 5500, 6500, 6900, 7200);
-- 商品 C 在不同地区的季度销售数据
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'North', 5500, 6500, 7200, 7800);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'South', 6000, 7000, 7800, 8200);
INSERT INTO sales_by_region (product_name, region_name, sales_q1, sales_q2, sales_q3, sales_q4) VALUES ('Product C', 'West', 4800, 5800, 6000, 6500);
样例一
-- 普通查询
select * from sales_by_region
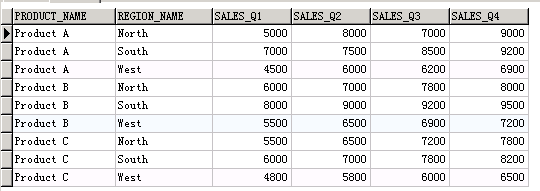
把四个季度的销售额合并到一个列中。
SELECT
*
FROM
sales_by_region UNPIVOT (销售额 FOR 季度 IN ( sales_q1, sales_q2 , sales_q3, sales_q4 )
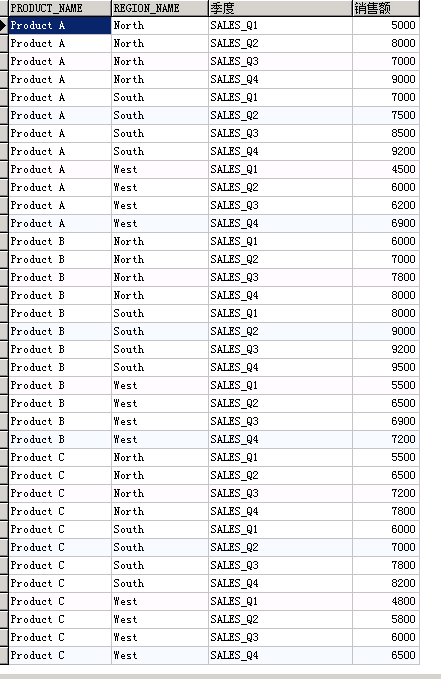
多个合并列
SELECT
*
FROM
sales_by_region UNPIVOT ( (销售额1 ,销售额2 ) FOR 季度 IN ( ( sales_q1, sales_q2 ) as '上季度' ,( sales_q3, sales_q4 ) as '下季度') );
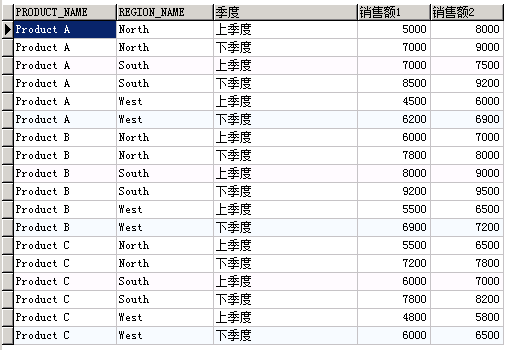
上季度的销售额1 就相当于sales_q1,
上季度的销售额2 就相当于sales_q2,
下季度的销售额1 就相当于sales_q3,
下季度的销售额1 就相当于sales_q4,
有点绕,对应好即可。
总结
unpivot函数也是写在表名后面,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。(与pivot一样)unpivot会以移出被合并的列,然后将剩余的列组合成一个唯一值,每一个唯一值占一行。unpivot被合并的列的列名会在,fieldName中当做值来显示。- 被合并的列可以通过
as改变在fieldName显示的值。- 大部分用法跟
pivot一致,可以相互参考。
ales_q3,下季度的销售额1 就相当于sales_q4,
有点绕,对应好即可。
总结
unpivot函数也是写在表名后面,如果需要把源表过滤后再转换为列显示的需要嵌套子查询。(与pivot一样)unpivot会以移出被合并的列,然后将剩余的列组合成一个唯一值,每一个唯一值占一行。unpivot被合并的列的列名会在,fieldName中当做值来显示。- 被合并的列可以通过
as改变在fieldName显示的值。- 大部分用法跟
pivot一致,可以相互参考。