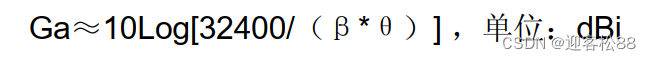Rust标准库包含了一系列非常有用的被称为集合的数据结构。大部分的数据结构都代表着某个特定的值,但集合却可以包含多个值。
与内置的数组与元组类型不同,这些集合将自己持有的数据存储在了堆上。这意味着数据的大小不需要在编译时确定,并且可以随着程序的运行按需扩大或缩小数据占用的空间。不同的集合类型有着不同的性能特性与开销,你需要学会如何为特定的场景选择合适的集合类型。
在本篇文章中,我们将讨论以下3个被广泛使用在Rust程序中的集合:
💗 动态数组(vector)可以让你连续地存储任意多个值。
💗 字符串(string)是字符的集合。我们之前提到过String类型,本文会更为深入地讨论它。
💗 哈希映射(hash map)可以让你将值关联到一个特定的键上,它是另外一种数据结构—映射(map)的特殊实现。
对于标准库中的其他集合类型,你可以通过在Rust官方网站查询相关文档来学习。我们会讨论如何创建和更新动态数组、字符串及哈希映射,并研究它们之间的异同。
1. 使用动态数组存储多个值
我们要学习的第一个集合类型叫作Vec<T>,也就是所谓的动态数组。动态数组允许你在单个数据结构中存储多个相同类型的值,这些值会彼此相邻地排布在内存中。
动态数组非常适合在需要存储一系列相同类型值的场景中使用,例如文本中由字符组成的行或购物车中的物品价格等。
2. 创建动态数组
我们可以调用函数Vec::new来创建一个空动态数组,如示例8-1所示。
// 示例8-1:创建一个用来存储i32数据的空动态数组
let v: Vec<i32> = Vec::new();注意,这段代码显式地增加了一个类型标记。因为我们还没有在这个动态数组中插入任何值,所以Rust无法自动推导出我们想要存储的元素类型。
这一点非常重要。动态数组在实现中使用了泛型;我们将在后面文章中学习如何为自定义类型添加泛型。但就目前而言,你只需要知道,标准库中的Vec<T>可以存储任何类型的元素,而当你希望某个动态数组持有某个特定的类型时,可以通过一对尖括号来显式地进行声明。
示例8-1中的语句向Rust传达了这样的含义:v变量绑定的Vec<T>会持有i32类型的元素。在实际的编码过程中,只要你向动态数组内插入了数据,Rust便可以在绝大部分情形下推导出你希望存储的元素类型。
我们只需要在极少数的场景中对类型进行声明。另外,使用初始值去创建动态数组的场景也十分常见,为此,Rust特意提供了一个用于简化代码的vec! 宏。这个宏可以根据我们提供的值来创建一个新的动态数组。
示例8-2创建了一个持有初始值1、2、3的Vec<i32>。
// 示例8-2:创建一个包含了值的新动态数组
let v = vec![1, 2, 3];由于Rust可以推断出我们提供的是i32类型的初始值,并可以进一步推断出v的类型是Vec<i32>,所以在这条语句中不需要对类型进行声明。接下来,我们会介绍如何修改一个动态数组。
3. 更新动态数组
为了在创建动态数组后将元素添加至其中,我们可以使用push方法,如示例8-3所示。
// 示例8-3:使用push方法将值添加到动态数组中
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);正如前文讨论过的,对于任何变量,只要我们想要改变它的值,就必须使用关键字mut来将其声明为可变的。由于Rust可以从数据中推断出我们添加的值都是i32类型的,所以此处同样不需要添加Vec<i32>的类型声明。
4. 销毁动态数组时也会销毁其中的元素
和其他的struct一样,动态数组一旦离开作用域就会被立即销毁,如示例8-4中的注释所示。
// 示例8-4:展示了动态数组及其元素销毁的地方
{
let v = vec![1, 2, 3, 4];
// 执行与v相关的操作
} // <- v在这里离开作用域并随之被销毁动态数组中的所有内容都会随着动态数组的销毁而销毁,其持有的整数将被自动清理干净。这一行为看上去也许较为直观,但却会在你接触到指向动态数组元素的引用时变得有些复杂。让我们接着来处理这种情况!
5. 读取动态数组中的元素
现在,你应该已经学会了如何去创建、更新及销毁动态数组,接下来就该了解如何读取其中的内容了。有两种方法可以引用存储在动态数组中的值。为了更加清晰地说明问题,我们在下面的示例中标记出了函数返回值的类型。
示例8-5展示了两种访问动态数组的方式,它们分别是使用索引和get方法。
// 示例8-5:使用索引或get方法来访问动态数组中的元素
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {}", third);
match v.get(2) {
Some(third) => println!("The third element is {}", third),
None => println!("There is no third element."),
}这里有两个需要注意的细节。首先,我们使用索引值2获得的是第三个值:动态数组使用数字进行索引,索引值从零开始。
其次,使用&与[]会直接返回元素的引用;而接收索引作为参数的get方法则会返回一个Option<&T>。当你尝试使用对应元素不存在的索引值去读取动态数组时,因为Rust提供了两种不同的元素引用方式,所以你能够自行选择程序的响应方式。
比如,示例8-6中创建的动态数组持有5个元素,但它却尝试着访问数组中索引值为100的元素,让我们来看一下这种行为会导致什么样的后果。
// 示例8-6:尝试在只有5个元素的动态数组中访问索引值为100的元素
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);当我们运行这段代码时,[]方法会因为索引指向了不存在的元素而导致程序触发panic。假如你希望在尝试越界访问元素时使程序直接崩溃,那么这个方法就再适合不过了。
get方法会在检测到索引越界时简单地返回None,而不是使程序直接崩溃。当偶尔越界访问动态数组中的元素是一个正常行为时,你就应该使用这个方法。
另外,正如在前面讨论的那样,你的代码应该合乎逻辑地处理Some(&element)与None两种不同的情形。例如,索引可能来自一个用户输入的数字。当这个数字意外地超出边界时,程序就会得到一个None值。
而我们也应该将这一信息反馈给用户,告诉他们当前动态数组的元素数量,并再度请求用户输入有效的值。这就比因为输入错误而使程序崩溃要友好得多!
如同在前面讨论过的那样,一旦程序获得了一个有效的引用,借用检查器就会执行所有权规则和借用规则,来保证这个引用及其他任何指向这个动态数组的引用始终有效。
回忆一下所有权规则,我们不能在同一个作用域中同时拥有可变引用与不可变引用。示例8-7便遵循了该规则。在这个例子中,我们持有了一个指向动态数组中首个元素的不可变引用,但却依然尝试向这个动态数组的结尾处添加元素,该尝试是不会成功的。
// 示例8-7:在存在指向动态数组元素的引用时尝试向动态数组中添加元素
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {}", first);编译这段代码将会导致下面的错误:
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
-->
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^ mutable borrow occurs here
7 |
8 | println!("The first element is: {}", first);你也许不会觉得示例8-7中的代码有什么问题:为什么对第一个元素的引用需要关心动态数组结尾处的变化呢?
此处的错误是由动态数组的工作原理导致的:动态数组中的元素是连续存储的,插入新的元素后也许会没有足够多的空间将所有元素依次相邻地放下,这就需要分配新的内存空间,并将旧的元素移动到新的空间上。
在本例中,第一个元素的引用可能会因为插入行为而指向被释放的内存。借用规则可以帮助我们规避这类问题。
注意:你可以查看The Rustonomicon中的相关内容来了解更多Vec<T>的实现细节。
6. 遍历动态数组中的值
假如你想要依次访问动态数组中的每一个元素,那么可以直接遍历其所有元素,而不需要使用索引来一个一个地访问它们。示例8-8展示了如何使用for循环来获得动态数组中每一个i32元素的不可变引用,并将它们打印出来。
// 示例8-8:使用for循环遍历并打印出动态数组中的所有元素
let v = vec![100, 32, 57];
for i in &v {
println!("{}", i);
}我们同样也可以遍历可变的动态数组,获得元素的可变引用,并修改其中的值。示例8-9中的for循环会让动态数组中的所有元素的值增加50。
// 示例8-9:遍历动态数组中所有元素的可变引用
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}为了使用+=运算符来修改可变引用指向的值,我们首先需要使用解引用运算符(*)来获得i绑定的值。我们会在第15章的“使用解引用运算符跳转到指针指向的值”一节中进一步讨论解引用运算符。
7. 使用枚举来存储多个类型的值
在本文开始的时候,我们曾经提到过动态数组只能存储相同类型的值。这个限制可能会带来不小的麻烦,实际工作中总是会碰到需要存储一些不同类型值的情况。
幸运的是,当我们需要在动态数组中存储不同类型的元素时,可以定义并使用枚举来应对这种情况,因为枚举中的所有变体都被定义为了同一种枚举类型。
假设我们希望读取表格中的单元值,这些单元值可能是整数、浮点数或字符串,那么就可以使用枚举的不同变体来存放不同类型的值。
所有的这些枚举变体都会被视作统一的类型:也就是这个枚举类型。接着,我们便可以创建一个持有该枚举类型的动态数组来存放不同类型的值,如示例8-10所示。
// 示例8-10:在动态数组中使用定义的枚举来存储不同类型的值
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];为了计算出元素在堆上使用的存储空间,Rust需要在编译时确定动态数组的类型。使用枚举的另一个好处在于它可以显式地列举出所有可以被放入动态数组的值类型。
假如Rust允许动态数组存储任意类型,那么在对动态数组中的元素进行操作时,就有可能会因为一个或多个不当的类型处理而导致错误。将枚举和match表达式搭配使用意味着,Rust可以在编译时确保所有可能的情形都得到妥当的处理,正如在前文讨论过的那样。
假如你没有办法在编写程序时穷尽所有可能出现在动态数组中的值类型,那么就无法使用枚举。为了解决这一问题,我们需要用到在第17章会介绍的动态trait。
现在,我们已经学会了一些常见的使用动态数组的方法,但请你一定要去看一下标准库中有关Vec<T>的API文档,它包含了Vec<T>所有方法的详细说明。例如,除了push,还有一个pop方法可以移除并返回末尾的元素。接下来,让我们来继续学习下一个集合类型:String!
8. 使用字符串存储UTF-8编码的文本
我们曾经在前面提到过字符串,现在终于可以来深入地讨论它了。刚刚接触Rust的开发者们十分容易在使用字符串时出现错误,这是由3个因素共同作用造成的:
首先,Rust倾向于暴露可能的错误;
其次,字符串是一个超乎许多编程者想象的复杂数据结构;
最后,Rust中的字符串使用了UTF-8编码。
假如你曾经使用过其他编程语言,那么这些因素组合起来也许会让你感到有些困惑。之所以要将字符串放在集合章节中来学习,是因为字符串本身就是基于字节的集合,并通过功能性的方法将字节解析为文本。
本节将会介绍一些常见的基于String的集合类型的操作,比如创建、更新及访问等。我们也会讨论String与其他集合类型不同的地方,比如,尝试通过索引访问String中的字符往往是十分复杂的,这是因为人和计算机对String数据的解释方式不同。
9. 字符串是什么
我们先来定义一下术语字符串的具体含义。Rust在语言核心部分只有一种字符串类型,那就是字符串切片str,它通常以借用的形式(&str)出现。
正如在前文讨论的那样,字符串切片是一些指向存储在别处的UTF-8编码字符串的引用。例如,字符串字面量的数据被存储在程序的二进制文件中,而它们本身也是字符串切片的一种。String类型被定义在了Rust标准库中而没有被内置在语言的核心部分。
当Rust开发者们提到“字符串”时,他们通常指的是String与字符串切片&str这两种类型,而不仅仅只是其中的一种。虽然本节会着重介绍String,但是这两种类型都广泛地被应用于Rust标准库中,并且都采用了UTF-8编码。
Rust的标准库中同时包含了其他一系列的字符串类型,比如OsString、OsStr、CString及CStr。某些第三方库甚至还提供了更多用于存储字符串数据的选择。注意到这些名字全都以String或Str结尾了吗?
这用来表明类型提供的是所有者版本还是借用者版本,正如你之前所看到的String和str类型一样。这些字符串类型可以使用不同的编码,或者不同的内存布局来存储文本。我们不会在本章讨论这些类型,但你可以通过查看它们的API文档来学习如何使用这些字符串,并了解各自最佳的使用场景。
10. 创建一个新的字符串
许多对于Vec<T>可用的操作也同样可用于String,我们可以从new函数开始来创建一个字符串,如示例8-11所示。
// 示例8-11:创建一个新的空字符串
let mut s = String::new();这行代码创建了一个叫作s的空字符串,之后我们可以将数据填入该字符串。但是一般而言,字符串在创建的时候都会有一些初始数据。
对于这种情况,我们可以对那些实现了Display trait的类型调用to_string方法,如同字符串字面量一样。示例8-12中展示了两个例子。
// 示例8-12:使用to_string方法基于字符串字面量创建String
let data = "initial contents";
let s = data.to_string();
// 这个方法同样也可以直接作用于字面量:
let s = "initial contents".to_string();这段代码所创建的字符串会拥有initial contents作为内容。
我们同样也可以使用函数String::from来基于字符串字面量生成String。示例8-13中的代码等价于示例8-12中使用to_string的代码。
// 示例8-13:使用String::from函数基于字符串字面量创建String
let s = String::from("initial contents");由于字符串被如此广泛地使用,因此在它的实现中提供了许多不同的通用API供我们选择。某些函数初看起来也许会有些多余,但是请相信它们自有妙用。在以上的例子中,String::from和to_string实际上完成了相同的工作,你可以根据自己的喜好来选择使用哪种方法。
记住,字符串是基于UTF-8编码的,我们可以将任何合法的数据编码进字符串中,如示例8-14所示。
// 示例8-14:存储在字符串中的不同语言的问候
let hello = String::from("");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("");
let hello = String::from("");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");所有这些问候短语都是合法的String值。
11. 更新字符串
String的大小可以增减,其中的内容也可以修改,正如我们将数据推入其中时Vec<T>内部数据所发生的变化一样。此外,我们还可以方便地使用+运算符或format! 宏来拼接String。
使用push_str或push向字符串中添加内容
我们可以使用push_str方法来向String中添加一段字符串切片,如示例8-15所示。
// 示例8-15:使用push_str方法向String中添加字符串切片
let mut s = String::from("foo");
s.push_str("bar");执行完上面的代码后,s中的字符串会被更新为foobar。由于我们并不需要取得参数的所有权,所以这里的push_str方法只需要接收一个字符串切片作为参数。
你可以想象一下,在示例8-16中,如果s2在拼接至s1后再也无法使用了该是多么不方便。
// 示例8-16:在将字符串切片附加至String后继续使用它
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {}", s2);假如push_str方法取得了s2的所有权,那么我们就无法在最后一行打印出它的值了。好在这些代码如期运行了!
push方法接收单个字符作为参数,并将它添加到String中。示例8-17展示了如何使用push方法向String的尾部添加字符l。
// 示例8-17:使用push方法将一个字符添加到String中
let mut s = String::from("lo");
s.push('l');这段代码执行完毕后,s中的内容会变为lol。
使用+运算符或format! 宏来拼接字符串你也许经常需要在代码中将两个已经存在的字符串组合在一起。一种办法是像示例8-18那样使用+运算符。
// 示例8-18:使用+运算符将两个String合并到一个新的String中
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // 注意这里的s1已经被移动且再也不能被使用了执行完这段代码后,字符串s3中的内容会变为Hello, world!。值得注意的是,我们在加法操作中仅对s2采用了引用,而s1在加法操作之后则不再有效。
产生这一现象的原因与使用+运算符时所调用的方法签名有关。这里的+运算符会调用一个add方法,它的签名看起来像下面一样:
fn add(self, s: &str) -> String {当然,这与标准库中实际的签名有些许差别:在标准库中,add函数使用了泛型来进行定义。此处展示的add函数将泛型替换为了具体的类型,这是我们使用String值调用add时使用的签名。我们将在后文继续讨论泛型。
这个签名应该能够帮助你理解+运算符中的微妙之处。首先,代码中的s2使用了&符号,这意味着我们实际上是将第二个字符串的引用与第一个字符串相加了,正如add函数中的s参数所指明的那样:我们只能将&str与String相加,而不能将两个String相加。
但是等等,&s2的类型是&String,而add函数中的第二个参数的类型则是&str。为什么示例8-18依然能够通过编译呢?我们能够使用&s2来调用add函数的原因在于:编译器可以自动将&String类型的参数强制转换为&str类型。
当我们调用add函数时,Rust使用了一种被称作解引用强制转换的技术,将&s2转换为了&s2[..]。我们将在第15章更加深入地讨论解引用强制转换这一概念。由于add并不会取得函数签名中参数s的所有权,因此变量s2将在执行这一操作后依旧保留一个有效的String值。
其次,我们可以看到add函数签名中的self并没有&标记,所以add函数会取得self的所有权。这也意味着示例8-18中的s1将会被移动至add函数调用中,并在调用后失效。
所以,即便let s3 = s1 +&s2;看起来像是复制两个字符串并创建一个新的字符串,但实际上这条语句会取得s1的所有权,再将s2中的内容复制到其中,最后再将s1的所有权作为结果返回。换句话说,它看起来好像进行了很多复制,但实际上并没有,这种实现要比单纯的复制更加高效。
假如你需要拼接多个字符串,那么使用+运算符可能就会显得十分笨拙了:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;本例中s的内容将是tic-tac-toe。在有这么多+及"字符的情况下,你很难去分析其中的具体实现。对于这种复杂一些的字符串合并,我们可以使用format! 宏:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{}-{}-{}", s1, s2, s3);这段代码同样也会在s中生成tic-tac-toe。format! 宏与println! 宏的工作原理完全相同,不过不同于println! 将结果打印至屏幕,format! 会将结果包含在一个String中返回。这段使用format! 的代码要更加易读,并且不会夺取任何参数的所有权。
12. 字符串索引
在许多编程语言中,往往可以合法地通过索引来引用字符串中每一个单独的字符。但不管怎样,假如你在Rust中尝试使用同样的索引语法去访问String中的内容,则会收到一个错误提示。下面来看一下示例8-19中的这段非法代码。
// 示例8-19:尝试对字符串使用索引语法
let s1 = String::from("hello");
let h = s1[0];这段代码会导致如下错误:
error[E0277]: the trait bound `std::string::String: std::ops::Index<{integer}>` is not satisfied
-->
|
3 | let h = s1[0];
| ^^^^^ the type `std::string::String` cannot be indexed by `{integer}`
|
= help: the trait `std::ops::Index<{integer}>` is not implemented for `std::string::String`这里的错误日志和提示信息说明了其中的缘由:Rust中的字符串并不支持索引。但是为什么不支持呢?为了回答这个问题,我们接着来看一下Rust是如何在内存中存储字符串的。
内部布局
String实际上是一个基于Vec<u8>的封装类型。下面来看一些示例8-14中的UTF-8编码的字符串的例子。首先来看下面这个:
let len = String::from("Hola").len();在这行代码中,len方法将会返回4,这意味着动态数组所存储的字符串Hola占用了4字节。在编码为UTF-8时,每个字符都分别占用1字节。那么,下面这个例子是否也符合这样的规律呢?(注意,这个字符串中的首字母是西里尔字母中的Ze,而不是阿拉伯数字3。)
let len = String::from("Здравствуйте").len();首先来猜一下这个字符串的长度,你给出的答案也许是12。但实际上,Rust返回的结果是24:这就是使用UTF-8编码来存储"Здравствуйте"所需要的字节数,因为这个字符串中的每个Unicode标量值都需要占据2字节。
发现了吧,对字符串中字节的索引并不总是能对应到一个有效的Unicode标量值。为了演示这一行为,让我们来看一看下面这段非法的Rust代码:
let hello = "Здравствуйте";
let answer = &hello[0];这段代码中的answer值会是多少呢?它应该是首字母З吗?当使用UTF-8编码时,З依次使用了208、151两字节空间,所以这里的answer应该是208吧,但208本身却又不是一个合法的字符。
请求字符串中首字母的用户可不会希望获得一个208的返回值,可这又偏偏是Rust在索引0处取到的唯一字节数据。用户想要的结果通常不会是一个字节值,即便这个字符串只由拉丁字母组成:如果我们将&"hello"[0]视作合法的代码,那么它会返回一个字节值104,而不是h。
为了避免返回意想不到的值,以及出现在运行时才会暴露的错误,Rust会直接拒绝编译这段代码,在开发阶段提前杜绝可能的误解。
字节、标量值及字形簇!天呐!
使用UTF-8编码还会引发另外一个问题。在Rust中,我们实际上可以通过3种不同的方式来看待字符串中的数据:字节、标量值和字形簇(最接近人们眼中字母的概念)。
假如我们尝试存入一个使用梵文书写的印度语单词“[插图]”,那么该单词在动态数组中存储的u8值看起来会像下面一样:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,224, 165, 135]这里有18字节,也是计算机最终存储数据的样子。假如我们将它们视作Unicode标量值,也就是Rust中的char类型,那么这些字节看起来会像是:

这里有6个char值,但实际上第四个与第六个并不能算作字母:它们本身没有任何意义,只是作为音标存在。最后,假如我们将它们视作字形簇,就会得到通常意义上的印度语字符:
![]()
Rust中提供了不同的方式来解析存储在计算机中的字符串数据,以便于程序员们自行选择所需的解释方式,而不用关心具体的语言类型。
Rust不允许我们通过索引来获得String中的字符还有最后一个原因,那就是索引操作的复杂度往往会被预期为常数时间(O(1))。但在String中,我们无法保障这种做法的性能,因为Rust必须要遍历从头至索引位置的整个内容来确定究竟有多少合法的字符存在。
13. 字符串切片
尝试通过索引引用字符串通常是一个坏主意,因为字符串索引操作应当返回的类型是不明确的:究竟应该是字节,还是字符,或是字形簇,甚至是字符串切片呢?
因此,如果真的想要使用索引来创建字符串切片,Rust会要求你做出更加明确的标记。为了明确表明需要一个字符串切片,你需要在索引的[]中填写范围来指定所需的字节内容,而不是在[]中使用单个数字进行索引:
let hello = "Здравствуйте";
let s = &hello[0..4];在这段代码中,s将会是一个包含了字符串前4字节的&str。前面曾提到过,这里的每个字符都会占据2字节,这也意味着s中的内容将是Зд。
假如我们在这里尝试使用&hello[0..1]会发生什么呢?答案是,Rust会如同我们在动态数组中使用非法索引时一样,在运行时发生panic。
thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`',
src/libcore/str/mod.rs:2188:4切记要小心谨慎地使用范围语法创建字符串切片,因为错误的指令会导致程序崩溃。
14. 遍历字符串的方法
幸运的是,还有其他访问字符串中元素的方法。
假如你想要对每一个Unicode标量值都进行处理,那么最好的办法就是使用chars方法。针对字符串“![]() ”调用chars会分别返回6个类型为char的值,接着就可以遍历这个结果来访问每个元素了:
”调用chars会分别返回6个类型为char的值,接着就可以遍历这个结果来访问每个元素了:
for c in "".chars() {
println!("{}", c);
}这段代码的输出如下所示:

而bytes方法则会依次返回每个原始字节,这在某些场景下可能会有用:
for b in "".bytes() {
println!("{}", b);
}这段代码会打印出组成这个String的18个字节值:
224
164
// --略--
165
135但是请记住,合法的Unicode标量值可能会需要占用1字节以上的空间。
从字符串中获取字形簇相对复杂一些,所以标准库中也没有提供这个功能。如果你有这方面的需求,那么可以在crates.io上获取相关的开源库。
15. 字符串的确没那么简单
总而言之,字符串确实是挺复杂的。不同的编程语言会做出不同的设计抉择,来确定将何种程度的复杂性展现给程序员。Rust选择了将正确的String数据处理方法作为所有Rust程序的默认行为,这也就意味着程序员需要提前理解UTF-8数据的处理流程。
与某些编程语言相比,这一设计暴露了字符串中更多的复杂性,但它也避免了我们在开发周期临近结束时再去处理那些涉及非ASCII字符的错误。
下面学习的这个集合要稍微简单一些,它就是哈希映射!
16. 在哈希映射中存储键值对
我们将要学习的最后一个集合类型就是哈希映射:HashMap<K, V>,它存储了从K类型键到V类型值之间的映射关系。哈希映射在内部实现中使用了哈希函数,这同时决定了它在内存中存储键值对的方式。
许多编程语言都支持这种类型的数据结构,只是使用了不同的名字,例如:哈希(hash)、映射(map)、对象(object)、哈希表(hash table)、字典(dictionary)或关联数组(associative array)等,这只是其中的一部分而已。
当你不仅仅满足于使用索引—就像是动态数组那样,而需要使用某些特定的类型作为键来搜索数据时,哈希映射就会显得特别有用。例如,在一个游戏中,你可以将团队的名字作为键,将团队获得的分数作为值,并将所有队伍的分数存放在哈希映射中。
随后只要给出一个队伍的名称,你就可以获得当前的分数值。我们会在本节介绍一些哈希映射的常用API,但是,此处无法覆盖标准库为HashMap<K, V>定义的全部有趣的功能。通常,你可以通过查阅标准库文档来获得更多信息。
17. 创建一个新的哈希映射
你可以使用new来创建一个空哈希映射,并通过insert方法来添加元素。在示例8-20中,我们记录了两支队伍的分数,它们分别被称作蓝队和黄队。蓝队的起始分数为10分,而黄队的起始分数为50分。
// 示例8-20:创建一个新的哈希映射并插入一些键值对
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);注意,我们首先需要使用use将HashMap从标准库的集合部分引入当前作用域。由于哈希映射的使用频率相比于本章介绍的其他两个集合低一些,所以它没有被包含在预导入模块内。
标准库对哈希映射的支持也不如另外两个集合,例如它没有提供一个可以用于构建哈希映射的内置宏。和动态数组一样,哈希映射也将其数据存储在堆上。上面例子中的HashMap拥有类型为String的键,以及类型为i32的值。
依然和动态数组一样,哈希映射也是同质的:它要求所有的键必须拥有相同的类型,所有的值也必须拥有相同的类型。另外一个构建哈希映射的方法是,在一个由键值对组成的元组动态数组上使用collect方法。
这里的collect方法可以将数据收集到很多数据结构中,这些数据结构也包括HashMap。例如,假设我们在两个不同的动态数组里分别存储了队伍的名字和分数,那么我们就可以使用zip方法来创建一个元组的数组,其中第一个元组由"Blue"与10组成,以此类推。
接着,我们还可以使用collect方法来将动态数组转换为哈希映射,如示例8-21所示。
// 示例8-21:使用队伍列表和分数列表创建哈希映射
use std::collections::HashMap;
let teams = vec![String::from("Blue"), String::from("Yellow")];
let initial_scores = vec![10, 50];
let scores: HashMap<_, _> =
teams.iter().zip(initial_scores.iter()).collect();这里的类型标记HashMap<_, _>不能被省略,因为collect可以作用于许多不同的数据结构,如果不指明类型的话,Rust就无法知道我们具体想要的类型。
但是对于键值的类型参数,我们则使用了下画线占位,因为Rust能够根据动态数组中的数据类型来推导出哈希映射所包含的类型。
18. 哈希映射与所有权
对于那些实现了Copy trait的类型,例如i32,它们的值会被简单地复制到哈希映射中。而对于String这种持有所有权的值,其值将会转移且所有权会转移给哈希映射,如示例8-22所示。
// 示例8-22:一旦键值对被插入,其所有权就会转移给哈希映射
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// filed_name和field_value从这一刻开始失效,若尝试使用它们则会导致编译错误!在调用insert方法后,field_name和field_value变量被移动到哈希映射中,我们再也没有办法使用这两个变量了。
假如我们只是将值的引用插入哈希映射,那么这些值是不会被移动到哈希映射中的。这些引用所指向的值必须要保证,在哈希映射有效时自己也是有效的。我们会在第10章的“使用生命周期保证引用的有效性”一节中详细地讨论这个问题。
19. 访问哈希映射中的值
我们可以通过将键传入get方法来获得哈希映射中的值,如示例8-23所示。
// 示例8-23:访问存储在哈希映射中的蓝队分数
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name);上面这段代码中的score将会是与蓝队相关联的值,也就是Some(&10)。因为get返回的是一个Option<&V>,所以这里的结果被封装到了Some中;假如这个哈希映射中没有键所对应的值,那么get就会返回None。接下来,程序需要使用我们在前文讨论过的方法来处理这个Option。
类似于动态数组,我们同样可以使用一个for循环来遍历哈希映射中所有的键值对:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (key, value) in &scores {
println!("{}: {}", key, value);
}这段代码会将每个键值对以不特定的顺序打印出来:
Yellow: 50
Blue: 1020. 更新哈希映射
尽管键值对的数量是可以增长的,但是在任意时刻,每个键都只能对应一个值。当你想要修改哈希映射中的数据时,你必须要处理某些键已经被关联到值的情况。你可以完全忽略旧值,并用新值去替换它。
你也可以保留旧值,只在键没有对应值时添加新值。或者,你还可以将新值与旧值合并到一起。让我们来看一看应该如何分别处理这些情况!
覆盖旧值
当我们将一个键值对插入哈希映射后,接着使用同样的键并配以不同的值来继续插入,之前的键所关联的值就会被替换掉。即便示例8-24中的代码调用了两次insert,这里的哈希映射也依然只会包含一个键值对,因为我们插入值时所用的键是一样的。
// 示例8-24:替换使用特定键存储的值
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{:?}", scores);原来的值10已经被覆盖掉了,这段代码会打印出{"Blue": 25}。
只在键没有对应值时插入数据
在实际工作中,我们常常需要检测一个键是否存在对应值,如果不存在,则为它插入一个值。哈希映射中提供了一个被称为entry的专用API来处理这种情形,它接收我们想要检测的键作为参数,并返回一个叫作Entry的枚举作为结果。
这个枚举指明了键所对应的值是否存在。比如,我们想要分别检查黄队、蓝队是否拥有一个关联的分数值,如果该分数值不存在,就将50作为初始值插入。使用entry API的代码如示例8-25所示。
// 示例8-25:通过使用entry方法在键不存在对应值时插入数据
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{:?}", scores);Entry的or_insert方法被定义为返回一个Entry键所指向值的可变引用,假如这个值不存在,就将参数作为新值插入哈希映射中,并把这个新值的可变引用返回。
使用这个功能要比我们自己编写逻辑代码更加简单,使代码更加整洁,另外也可以与借用检查器结合得更好。运行示例8-25中的代码将会打印出{"Yellow": 50, "Blue": 10}。
由于黄队的比分还不存在,所以第一个对entry的调用会将分数50插入哈希映射中;而由于蓝队已经存储了比分10,所以第二个对entry的调用不会改变哈希映射。
基于旧值来更新值
哈希映射的另外一个常见用法是查找某个键所对应的值,并基于这个值来进行更新。比如,示例8-26中的代码用于计算一段文本中每个单词所出现的次数。
我们使用了一个以单词作为键的哈希映射来记录它们所出现的次数。在遍历的过程中,假如出现了一个新的单词,我们就先将值0插入哈希映射中。
// 示例8-26:使用哈希映射来存储并计算单词出现的次数
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{:?}", map);运行这段代码会输出{"world": 2, "hello": 1, "wonderful": 1}。代码中的方法or_insert实际上为我们传入的键返回了一个指向关联值的可变引用(&mut V)。
这个可变引用进而被存储到变量count上,为了对这个值进行赋值操作,我们必须首先使用星号(*)来对count进行解引用。由于这个可变引用会在for循环的结尾处离开作用域,所以我们在代码中的所有修改都是安全且满足借用规则的。
21. 哈希函数
为了提供抵御拒绝服务攻击(DoS,Denial of Service)的能力,HashMap默认使用了一个在密码学上安全的哈希函数。这确实不是最快的哈希算法,不过为了更高的安全性付出一些性能代价通常是值得的。
假如你在对代码进行性能分析的过程中,发现默认哈希函数成为了你的性能热点并导致性能受损,你也可以通过指定不同的哈希计算工具来使用其他函数。这里的哈希计算工具特指实现了BuildHasher trait的类型。
我们会在后文讨论trait,以及如何实现它们。你并不一定非要从头实现自己的哈希工具,Rust开发者们已经在crates.io上分享了许多基于不同哈希算法的开源项目。
22. 本篇文章总结
动态数组、字符串及哈希映射为我们提供了很多用于存储、访问或修改数据的功能,你可以非常方便地将它们应用到自己的程序中。这里给出了一些小问题,你可以尝试独立解决它们来练习在本章中学到的知识:
💗 给定一组整数,使用动态数组来计算该组整数中的平均数、中位数(对数组进行排序后位于中间的值)及众数(出现次数最多的值;哈希映射可以在这里帮上忙)。
💗 将给定字符串转换为Pig Latin格式。在这个格式中,每个单词的第一个辅音字母会被移动到单词的结尾并增加“ay”后缀,例如“first”就会变为“irst-fay”。元音字母开头的单词则需要在结尾拼接上“hay”(例如,“apple”就会变为“apple-hay”)。要牢记我们讨论的关于UTF-8编码的内容!
💗 使用哈希映射和动态数组来创建一个添加雇员名字到公司部门的文本接口。例如,“添加Sally 至项目部门”或“添加Amir至销售部门”。除此之外,该文本接口还应该允许用户获得某个部门所有员工或公司中所有部门员工的列表,列表按照字母顺序进行排序。
这里有个小提示:标准库中关于动态数组、字符串和哈希映射的API文档会有助于你解决这些问题!
我们已经开始接触到一些可能会导致操作失败的复杂程序了,现在正是讨论如何进行错误处理的绝佳时机。让我们继续学习下一篇吧!