数据集准备
在本文中,我们使用“Cats vs Dogs”的数据集。这个数据集包含了23,262张猫和狗的图像

你可能注意到了,这些照片没有归一化,它们的大小是不一样的
但是非常棒的一点是,你可以在Tensorflow Datasets中获取这个数据集
所以,确保你的环境里安装了Tensorflow Dataset
pip install tensorflow-dataset
和这个库中的其他数据集不同,这个数据集没有划分成训练集和测试集
所以我们需要自己对这两类数据集做个区分
关于数据集的更多信息:https://www.tensorflow.org/datasets/catalog/cats_vs_dogs
实现
这个实现分成了几个部分
首先,我们实现了一个类,其负责载入数据和准备数据。
然后,我们导入预训练模型,构建一个类用于修改最顶端的几层网络。
最后,我们把训练过程运行起来,并进行评估。
当然,在这之前,我们必须导入一些代码库,定义一些全局常量:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
IMG_SIZE = 160
BATCH_SIZE = 32
SHUFFLE_SIZE = 1000
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
数据载入器
这个类负责载入数据和准备数据,用于后续的数据处理。以下是这个类的实现:
class DataLoader(object):
def __init__(self, image_size, batch_size):
self.image_size = image_size
self.batch_size = batch_size
# 80% train data, 10% validation data, 10% test data
split_weights = (8, 1, 1)
splits = tfds.Split.TRAIN.subsplit(weighted=split_weights)
(self.train_data_raw, self.validation_data_raw, self.test_data_raw), self.metadata = tfds.load(
'cats_vs_dogs', split=list(splits),
with_info=True, as_supervised=True)
# Get the number of train examples
self.num_train_examples = self.metadata.splits['train'].num_examples*80/100
self.get_label_name = self.metadata.features['label'].int2str
# Pre-process data
self._prepare_data()
self._prepare_batches()
# Resize all images to image_size x image_size
def _prepare_data(self):
self.train_data = self.train_data_raw.map(self._resize_sample)
self.validation_data = self.validation_data_raw.map(self._resize_sample)
self.test_data = self.test_data_raw.map(self._resize_sample)
# Resize one image to image_size x image_size
def _resize_sample(self, image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1
image = tf.image.resize(image, (self.image_size, self.image_size))
return image, label
def _prepare_batches(self):
self.train_batches = self.train_data.shuffle(1000).batch(self.batch_size)
self.validation_batches = self.validation_data.batch(self.batch_size)
self.test_batches = self.test_data.batch(self.batch_size)
# Get defined number of not processed images
def get_random_raw_images(self, num_of_images):
random_train_raw_data = self.train_data_raw.shuffle(1000)
return random_train_raw_data.take(num_of_images)
这个类实现了很多功能,它实现了很多public方法:
_prepare_data:内部方法,用于缩放和归一化数据集里的图像。构造函数需要用到该函数。_resize_sample:内部方法,用于缩放单张图像。_prepare_batches:内部方法,用于将图像打包创建为batches。创建train_batches、validation_batches和test_batches,分别用于训练、评估过程。get_random_raw_images:这个方法用于从原始的、没有经过处理的数据中随机获取固定数量的图像。
但是,这个类的主要功能还是在构造函数中完成的。让我们仔细看看这个类的构造函数。
def __init__(self, image_size, batch_size):
self.image_size = image_size
self.batch_size = batch_size
# 80% train data, 10% validation data, 10% test data
split_weights = (8, 1, 1)
splits = tfds.Split.TRAIN.subsplit(weighted=split_weights)
(self.train_data_raw, self.validation_data_raw, self.test_data_raw), self.metadata = tfds.load(
'cats_vs_dogs', split=list(splits),
with_info=True, as_supervised=True)
# Get the number of train examples
self.num_train_examples = self.metadata.splits['train'].num_examples*80/100
self.get_label_name = self.metadata.features['label'].int2str
# Pre-process data
self._prepare_data()
self._prepare_batches()
首先我们通过传入参数定义了图像大小和batch大小
然后,由于该数据集本身没有区分训练集和测试集,我们通过划分权值对数据进行划分
一旦我们执行了数据划分,我们就开始计算训练样本数量,然后调用辅助函数来为训练准备数据
在这之后,我们需要做的仅仅是实例化这个类的对象,然后载入数据即可。
data_loader = DataLoader(IMG_SIZE, BATCH_SIZE)
plt.figure(figsize=(10, 8))
i = 0
for img, label in data_loader.get_random_raw_images(20):
plt.subplot(4, 5, i+1)
plt.imshow(img)
plt.title("{} - {}".format(data_loader.get_label_name(label), img.shape))
plt.xticks([])
plt.yticks([])
i += 1
plt.tight_layout()
plt.show()
输出结果

基础模型 & Wrapper
下一个步骤就是载入预训练模型了
这些模型位于tensorflow.kearas.applications
我们可以用下面的语句直接载入它们
vgg16_base = tf.keras.applications.VGG16(input_shape=IMG_SHAPE, include_top=False, weights='imagenet')
googlenet_base = tf.keras.applications.InceptionV3(input_shape=IMG_SHAPE, include_top=False, weights='imagenet')
resnet_base = tf.keras.applications.ResNet101V2(input_shape=IMG_SHAPE, include_top=False, weights='imagenet')
这段代码就是我们创建上述三种网络结构基础模型的方式
注意,每个模型构造函数的include_top参数传入的是false
这意味着这些模型是用于提取特征的
我们一旦创建了这些模型,我们就需要修改这些模型顶部的网络层,使之适用于我们的具体问题
我们使用Wrapper类来完成这个步骤
这个类接收预训练模型,然后添加一个Global Average Polling Layer和一个Dense Layer
本质上,这最后的Dense Layer会用于我们的二分类问题(猫或狗)
Wrapper类把所有这些元素都放到了一起,放在了同一个模型中
class Wrapper(tf.keras.Model):
def __init__(self, base_model):
super(Wrapper, self).__init__()
self.base_model = base_model
self.average_pooling_layer = tf.keras.layers.GlobalAveragePooling2D()
self.output_layer = tf.keras.layers.Dense(1)
def call(self, inputs):
x = self.base_model(inputs)
x = self.average_pooling_layer(x)
output = self.output_layer(x)
return output
然后我们就可以创建Cats vs Dogs分类问题的模型了,并且编译这个模型。
base_learning_rate = 0.0001
vgg16_base.trainable = False
vgg16 = Wrapper(vgg16_base)
vgg16.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss='binary_crossentropy',
metrics=['accuracy'])
googlenet_base.trainable = False
googlenet = Wrapper(googlenet_base)
googlenet.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss='binary_crossentropy',
metrics=['accuracy'])
resnet_base.trainable = False
resnet = Wrapper(resnet_base)
resnet.compile(optimizer=tf.keras.optimizers.RMSprop(lr=base_learning_rate),
loss='binary_crossentropy',
metrics=['accuracy'])
注意,我们标记了基础模型是不参与训练的
这意味着在训练过程中,我们只会训练新添加到顶部的网络层,而在网络底部的权重值不会发生变化。
训练
在我们开始整个训练过程之前,让我们思考一下,这些模型的大部头其实已经被训练过了
所以,我们可以执行评估过程来看看评估结果如何:
steps_per_epoch = round(data_loader.num_train_examples)//BATCH_SIZE
validation_steps = 20
loss1, accuracy1 = vgg16.evaluate(data_loader.validation_batches, steps = 20)
loss2, accuracy2 = googlenet.evaluate(data_loader.validation_batches, steps = 20)
loss3, accuracy3 = resnet.evaluate(data_loader.validation_batches, steps = 20)
print("--------VGG16---------")
print("Initial loss: {:.2f}".format(loss1))
print("Initial accuracy: {:.2f}".format(accuracy1))
print("---------------------------")
print("--------GoogLeNet---------")
print("Initial loss: {:.2f}".format(loss2))
print("Initial accuracy: {:.2f}".format(accuracy2))
print("---------------------------")
print("--------ResNet---------")
print("Initial loss: {:.2f}".format(loss3))
print("Initial accuracy: {:.2f}".format(accuracy3))
print("---------------------------")
有意思的是,这些模型在没有预先训练的情况下,我们得到的结果也还过得去(50%的精确度):
———VGG16———
Initial loss: 5.30
Initial accuracy: 0.51
—————————-
——GoogLeNet—–
Initial loss: 7.21
Initial accuracy: 0.51
—————————-
——–ResNet———
Initial loss: 6.01
Initial accuracy: 0.51
—————————-
把50%作为训练的起点已经挺好的了
所以,就让我们把训练过程跑起来吧,看看我们是否能得到更好的结果
首先,我们训练VGG16:
history = vgg16.fit(data_loader.train_batches, epochs=10, validation_data=data_loader.validation_batches)
训练过程历史数据显示大致如下:
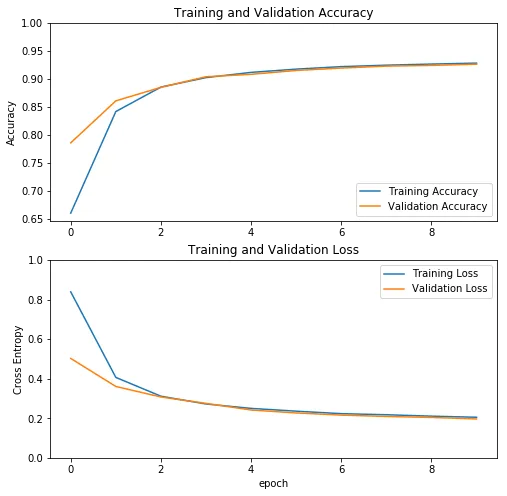
然后我们可以训练GoogLeNet
history = googlenet.fit(data_loader.train_batches,
epochs=10,
validation_data=data_loader.validation_batches)
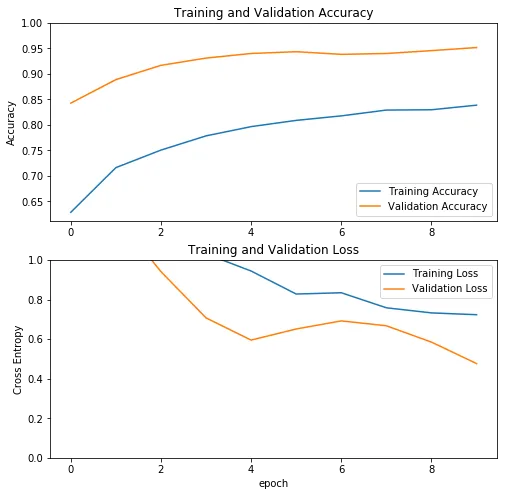
最后是ResNet的训练
history = resnet.fit(data_loader.train_batches,
epochs=10,
validation_data=data_loader.validation_batches)
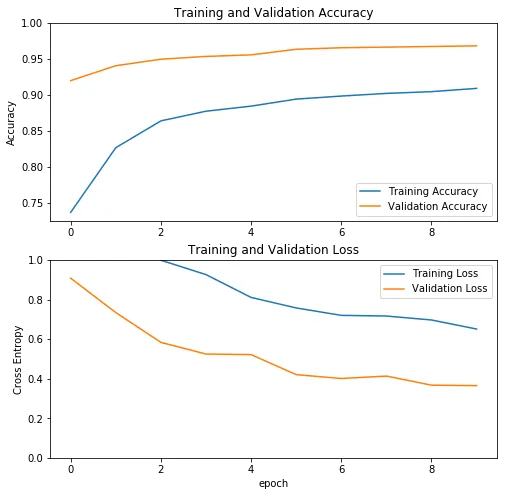
由于我们只训练了顶部的几层网络,而不是整个网络,所以训练这三个模型只用了几个小时
评估
我们看到在训练开始前,我们已经有了50%左右的精确度。让我们来看下训练后是什么情况:
loss1, accuracy1 = vgg16.evaluate(data_loader.test_batches, steps = 20)
loss2, accuracy2 = googlenet.evaluate(data_loader.test_batches, steps = 20)
loss3, accuracy3 = resnet.evaluate(data_loader.test_batches, steps = 20)
print("--------VGG16---------")
print("Loss: {:.2f}".format(loss1))
print("Accuracy: {:.2f}".format(accuracy1))
print("---------------------------")
print("--------GoogLeNet---------")
print("Loss: {:.2f}".format(loss2))
print("Accuracy: {:.2f}".format(accuracy2))
print("---------------------------")
print("--------ResNet---------")
print("Loss: {:.2f}".format(loss3))
print("Accuracy: {:.2f}".format(accuracy3))
print("---------------------------")
结果如下:
——–VGG16———
Loss: 0.25
Accuracy: 0.93
—————————
——–GoogLeNet———
Loss: 0.54
Accuracy: 0.95
—————————
——–ResNet———
Loss: 0.40
Accuracy: 0.97
—————————
我们可以看到这三个模型的结果都相当好,其中ResNet效果最好,精确度高达97%。