论文链接:https://openreview.net/forum?id=pfNyExj7z2 | https://arxiv.53yu.com/abs/2110.04627
原文标题:Vector-quantized Image Modeling with Improved VQGAN
一、问题提出
Natural language processing (NLP) has recently experienced dramatic improvements from learning general-purpose representations by pretraining language models on unlabeled text corpora. This strategy has produced large performance gains for a wide range of natural language generation (NLG) and natural language understanding (NLU) tasks.
最近,自然语言处理(NLP)通过在未标记文本语料库上预训练语言模型来学习通用表示,取得了巨大的进步。这种策略已经为广泛的自然语言生成(NLG)和自然语言理解(NLU)任务带来了巨大的性能提升
在大规模图像识别中,iGPT(使用自回归目标学习直接预测像素值的huge-transformer)的最大分辨率为64 × 64,这严重限制了它的表示能力。
二、模型架构(Vit-VQVAE + VIM)

1、流程
stage1:Image Quantization.
给定分辨率为256×256的图像,基于Vit的VQGAN将其编码为32×32离散潜码(discretized latent codes),其中codebook大小为8192。
Stage 2: Vector-quantized Image Modeling.
训练一个Transformer模型来自回归预测栅格化32×32 = 1024图像标记,其中图像标记由学习的Stage 1 Vit-VQGAN编码。对于无条件图像合成或无监督学习,预先训练一个仅解码器的Transformer模型来预测下一个令牌。为评估无监督学习的质量,平均中间Transformer特征,并学习一个linear head来预测类的logit(也就是linear-probe)。
2、model
VQVAE和VQGAN用于encoder和decoder图像的核心网络架构是CNN,作者使用vit替换。一是因为数据量丰富、二是CNN的归纳偏置对模型的约束是有限的,三是计算效率和重建质量更显著。

将image打成8*8个patches,每个patch有1024维的token,(bs,64,1024)经过Tranformer blocks维度不变,然后映射为codebook中的code,找到最近邻,decoder是逆向操作,将其8*8的patches映射为256*256的图像。在block中,有两个全连接层,使用tanh激活,预测值采用sigmoid。
3、codebook learning
传统VQVAE由于codebook初始化不佳而导致码本使用率低。因此,在训练过程中,有相当一部分code很少被使用,或者dead。有效codebook大小的减少导致在stage 1中重建较差,在图像合成的stage 2中多样性较差。

β是0.25,e是codebook向量。
Factorized codes. 从编码器输出到低维潜变量空间的线性投影,用于code index检索(例如,每个code从768d向量减少到32d或8d向量),并发现立即提高了codebook的使用。在低维查找空间上查找从输入编码的最接近的code,然后将匹配的latent code投影到高维embedding空间。
L2-normalized codes. 对编码的潜在变量ze(x)和码本潜在变量e应用L2归一化。码本变量从正态分布初始化。通过将所有潜在变量映射到一个sphere,L2-归一化潜在变量的欧氏距离演化为ze(x)和e之间两个向量的余弦相似度,进一步提高了实验中训练的稳定性和重构质量。
4、training Loss
logit-laplace loss, L2 loss, perceptual loss。Total Loss:
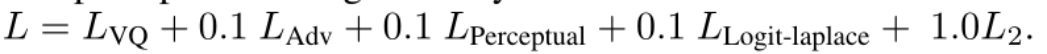
5、image Modeling
使用decoder-only Transformer对图像建模:

训练object:

网络配置:

使用预训练的生成Transformer模型,通过简单地从输出softmax分布中逐个token采样来实现无条件图像生成。
默认的Stage 1 ViTVQGAN将分辨率为256 × 256的输入图像编码为32 × 32的潜在码,码本大小为8192,而Stage 2 Transformer则采用总长度为1024的扁平图像令牌。
将无条件生成扩展为有类条件的生成,方法是在图像令牌之前前置一个类id令牌。对于类id标记和图像标记,从头开始学习单独的嵌入层,嵌入维度与Transformer模型维度相同。在采样期间,在第一个位置提供一个类id标记,以自回归解码剩余的图像token。
三、实验
参数设置:
batchsize256,128 CloudTPUv4,总共50w step,Adam,warmup 5W step,lr 1e−4,Loshchilov 衰减 5e-5,256*256
模型比较:

条件生成:
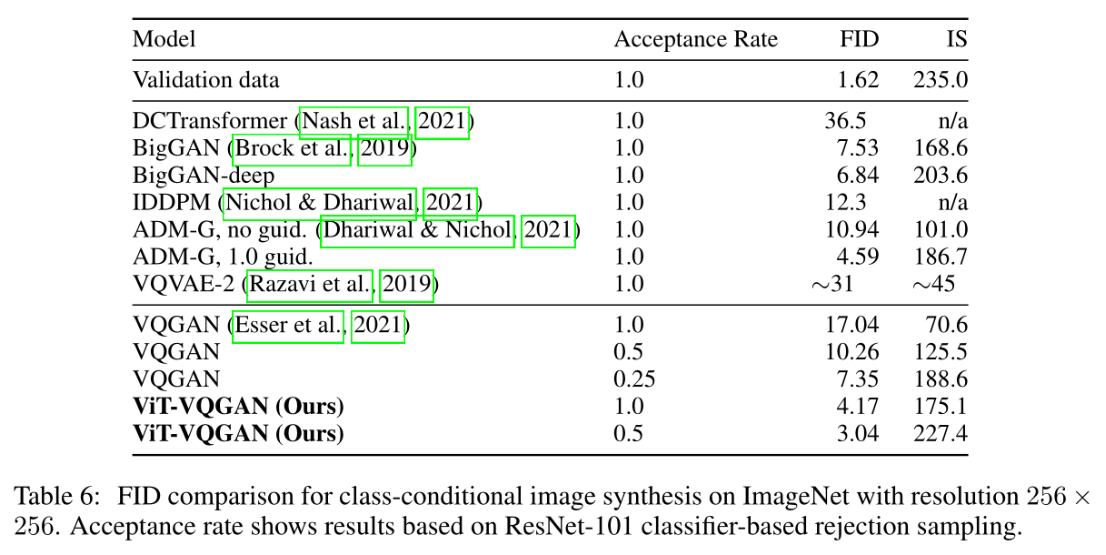
ImageNet上的条件生成:






![[程序设计]-基于人工智能博弈树,极大极小(Minimax)搜索算法并使用Alpha-Beta剪枝算法优化实现的可人机博弈的AI智能五子棋游戏。](https://img-blog.csdnimg.cn/83e1004aada2485d8d7c4c074aaafc1a.png)