一、Roundabout Aerial Images for Vehicle Detection
本数据集是从无人机拍摄的西班牙环形交叉口航空图像数据集,使用PASCAL VOC XML文件进行注释,指出车辆在其中的位置。此外,还附带一个CSV文件,其中包含与捕获的环形交叉口的位置和特征有关的信息。这项工作详细描述了获取它们的过程:图像捕获、处理和标记。数据集包含985,260个实例:947,400辆汽车,19,596辆自行车,2,262辆卡车,7,008辆公共汽车和2208个空环形路,61,896张1920x1080px JPG图像。这些图像被分为15,474张从8个不同交通流的环形交叉口提取的图像和46,422张使用数据增强技术创建的图像。
数据集链接:https://www.kaggle.com/datasets/javiersanchezsoriano/roundabout-aerial-images-for-vehicle-detection
论文链接:https://doi.org/10.3390/data7040047

图例:

本数据集从原版数据集每隔15张抽取了1张图片用于测试,共计1032张
相应的脚本工程如下:
import os
import numpy as np
import shutil
files = 'img/uavdtallimages_rename'
target_files = 'img_chouqu'
def mycopyfile(srcfile, dstpath, ari):
if not os.path.exists(dstpath):
os.makedirs(dstpath) # 创建路径
print(srcfile)
shutil.copy(srcfile, target_files + "/" + ari) # 复制文件
print("copy %s -> %s"%(srcfile, target_files + ari))
name1 = os.listdir(files)
name = np.array(name1)
need_num = 1 # 每批图片的前几张图片
batch_size = 40 # 每批图片的数量
n = len(name)
bi = np.floor(np.arange(n) / batch_size).astype(np.int)
bn = bi[-1] + 1
for i in range(bn):
ari = name[bi == i]
for x in range(need_num):
path = files + "/" + ari[x]
mycopyfile(path, target_files, ari[x])
二、LEVIR数据集
Zou Z, Shi Z. Random access memories: A new paradigm for target detection in high resolution aerial remote sensing images[J]. IEEE Transactions on Image Processing, 2017, 27(3): 1100-1111.
数据下载地址:http://levir.buaa.edu.cn/Code.htm
链接: https://pan.baidu.com/s/1-eUAq2PszdHeE2VSG3q5cw 提取码: j9jp
LEVIR数据集由大量 800 × 600 像素和0.2m-1.0m 像素的高分辨率Google Earth图像和超过22k的图像组成。LEVIR数据集涵盖了人类居住环境的大多数类型的地面特征,例如城市,乡村,山区和海洋。数据集中未考虑冰川,沙漠和戈壁等极端陆地环境。数据集中有3种目标类型:飞机,轮船(包括近海轮船和向海轮船)和油罐。所有图像总共标记了11k个独立边界框,包括4,724架飞机,3,025艘船和3,279个油罐。每个图像的平均目标数量为0.5。
数据集下载地址:http://levir.buaa.edu.cn/Code.htm
论文地址:https://ieeexplore.ieee.org/document/8106808

由于本数据集有与许多负样本图片,需要对图片进行筛选,将负样本图片剔除,脚本工程如下:
import os
import shutil
image = './数据集分割/验证集'
labels = "./2"
image = os.listdir(image)
labels = os.listdir(labels)
for file in image:
file = file.split(".")[0]
for label in labels:
label = label.split(".")[0]
pathall = "." + "/" + "2" + "/" + file + '.' + "txt"
outpath = "." + "/" + "数据集分割" + "/" + "验证集" + "/" + file + '.' + "txt"
if label == file:
shutil.copy(pathall, outpath)
break
else:
pass
筛选完成后,由于其特殊的标注方式,会有负坐标的产生,因此需要对负坐标置为1,并且需要对相应的坐标进行归一化。需要对其格式进行转换相应的转换脚本工程如下:
import os
from xml.dom.minidom import Document
import cv2
def convert(size, box):
x_center = (int(box[3]) + int(box[1])) / 2.0
y_center = (int(box[4]) + int(box[2])) / 2.0
# 归一化
x = x_center / int(size[0])
y = y_center / int(size[1])
# 求宽高并归一化
w = (int(box[3]) - int(box[1])) / size[0]
h = (int(box[4]) - int(box[2])) / size[1]
return (int(box[0]), x, y, w, h)
def makexml(picPath, txtPath, yolo_paths): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
files = os.listdir(txtPath)
for i, name in enumerate(files):
yolo_txt_path = os.path.join(yolo_paths, name.split(".")[0]
+ ".txt")
txtFile = open(txtPath + name)
with open(yolo_txt_path, 'w') as f:
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, _ = img.shape
for j in txtList:
oneline = j.strip().split(" ")
obj = oneline[0]
xmin = oneline[1]
if int(xmin) < 0 :
xmin = "1"
ymax = oneline[2]
if int(ymax) < 0 :
ymax = "1"
xmax = oneline[3]
ymin = oneline[4]
box = convert((Pwidth, Pheight), oneline)
f.write(str(box[0]) + " " + str(box[1]) + " " + str(box[2]) + " " + str(box[3]) + " " + str(box[4]) + '\n')
if __name__ == "__main__":
picPath = "./out/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "./labels/" # txt所在文件夹路径,后面的/一定要带上
yolo = "./xml/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, yolo)
三、NWPU VHR-10 dataset
论文:Cheng G, Zhou P, Han J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(12): 7405-7415.
链接: https://pan.baidu.com/s/1YJXr1jlwgJVVX9hl8v93lw 提取码: jpuz
数据集下载链接:https://hyper.ai/tracker/download?torrent=6830
此数据集由西北工业大学标注的航天遥感目标检测数据集,共有800张图像,这些图像是从Google Earth和Vaihingen数据集裁剪而来的,然后由专家手动注释。其中包含目标的650张,背景图像150张,目标包括:飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁、车辆10个类别。
数据说明:数据集包含以下文件
数据包包括如下:
negative image set:包含150个不包含给定对象类别的任何目标的图像;
positive image set:650个图像,每个图像至少包含一个要检测的目标;
ground truth:包含650个单独的文本文件,每个对应于“正图像集”文件夹中的图像。这些文本文件的每一行都以以下格式定义了ground truth边界框:
x1,y1),(x2,y2),a
其中(x1,y1)表示边界框的左上角坐标,(x2,y2)表示边界框的右下角坐标,
a是对象类别(1-飞机,2-轮船,3-储罐,4-棒球场,5-网球场,6-篮球场,7-田径场,8-港口,9-桥梁,10-车辆)。
10个地理空间对象类,包括飞机、棒球场、篮球场、桥梁、港口、地面田径场、船舶、储罐、网球场和车辆。它由715幅RGB图像和85幅锐化彩色红外图像组成。其中715幅RGB图像采集自谷歌地球,空间分辨率从0.5m到2m不等。85幅经过pan‐锐化的红外图像,空间分辨率为0.08m,来自Vaihingen数据。该数据集共包含3775个对象实例,其中包括757架飞机、390个棒球方块、159个篮球场、124座桥梁、224个港口、163个田径场、302艘船、655个储罐、524个网球场和477辆汽车,这些对象实例都是用水平边框手工标注的。

由于数据集的标注格式与yolo格式有所出入,需要将其转化为yolo格式,其脚本工程如下:
import os
import cv2
def convert(size, box):
x_center = (int(box[3]) + int(box[1])) / 2.0
y_center = (int(box[4]) + int(box[2])) / 2.0
# 归一化
x = x_center / int(size[0])
y = y_center / int(size[1])
# 求宽高并归一化
w = (int(box[3]) - int(box[1])) / size[0]
h = (int(box[4]) - int(box[2])) / size[1]
return (int(box[0]), x, y, w, h)
def makexml(picPath, txtPath, yolo_paths): # txt所在文件夹路径,yolo文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
files = os.listdir(txtPath)
for i, name in enumerate(files):
print(name)
yolo_txt_path = os.path.join(yolo_paths, name.split(".")[0]
+ ".txt")
txtFile = open(txtPath + name)
with open(yolo_txt_path, 'w') as f:
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, _ = img.shape
for j in txtList:
oneline = j.strip().split(",")
a = int(oneline[4])
b = int(oneline[0][1:])
c = int(oneline[1][:-1])
d = int(oneline[2][1:])
e = int(oneline[3][:-1])
oneline = (int(oneline[4]), int(oneline[0][1:]), int(oneline[1][:-1]), int(oneline[2][1:]), int(oneline[3][:-1]))
box = convert((Pwidth, Pheight), oneline)
f.write(str(box[0]) + " " + str(box[1]) + " " + str(box[2]) + " " + str(box[3]) + " " + str(box[4]) + '\n')
if __name__ == "__main__":
picPath = "./image/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "./txt/" # txt所在文件夹路径,后面的/一定要带上
yolo = "./xml/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, yolo)
四、UCAS_AOD
用于飞机和车辆检测。具体来说,飞机数据集包括600张图像和3210架飞机,而车辆数据集包括310张图像和2819辆车辆。所有的图像都经过精心挑选,使数据集中的物体方向分布均匀。
样例图示如下:

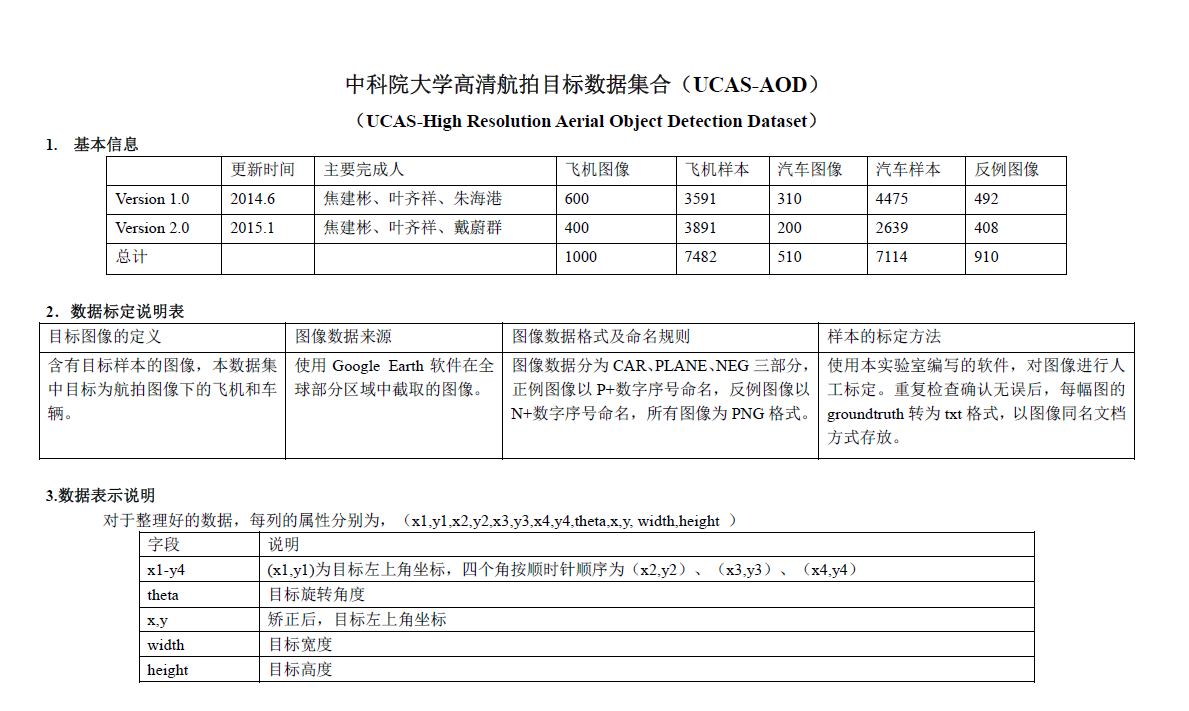
论文:H. Zhu, X. Chen, W. Dai, K. Fu, Q. Ye, J. Jiao, “Orientation Robust Object Detection in Aerial Images Using Deep Convolutional Neural Network,” IEEE Int’l Conf. Image Processing, 2015.
数据下载:http://www.ucassdl.cn/resource.asp
https://hyper.ai/tracker/download?torrent=6626
下载地址:https://pan.baidu.com/s/1Poo0zEHTHDfBTnKPb5YTCg 提取码: 7zsi
数据集转化为yolo格式的脚本如下:
import os
import cv2
import math
def convert(size, box):
x_center = box[1] + box[3] / 2.0
y_center = box[2] + box[4] / 2.0
# 归一化
x = x_center / int(size[0])
y = y_center / int(size[1])
# 求宽高并归一化
w = box[3] / size[0]
h = box[4] / size[1]
return (int(box[0]), x, y, w, h)
def fun(str_num):
before_e = float(str_num.split('e')[0])
sign = str_num.split('e')[1][:1]
after_e = int(str_num.split('e')[1][1:])
if sign == '+':
float_num = before_e * math.pow(10, after_e)
elif sign == '-':
float_num = before_e * math.pow(10, -after_e)
else:
float_num = None
print('error: unknown sign')
return float_num
def makexml(picPath, txtPath, yolo_paths): # txt所在文件夹路径,yolo文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
files = os.listdir(txtPath)
for i, name in enumerate(files):
print(name)
yolo_txt_path = os.path.join(yolo_paths, name.split(".")[0]
+ ".txt")
txtFile = open(txtPath + name)
with open(yolo_txt_path, 'w') as f:
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".png")
Pheight, Pwidth, _ = img.shape
for j in txtList:
oneline = j.strip().split("\t")
try:
int(oneline[9])
except ValueError:
a = fun(oneline[9])
else:
a = int(oneline[9])
try:
int(oneline[10])
except ValueError:
b = fun(oneline[10])
else:
b = int(oneline[10])
try:
int(oneline[11])
except ValueError:
c = fun(oneline[11])
else:
c = int(oneline[11])
try:
int(oneline[12])
except ValueError:
d = fun(oneline[12])
else:
d = int(oneline[12])
oneline = (10, a, b, c, d)
box = convert((Pwidth, Pheight), oneline)
f.write(str(box[0]) + " " + str(box[1]) + " " + str(box[2]) + " " + str(box[3]) + " " + str(box[4]) + '\n')
if __name__ == "__main__":
picPath = "./PLANE/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "./xml/" # txt所在文件夹路径,后面的/一定要带上
yolo = "./yolo/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, yolo)
五、 UAVDT
UAVDT是ICCV2018提出的一个数据集,共包含80000帧图片,不仅可以用于目标跟踪,也可以用于目标检测等。
针对目标跟踪,主要有单目标跟踪(UAV-benchmark-S)和多目标跟踪(UAV-benchmark-M)两个数据集,作者在主页据给出相应的跑库工具。
作者主页(数据集+跑库工具):https://sites.google.com/site/daviddo0323/projects/uavdt
论文下载:https://arxiv.org/abs/1804.00518
虽然作者在主页给了数据集和跑库工具的谷歌下载地址、百度网盘下载地址,但为了方便,将作者主页的单目标跟踪的数据集百度网盘下载地址:https://pan.baidu.com/s/1Vts7V-6JYd395vL6mVYMFQ#list/path=%2F
检测数据集:链接: https://pan.baidu.com/s/1fYhb0cuxQ4dtjutgu5hq8Q 提取码: 24uw
样例图片如下:

标签格式如下:

本文提供python版本的转换脚本:
1、将多文件数据集进行合并
import os
import shutil
multidirpath = 'model/down/UAVDET/UAV-benchmark-M'
outdir = 'model/down/UAVDET/uavdtallimages_rename'
os.mkdir((outdir))
filenames = os.listdir(multidirpath)
print(filenames)
for file in filenames:
wholefile = multidirpath + '/' + file + '/' + "img1"
filenextname = os.listdir(wholefile)
print("filenextname", filenextname)
for filenext in filenextname:
pathall = multidirpath + '/' + file + '/' + "img1"+ '/' + filenext
# print(pathall)
str1 = str(file)
outpath = outdir + '/' + str1 + '_' + filenext[-10:]
# print(outpath)
print("pathall", pathall)
print("outpath",outpath)
shutil.copyfile(pathall,outpath)
2、将标签转化为COCO格式·
import json
import pandas as pd
import os
classList = ["car", "truck", "bus"]
# By default, coco dataset starts index of categories from 1
PRE_DEFINE_CATEGORIES = {key: idx + 1 for idx, key in enumerate(classList)}
# print(PRE_DEFINE_CATEGORIES)
txtdir = 'down/UAVDET/UAV-benchmark-MOTD_v1.0/GT'
out_json_file = "out.json"
json_dict = {"images": [], "type": "instances", "annotations": [],
"categories": []}
# json格式如下,我们要写这总的4个部分,先把最简单的categories写了吧
# {"images": [], "type": "instances", "annotations": [], "categories": []}
# 先把categories部分写完
for cate, cid in PRE_DEFINE_CATEGORIES.items():
cat = {'supercategory': cate, 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
def get_annot_data(txt_file):
'''Read annotation into a Pandas dataframe'''
annot_data = pd.read_csv(txt_file, delimiter=',', names=['<frame_index>','<target_id>','<bbox_left>','<bbox_top>','<bbox_width>','<bbox_height>','<out-of-view>','<occlusion>','<object_category>'])
return annot_data
# 记录键值对为后面id进行使用
dict_imagename2id = {}
# 先实现images部分
# begin
imageid= 0
imagesdir = '/home/renkeying/model/down/UAVDET/uavdtallimages_rename'
for image_name in os.listdir(imagesdir):
file_name = image_name
width = 540
height = 1024
id = imageid
imageid += 1
dict_imagename2id[file_name[:-4]] = id
image = {'file_name': file_name, 'height': height, 'width': width, 'id': id}
json_dict['images'].append(image)
# end
# images部分写好了
# 接下来写annotations部分
bndid_change = 1
for txt_file in os.listdir(txtdir):
if 'gt_whole' in txt_file:
# print(txt_file)
txtwholepath = txtdir + '/'+ txt_file
# print(txtwholepath)
with open(txtwholepath) as f:
annot_data = get_annot_data(txtwholepath)
# print(annot_data)
# print(annot_data.loc[0])
# for index in annot_data:
# print(index)
# pandas按行输出
for index, row in annot_data.iterrows():
# print(index) # 输出每行的索引值
# 要加int不然会出现int64错误
o_width = int(row['<bbox_width>'])
o_height = int(row['<bbox_height>'])
xmin = int(row['<bbox_left>'])
ymin = int(row['<bbox_top>'])
category_id = int(row['<object_category>'])
bnd_id = int(bndid_change)
# image_id需要建立一个map或者叫dict
# 转化成000001
imageindx = row['<frame_index>']
k = str(imageindx)
str1 = txt_file[0:5]
str2 = k.zfill(6)
dictfilename = str1 + '_' + str2
image_id = int(dict_imagename2id[dictfilename])
print(image_id)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':image_id, 'bbox': [xmin, ymin, o_width, o_height],'category_id': category_id, 'id': bnd_id, 'ignore': 0,'segmentation': []}
bndid_change += 1
json_dict['annotations'].append(ann)
# break
# about json
json_fp = open(out_json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()