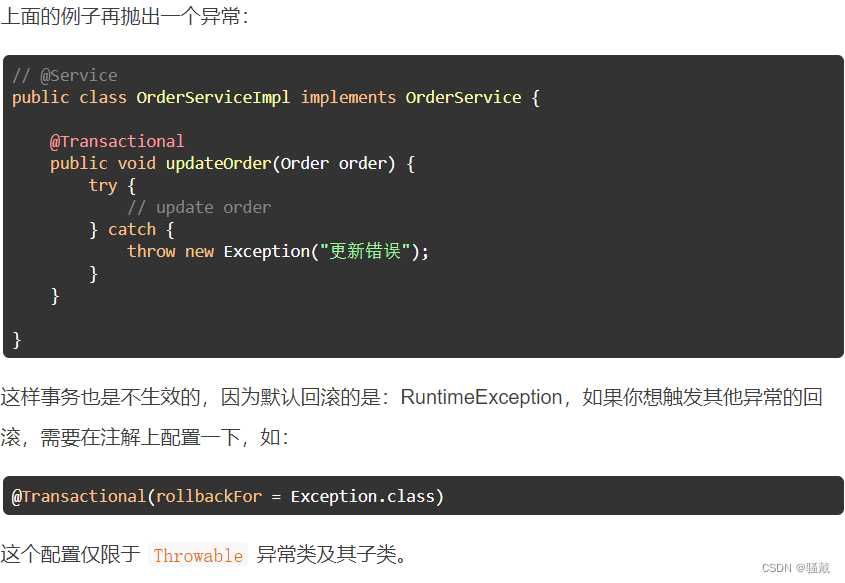
首先要明白几个概念:程序、进程、线程、纤程。
如果要非常严格的定义上来说的话,进程是操作系统用来做资源调度的基本单位。后来发现进程的切换是在的太费资源了,于是诞生了线程;线程多了来回切换还是很费资源,于是又诞生了纤程。所以从进程到线程再到纤程,可以看成是一层层的优化。
那什么是程序呢?从win系统角度来说,硬盘上的一个.exe可执行文件,就是一个程序。双击这个程序,在系统中运行起来的一个实例就是进程。所以理论上一个程序是可以对应多个进程实例,不过现在很多的程序都做了单进程的限制。
在一个进程里面,不同的执行路径就是一个个的线程,比如UI线程,网络线程.....在一个线程内部还可以分不同路径的,这就是纤程。
如果有学过操作系统基本原理的话,应该知道操作系统如何进行线程之间的切换。当CPU要切换不同的线程时,每个线程在自己内部会维护一个栈,每次切换线程的时候,都会将线程中的栈内信息保存好,这样通过栈内信息就知道每个线程执行到哪里了。
而纤程间的相互切换,也是通过维护栈内信息来完成。线程和纤程的本质区别就在于:线程的切换需要通过内核空间,纤程的切换无需经过内核空间。Linux系统分为用户空间(user)和内核空间(kernel),JVM肯定是跑在用户空间,需要进行一些系统调用的时候,必然要经过内核空间进行调用,譬如启动一个线程。每次启动线程都需要经过内核空间的调用,占用的资源较多,所以线程级的并发就比较的重量级,线程间的切换,消耗的资源比较多,耗时比较长。为了解决这个问题,有人提出那干脆将线程给挪到用户空间得了呗,这样相互之间的切换不经过内核空间,占用资源少,执行效率高。
以现在的操作系统来说,线程其实起不了太多,当一个系统起到1万个线程的时候,基本上所有的资源都浪费在线程间的切换上,干不了什么正经的事情。如果是纤程的话,随便起几万个跑起来照样轻轻松松。
不过一直到JDK13,官方都没有支持纤程这个玩意儿,随着JDK19 GA版本的发布,虚拟线程这一特性也闪亮登场,虚拟线程是 JDK 而并非OS 实现的轻量级线程,许多虚拟线程共享同一操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量,这就有点纤程的味道了。Oracle做事总是比别人慢一拍,整天脑子里不知道在想什么。现在想用纤程的话,得用一些第三方开源的纤程库,譬如Quasar。
<dependency>
<groupId>co.paralleluniverse</groupId>
<artifactId>quasar-core</artifactId>
<version>0.8.0</version>
</dependency>Quasar这个类库说起来也挺好笑,最新的一个版本是18年发布的0.8.0版本,然后就没有然后了,到现在23年了还没更新到1.0版本.....这东西拿来玩玩就可以了,实际项目中也不建议去使用。
package com.feenix.fiberboot;
import co.paralleluniverse.fibers.Fiber;
import co.paralleluniverse.fibers.SuspendExecution;
import co.paralleluniverse.strands.SuspendableRunnable;
public class HelloFiber {
public static void main(String[] args) {
long s = System.currentTimeMillis();
for (int k = 0; k < 10000; k++) {
Fiber<Void> fiber = new Fiber<>(new SuspendableRunnable() {
@Override
public void run() throws SuspendExecution, InterruptedException {
cal();
}
});
fiber.start();
/*Thread thread = new Thread(() -> {
cal();
});
thread.start();*/
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - s));
}
static void cal() {
int result = 0;
for (int i = 0; i < 10000; i++) {
for (int j = 0; j < 100; j++) {
result += j;
}
}
}
}
同样的计算过程,使用线程的耗时是纤程的3~5倍左右,这还是建立在数据量不是很大的情况下,随着数据量的增大,纤程的效率比线程快的不止一丁半点。

![[Linux]Linux项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/5082d146f0734292bdf6d13eb197672f.png)