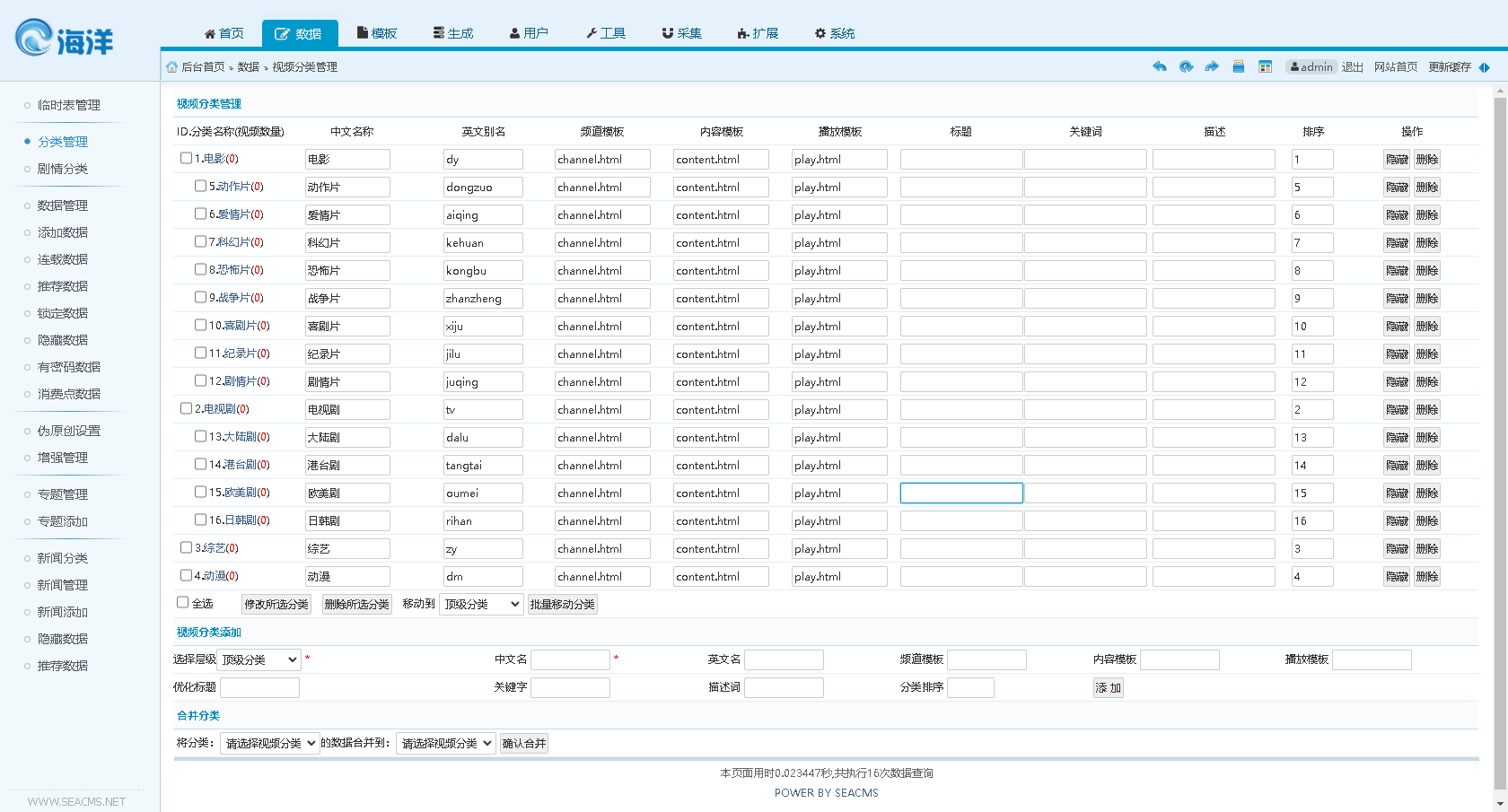
机器阅读理解复习
- 机器阅读理解概述
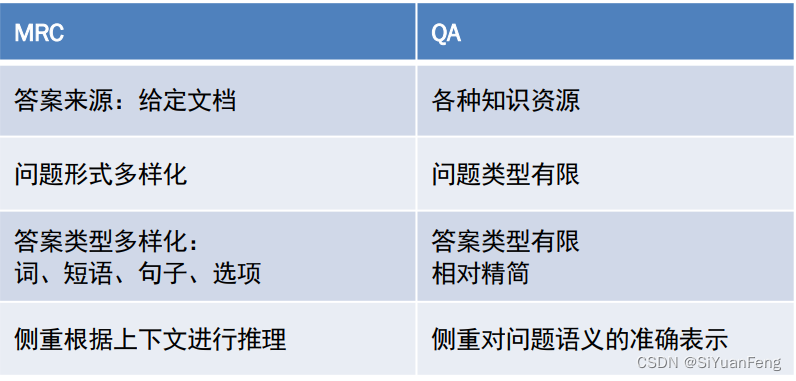
- 机器阅读(MRC)理解与问答系统(QA)的区别:
- 本章内容:
- MRC 任务分类:
- 完形填空形式(cloze-style)
- 选项形式
- 片段抽取形式(span extraction)
- 文本生成形式(free-answer/generation)
- 阅读理解实现方法
- 传统特征工程
- 深层语义图匹配
- 深度神经网络
- 神经网络机器阅读理解基本框架
- 嵌入编码:
- 特征提取:
- 文章-问题交互:
- 答案预测:
- 神经网络机器阅读理解典型模型
本章复习重点:
阅读理解的方法,和问答系统的方法 基本过程上有哪些典型的区别,它的基本过程是什么样的,和问答系统的核心区别是什么,大致的技术思路概念就可以
机器阅读理解概述

机器阅读理解其实和人阅读理解面临的问题是类似的,不过为了降低任务难度,很多目前研究的机器阅读理解都将世界知识排除在外,采用人工构造的比较简单的数据集,在给定的文本或相关内容(事实)的基础上,要求机器根据文本的内容,对相应的问题作出回答;一般回答的是一些非事实性的、高度抽象的需要对语言理解的问题 。
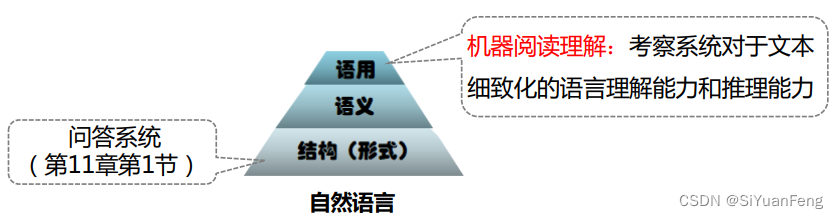
机器阅读(MRC)理解与问答系统(QA)的区别:
- 问答系统(QA)考察系统的文本匹配、信息抽取能力;
- MRC考察系统对于文本细致化的语言理解能力和推理能力;
- 机器阅读理解核心问题:理解和推理,并不是简单的文本匹配或者相似度计算
- 机器阅读理解研究特点: 任务导向 + 数据驱动
在机器阅读理解任务当中,问题的答案是给定的,是有监督学习任务
本章内容:
- 任务分类及评价指标
- 数据集
- 实现方法
- 主要挑战
MRC 任务分类:
传统的MRC任务可以分为四种类型:完形填空、多项选择、片段抽取、自由回答
考虑到目前方法的局限性,MRC出现了新的任务,如,knowledge-based MRC, MRC with unanswerable questions, multi-passage MRC,conversational question answering
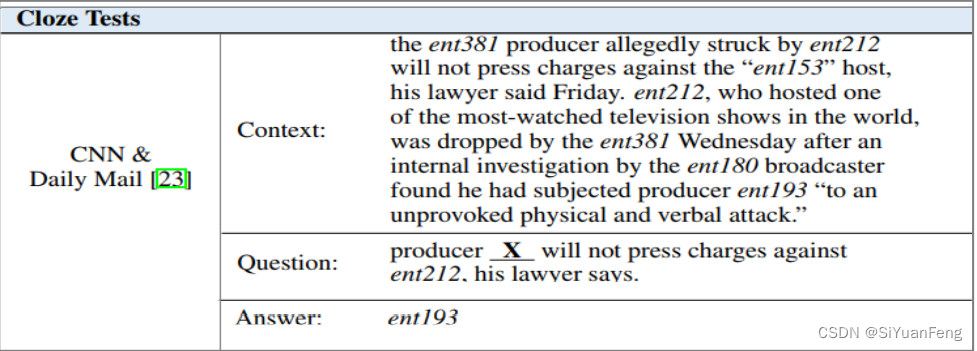
完形填空形式(cloze-style)
- 提供:文本C,且一个词或实体 a ( a∈C ) 被移除
- 任务:使用正确的词或实体进行填空(最大化条件概率 P(a |C - {a} )
- 数据集:CNN & Daily Mail 、 Children’s Book Test (CBT)、LAMBADA、Who-did-What、CLOTH
- 答案类型: 客观
评价指标: Accuracy 准确率:衡量正确预测出答案占测试集合的比例
A c c u r a c y = 预测答案正确的个数 测试集合的大小 Accuracy=\frac{预测答案正确的个数}{测试集合的大小} Accuracy=测试集合的大小预测答案正确的个数
选项形式
- 提供:文本C,问题Q ,候选答案列表 A={a1, a2 ,…. an }
- 任务:从A中选择正确的答案ai (最大化条件概率 P(ai |C ,Q ,A )
- 数据集: MCTest、RACE
- 答案类型: 客观
- Accuracy 准确率:衡量正确预测出答案占测试集合的比例
A c c u r a c y = 预测答案正确的个数 测试集合的大小 Accuracy=\frac{预测答案正确的个数}{测试集合的大小} Accuracy=测试集合的大小预测答案正确的个数

片段抽取形式(span extraction)
- 提供:文本C,问题Q ,其中 C = {t1, t2 ,…. tn }
- 任务:从C中抽取连续的子序列 {ti, ti+1 ,…. ti+k } (1 ≤i ≤i+k≤ n) 做为正确答案
(最大化条件概率 P(a |C ,Q ) - 数据集: SQuAD、NewsQA、TriviaQA、DuoRC
- 答案类型: 半客观
- Exact Match 精确匹配:衡量预测答案是否与标准答案完全一致
- u F1 值:衡量预测答案与标准答案的相似度

文本生成形式(free-answer/generation)
- 提供:文本C,问题Q
- 任务:根据文本内容和问题生成答案 a ,a可以是C的子序列,也可以不是C的子序列。
(最大化条件概率 P(a |C ,Q ) - 数据集: bAbI、MS MARCO 、SearchQA、NarrativeQA、DuReader
- 答案类型: 主观
- 评价指标:
- BLEU
- ROUGE-L(自动摘要任务当中的常用指标)

阅读理解实现方法
机器阅读理解通常是有监督的,实现方法有三类
- 传统的特征工程方法
- 深层语义图匹配方法
- 深度神经网络方法
传统特征工程
优点:解释性强,每一部分的结果都能直观的展现出来
缺点:需要大量人工构建的特征,特征本身具有局限性;
- 大多数特征都是基于离散的串匹配的,无法很好地解决表达的多样性问题;
- 大多数特征是基于窗口的,很难处理多个句子之间的长距离依赖问题;
- 由于窗口或者是n-gram并不是一个有效的表达语义的单元,存在语义缺失
或引入噪声等问题;
- 由于窗口或者是n-gram并不是一个有效的表达语义的单元,存在语义缺失
- 基于 词汇重叠程度 或 文本相似程度 在很多情况下会失效;
- 错误答案和正确答案都在文档中出现;
- 不具备推理能力:在计数、处理时间、比较等问题上
深层语义图匹配
优点:引入了深层次的语义结构,能够捕捉深层面的语义信息;
- 语义建模方式解释性好,每一部分的语义都能很直观地表示出来;
缺点:语义结构的定义与问题相关;
- 语义结构的定义十分依赖于人工特征的干预;
- 属于领域相关的方法,应用范围有很大的局限性;
深度神经网络
优点:各种语义单元被表示为连续的语义空间上的向量,可以有效地解决语义稀疏性以及复述的问题。
- 建立一种End-to-End的网络模型;改善了传统方法中的错误级联和语义匹配问题;
- 自动学习文本的语义表示、语义组合以及问答的过程;
缺点:缺乏引入外部知识进行更深层次推理机制;
- 需要更加复杂的网络模型对MRC过程进行建模与刻画;
神经网络机器阅读理解基本框架
一般由四个模块组成
- 嵌入编码 Embeddings
- 特征提取 Feature Extraction / Encoding
- 文章-问题交互 Context-Question Interaction
- 答案预测 Answer Prediction
嵌入编码:
将模型的输入(自然语言形式的文章和问题)编码成固定维度的向量
输入:
- 文档token序列(词表中的id构成的序列)
- 问题token序列
输出:
- 文档token序列的词向量表示(分布式向量表示)
- 问题token序列的词向量表示
注: 如果存在候选答案选项,也要进行Embedding
特征提取:
接收由嵌入编码层编码得到的文章和问题的词向量表示,对其进行处理,抽取更多上下文信息
输入:
- 文档和问题token序列的词向量表示
输出:
- 文档和问题token序列的上下文表示
文章-问题交互:
利用文章和问题之间的交互信息来推测出文章中哪些部分对于回答问题更为重要(常用单向或双向的注意力机制来实现) 两者之间的交互过程有时可能会执行多次–模拟人类的推理过程。
输入:
- 文档和问题token序列的上下文表示
输出:
- 文档和问题token序列的注意力感知更新后的序列表示
答案预测:
基于前述三个模块累积得到的信息进行最终的答案预测
输入:
- 经过交互操作后的融合表示(通常是更新后的文档表示)
输出: - 预测的答案分布,不同的任务类型有不同答案结果形式
神经网络机器阅读理解典型模型
- 基于完形填空的机器阅读理解
- 基于选项的机器阅读理解
- 基于片段抽取的机器阅读理解
- 基于文本生成的机器阅读理解
仍然是上面这四种类型