文中程序以Tensorflow-2.6.0为例
部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。
截图和程序部分引用自北京大学机器学习公开课
认识网络的构建结构
在神经网络的构建过程中,都避不开以下几个步骤:
- 导入网络和依赖模块
- 原始数据处理和清洗
- 加载训练和测试数据
- 构建网络结构,确定网络优化方法
- 将数据送入网络进行训练,同时判断预测效果
- 保存模型
- 部署算法,使用新的数据进行预测推理
使用Keras快速构建网络的必要API
在tensorflow2版本中将很多基础函数进行了二次封装,进一步急速了算法初期的构建实现。通过keras提供的很多高级API可以在较短的代码体量上实现网络功能。同时通过搭配tf中的基础功能函数可以实现各种不同类型的卷积和组合操作。正是这中高级API和底层元素及的操作大幅度的提升了tensorflow的自由程度和易用性。
常用网络
全连接层
tf.keras.layers.Dense(units=3, activation=tf.keras.activations.softmax, kernel_regularizer=tf.keras.regularizers.L2())
units:维数(神经元个数)
activation:激活函数,可选:relu softmax sigmoid tanh,这里记不住的话可以用tf.keras.activations.逐个查看
kernel_regularizer:正则化函数,同样的可以使用tf.keras.regularizers.逐个查看
全连接层是标准的神经元组成,更多被用在网络的后端或解码端(Decoder)用来输出预测数据。
拉伸层(维度展平)
tf.keras.layers.Flatten()
这个函数默认不需要输入参数,直接使用,它会将多维的数据按照每一行依次排开首尾连接变成一个一维的张量。通常在数据输入到全连接层之前使用。
卷积层
tf.keras.layers.Conv2D(filters=3, kernel_size=3, strides=1, padding='valid')
filters:卷积核个数
kernel_size:卷积核尺寸
strides:卷积核步长,卷积核是在原始数据上滑动遍历完成数据计算。
padding:可填 ‘valid’ ‘same’,是否使用全零填充,影响最后卷积结果的大小。
卷积一般被用来提取数据的数据特征。卷积最关键的就是卷积核个数和卷积核尺寸。假设输入一个1nn大小的张量,经过x个卷积核+步长为2+尺寸可以整除n的卷积层之后会输出一个x*(n/2)*(n/2)大小的张量。可以理解为卷积步长和卷积核大小影响输出张量的长宽,卷积核的大小影响输出张量的深度。
构建网络
使用Sequential构建简单网络,或者构建网络模块。列表中顺序包含网络的各个层。
tf.keras.models.Sequential([ ])
使用独立的class构建,这里定义一个类继承自 tensorflow.keras.Model 后面基本是标准结构>初始化相关参数>定义网络层>重写call函数定义前向传播层的连接顺序。后续随着使用的深入可以进一步的添加更多函数来实现不同类型的网络。
class mynnModel(Model): # 继承from tensorflow.keras import Model 作为父类
def __init__(self):
super(IrisModel, self).__init__() # 初始化父类的参数
self.d1 = layers.Dense(units=3, activation=tf.keras.activations.softmax, kernel_regularizer=tf.keras.regularizers.L2())
def call(self, input): # 重写前向传播函数
y = self.d1(input)
return y
model = IrisModel()
训练及其参数设置
设置训练参数
tensorflow.keras.Model.compile(optimizer=参数更新优化器,
loss=损失函数
metrics=准确率计算方式,即输出数据类型和标签数据类型如何对应)
具体参数可以看下面的内容:
optimizer:参数优化器
SGD: tf.keras.optimizers.SGD(learning_rate=0.1,momentum=动量参数) learning_rate学习率,momentum动量参数
AdaGrad: tf.keras.optimizers.Adagrad(learning_rate=学习率)
Adam: tf.keras.optimizers.Adam(learning_rate=学习率 , beta_1=0.9, beta_2=0.999)
loss:损失函数
MSE: tf.keras.losses.MeanSquaredError()
交叉熵损失: tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False) from_logits=true时输出值经过一次softmax概率归一化
metrics:准确率计算方式,就是输出数据类型和标签数据类型如何对应
数值型(两个都是序列值): 'accuracy'
都是独热码: 'categorical_accuracy'
标签是数值,输出是独热码: 'sparse_categorical_accuracy'
训练
tensorflow.keras.Model.model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
网络传入参数含义如下:
输入的数据依次为:输入训练特征数据,标签数据,单次输入数据量,迭代次数
validation_split=从训练集划分多少比例数据用来测试 / validation_data=(测试特征数据,测试标签数据) 这两个参数智能二选一
validation_freq=多少次epoch测试一次
输出网络信息
tensorflow.keras.Model.model.summary()
上面这个函数可以在训练结束或者训练开始之前输出一次网络的结构信息用于确认。
实际应用展示
环境
软件环境的配置可以查看环境配置流程说明
cuda = 11.8 # CUDA也可以使用11.2版本
python=3.7
numpy==1.19.5
matplotlib== 3.5.3
notebook==6.4.12
scikit-learn==1.2.0
tensorflow==2.6.0
keras==2.6.0
使用iris数据集构建基础的分类网络
import tensorflow as tf
from sklearn import datasets
import numpy as np
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
model = tf.keras.models.Sequential([ tf.keras.layers.Dense(3, activation='softmax',
kernel_regularizer=tf.keras.regularizers.l2())])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
model.summary( )
通过上面这样几行简单的代码,我们实现了对iris数据的分类训练。在上面的代码中使用了Sequential函数来构建网络。
使用MNIST数据集设计分类网络
在开始下面的代码之前,要先下载对应的数据 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 复制这段网址在浏览器打开会直接下载数据,然后将下载好的mnist.npz复制到一个新的路径下,然后在tf.keras.datasets.mnist.load_data(path=‘you file path ’)代码中的这行里修改为你的路径,注意要使用绝对路径。
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras import layers
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data(path='E:\Tensorflow\data\mnist.npz') # 注意替换自己的使用绝对路径
x_train, x_test = x_train/255.0, x_test/255.0 # 图像数据归一化
print('训练集样本的大小:', x_train.shape)
print('训练集标签的大小:', y_train.shape)
print('测试集样本的大小:', x_test.shape)
print('测试集标签的大小:', y_test.shape)
#可视化样本,下面是输出了训练集中前20个样本
fig, ax = plt.subplots(nrows=4,ncols=5,sharex='all',sharey='all')
ax = ax.flatten()
for i in range(20):
img = x_train[i].reshape(28, 28)
ax[i].imshow(img,cmap='Greys')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
# 定义网络结构
class mnisModel(Model):
def __init__(self, *args, **kwargs):
super(mnisModel, self).__init__(*args, **kwargs)
self.flatten1=layers.Flatten()
self.d1=layers.Dense(128, activation=tf.keras.activations.relu)
self.d2=layers.Dense(10, activation=tf.keras.activations.softmax)
def call(self, input):
x = self.flatten1(input)
x = self.d1(x)
x = self.d2(x)
return(x)
model = mnisModel()
#设置训练参数
model.compile(optimizer='adam', # 'adam' tf.keras.optimizers.Adam(learning_rate=0.4 , beta_1=0.9, beta_2=0.999)
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 训练
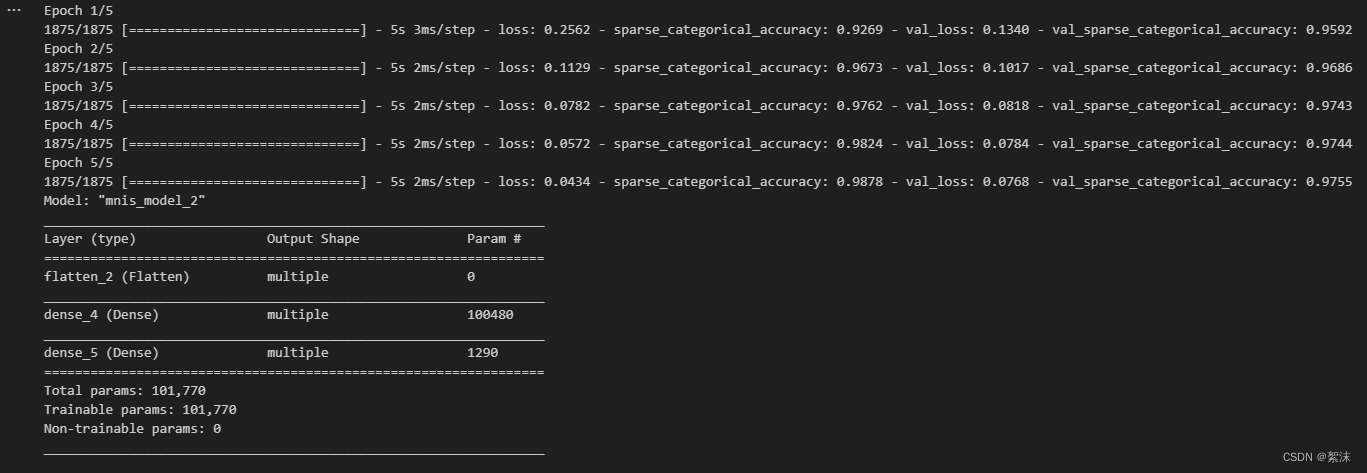
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data = (x_test, y_test), validation_freq=1)
model.summary()
运行后会先显示数据集中的前二十个数字

关闭数字展示窗口后开始训练,并看到训练的过程