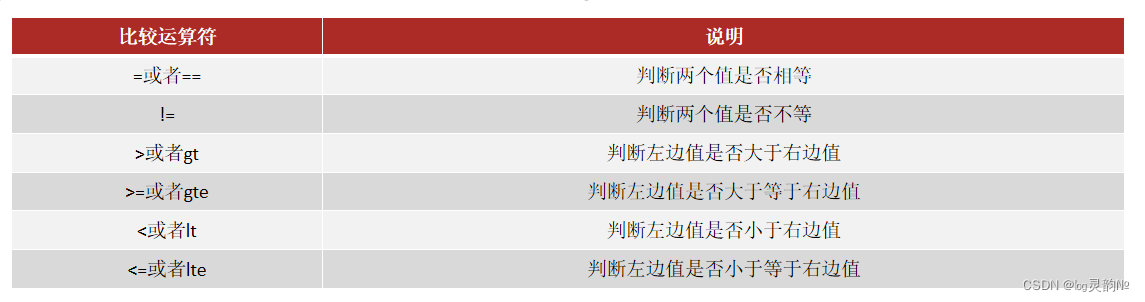
是基于时序数据库的开源监控告警系统,非常适合对K8S集群的监控,它通过HTTP协议周期性的抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控,
特点:
支持多维数据模型:由度量名和键值对组成的时间序列数据
内置时间序列数据库TSDB
支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
支持HTTP的Pull方式采集时间序列数据
支持PushGateway采集瞬时任务的数据
支持服务发现和静态配置两种方式发现目标
支持接入Grafana
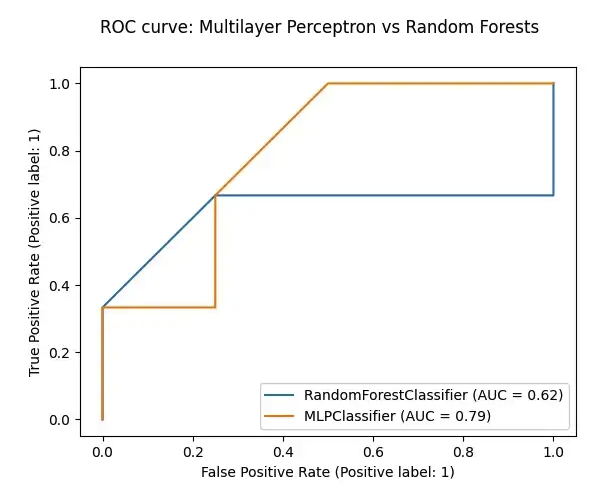
架构图:
Prometheus架构详解:
在上图中可以看到几个重要的组件,下面给大家简单介绍,
- Promtheus Server
这是Prometheus 整个架构核心,promtheus Server是promtheus组件中核心
负责,负责实现对监控数据的获取,存储以及查询,.Prometheus server可以通过
静态配置管理的目标,同时配合使用service discovery的方式动态管理监控目标,
并从这些监控目标,获取数据,其次promtheus server需要采集列的监控数据进行存储,promtheus server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储到磁盘中,这里是Prometheus server自身采用的时序数据库TSDB,这个后面介绍.
最后通过Prometheus server对外提供自定义的promQL语言,对数据进行处理,对数据进行处理.
- Exporter:
用户暴露已有的第三方服务的metrics将数据给到Prometheus,
Exporter将监控数据通过HTTP方式暴露该Prometeus Server, Prometheus Server通过该Export获取到监控的主机数据, 即可获取到需要采集的监控数据。Export的类型有很多.
- Push Gateway
Push Gateway 主要是用来给Prometheus推送数据,这种情况主要是用于在和Prometheus 不在同一个网络,或者有网络隔离不能直接采集的情况下,或者自定义的一些监控项的情况下进行数据采集,后面详细介绍.
- Grafana
主要是将数据进行展示出来,用来数据展示,通过接入到Prometheus的数据源,套用模板可以很好的将数据展示出来.
- AlertManager
主要是配合Prometheus的规则rule文件,来进行监控告警的配置,,用来会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,钉钉、企业微信,pagerduty等。
- Client Library
客户端库,为需要监控的服务生成相应的metrics并暴露给Prometheus Server,当Prometheus server来pull,直接返回实时状态的metrics,
Promtheus的主要使用逻辑:
- Server周期性从静态配置的targets或者服务发现的targets上拉取数据,
- 当新拉取的数据大于配置内存缓存区的时候,就会进行数据的存储,
- Prometheus可以配置rules规则,然后是通过一个job方式定时去查询这个数据,当条件触发的时候,会将alert推送到配置的Alertmanager
- 通过Alertmanager收到警告的时候,可以根据配置, 聚合,去重,降噪,最后发送警告。,
- 然后使用API,Prometheus UI或者Grafana查询展示数据
Prometheus中的几个概念
数据模型:
Prometheus是将所有数据存储为时间序列,属于相同的metric名称,和相同标签组的时间戳流,
metric 和 标签:
每个时间序列都是由其metric名称和一组标签组成的唯一标识,.
metric名称代表了被监控系统的一般特征(如 http_requests_total代表接收到的HTTP请求总数)。它可能包含ASCII字母和数字,以及下划线和冒号,它必须匹配正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
标签给prometheus建立了多维度数据模型:对于相同的 metric名称,标签的任何组合都可以标识该 metric的特定维度实例,
Metric类型:
Counter 值只能单调增加或重启时归零,可以用来表示处理的请求数、完成的任务数、出现的错误数量等
Gauge 值可以任意增加或减少,可以用来测量温度、当前内存使用等
Histogram 取样观测结果,一般用来请求持续时间或响应大小,并在一个可配置的分布区间(bucket)内计算这些结果,提供所有观测结果的总和
累加的 counter,代表观测区间:<basename>_bucket{le="<upper inclusive bound>"}
所有观测值的总数:<basename>_sum
观测的事件数量:<basenmae>_count
Summary 取样观测结果,一般用来请求持续时间或响应大小,提供观测次数及所有观测结果的总和,还可以通过一个滑动的时间窗口计算可分配的分位数
观测的事件流φ-quantiles (0 ≤ φ ≤ 1):<basename>{quantile="φ"}
所有观测值的总和:<basename>_sum
观测的事件数量:<basename>_count
样本(Samples):
Samples 构成了真正的时间序列值,样本主要由以下几个部分组成:
时间戳: (timestamp): 一个精确到毫秒的时间戳
样本值(value): 一个float64的浮点型数据表示当前样本的值.
构成一个键值的形式.
实例与任务:
在prometheus中,一个可以拉取数据的端点叫做实例,一般等同于同一个进程,对于一组有着相同目标的实例,叫做任务.
当prometheus拉取目标时,它会自动添加一些标签到时间序列中去,用于标识被拉取的目标,job:目标所属的任务名称
instance:目标URL中的:部分
如果两个标签在被拉取的数据中已经存在,那么就要看配置选项 honor_labels 的值来决定行为了。
每次对实例的拉取,prometheus会在以下的时间序列中保存一个样本(样本指的是在一个时间序列中特定时间点的一个值):
up{job="<job-name>", instance="<instance-id>"}:如果实例健康(可达),则为 1 ,否则为 0
scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}:拉取的时长
scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}:在 metric relabeling 之后,留存的样本数量
scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}:目标暴露出的样本数量
Prometheus 的所有配置都是prometheus.yaml文件的一部分,而 Alertmanager 的所有警报规则都配置在prometheus.rules.
prometheus.yaml:这是主要的 Prometheus 配置,包含所有抓取配置、服务发现详细信息、存储位置、数据保留配置等
prometheus.rules:此文件包含所有 Prometheus 警报规则
通过将 Prometheus 配置外部化到 Kubernetes 的 config map,那么就无需当需要添加或删除配置时,再来构建 Prometheus 镜像。这里需要更新配置映射并重新启动 Prometheus pod 以应用新配置。
Prometheus工作流程
指标采集: prometheus server 通过 pull 形式采集监控指标,可以直接拉取监控指标,也可以通过pushgateway做中间环节,监控目标先push形式上报数据到pushgateway.
指标处理:prometheus server 将采集的数据存储在自身 db 或者第三方 db;
指标展示:prometheus server 通过提供 http 接口,提供自带或者第三方展示系统;
指标告警:prometheus server 通过 push 告警信息到 alert-manager,alert-manager 通过"静默-抑制-整合-下发"4个阶段处理通知到观察者。
Prometheus的配置文件
首先就是他的主配置文件,Prometheus.yaml文件,其中主要分为一下几个模块:
全局配置: global
告警配置: alerting
规则文件配置: rule_files
拉取配置: scrape_configs
配置文件内容:
[root@node00 prometheus]# cat prometheus.yml.default
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Golbal 指定在所有配置上下中有效的的参数,同时可以做其他配置的默认设置,
下面的配置项: 比如配置采集间隔,抓取超时时间等全局设置信息
global:
# 默认拉取频率
[ scrape_interval: <duration> | default = 1m ]
# 拉取超时时间
[ scrape_timeout: <duration> | default = 10s ]
# 执行规则频率
[ evaluation_interval: <duration> | default = 1m ]
# 通信时添加到任何时间序列或告警的标签
# external systems (federation, remote storage, Alertmanager).
external_labels:
[ <labelname>: <labelvalue> ... ]
# 记录PromQL查询的日志文件
[ query_log_file: <string> ]
其中拉取配置项:scrape_configs:
用来指定数据采集的相关配置,它里面想当于运行的一个job,通过这个job和后面的其他配置,定时去抓取数据,
主要的一些参数:
scrape_interval: 抓取间隔,默认继承global值。
scrape_timeout: 抓取超时时间,默认继承global值。
metric_path: 抓取的一个路径,默认是接口+/metrics
scheme: 指定采集使用的协议,https或者https
params: 指定一个url的参数
basic_auth: 指定认证的信息,
*_sd_configs: 指定服务发现配置
static_config: 用来指定服务job
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: "node"
static_configs:
- targets:
- "192.168.100.10:20001" - "192.168.100.11:20001 - "192.168.100.12:20001"
其中的targets的配置,就是需要监控的主机的ip,,如果主机多,也可以专门放在一个文件中,然后将文件路径引入文件即可.但这种方式下,就从维护配置文件变成了维护targets文件,也比较麻烦,后面要介绍的Prometheus-operator 就很好的简化了这个工作.
规则文件配置: rule_files
这个部分是用来定义Prometheus的一些监控告警的规则,一般是填写一个文件路径,然后Prometheus会将这个文件加载进去,生成告警规则,具体的告警规则就需要在PrometheusRule.yaml文件中进行编写.
简单看一些这个规则文件的具体配置:
groups:
- name: node_health
rules:
- alert: HighMemoryUsage
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes < 0.5
for: 1m
labels:
severity: warning
annotations:
summary: High memory usage
其中,
name: 是定义rule名称,
alert 是定义这个告警的名称
expr:是定义触发告警的条件,这个就是通过编写promPQL语句,写出的一个表达式,然后通过判断数据,,
for: 定义告警持续时间,在达到这个时间后,就会触发通知告警.防止一些误报的产生/
labels: 定义这个标签
annotation: 定义告警的说明内容,,这向外接入告警通知平台的时候很有用
告警配置: alerting
这个alert的配置,主要是针对一个告警通知的组件alertmange的关联,因为Prometheus的告警是通过这个组件进行发送的,Prometheus是一个采集和告警分离的架构,,里面也是配置targets,就是alertmange服务的ip和端口,
Alertmange介绍和使用
Alertmange工作机制:
它的作用就是专门用来告警的一个组件,与Prometheus进行配合来进行使用. 前面说到过rule文件,这个是Prometheus的规则配置,那这个规则被触发后,就需要向alertmange进行通知,在alertmange接受到告警信息之后,会对告警信息进行处理,进行信息分组Group.同时alertmange是由一个路由匹配的机制,来匹配整个告警应该通知给那个人,然后根据定义好的通知方式,将这个信息通知到告警接收人,一般alertmange可以通过Email Slack 钉钉、企业微信 Robot(webhook) 企业微信 等进行通知.
在 Prometheus 中, 我们不仅仅可以对单条警报进行命名通过 PromQL定义规则,更多时候是对相关的多条警报进行分组后统一定义。这些定义会在后面说明与其管理方法.
下面介绍几个重概念:
分组(group):
Group是Alertmanager把同类型的警报进行分组,将警报进行很好的合并,这样做的好处就是很好的避免了重复告警,在大规模集群中,可能有多台主机都是同一个告警,此时就不需要大量重复的告警,通过这个方式可以很好的避免,
抑制(inhibition):
这个机制是用来,在某条警告已经发送的情况下,停止重复发送一些由于上一条警报引发的其他异常告警,.在生产中可以很好避免,告警的一个连锁反应,导致发送大量无意义的告警.
静默(sliences): Silences 提供了一个简单的机制,根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接受到警报符合静默的配置,Alertmanager 则不会发送警报通知。
Alertmanager配置文件详解
## Alertmanager 配置文件
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "123456789@qq.com"
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: "123456789@qq.com"
smtp_auth_password: "auth_pass"
smtp_require_tls: true
# email、企业微信的模板配置存放位置,钉钉的模板会单独讲如果配置。
templates:
- '/data/alertmanager/templates/*.tmpl'
# 路由分组
route:
receiver: ops
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 24h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname] # 报警分组
routes:
- match:
team: operations
group_by: [env,dc]
receiver: 'ops'
- match_re:
service: nginx|apache
receiver: 'web'
- match_re:
service: hbase|spark
receiver: 'hadoop'
- match_re:
service: mysql|mongodb
receiver: 'db'
# 接收器
# 抑制测试配置
- receiver: ops
group_wait: 10s
match:
status: 'High'
# ops
- receiver: ops # 路由和标签,根据match来指定发送目标,如果 rule的lable 包含 alertname, 使用 ops 来发送
group_wait: 10s
match:
team: operations
# web
- receiver: db # 路由和标签,根据match来指定发送目标,如果 rule的lable 包含 alertname, 使用 db 来发送
group_wait: 10s
match:
team: db
# 接收器指定发送人以及发送渠道
receivers:
# ops分组的定义
- name: ops
email_configs:
- to: '9935226@qq.com,10000@qq.com'
send_resolved: true
headers:
subject: "[operations] 报警邮件"
from: "警报中心"
to: "小煜狼皇"
# 钉钉配置
webhook_configs:
- url: http://localhost:8070/dingtalk/ops/send
# 企业微信配置
wechat_configs:
- corp_id: 'ww5421dksajhdasjkhj'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
send_resolved: true
to_party: '2'
agent_id: '1000002'
api_secret: 'Tm1kkEE3RGqVhv5hO-khdakjsdkjsahjkdksahjkdsahkj'
# web
- name: web
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[web] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/web/send
- url: http://localhost:8070/dingtalk/ops/send
# db
- name: db
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[db] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/db/send
- url: http://localhost:8070/dingtalk/ops/send
# hadoop
- name: hadoop
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[hadoop] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/hadoop/send
- url: http://localhost:8070/dingtalk/ops/send
# 抑制器配置
inhibit_rules: # 抑制规则
- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 status: 'High'
status: 'High' # 此处的抑制匹配一定在最上面的route中配置不然,会提示找不key。
target_match:
status: 'Warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
equal: ['alertname','operations', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
这个配置中就进行配置,一些告警的路由匹配,接收人,以及接收人的通知方式,等等设置.
Global:
这个是Alertmanager的一个全局配置,其他的配置可以进行继承,覆盖,. 全局配置中就配置告警通知时延,发松端的配置信息,以及一些模板文件,
Template:
警报的模板是可以自定义通知的信息格式,以及其包含的对应的监控报警的指标, 可以自定义Email、企业微信的模板,配置指定的存放位置,对于钉钉的模板会单独讲如何配置,这里的模板是指的发送的通知源信息格式模板;.
Route
警报路由模块是描述在告警生成之后,会进入到路由匹配中,从根路由向下层层匹配,然后将告警的信息发送给这个接受者receiver,,
这是一个简单的router定义格式
route:
group_by: ['alertname']
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
因为这里只定义了一个路由,那么就Prometheus产生的告警都会先进入这个根路由中,,然后告警就都会发给接收的web.hook,
所以对于不同的级别,就需要定义更多的子路由,这些router通过标签匹配告警的方式进行处理.
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [cluster, alertname]
routes:
- receiver: 'database-pager'
group_wait: 10s
match_re:
service: mysql|cassandra
- receiver: 'frontend-pager'
group_by: [product, environment]
match:
team: frontend
子路由和根路由的配置差不多,主要是通过match 的标签去匹配这个告警,.
这里面需要注意的就是: 路由匹配的一个规则
每一个告警都会从配置文件中顶级的route进入路由树,需要注意的是顶级的route必须匹配所有告警(即不能有任何的匹配设置match和match_re),每一个路由都可以定义自己的接受人以及匹配规则;
默认情况下,是通过路由匹配一直向最深处匹配,但是router中设置了continue的值为false ,那么告警就会在匹配到第一个子节点后停止下来,为true才会继续向下.
自己学习过程中的不断总结收录,
未完待续~




![[学习笔记]2021韩顺平一周学会Linux](https://img-blog.csdnimg.cn/2aa3b10176cf41cda5d5b460da40be9d.png)