摘要:本文整理自阿里云 Flink 存储引擎团队负责人,Apache Flink 引擎架构师 & PMC 梅源在 FFA 核心技术专场的分享。主要介绍在 2022 年度,Flink 容错 2.0 这个项目在社区和阿里云产品的进展,内容包括:
Flink 容错恢复 2.0 项目简介及思考
2022 年度 Flink 容错 2.0 项目进展
Tips:点击「阅读原文」查看原文视频&演讲 ppt
01
Flink 容错恢复 2.0 项目简介及思考
首先来概括的看一下 Flink 容错的链路,主要包括四个过程:做快照(Checkpointing),发现失败节点(Failure Detection),重新调度(Re-Scheduling)和状态恢复(State Recovery)。
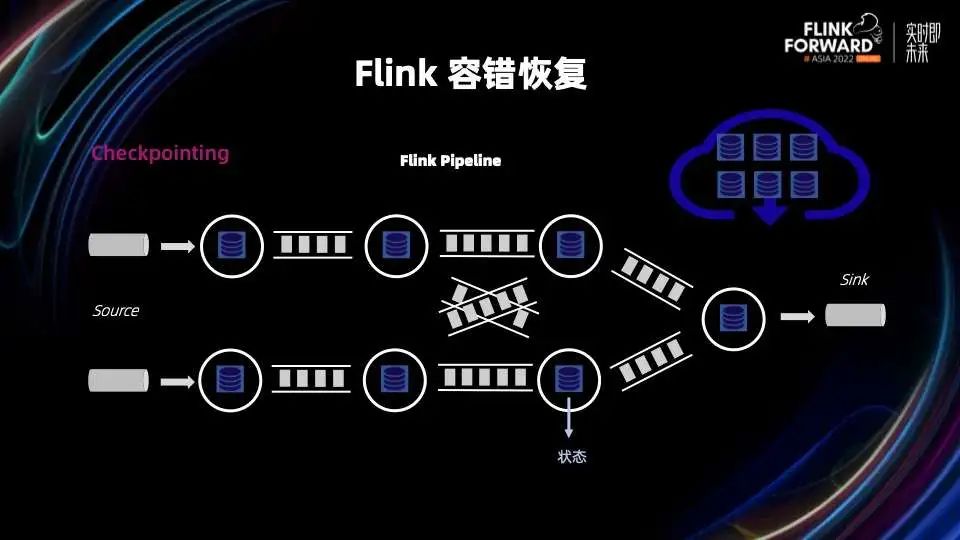
在一个 Flink 作业中,数据从数据源经过各个算子的处理最终写入 Sink。其中有些算子需要记录数据处理的中间结果,会暂时把中间结果缓存在算子内部,即算子的状态中。如果这个 Flink 作业因为各种原因出现失败或者错误,就需要重新恢复这些状态,因此我们需要对状态进行周期性快照,即 Checkpointing 过程。由于快照很频繁,所以需要 Checkpointing 过程稳定、轻量并保证成功。

如果一个节点挂了,需要快速发现失败节点,并完成相应的清理工作。
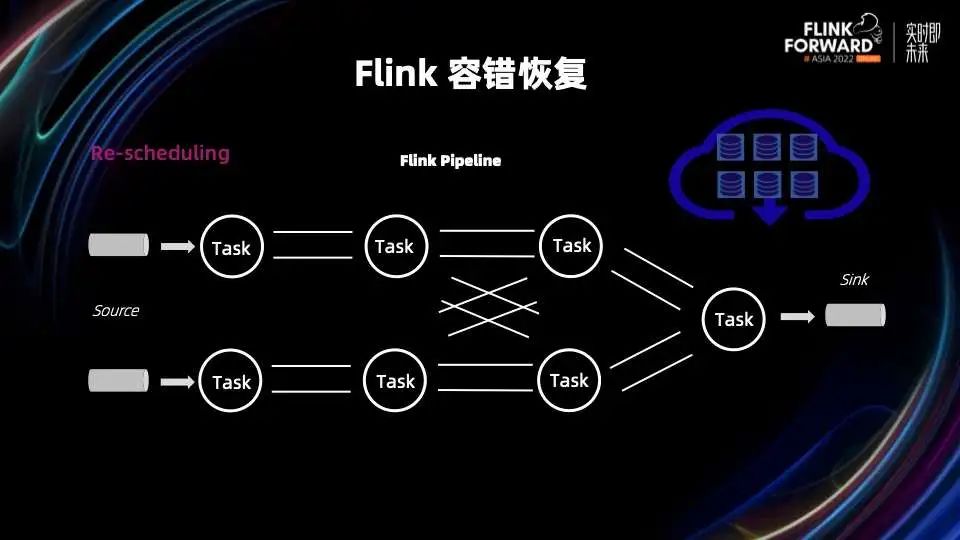
然后生成新的作业,并重新调度,完成部署。
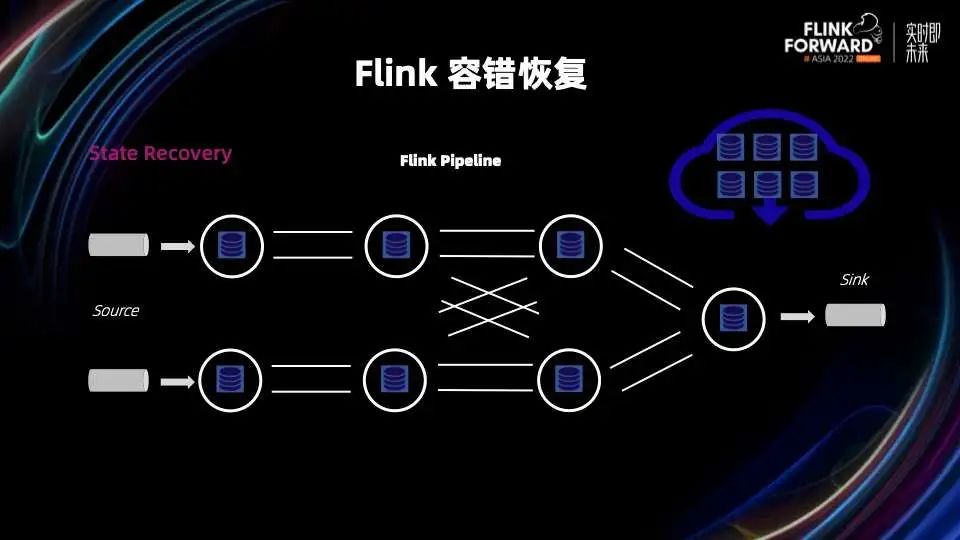
当作业重新调度之后,需要从最新的快照中恢复算子的中间状态,也就是 State Recovery 状态恢复。

从上面的描述不难看出,容错恢复是一个全链路的过程,包括给状态做快照,发现节点失败,重新调度部署以及恢复状态。另一方面容错恢复也是个需要从多个维度来考虑的问题,包括容错成本、对正常处理的影响、数据一致性保证的程度、以及在整个容错恢复过程中的行为表现(比如是否需要满速 TPS 的保证和不断流的保证)等等。另外需要指出的是在云原生背景下,容器化部署带来了一些新的限制和便利,这些都是我们在设计新一代容错时不能忽视的地方。有关这个部分更详细的内容可以参考去年的 talk “Flink 新一代流计算和容错——阶段总结和展望”[1]

2022 年我们的工作主要集中在 Checkpointing,Scheduling 和 State Recovery 这三个部分。在 Checkpointing 这个部分,我们实现了分布式快照架构的升级:
Flink 1.16 修复了和 Unaligned Checkpoint 相关的几个关键 bug,特别是 Unaligned 和 Aligned Checkpoint 之间转换这个部分,使得 Unaligned Checkpoint 可以真正做到生产可用;
Flink 1.16 发布的一个重要 feature 是通用增量 Checkpoints,通过增量快照和 State Store 快照过程的分离,可以保证稳定快速的 Checkpointing 过程。这个后续我们会有相关 Blog Post 详细的分析通用增量 Checkpoints 在各种 Benchmark 下的各项指标以及适用场景。
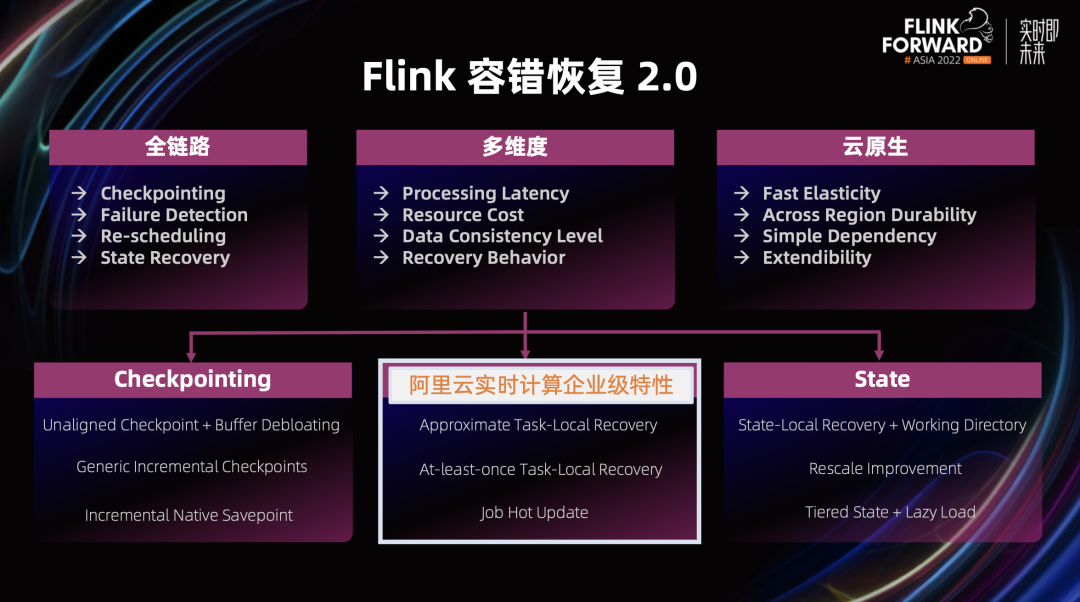
在 Scheduling 这个部分,Approximate 和 At-least-once 单点重启功能已经在阿里云实时计算企业级服务里实现,主要由阿里云实时计算 Flink Runtime 团队完成,他们还通过引入作业热更新功能,极大缩短了扩缩容的断流时间。这两个功能在阿里云实时计算 VVR 6.0.4 版本上线,欢迎大家试用。
在 State Recovery 这个部分,社区在 1.15 引入了工作目录的概念,结合 K8S 的 PV 挂载,可以实现状态的本地恢复。为了适应云原生部署,我们在状态存储部分进行了分层存储架构升级,对恢复和扩缩容都有很大的改进。特别是 Lazy-Load 的引入,使得快速恢复不再受状态大小的影响,结合上面提到的作业热更新功能,基本可以做到扩缩容无断流。Lazy-Load 这个功能也已在阿里云 VVR 6.x 版本中上线。
下面我主要从快照生成,作业恢复/扩缩容,快照管理这三个方面详细介绍 2022 年度 Flink 在容错部分的进展。
02
2022 年度 Flink 容错 2.0 项目进展
2.1 优化快照生成
在快照生成部分,我们对 Flink 分布式快照架构进行了整体升级。
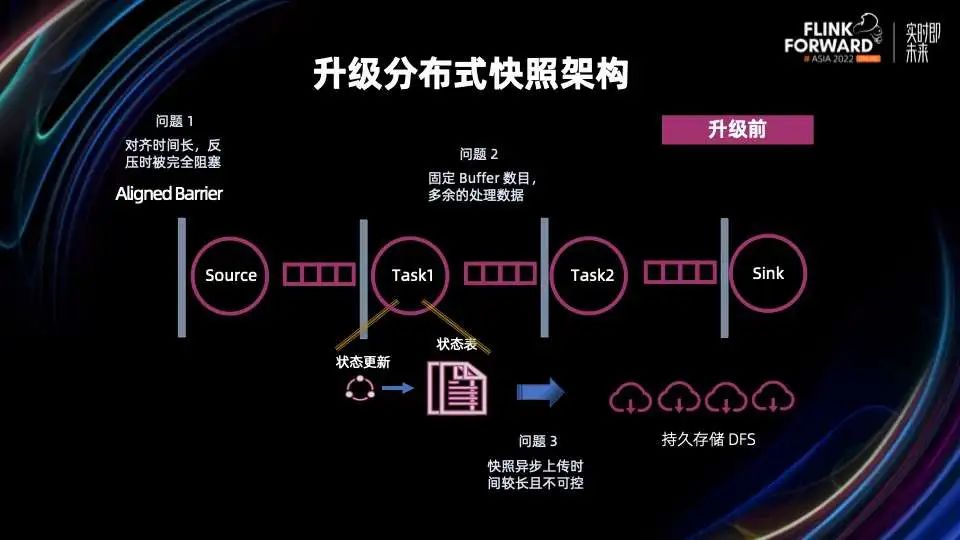
先来看看升级前的架构有什么问题:
问题 1:对齐时间长,反压时被完全阻塞
Flink 的 Checkpoint 机制是通过从 Source 插入 Barrier,然后在 Barrier 流过每个算子的时候给每个算子做快照来完成的。为了保证全局一致性,如果算子有多个输入管道的时候,需要对齐多个输入的 Barrier。这就产生了问题 1,因为每条链路的处理速度不一样,因此 Barrier 对齐是需要时间的。如果某一条链路有反压,会因为等待对齐而使得整条链路完全被阻塞,Checkpoint 也会因为阻塞而无法完成。
问题 2:Buffer 数目固定,管道中有多余的处理数据
由于算子间的上下游 Buffer 数目是固定的,它们会缓存比实际所需更多的数据。这些多余的数据不仅会在反压时进一步阻塞链路,而且会使得 Unaligned Checkpoint 存储更多的上下游管道数据。
问题 3:快照异步上传时间较长且不可控
快照的过程包括两部分:同步状态刷盘和异步上传状态文件,其中异步文件上传的过程和状态文件大小相关,时间较长且不可控。
我们从 Flink 1.11 开始着手逐一的解决这些问题,如下图所示。

Flink 1.11、 Flink 1.12 引入了 Unaligned Checkpoint, 使得 Checkpoint Barrier 不被缓慢的中间数据阻塞。Flink 1.13、Flink 1.14 引入了 Buffer Debloating,让算子与算子间的管道数据变得更少。Flink 1.15、Flink 1.16 引入了通用增量 Checkpoints,让异步上传的过程更快、更稳定。
升级后的分布式快照架构如下图所示:
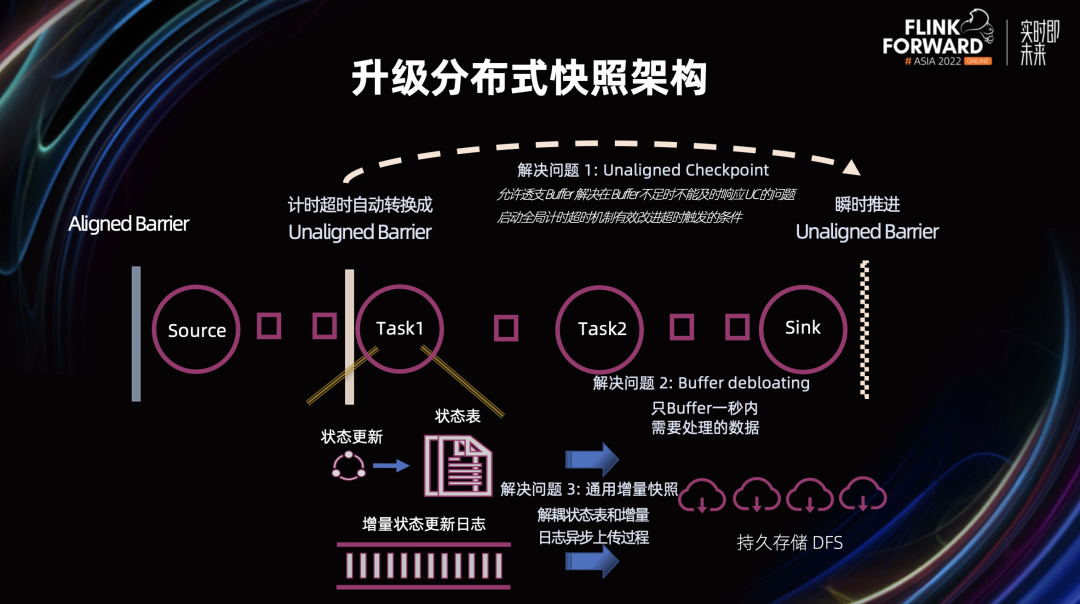
对于问题 1,在 Flink 1.16 版本中,Unaligned Checkpoint 允许透支 Buffer,解决了在 Buffer 不足时,不能及时响应 Unaligned Checkpoint 的问题。此外,全局计时超时机制的引入能够有效改进 Unaligned 和 Aligned Checkpoint 之间自动转换的触发条件。
对于问题 2,Buffer debloating 的引入可以动态调整缓存的数据量,动态缓存 1 秒内需要处理的数据。
下面我们来重点看一看第 3 个问题是如何用通用增量 Checkpoint 来解决的
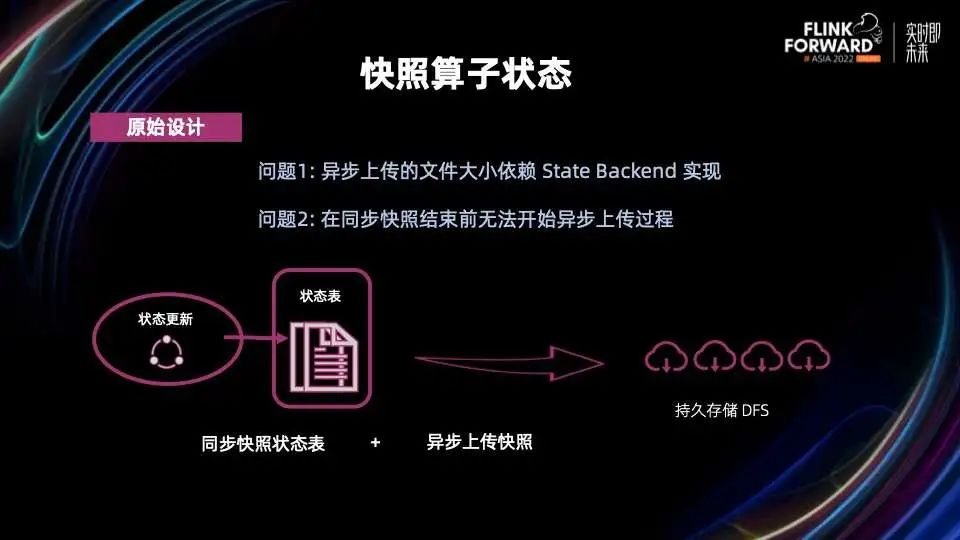
Flink 的算子状态更新会反映在状态表中。在之前的设计当中,Flink 算子做快照的过程分为两步:第一步是同步的对状态表进行快照,内存中的数据刷盘,准备好上传到持久存储的文件;第二步是异步的上传这些文件。
异步上传文件这个部分有两个问题:
问题 1:异步上传的文件大小依赖 State Backend 的实现
问题 2:异步过程需要等到同步过程结束才能开始,因为同步快照结束前是没法准备好需要上传的文件的
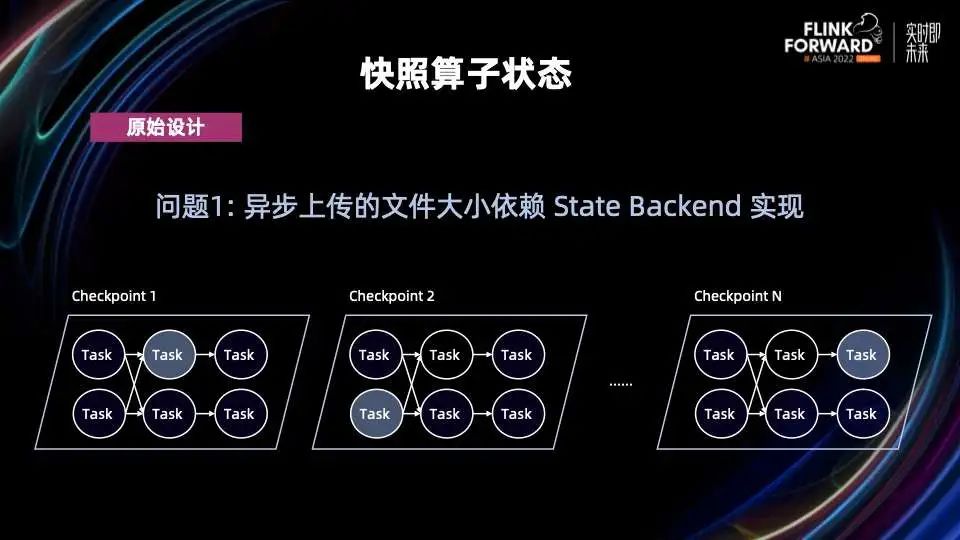
我们来分别看一下这两个问题。对于第一个问题,以 RocksDB 为例,虽然 Flink 对 RocksDB 也支持增量 Checpoint,但是 RocksDB 出于自身实现考虑,它需要对文件做 Compaction。每次 Compaction 会产生新的比较大的文件,那这个时候即使是增量 Checkpoint,需要上传的文件也会因此时不时变大。在 Flink 作业并发比较大的情况下,上传文件时不时变大的问题就会变得很频繁,因为只有等所有并发的文件上传完毕,一个完整的算子状态才算快照完成。

对于第二个问题,在同步快照结束前,Flink 无法准备好需要上传的文件,所以必须要等快照结束时才能开始上传。也就是说,上图中的红色斜条纹这个时间段完全被浪费了。如果需要上传的状态比较大,会在很短时间内对 CPU 和网络产生较大的压力。
为了解决上述两个问题,我们在 Flink 社区实现了通用增量快照。在新架构下,状态更新不仅会更新状态表,而且会记录状态的更新日志。上图中状态表会和架构升级前一样周期性的刷到持久存储,但是这个周期可以比较大(比如 10 分钟)在后台慢慢上传,该过程称为物化过程。同时状态更新日志也会持续上传到远端持久存储,并且在做 Checkpoint 时 Flush 剩余全部日志。

这样的设计就比较好的解决了前面提到的两个问题:通过将快照过程和物化过程完全独立开来,可以让异步上传的文件大小变得很稳定;同时因为状态更新是持续的,所以我们可以在快照之前就一直持续的上传更新日志,所以在 Flush 以后我们实际需要上传的数据量就变得很小。
架构升级后的一个 Checkpoint 由物化的状态表以及增量更新的日志组成。物化过程结束后,相对应的更新日志就可以被删除了。上图中的蓝色方框部分,是通用增量快照和之前架构的区别,这个部分被称为 Changelog Storage(DSTL)。

DSTL 是 Durable Short-term Log 的缩写。我们从这个英文名就能看出来 DSTL 是有针对性需求的
需要短期持久化增量日志,物化后即可删除
需要支持高频写,是一个纯 append 写操作,仅在恢复时需要读取
需要 99.9% 的写请求在1秒内完成
需要和现有的 Checkpoint 机制提供同一级别的一致性保证
社区现在的版本是用 DFS 来实现的,综合考量下来基本可以满足需求。同时 DSTL 提供了标准的接口也可以对接其他的存储。在本次 Flink Forward 美团的分享中,可以看到美团在使用 Bookkeeper 实现 DSTL 以及通用增量快照方面取得的性能的提升。

这个部分的最后我们来看一下使用通用增量快照的 Trade-off
通用增量快照带来的好处显而易见:
可以让 Checkpoint 做的更稳定,平滑 CPU 曲线,平稳网络流量使用(因为快照上传的时间被拉长了,并且单次上传量更小更可控)
可以更快速的完成 Checkpoint(因为减少了做快照 Flush 的那个部分需要上传的数据)
也因此,我们也可以获得更小的端到端的数据延迟,减小 Transactional Sink 的延迟
因为可以把 Checkpoint 做快,所以每次 Checkpoint 恢复时需要回滚的数据量也会变少。这对于对数据回滚量有要求的应用是非常关键的
通用增量快照也会带来一些额外的 Cost,主要来自两个方面:Checkpoint 放大和状态双写:
Checkpoint 放大的影响主要有两点。第一,远端的存储空间变大。但远端存储空间很便宜,10G 一个月大约 1 块钱。第二,会有额外的网络流量。但一般做 Checkpoint 使用的流量也是内网流量,费用几乎可以忽略不计。
对于状态双写,双写会对极限性能有一些影响,但在我们的实验中发现在网络不是瓶颈的情况下,极限性能的损失在 2-3% 左右(Flink 1.17 中优化了双写部分 FLINK-30345 [2] ,也会 backport 到 Flink 1.16),因此性能损失几乎可以忽略不计。
对于通用增量 Checkpoint 这个部分我们近期会有更详尽的测试分析报告,敬请期待。
2.2 优化作业恢复和扩缩容
接下来讲一讲 Flink 社区在作业恢复和扩缩容部分的优化,主要包括优化本地状态重建,云原生背景下的分层状态存储架构升级,以及简化调度过程。

作业扩缩容和作业容错恢复有很多共性,比如都需要依据上一次快照来做恢复,都需要重新调度,但他们在细微之处又是有些区别的。
■ 本地状态重建
以状态恢复本地重建来讲,对于容错恢复,将状态文件原样加载进本地数据库就可以了,但是如果是扩缩容恢复就会更复杂一些。举例来说上图中的作业并发从 3 扩容到 4,新作业 task 2 的状态有一部分来自原先作业的 task 1,还有一部分来自原先作业的 task 2,分别是橙色和黄色部分。
Flink 作业算子的状态在 Rescaling 做状态重新分配时,新分配的状态来自原先作业相邻的并发,不可能出现跳跃的有间隔的状态分配。在缩容时,有可能有多个状态合成一个新状态;在扩容的时候,因为状态一定是变小的,所以新的变小的状态一定最多来自相邻的两个原先的并发。

接下来具体讲一讲状态是如何做本地重建的,以 RocksDB 为例。
第一步,需要下载相关的状态文件。
第二步,重建初始的 RocksDB 实例,并删除对实例无用的 Key,即删除上图中灰色的部分,留下橙色部分。
第三步,将临时 RocksDB 实例中的 Key 插入到第二步重建的 RocksDB 中,也就是黄色的部分插入到橙色的 DB 中。

我们在 Flink 1.16 中,对本地重建的第二步进行了优化。通过引入 DeleteRange,使得整个删除无用 Key 的操作变成 O(1),并且因为最多只可能有 2 个 Range 需要删除,因此额外的数据结构(TombStone 表)对正常读写的影响微乎其微。
从上图右边的实验结果可以看出,对于状态大小 122GB 的 Word Count 作业,从并发 3 扩容到并发 4,Flink 1.16 比之前的版本扩容速度提升 2 – 10 倍。同时我们在 Flink 1.16 引入了标准的 Rescaling Micro Benchmark,在此之前社区没有一个标准来测试 Rescaling 的性能。
在阿里云实时计算企业版中,我们对本地状态重建的第一步和第三步也进行了优化。我们只需要下载需要的状态文件,并且可以进行文件粒度的直接合并,避免创建临时 DB 实例。阿里云实时计算版本和 Flink 1.16 社区版本对比,缩容速度也有 7 倍的提升。
■ 分层状态存储架构
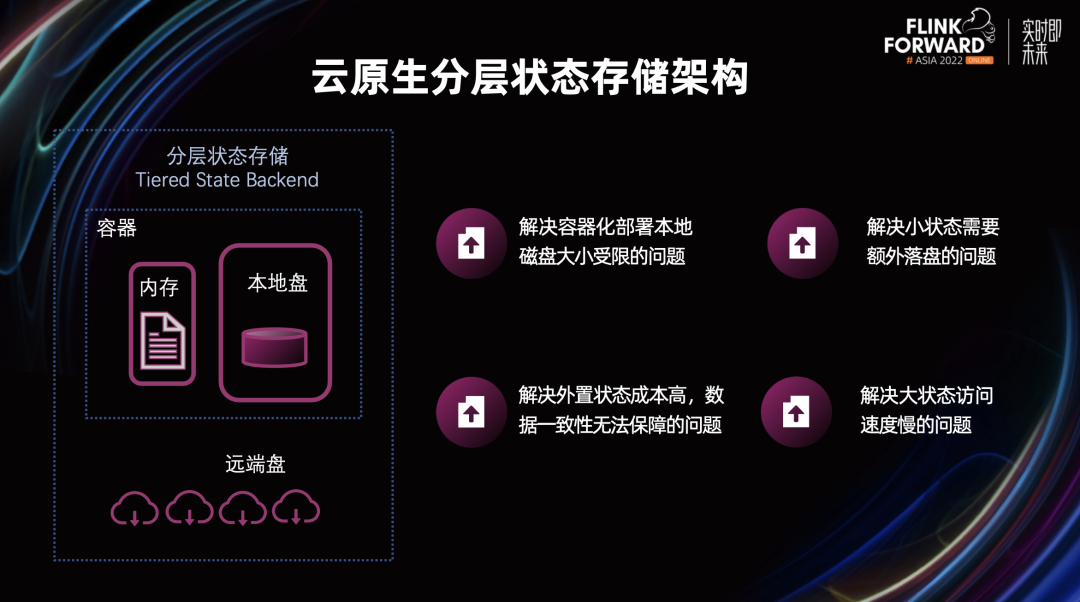
为了更好的适应云原生的大背景,我们对分层状态存储架构也进行了初步探索,也就是说我们把远端盘也作为 State Backend 的一部分。这种分层架构可以解决 Flink 状态存储在云原生背景下面临的大部分问题:
解决容器化部署本地磁盘大小受限的问题
解决外置状态成本高,数据一致性难以保障的问题
解决小状态需要额外落盘的问题
解决大状态访问速度慢的问题
这些问题和容错没有太大关系,以后有机会专门讲一讲这个部分。
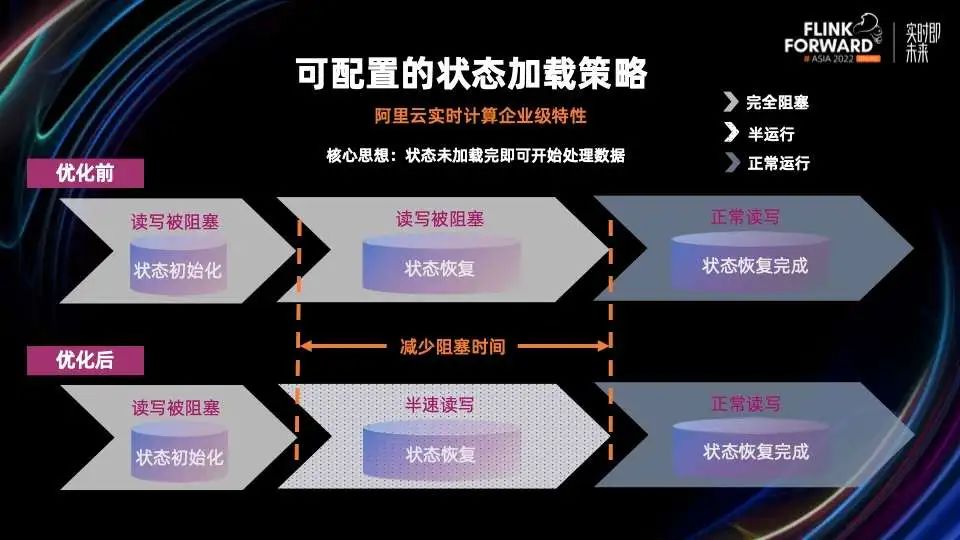
远端盘作为 State Backend 的一部分,状态加载策略可以变得更灵活。这样状态在没有完全加载恢复完成之前,就可以开始数据处理。在优化前,用户状态恢复时,读写被完全阻塞。在优化后,用户状态恢复的过程中,可以进行半速读写,然后逐渐恢复到全速,如上图所示。
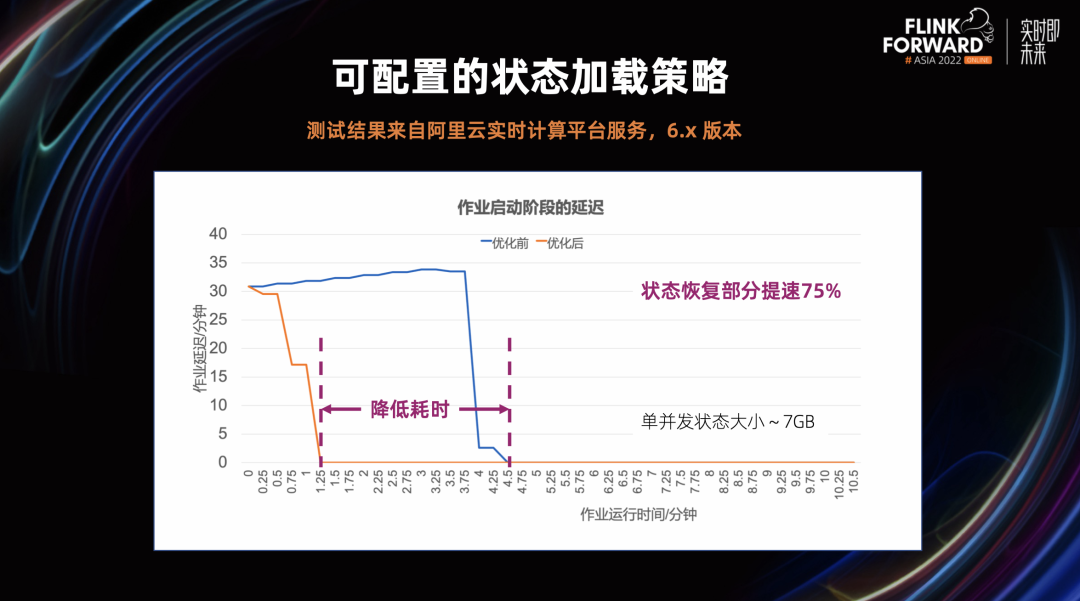
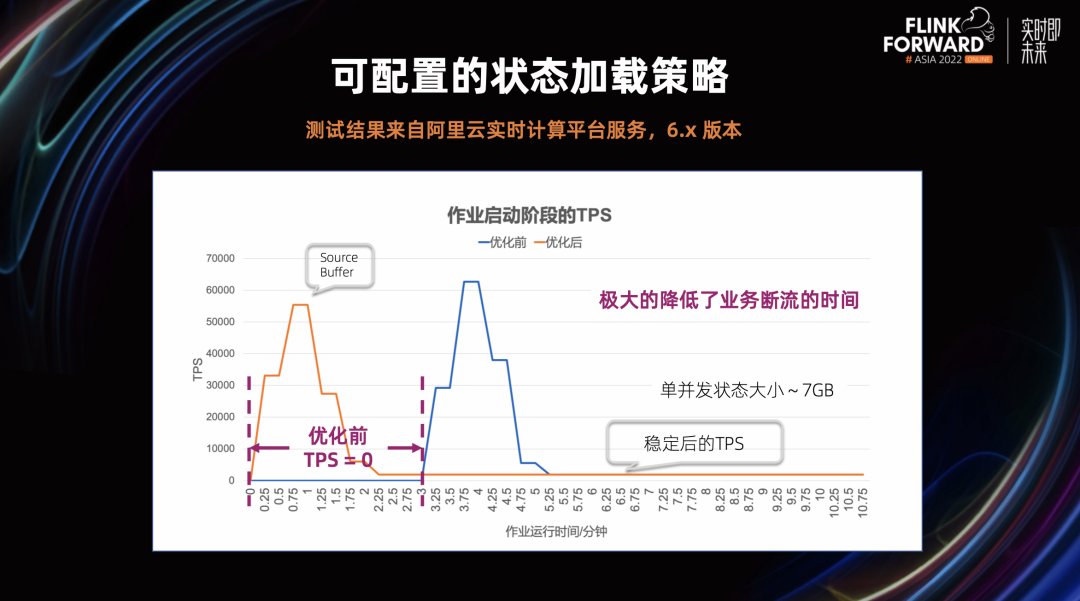
可配置的状态加载策略的引入,极大的缩短了状态恢复的初始延迟和业务断流时间。我们从下面两个实验可以看到,单并发状态大小 7GB 左右的作业启动后延迟时间在优化后从 4.5 分钟降到了 1.25 分钟,状态恢复部分提速 75%。同样的作业,在优化后可以发现从状态恢复开始时,就会有 TPS,极大的降低了业务断流的时间。
在作业调度这个部分,阿里云 Flink Runtime 团队在阿里云实时计算 VVR 6.0.4 版本中引入了作业热更新这个功能,其核心思想是在扩缩容的时候简化作业重新调度的步骤,并且在新的作业生成后再停掉老的作业,这样可以进一步缩短作业断流的时间。在没有资源预申请的情况下,作业热更新可以使无状态作业扩容和缩容时间降低三倍左右。

综上所述,通过延迟状态加载策略,配合作业热更新,基本可以保证在状态恢复和调度层面,做到扩缩容无断流或极短时间断流。
2.3 优化快照管理
前两个部分都是讲性能上的优化,最后一个部分我想聊一聊快照管理部分的一些梳理。Flink 发展到现今已经是一个很成熟的系统了,清晰化的概念以及简单易用性是衡量一个系统成熟度的很重要的部分,所以这里聊一聊快照概念和管理。
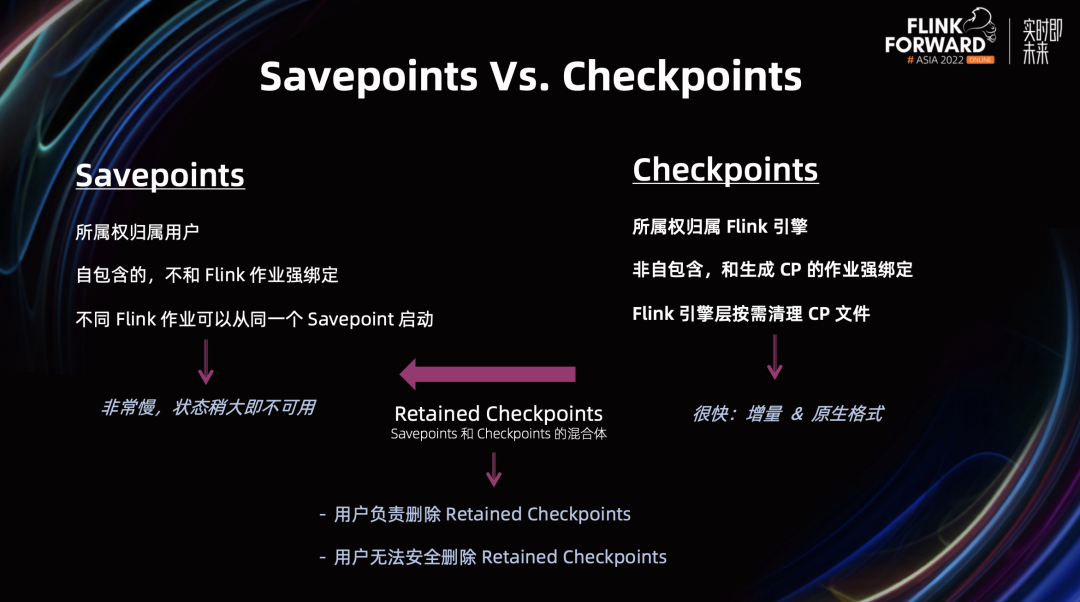
Flink 的快照 Snapshot 分为两种:Savepoint 和 Checkpoint。
Savepoint 一般由用户触发,所以它归属用户所有,因此由用户负责创建和删除。正因此,Flink 系统引擎层是不能够去删除 Savepoint 相关文件的。所以 Savepoint 不和 Flink 作业强绑定,不同的 Flink 作业可以从同一个 Savepoint 启动。Savepoint 是自包含的:自己包含所需要的一切。
Checkpoint 正好相反,它的主要作用是系统容错自愈,所以它由 Flink 引擎周期性触发,并且所属权归属 Flink 引擎。Checkpoint 文件的组织结构都由 Flink 引擎决定和管理,所以引擎负责按需清理 Checkpoint 文件。正因此,Checkpoint 和生成该 Checkpoint 的作业强绑定,并且是非自包含的,比如说 Incremental Checkpoint 之间会有依赖关系。
那有什么问题呢?因为 Savepoint 主要目标服务对象是用户,为了对用户友好,Savepoint 使用用户可读的标准格式,也正因此 Savepoints 做得非常慢,经常情况下状态稍微大一点就会超时,同样恢复也很慢。另一方面,Checkpoint 使用的是增量系统原生格式,所以做得很快。
这种情况下,用户会把 Retained Checkpoint 当成 Savepoint 来使用。Retained Checkpoint 是在作业停掉后保留的 Checkpoint,这样Retained Checkpoint 就变成了 Savepoint 和 Checkpoint 的混合体。造成的问题是用户负责删除 Retained Checkpoint,但是用户并不知道如何安全的删除 Retained Checkpoint。
为了解决上述问题,Flink 1.15 引入了两种状态恢复模式,即 Claim 模式和 No-Claim 模式。
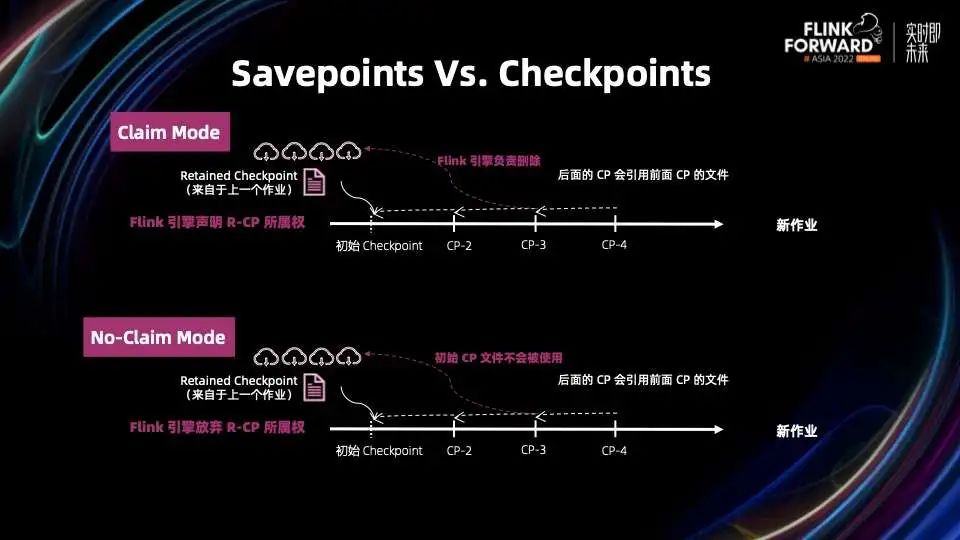
在 Claim 恢复模式下,引擎声明 Retained Checkpoint 的所属权,Retained Checkpoint 归引擎所有,引擎负责删除。
在 No-Claim 恢复模式下,引擎放弃 Retained Checkpoint 的所属权。Retained Checkpoint 中所有的文件都不会被 Flink 引擎使用,用户可以很安全的删除 Retained Checkpoint。
在 No-Claim 的基础上,我们引入了 Native Savepoint,来加速 Savepoint 的创建和恢复。Native Savepoints 使用和 Checkpoint 一样的存储格式,其实现原理和 No-Claim 类似。Savepoint 不会使用之前的 Checkpoint 文件,相当于做一个全量的 Checkpoint。我们的企业版本通过进一步优化,让 Native Savepoint 也真正能做到增量 Savepoint。

上图是 Flink 社区引入 Native Savepoint 之前,之后以及企业版进一步优化后的 Savepoint 性能对比图。我们可以看到在引入 Native Savepoint 之前,Savepoint 做的很慢。在 Savepoint 总大小 5GB 的情况下(状态中等大小),做一次 Savepoint 超过 10 分钟(超时)。这意味着一旦用户使用 stop-with-savepoint 来停止作业(也就是在停止作业前做个 Savepoint),就得等超过 10 分钟,完全没法用。在引入 Native Savepoint 之后,需要等 2 分半钟,也比较长,勉强能用。企业版进一步优化后,等待时间变成 5s 钟,这个基本上在可等待的范围之内了。

最后我们小结回顾一下 Flink 容错恢复在 2022 年的主要进展
在分布式快照架构方面,Unaligned Checkpoint 引入全局计时器,可以通过超时机制自动从 Aligned Checkpoint 切换成 Unaligned Checkpoint,这个对于 Unaligned Checkpoint 生产可用是非常重要的一步
通用增量 Checkpoint 生产可用,这对于 Checkpoint 稳定性和完成速度有很大的提升,同时可以平滑 CPU 和网络带宽的使用
这里值得一提的是,不仅仅是阿里巴巴在 Checkpoint 这个部分贡献了大量的代码,很多其他的公司也积极的投入到社区当中,比如 Shopee 和美团。他们在社区中贡献代码同时,也积极推动这些功能在公司内部的落地和延展,取得了不错的效果
在状态存储方面,我们进行了分层状态存储的初步探索,扩缩容速度有 2 – 10 倍的提升
阿里云实时计算平台推出了扩缩容无断流的组合功能:延迟状态加载和作业热更新,分别从状态加载和作业调度这两个方面来实现扩缩容无断流
引入增量 Native Savepoint,全面提升 Savepoint 的可用性和性能
参考链接
[1] Flink 新一代流计算和容错——阶段总结和展望
[2] https://issues.apache.org/jira/browse/FLINK-30345
往期精选





▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT