Undo Log 、Binary Log、Redo Log各自的作用
先抛结论:他们各自的作用是什么
- Undo Log :用于保证数据库事务原子性
- Binary Log:用于数据库的数据备份/主从复制
- Redo Log:用于保证数据库事务持久性
接下来详细谈谈它们
Undo Log
当数据库开启事务之后,如果事务进行到一半时发生错误需要进行回滚,这个时候就需要使用到Undo Log用于数据库事务的回滚,将数据恢复到事务开始之前
如何实现
对于Undo Log的具体操作就是记录相关操作的反操作:
- 当插入一条记录的时候,记下这条数据的主键,在发生回滚时进行删除
- 当删除一条记录的时候,记下这条数据的主键,在发生回滚时进行插入
- 当更新一条数据的时候,记下这条数据的旧值,在发生回滚时将数据更新回旧值
- …
Undo Log中的事务ID以及版本链指针
Undo Log中有一个事务id以及版本链指针
- 事务ID是用于记录是被哪个事务使用的
- 版本链指针是用于 Undo Log 指向下一个 Undo Log的,一条又一条的Undo Log通过指针串起了起来从而形成版本链
我们知道MVCC是用于实现事务的隔离性的,MVCC则是通过Undo Log和Read View实现的
Read View是在开启事务时就生成的一张“快照”,整个事务都是使用这个快照,也就是事务开启前的数据库中的数据内容
通过比对当前事务的Read View中的一些字段和不同事务之间的事务id,查看是否满足可见性,如果不满足可见行,就会顺着 undo log 版本链里找到满足其可见性的记录
具体规则如下:
-
Read View中记录了已经提交的事务id且记为min_id,还没有开启的事务的id且记为max_id,创建当前事务的事务id切记为create_id
那么处于min_id和max_id之间的事务id代表这是还没有提交的事务
-
当一个事务执行写操作(如插入、更新、删除)时,数据库会将这个事务的
trx_id记录在相应的数据行中。这样,数据库系统就能够追踪每个数据行是由哪个事务创建或修改的。 -
如果当前事务去访问记录时,这条记录中的id小于min_id则说明这个版本的记录是在Read View之前提交的,可见
-
如果当前事务去访问记录时,这条记录中的id大于max_id则说明这个版本的记录是在Read View之后开启的,不可见,通过版本链查找可见的记录
-
如果当前事务去访问记录时,这条记录中的id处于min_id和max_id之间那么需要再做判断
- 有一个活跃事务列表,里面记录了已经开启但是没有提交的事务的事务id
- 如果这个id在活跃事务列表内说明还没有提交,不可见,通过版本链查找可见的记录
- 如果这个id不在活跃事务列表内说明该事务已经提交,数据对Read View可见
总结
Undo Log是用于数据库事务的回滚的,同时也是实现MVCC的
也就是说Undo Log既保证了事务的原子性也保证了数据库的隔离性
Binary Log
Binary Log里面记录了逻辑变更,也就是记录了所有的表结构变更(对表的插入、更改、删除),以及数据库表的数据变更
当事务提交以后,MySQL会将该事务产生的Binary Log统一写入Binary Log文件中
记录了什么
虽然说Binary Log中记录了逻辑变更,这个逻辑变更到底是什么?
具体来说,Binary Log其实记录了数据库执行的所有操作(除了查询),也就是插入语句,删除语句,更新语句
通过文本文件的形式保存下来,同时以追加写的方式不停的记录
作用
由于以追加写的方式记录了所有的逻辑变更,所以Binary Log更适合用于数据库的数据备份以及主从复制
当我们不小心把数据库里面的所有数据全部删除时,这个时候就得请出我们的Binary Log了,通过执行Binary Log里面的SQL语句就能够将数据库的数据进行恢复
我们部署集群的时候,我们的主库写入Binary Log,然后将Binary Log复制到从库上,再回放Binary Log,这个时候从库里面的数据就能够跟主库的数据保持一致了
数据备份和主从复制的原理都是相同的,都是回放Binary Log
总结
Binary Log 包含了数据库中执行过的写操作的SQL,所以更适合用于备份以及主从复制
Redo Log
当数据库开启事务之后,会将所有的数据修改记录到Redo Log中,所以说当数据库发生崩溃后使用Redo Log将数据库恢复到最近一次的事务提交之后的状态
具体操作
Redo Log中记录了事务的物理变更,换句话说就是记录了数据库中哪一个地方进行了什么修改
由于MySQL中WAL机制(WAL机制它确保在对数据库进行写入操作之前,相关的日志记录已经被写入到持久化的存储介质上)的存在,MySQL在完成数据修改以后,并不会立刻将数据写入到磁盘中,而是先写入Redo Log中,然后数据在合适的时机写入到磁盘中
为什么要先写入进Redo Log中而不是直接写入磁盘里面?
原因在于Redo Log让磁盘变成了顺序写而不是随机写,提高了写操作的效率
随机写是指一个又一个的数据先在磁盘中找到相应的位置然后再进行写入,顺序写是指第一个数据先找好位置然后把数据一个接一个地依次存入硬盘
写入Redo Log的方式是追加操作,使得写入磁盘操作是顺序写,提高了写入效率
缓存在 redo log buffer 里的 redo log 还是在内存中,它什么时候写入到磁盘中的Redo Log File中?
前置知识:Redo Log有自己的缓存区,每次写好一条Redo Log就放进Redo Log Buffer(也就是缓存区)中然后再将Redo Log Buffer
具体来说有几个时机
- MySQL关闭的时候
- 当 redo log buffer 中记录的Redo Log量大于 redo log buffer 内存空间的一半时
- 后台线程每隔1秒
- 每次事务提交都会将redo log buffer 中记录的Redo Log写入磁盘
- 这个操作可以使用三个参数进行控制
- 当参数为0时,每次事务提交后redo Log还是保留在 redo log buffer 中
- 当参数为1时,每次事务提交后将redo log buffer 中记录的redo Log写入磁盘
- 当参数为2时,每次事务提交后将redo log buffer 中记录的redo Log写入操作系统中的文件缓存中
Redo Log写满了会怎么样?
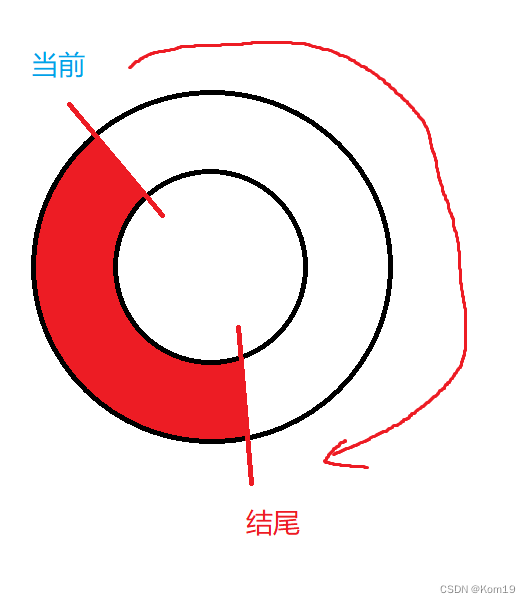
Redo Log是采用循环写的方式进行记录的,可以想象成一个环形,有两个参数,一个记录着当前写的位置,一个记录着末尾位置
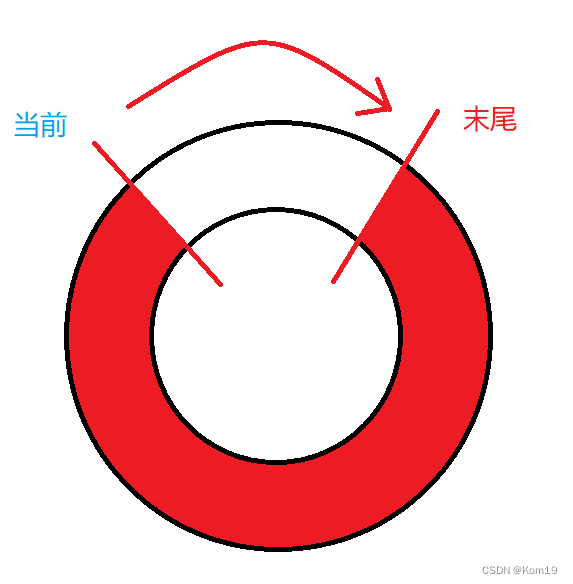
当前位置追上了末尾位置,此时说明文件写满了,这个时候MySQL阻塞停下来,将Buffer Pool中的脏页数据写入到磁盘,再标记Redo Log中哪些数据是可以删除的,接着将这些数据进行删除,此时就有了一大块空出来的空间了,更新一下末尾位置,然后继续开始写,直到下一次当前写的位置又追上末尾位置
总结
通过Redo Log可以保证在数据库突然发生崩溃的时,将数据恢复到最近一次事务提交的状态,从而保证事务的持久性
由于Redo会不断地擦除一些已经写入到磁盘的数据,所以也就解释了为什么所有数据全部删除时,这个时候就得请出我们的Binary Log而不是我们的Redo Log了
因为Binary Log记录了所有的SQL,而Redo Log并没有记录所有的数据(旧的日志会被新的日志覆盖,因此不会一直增长)