Vue 模板编译原理解析
模板编译整体流程
首先我们看一下什么是编译?
所谓编译(Compile),指的是将语言 A 翻译成语言 B,语言 A 就被称之为源码(source code),语言 B 就被称之为目标代码(target code),这个事情谁来做?编译器来做。编译器你也不用想得那么神秘,就是一段程序而已。
完整的编译流程一般包含以下几个步骤:
- 词法分析:就是负责将源码拆解成一系列的词法单元(token)
- 语法分析:将上一步所得到的词法单元组成一颗抽象语法树
- 语义分析:主要就是根据上一步所得到的抽象语法树,进行深度遍历,检查语法规则是否符合要求
- 中间代码生成
- 优化
- 目标代码生成

上面的步骤,如果从大的方面去分,那么可以分为 编译前端 和 编译后端。
- 编译前端:所谓编译前端,它通常是和目标平台无关的,仅仅是负责分析源代码
- 编译后端:通常与目标平台有关系
回到 Vue,在 Vue 的模板里面就涉及到了编译的操作:
<template>
<div>
<h1 :id="someId">Hello</h1>
</div>
</template>
编译后的结果是什么?编译后的结果就是渲染函数
function render() {
return h("div", [h("h1", { id: someId }, "Hello")]);
}
注意这里,整个编译过程并非一蹴而就,而是经历了一个又一个的步骤,一点一点转换而来的。
整体来讲,整个编译过程如下图:

在编译器内部,实际上又分为了三个东西:
- 解析器:负责将模板解析为对应的模板抽象语法树
- 转换器:负责将上一步所得到模板抽象语法树转为 JS 抽象语法树
- 生成器:负责将上一步所得到的 JS 抽象语法树生成目标代码
通过上面的图,我们还会发现一个很重要的东西,那就是 AST 扮演了非常重要的角色。
AST
什么是 AST 呢?
所谓 AST,英语全称 Abstract Syntax Tree,翻译成中文,就是抽象语法树。
什么又叫抽象语法树?这里我们可以采用分词方式。分为 抽象、语法、树。
先来说树。树的话是数据结构里面的一种,用于表示层次关系的集合。树的基本思想将数据组织成分层结构,每个节点有一个父节点和零个或者多个子节点。
例如:
A
/ \
B C
/ \ \
D E F
上面就是一个树结构,上面的树是一个完全二叉树。
树的结构的这种特点就让它在搜索、排序、存储以及表示层次这些需求方面有广泛的应用,常见的应用场景文档对象模型(DOM)、路由算法、数据库索引等,在这里,我们的抽象语法树,很明显也是一种树结构。
接下来语法树就非常好理解。
var a = 42;
var b = 5;
function addA(d) {
return a + d;
}
var c = addA(2) + b;
上面的代码,对于 JS 引擎而言,其实就是一段字符串:
"var a = 42;var b = 5;function addA(d){return a + d;}var c = addA(2) + b;";
JS 引擎首先第一步是遍历上面的字符串,将源码字符串拆解为一个一个的词法单元(词法分析),词法单元又被称之为 token,它是最小的词法单元,词法单元一般就是关键字、操作符、数字、运算符。
例如上面的代码,在进行了词法分析后,会得到如下的 token:
Keyword(var) Identifier(a) Punctuator(=) Numeric(42) Punctuator(;) Keyword(var) Identifier(b) Punctuator(=) Numeric(5) Punctuator(;) Keyword(function) Identifier(addA) Punctuator(() Identifier(d) Punctuator()) Punctuator({) Keyword(return) Identifier(a) Punctuator(+) Identifier(d) Punctuator(;) Punctuator(}) Keyword(var) Identifier(c) Punctuator(=) Identifier(addA) Punctuator(() Numeric(2) Punctuator()) Punctuator(+) Identifier(b) Punctuator(;)
接下来下一步,就是根据这些 token,形成一颗树结构(语法分析):

可以在 https://www.jointjs.com/demos/abstract-syntax-tree 或者 https://astexplorer.net/ 看到代码的抽象语法树。
目前我们已经搞懂什么是语法树。
为什么叫做 抽象 语法树 ?
**抽象**在计算机科学里面,是一种非常重要的思想。这里的抽象和现实生活中的抽象的说法是有区别。现实生活中的抽象往往是指“模糊、含糊不清、难以理解”,例如“他说的话很抽象”。
计算机科学里面的抽象,指的是将关键部分从细节中分离出来,忽略不必要的细节,专注问题的关键方面。
例如面向对象编程里面,类其实就是对对象的一种抽象,类描述了对象的关键信息(有哪些属性,有哪些方法),再举一个例子,比如接口,在定义接口的时候,只会规定这个接口里面有哪些方法,不需要关心内部具体的实现。
回到我们的抽象语法树,在形成树结构的时候,同样会忽略一些不重要的,非关键的信息(比如空格、换行符),只会将关键的部分(关键字、标志符、运算符)生成到树结构里面。
理解 AST 非常重要,在开发中但凡涉及到 转换 的场景,都是基于抽象语法树来运作的。
- Typescript

- Babel
- Prettier
- ESLint
解析器
解析器的核心作用是负责将模板解析为 AST
<template>
<div>
<h1 :id="someId">Hello</h1>
</div>
</template>
对于解析器来讲,就是一段字符串:
'<template><div><h1 :id="someId">Hello</h1></div></template>';
接下来我们的工作重点,就是解析这段字符串。
这里涉及到了 有限状态机 的概念。
FSM
英语全称 Finite State Machine,翻译成中文就是有限状态机,它首先会定义一组状态,然后会定义状态之间进行转移的事件。
来看一个具体的例子:
"<p>Vue</p>";
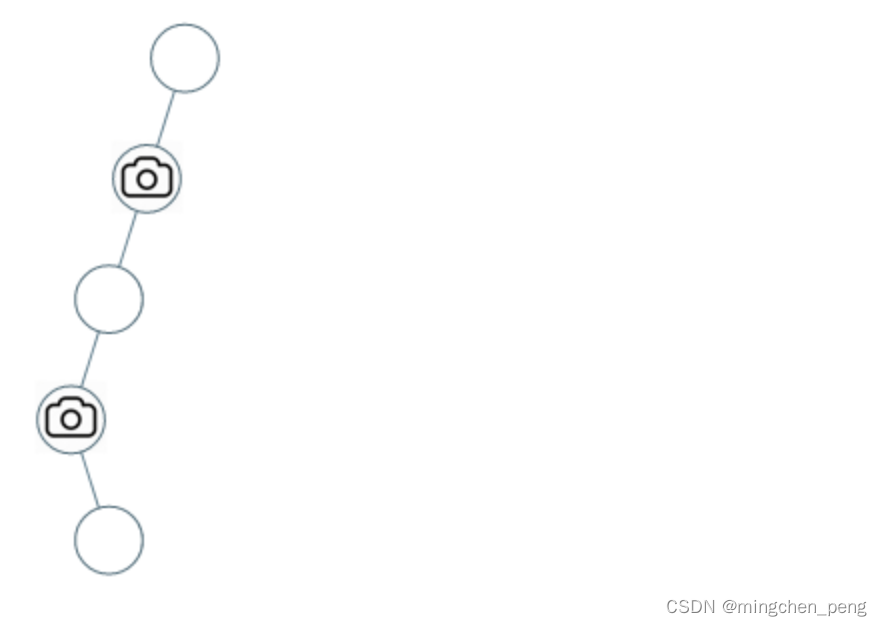
那么整个状态的迁移过程如下:
- 状态机一开始处于 初始状态。
- 在初始状态下,读取字符串的第一个字符 < ,然后状态机的状态就会更新为 标签开始状态。
- 读取下一个字符 p,由于 p 是字母,那么状态机的状态就会更新为 标签名称开始状态。
- 读取下一个字符 >,状态机会回归为 初始状态。
- 读取下一个字符 V,状态机的状态为 文本状态
- 下一个字符 u,状态机的状态为 文本状态
- 下一个字符 e,状态机的状态为 文本状态
- 读取下一个字符 < ,此时状态机会进入到 标签开始状态
- 读取下一个字符 / ,状态机的状态会变为 标签结束状态
- 读取下一个字符 p,状态机的状态为 标签名称结束状态
- 最后是 > ,状态机重新回到 初始状态
具体如下图所示:

实际上,我们最熟悉的 HTML,浏览器引擎在内部进行解析的时候,也是通过有限状态机进行解析的。
接下来我们落地到代码,大致就如下:
const tempalte = "<p>Vue</p>";
// 首先需要定义一些状态
const state = {
initial: 1, // 初始状态
tagOpen: 2, // 标签开始状态
tagName: 3, // 标签名称开始状态
text: 4, // 文本状态
tagEnd: 5, // 标签结束状态
tagEndName: 6, // 标签名称结束状态
};
function tokenize(str) {
let currentState = state.initial; // 一开始是初始状态
const chars = []; // 用于缓存字符
const tokens = []; // 用于存储最终分析出来的 tokens,并且作为函数的返回值
while (str) {
const char = str[0]; // 先取出第一个字符
switch (currentState) {
case state.initial: {
// ...
str = str.slice(1); // 消费一个字符
}
case state.tagOpen: {
// ...
}
}
}
return tokens;
}
构造 AST
到目前为止,我们只是将模板解析为了一个一个的 token,任务只完成了一半,接下来需要根据上一步所得到的 tokens 来构造 AST 树。
构造 AST 的过程其实就是就是对 tokens 列表进行扫描的过程,从列表的第一个 token,按照顺序进行扫描,直到列表中所有 token 都被处理完毕。
在这个过程中,我们需要维护一个栈(这个也是一种数据结构),这个栈的作用主要使用用于维护元素间的父子关系,每遇到一个开始标签的节点,就会构造一个 Element 类型的 AST 节点,压入到栈里面。
来看一个具体的例子:
"<div><p>Vue</p><p>React</p></div>";
上面的字符串,对应的解析出来的 tokens 为:
[
{ type: "tag", name: "div" },
{ type: "tag", name: "p" },
{ type: "text", content: "Vue" },
{ type: "tagEnd", name: "p" },
{ type: "tag", name: "p" },
{ type: "text", content: "React" },
{ type: "tagEnd", name: "p" },
{ type: "tagEnd", name: "div" },
];
接下来我们就需要扫描这个 tokens
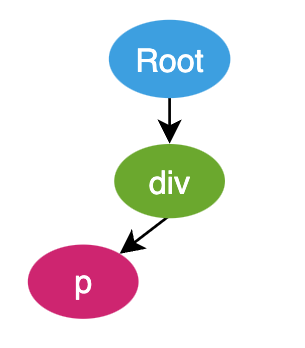
- 一开始会有一个栈,这个栈里面只有 Root 节点 [ Root ]
- 首先是 div tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div ],div 就作为 Root 的子节点
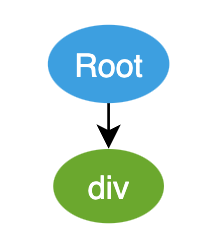
- 接下来是 p tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div, p ],p 作为 div 的子节点。
- 接下来是 Vue text 文本节点,此时就会创建一个 Text 类型的 AST 节点,作为 p 的子节点
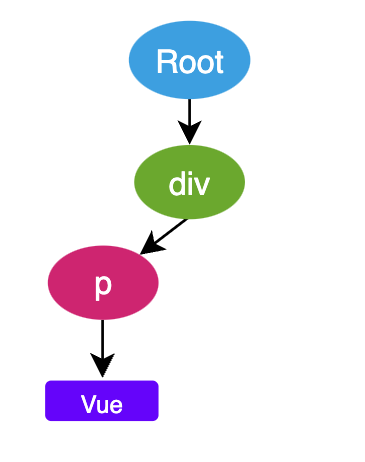
- 接下来是 p tagEnd,发现这是一个结束标签,此时就会将 p 出栈,当前的栈为 [ Root, div ]
- 接下来是 p tag,创建一个 Element 类型的 AST 节点,压栈,当前的栈为 [ Root, div, p ],p 作为 div 的子节点。

- 接下来是 React text 文本节点,此时就会创建一个 Text 类型的 AST 节点,作为 p 的子节点

- 接下来是 p tagEnd,发现这是一个结束标签,此时就会将 p 出栈,当前的栈为 [ Root, div ]
- 接下来是 div tagEnd,发现这是一个结束标签,此时就会将 div 出栈,当前的栈为 [ Root ]
最后落地到代码:
function parse(str) {
// 首先对模板进行 token 解析,得到对应的 tokens 数组
const tokens = tokenize(str);
// 创建 Root 根 AST 节点的
const root = {
type: "Root",
children: [],
};
// 创建 elementStack 栈,一开始只有 Root 根节点
const elementStack = [root];
// 直到 tokens 数组被全部扫描完才会推出
while (tokens.length) {
// 获取当前栈顶点作为父节点
const parent = elementStack[elementStack.length - 1];
// 当前扫描的 token
const t = tokens[0];
// 根据 token 的不同类型,创建不同的 AST 节点
switch (t.type) {
case "tag":
// 创建对应的 Element 类型的 AST 节点
const elementNode = {
type: "Element",
tag: t.name,
children: [],
};
// 将其添加到父级节点的 children 中
parent.children.push(elementNode);
// 将当前节点压入栈
elementStack.push(elementNode);
break;
case "text":
// 创建文本类型的 AST 节点
const textNode = {
type: "Text",
content: t.content,
};
// 将其添加到父级节点的 children 中
parent.children.push(textNode);
break;
case "tagEnd":
// 遇到结束标签,将当前栈顶的节点弹出
elementStack.pop();
break;
}
// 消费已经扫描过的 token
tokens.shift();
}
return root;
}
通过上面的代码,最终就会得到如下的 AST 树结构:
{
"type": "Root",
"children": [
{
"type": "Element",
"tag": "div",
"children": [
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Vue"
}
]
},
{
"type": "Element",
"tag": "p",
"children": [
{
"type": "Text",
"content": "Template"
}
]
}
]
}
]
}
到目前为止,我们整个解析器的任务就完成了。
转换器
主要的目的是将模板的 AST 转换为 JS 的 AST,整个模板的编译过程如下:
// Vue 的模板编译器
function compile(template) {
// 1. 得到模板的 AST
const ast = parse(template);
// 2. 将模板 AST 转为 JS AST
transform(ast);
}
整个转换实际上可以分为两个大的部分:
- 模板 AST 的遍历以及针对节点的操作能力
- 生成 JavaScript AST
模板 AST 的遍历以及针对节点的操作能力
步骤一
先书写一个简单的工具方法,方便我们查看模板 AST 中节点的信息
// 打印 AST 节点
function dump(node, indent = 0) {
const type = node.type;
// 根据节点类型来构建描述信息
const desc =
node.type === "Root"
? ""
: node.type === "Element"
? node.tag
: node.content;
// 接下来进行一个打印
console.log(`${"-".repeat(indent)}${type}: ${desc}`);
// 如果有子节点,递归打印
if (node.children) {
node.children.forEach((child) => dump(child, indent + 2));
}
}
步骤二
接下来我们就需要遍历整棵模板的 AST 树,在遍历的时候就可以针对一些节点动一些手脚,例如我们要将所有的 p 修改为 h1
// 该方法就是用于遍历 AST 节点的
function traverseNode(ast) {
// 获取当前节点
const currentNode = ast;
// 接下来我们就可以针对拿到的节点做一些事情
if (currentNode.type === "Element" && currentNode.tag === "p") {
// 如果是 p 标签,就将其转换为 h1 标签
currentNode.tag = "h1";
}
// 如果有子节点,递归遍历
const children = currentNode.children;
if (children) {
// 如果有子节点,那么我们就遍历
for (let i = 0; i < children.length; i++) {
traverseNode(children[i]);
}
}
}
// 负责将模板 AST 转换为 JavaScript AST
function transform(ast) {
traverseNode(ast);
console.log(dump(ast));
}
在上面的代码中,transform 是最终负责转换的方法,转换的核心逻辑是放在 transform 里面的。transform 里面决定了我整个转换操作,第一步做什么,第二步做什么。
traverseNode 负责遍历整个模板的 AST,并且在遍历的途中,我们还能够进行一些修改。
步骤三
目前为止,这个 traverseNode 方法既负责了遍历 AST 节点,又负责了转换的工作,假设我们有一个新的需求,例如要将文本全部转为大写,那么我们就必须要去修改 traverseNode
// 该方法就是用于遍历 AST 节点的
function traverseNode(ast) {
// 获取当前节点
const currentNode = ast;
// 接下来我们就可以针对拿到的节点做一些事情
if (currentNode.type === "Element" && currentNode.tag === "p") {
// 如果是 p 标签,就将其转换为 h1 标签
currentNode.tag = "h1";
}
if (currentNode.type === "Text") {
// 如果是文本节点,就将其内容转换为大写
currentNode.content = currentNode.content.toUpperCase();
}
// 如果有子节点,递归遍历
const children = currentNode.children;
if (children) {
// 如果有子节点,那么我们就遍历
for (let i = 0; i < children.length; i++) {
traverseNode(children[i]);
}
}
}
这个时候,我们就需要让 遍历 和 转换 进行一个解耦。
可以在 transform 里面维护一个上下文对象。
什么是上下文 ?
**上下文是一个非常非常非常重要且常见的概念,所谓上下文,指的是一个环境信息。**我们在执行代码的时候,我们是需要一些数据的,那你的这些个数据从哪里去获取?就是从上下文环境中去获取。
实际上在现实生活中也有类似的上下文环境的场景,比如你在厨房做饭,整个厨房就是你做饭的环境,厨房里面有你要做饭的时候用到的各种厨具,比如菜刀、案板、锅、碗,灶台,这些工具整体构成了一个环境(上下文环境),当你做饭的时候要用到某一样工具,直接从这个环境中去获取。

上下文在很多地方都很常见:
- React 中可以使用 React.createContext 创建一个上下文,其他组件可以访问该上下文里面的数据。
- Vue 里面也有类似的概念,provide/inject 被称之为依赖注入,本质上也是提供了一个上下文环境。
- Koa 里面的中间件接收一个 context 参数,本质上也是一个上下文对象
- 还有就是我们最最最熟悉的 JS 里面的执行上下文。
接下来修改 transform,在内部维护一个 context 上下文对象:
const context = {
currentNode: null, // 用于存储当前正在转换的节点
childIndex: 0, // 存储当前正在转换的子节点在父节点的 children 数组中的索引
parent: null, // 存储当前正在转换的节点的父节点
nodeTransforms: [transformElement, transformText], // 这里面会放置各种转换函数
};
步骤四
接下来我们可以继续完善 context 这个上下文对象,可以添加一些方法,例如替换节点的方法以及删除节点的方法,如下:
const context = {
currentNode: null, // 用于存储当前正在转换的节点
childIndex: 0, // 存储当前正在转换的子节点在父节点的 children 数组中的索引
parent: null, // 存储当前正在转换的节点的父节点
// 替换节点的方法
replaceNode(node) {
context.parent.children[context.childIndex] = node;
context.currentNode = node;
},
// 删除节点的方法
removeNode() {
if (context.parent) {
context.parent.children.splice(context.childIndex, 1);
context.currentNode = null;
}
},
nodeTransforms: [transformElement, transformText], // 这里面会放置各种转换函数
};
步骤五
最后我们还需要解决一个问题,那就是节点处理的次数问题。
目前我们使用的是深度优先遍历的方式来处理的节点。这种工作流方式有一个问题,在转换 AST 节点的过程中,往往需要根据子节点的情况来决定当前节点如何进行转换,这就要求父节点的转换操作必须等到子节点完毕后在执行。
这里我们可以对转换函数进行一个改造,让它返回一个方法,这个方法就是之后要再次处理的回调方法。
function transformText(node, context) {
// ...
// 返回一个回掉方法,这个回掉方法是在退出阶段执行的
return () => {
console.log("可以再次处理节点:", node.type, node.tag || node.content);
};
}
之后最核心的是要对 traverseNode 方法进行一个改造:
// 该方法就是用于遍历 AST 节点的
function traverseNode(ast, context) {
console.log("处理节点:", ast.type, ast.tag || ast.content);
// 获取当前节点
context.currentNode = ast;
// 1. 新增一个在退出节点要执行的回调函数的数组
const exitFns = [];
// 拿到转换方法的数组
const transforms = context.nodeTransforms;
// 遍历数组中的方法,依次执行
for (let i = 0; i < transforms.length; i++) {
const onExit = transforms[i](context.currentNode, context);
if (onExit) {
exitFns.push(onExit);
}
// 如果执行的是删除操作,那么我们需要检查当前节点是否已经被删除了
if (!context.currentNode) return;
}
// 如果有子节点,递归遍历
const children = context.currentNode.children;
if (children) {
// 如果有子节点,那么我们就遍历
for (let i = 0; i < children.length; i++) {
// 在进行递归遍历之前,也需要更新上下文里面的 parent 以及 childIndex
context.parent = context.currentNode;
context.childIndex = i;
traverseNode(children[i], context);
}
}
// 3. 在节点处理的最后节点,执行缓存在 exitFns 数组中的所有回调函数
let i = exitFns.length;
while (i--) {
exitFns[i]();
}
}
通过这种方式,我们就可以在节点进入和退出的时候做处理。这个思想在很多地方也很常见:
- React 中 beginWork 和 completeWork
- Koa 中间件采用的洋葱模型
生成 JavaScript AST
我们要对整个模板的 AST 进行转换,转换为 JS AST。
我们目前的代码已经有了遍历模板 AST,并且针对不同的节点,做不同操作的能力。
我们首先需要知道 JS AST 长什么样子:
function render() {
return null;
}
上面的代码,所对应的 JS AST 如下图所示:

这里有几个比较关键的部分:
- id:对应的是我函数的名称,类型为 Identifier
- params:对应的是函数的参数,是一个数组的形式来表示的
- body:对应的是函数体,由于函数体是可以有多条语句的,因此也是一个数组
我们仿造上面的设计,自己设计一个基本的数据结构来描述函数声明语句:
const FunctionDeclNode = {
type: "FunctionDecl", // 表示该节点是一个函数声明
id: {
type: "Identifier",
name: "render", // 函数的名称
},
params: [],
body: [
{
type: "ReturnStatement",
return: null,
},
],
};
回到我们上面的模板:
<div>
<p>Vue</p>
<p>React</p>
</div>
转换出来的渲染函数:
function render() {
return h("div", [h("p", "Vue"), h("p", "React")]);
}
根据渲染函数所对应的 AST 去分析对应的节点
下面说一下几个比较重要的节点:
h 函数对应的节点:
const callExp = {
type: "CallExpression",
callee: {
type: "Identifier",
name: "h",
},
};
字符串所对应的节点:
const Str = {
type: "StringLiteral",
value: "div",
};
数组对应的节点:
const Arr = {
type: "ArrayExpression",
elements: [],
};
分析完节点之后,那么我们上面的那个 render 函数所对应的 AST 就应该长下面的样子:
{
"type": "FunctionDecl",
"id": {
"type": "Identifier",
"name": "render"
},
"params": [],
"body": [
{
"type": "ReturnStatement",
"return": {
"type": "CallExpression",
"callee": {"type": "Identifier", "name": "h"},
"arguments": [
{ "type": "StringLiteral", "value": "div"},
{"type": "ArrayExpression","elements": [
{
"type": "CallExpression",
"callee": {"type": "Identifier", "name": "h"},
"arguments": [
{"type": "StringLiteral", "value": "p"},
{"type": "StringLiteral", "value": "Vue"}
]
},
{
"type": "CallExpression",
"callee": {"type": "Identifier", "name": "h"},
"arguments": [
{"type": "StringLiteral", "value": "p"},
{"type": "StringLiteral", "value": "React"}
]
}
]
}
]
}
}
]
}
分析完结构之后,下一步我们就是书写对应的转换函数。在转换函数之前,我们需要一些辅助函数,这些辅助函数用于帮助我们创建 JS AST 的节点:
function createStringLiteral(value) {
return {
type: "StringLiteral",
value,
};
}
function createIdentifier(name) {
return {
type: "Identifier",
name,
};
}
function createArrayExpression(elements) {
return {
type: "ArrayExpression",
elements,
};
}
function createCallExpression(callee, args) {
return {
type: "CallExpression",
callee: createIdentifier(callee),
arguments: args,
};
}
接下来,我们就需要去修改我们的转换函数,一个有三个转换函数,分别是:
- transformText
function transformText(node, context) {
if (node.type !== "Text") return;
node.jsNode = createStringLiteral(node.content);
}
- transformElement
// 接下来我们就可以书写一些转换函数
// 将之前写在 traverseNode 里面的各种转换逻辑抽离出来了
function transformElement(node) {
// 对外部返回一个函数,这个函数就是在退出节点时要执行的回调函数
return () => {
if (node.type !== "Element") return;
// 1. 创建 h 函数的 AST 节点
const callExp = createCallExpression("h", [createStringLiteral(node.tag)]);
// 2. 处理 h 函数里面的参数
node.children.length === 1
? // 如果之后一个子节点,那么直接将子节点的 jsNode 作为参数即可
callExp.arguments.push(node.children[0].jsNode)
: // 如果是多个子节点,那么就需要将子节点的 jsNode 作为数组传入
callExp.arguments.push(
createArrayExpression(node.children.map((child) => child.jsNode))
);
};
}
- transformRoot
// 最后再写一个转换函数,负责转换 Root 根节点
function transformRoot(node) {
return () => {
if (node.type !== "Root") return;
// 生成最外层的节点
const vnodeJSAST = node.children[0].jsNode;
node.jsNode = {
type: "FunctionDecl",
id: {
type: "Identifier",
name: "render",
},
params: [],
body: [
{
type: "ReturnStatement",
return: vnodeJSAST,
},
],
};
};
}
最后在 transform 中使用这三个转换函数
生成器
整理一下思绪,哪怕你前面都没有听懂,但是你需要知道我们走到哪一步了。
目前我们已经有 js ast,只剩下最后一步,革命就成功了。
遍历这个生成的 js ast,转为具体的渲染函数
function compile(template) {
// 1. 得到模板的 AST
const ast = parse(template);
// 2. 将模板 AST 转为 JS AST
transform(ast);
// 3. 代码生成
const code = genrate(ast.jsNode);
return code;
}
和转换器一样,我们在生成器内部也需要维护一个上下文对象,为我们提供一些辅助函数和必要的信息:
// 和上一步转换器非常相似,我们也需要一个上下文对象
const context = {
// 存储最终所生成的代码
code: "",
// 在生成代码的时候,通过调用 push 方法来进行拼接
push(code) {
context.code += code;
},
// 当前缩进的级别,初始值为 0,也就是没有缩进
currentIndent: 0,
// 该方法用来换行,会根据当前缩进的级别来添加相应的缩进
newline() {
context.code += "\n" + ` `.repeat(context.currentIndent);
},
// 用来缩进,会将缩进级别加一
indent() {
context.currentIndent++;
context.newline();
},
// 用来取消缩进,会将缩进级别减一
deIndent() {
context.currentIndent--;
context.newline();
},
};
之后调用 genNode 方法,而 genNode 方法的内部,就是根据不同的 AST 节点类型,调用对应的生成方法:
function genNode(node, context) {
// 我这里要做的事情,就是根据你当前节点的 type 来调用不同的方法
switch (node.type) {
case "FunctionDecl":
genFunctionDecl(node, context);
break;
case "ReturnStatement":
genReturnStatement(node, context);
break;
case "CallExpression":
genCallExpression(node, context);
break;
case "StringLiteral":
genStringLiteral(node, context);
break;
case "ArrayExpression":
genArrayExpression(node, context);
break;
}
}
每一种生成方法本质都非常简单,就是做字符串的拼接:
// 之后我们要做的就是完善上面的各种生成方法,而每一种生成方法的实质其实就是做字符串的拼接
// 生成函数声明
function genFunctionDecl(node, context) {
// 从上下文中获取一些实用函数
const { push, indent, deIndent } = context;
// 向输出中添加 "function 函数名"
push(`function ${node.id.name} `);
// 添加左括号开始参数列表
push(`(`);
// 生成参数列表
genNodeList(node.params, context);
// 添加右括号结束参数列表
push(`) `);
// 添加左花括号开始函数体
push(`{`);
// 缩进,为函数体的代码生成做准备
indent();
// 遍历函数体中的每个节点,生成相应的代码
node.body.forEach((n) => genNode(n, context));
// 减少缩进
deIndent();
// 添加右花括号结束函数体
push(`}`);
}
function genNodeList(nodes, context) {
const { push } = context;
for (let i = 0; i < nodes.length; i++) {
const node = nodes[i];
genNode(node, context);
if (i < nodes.length - 1) {
push(`, `);
}
}
}
// 生成 return 语句
function genReturnStatement(node, context) {
const { push } = context;
// 添加 "return "
push(`return `);
// 生成 return 语句后面的代码
genNode(node.return, context);
}
// 生成函数调用表达式
function genCallExpression(node, context) {
const { push } = context;
const { callee, arguments: args } = node;
// 添加 "函数名("
push(`${callee.name}(`);
// 生成参数列表
genNodeList(args, context);
// 添加 ")"
push(`)`);
}
// 生成字符串字面量
function genStringLiteral(node, context) {
const { push } = context;
// 添加 "'字符串值'"
push(`'${node.value}'`);
}
// 生成数组表达式
function genArrayExpression(node, context) {
const { push } = context;
// 添加 "["
push("[");
// 生成数组元素
genNodeList(node.elements, context);
// 添加 "]"
push("]");
}