任务描述
知识点:
- 使用MapReduce提取数据
重 点:
- 开发MapReduce程序
- 统计每年每个月的最低气温
- 统计每年每个月的最高气温
内 容:
- 使用IDEA创建一个MapReduce项目
- 开发MapReduce程序
- 使用MapReduce统计每年每个月的最低气温
- 使用MapReduce统计每年每个月的最高气温
任务指导
1. 使用MapReduce提取最低气温
- 使用IDEA创建Maven项目:TemperatureDemo
- 在Settings中配置Maven
- 配置pom.xml文件
- 开发MapReduce程序
- com.MinTemperatureMapper:提取日期和气温数据
- com.MinTemperatureReducer:提取其中的最低温度,由于气温数据的膨胀因子为10,也就是说是原始数据的10倍,因此需要将获取的气温数据除以10
- com.MinTemperature:MapReduce程序主入口
- 程序编写完成,右键MinTemperature,点击Run 'MinTemperature.main()'运行MapReduce程序
- 程序运行完成,进入master机器,查看运行结果

2. 使用MapReduce提取最高气温
- 开发MapReduce程序
- com.MaxTemperatureMapper:提取日期和气温数据
- com.MaxTemperatureReducer:提取其中的最高温度,由于气温数据的膨胀因子为10,也就是说是原始数据的10倍,因此需要将获取的气温数据除以10
- com.MaxTemperature:MapReduce程序主入口
- 程序编写完成,右键MaxTemperature,点击Run 'MaxTemperature.main()'运行MapReduce程序
- 程序运行完成,进入master机器,查看运行结果

任务实现
1. 使用MapReduce提取最低气温
- 使用IDEA创建Maven项目:TemperatureDemo
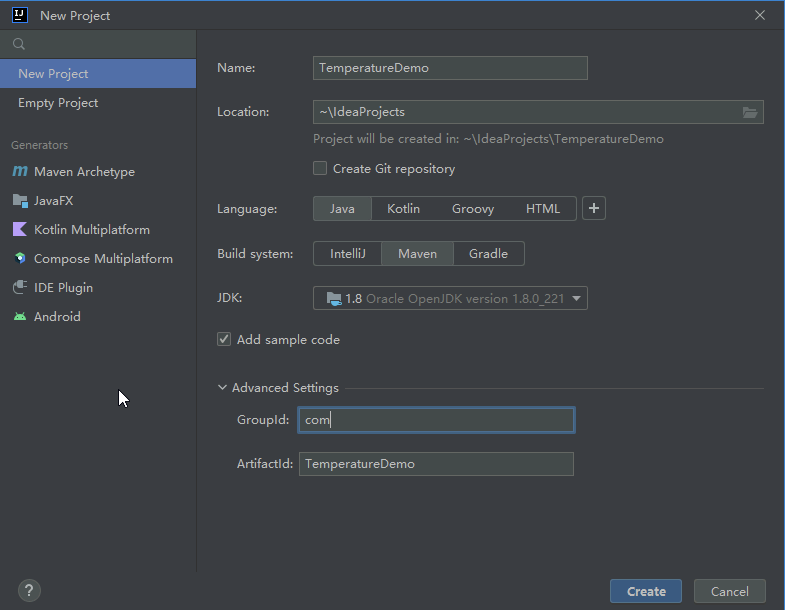
- 在Settings中配置Maven
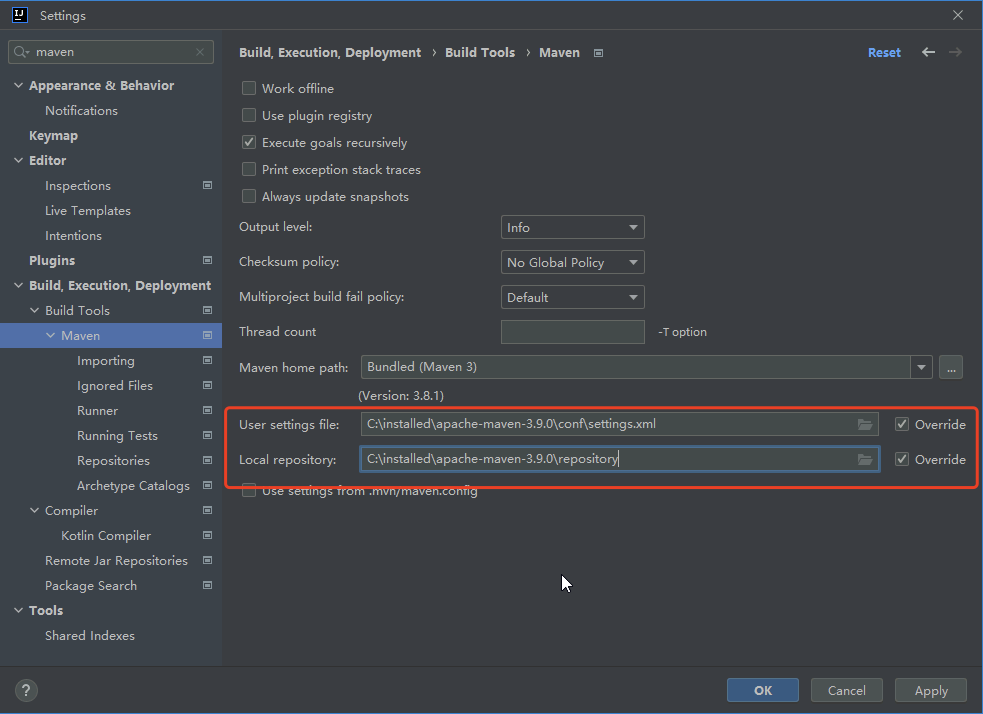
- 配置pom.xml文件,内容如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies>程序是一个典型的MapReudce程序结构,主要包括三个类,分别为:MinTemperatureMapper.java(Map程序)、MinTemperatureReducer.java(Reduce程序)、MinTemperature.java(Driver驱动类)。
程序的作用是将前面ETL后的天气数据进行提取数据操作,抽取出22年内的每个月的最低温度,并保存到HDFS。
- Map端:提取日期和气温数据
- 在项目的src/main/java/com包中创建一个类MinTemperatureMapper.java,内容如下:
package com;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MinTemperatureMapper extends Mapper<LongWritable, Text,Text, FloatWritable> {
private static final int MISSING = -9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
if (!"".equals(line)) {
String[] values = line.split(",");
// 获取年份
String year = values[1];
// 获取月份
String month = values[2];
// 拼接年份和月份,作为输出key
String textKey = year + "-" + month;
// 获取气温数据
float temp = Float.parseFloat(values[5]);
if (temp != MISSING) {
System.out.println(textKey+":"+temp);
context.write(new Text(textKey), new FloatWritable(temp));
}
}
}
}- Reduce端:Reduce获取到Map端的输出,例如:<2000-01,list[-121,-32,-53,51........]>,将同一个月份的气温数据整合到一个list列表中,提取其中的最低温度,由于气温数据的膨胀因子为10,也就是说是原始数据的10倍,因此需要将获取的气温数据除以10。
- 在项目的src/main/java/com包中创建一个类MinTemperatureReducer.java,内容如下:
package com;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MinTemperatureReducer extends Reducer<Text, FloatWritable,Text,FloatWritable> {
@Override
protected void reduce(Text key, Iterable<FloatWritable> values, Context context) throws IOException, InterruptedException {
float minValue = Float.MAX_VALUE;
for (FloatWritable value : values) {
// 获取最低温度
minValue = Math.min(minValue, value.get());
}
// 气温数据的膨胀因子为10,需要将获取的气温数据除以10
float air = minValue/10;
context.write(key,new FloatWritable(air));
}
}- Driver端:MapReduce程序的驱动类
- 在项目的src/main/java/com包中创建一个类MinTemperature.java,内容如下:
package com;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MinTemperature {
public static void main(String[] args) {
Configuration conf = new Configuration();
Job job = null;
try {
job = Job.getInstance(conf);
job.setJarByClass(MinTemperature.class);
job.setJobName("Min temperature");
job.setMapperClass(MinTemperatureMapper.class);
job.setReducerClass(MinTemperatureReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
FileInputFormat.addInputPath(job,new Path("hdfs://master:9000/china_all/"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://master:9000/output/mintemp/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
// job.submit();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- 程序编写完成,右键MinTemperature,点击Run 'MinTemperature.main()'运行MapReduce程序
- 控制台输出:
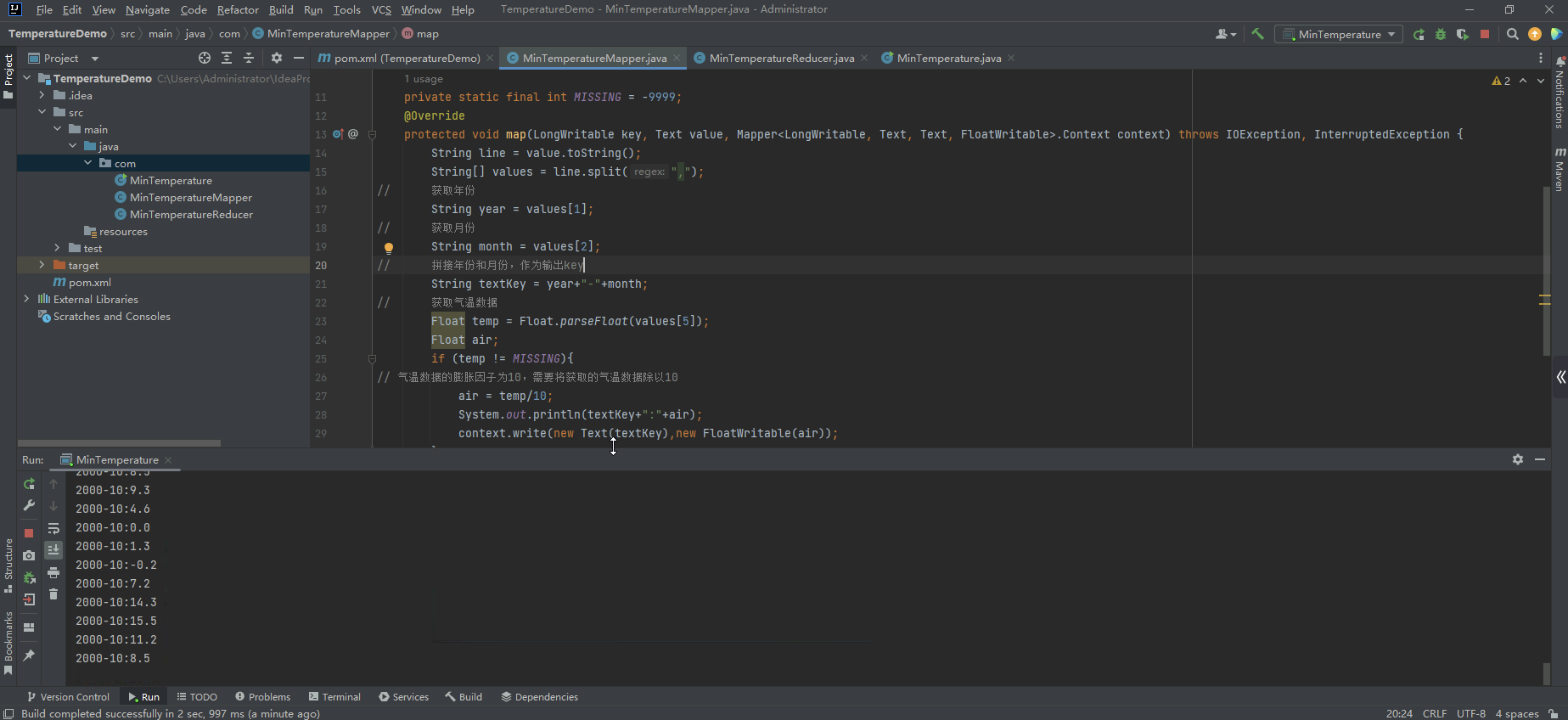
- 程序运行完成,进入master机器,查看运行结果
# hadoop fs -ls /output/mintemp
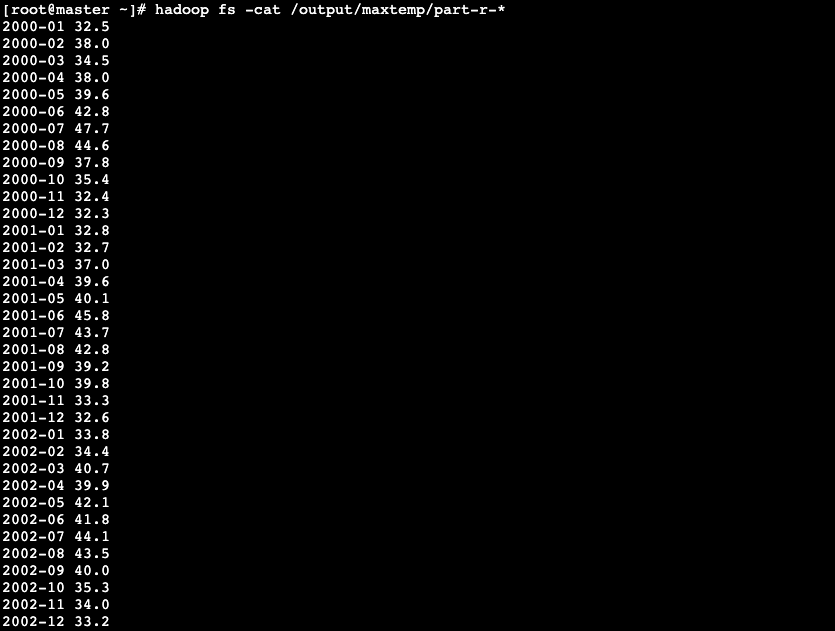
# hadoop fs -cat /output/mintemp/part-r-*
2. 使用MapReduce提取最高气温
程序同样是一个典型的MapReudce程序结构,主要包括三个类,分别为:MaxTemperatureMapper.java(Map程序)、MaxTemperatureReducer.java(Reduce程序)、MaxTemperature.java(Driver驱动类)。
程序的作用是将前面ETL后的天气数据进行提取数据操作,抽取出22年内的每个月的最高温度,并保存到HDFS。
- Map端:提取日期和气温数据
- 在TemperatureDemo项目的src/main/java/com包中创建一个类MaxTemperatureMapper.java,内容如下:
package com;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MaxTemperatureMapper extends Mapper<LongWritable, Text,Text, FloatWritable> {
private static final int MISSING = -9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
if (!"".equals(line)) {
String[] values = line.split(",");
// 获取年份
String year = values[1];
// 获取月份
String month = values[2];
// 拼接年份和月份,作为输出key
String textKey = year + "-" + month;
// 获取气温数据
float temp = Float.parseFloat(values[5]);
if (temp != MISSING) {
System.out.println(textKey+":"+temp);
context.write(new Text(textKey), new FloatWritable(temp));
}
}
}
}- Reduce端:Reduce获取到Map端的输出,例如:<2000-01,list[-121,-32,-53,51........]>,将同一个月份的气温数据整合到一个list列表中,提取其中的最高温度,由于气温数据的膨胀因子为10,也就是说是原始数据的10倍,因此需要将获取的气温数据除以10。
- 在项目的src/main/java/com包中创建一个类MaxTemperatureReducer.java,内容如下:
package com;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MaxTemperatureReducer extends Reducer<Text, FloatWritable,Text,FloatWritable> {
@Override
protected void reduce(Text key, Iterable<FloatWritable> values, Context context) throws IOException, InterruptedException {
float maxValue = Float.MIN_VALUE;
for (FloatWritable value : values) {
// 获取最高温度
maxValue = Math.max(maxValue, value.get());
}
// 气温数据的膨胀因子为10,需要将获取的气温数据除以10
float air = maxValue/10;
context.write(key,new FloatWritable(air));
}
}- Driver端:MapReduce程序的驱动类
- 在项目的src/main/java/com包中创建一个类MaxTemperature.java,内容如下:
package com;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MaxTemperature {
public static void main(String[] args) {
Configuration conf = new Configuration();
Job job = null;
try {
job = Job.getInstance(conf);
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
FileInputFormat.addInputPath(job,new Path("hdfs://master:9000/china_all/"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://master:9000/output/maxtemp/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
// job.submit();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}- 程序编写完成,右键MaxTemperature,点击Run 'MaxTemperature.main()'运行MapReduce程序
- 程序运行完成,进入master机器,查看运行结果
# hadoop fs -ls /output/maxtemp
# hadoop fs -cat /output/maxtemp/part-r-*