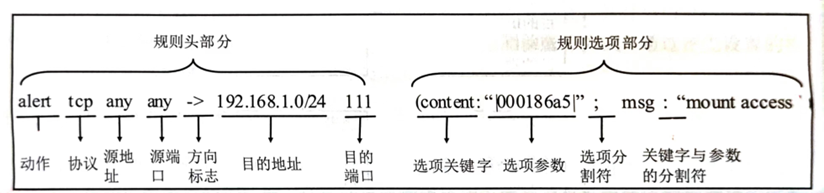
摘要:本文整理自阿里云智能 Flink SQL、Flink CDC 负责人伍翀(花名:云邪),在 Flink Forward Asia 2023 主会场的分享。Flink CDC 是一款基于 Flink 打造一系列数据库的连接器。本次分享主要介绍 Flink CDC 开源社区在过去一年的发展、Flink CDC 3.0 产品定位调整以及全新的架构设计,并重磅宣布 Flink CDC 开源旅程的下一站。
一、Flink CDC
1.1 简介
Flink CDC 是一款基于 Flink 打造一系列数据库的连接器。Flink 是流处理的引擎,其主要消费的数据源是类似于一些点击的日志流、曝光流等数据,但在业务场景中,点击流的日志数据只是一部分,具有更大价值的数据隐藏在用户的业务数据库中。Flink CDC 弥补了 Flink 读取这些数据的缺陷,能够通过流式的方式读取数据库中的增量变更的日志。
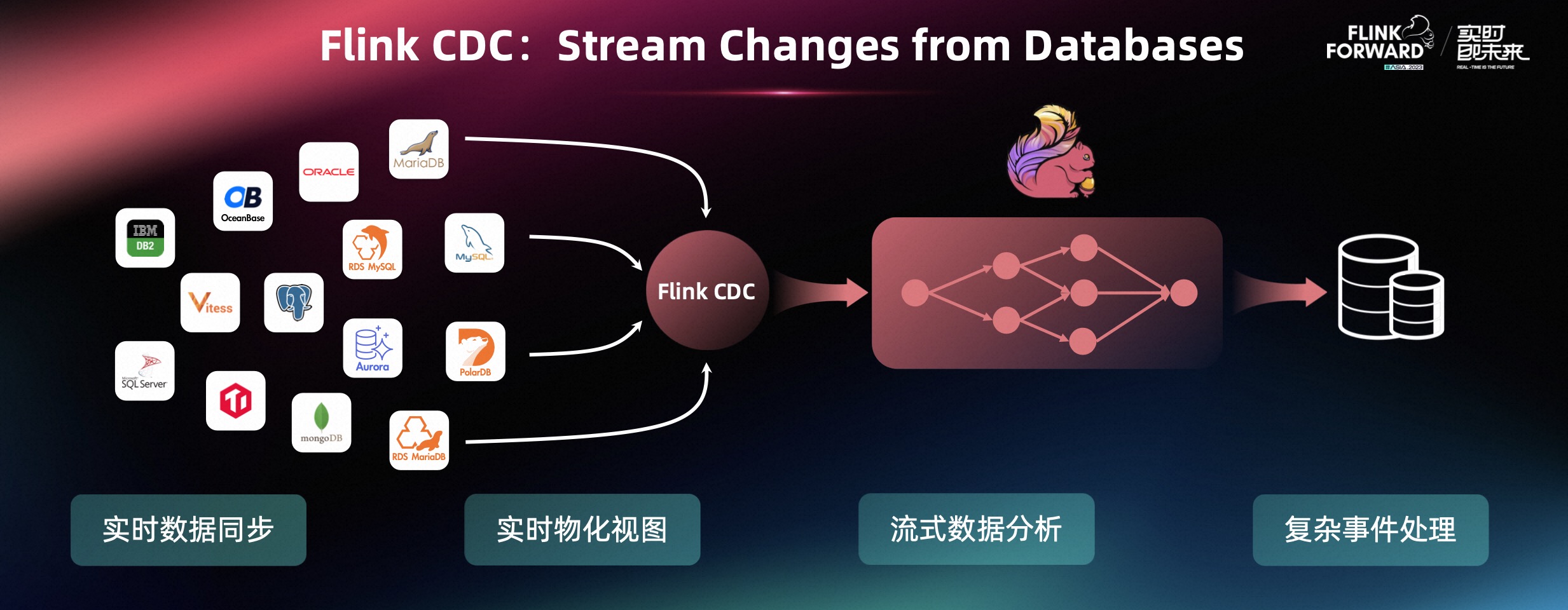
目前,Flink CDC 可以支持很多种数据库,如 MySQL、Postgresql、PolarDB、OceanBase、TiDB、MongoDB 等十多种数据源。Flink CDC 又能与 Flink SQL 实现无缝的打通,让用户使用 SQL 就可以构建非常丰富的应用形态,用户可以用 SQL 简单地实现数据的实时同步,如实时入仓入湖。用户也可以用 SQL 非常简单地在数据库上构建实时的物化视图,对数据库的数据做流式的数据分析,甚至可以用 SQL 对数据库的变更日志做复杂的事件处理,如做日志审计等。
1.2 Flink CDC in 2023
Flink CDC 在过去的 2023 年蓬勃发展。

1、生态方面
支持了两个新的 CDC Connector,包括 IBM DB2 和 Vitess;在增量快照读取能力方面,我们扩展到了更多的数据源,包括 ORACLE、SQL Server、MongoDB、PostgreSQL,用户在读取这些数据库的数据时候也可以并行无锁地读取,获得更好的性能和更高的稳定性。
2、引擎能力方面
引擎能力方面提供了非常多的高级特性。
如动态加表,可以在已有的数据同步作业中动态地加上想要同步的新表,而已有的同步表会继续同步,不会断流,新增的表会以并行的模式、全增量一体化的模式进行同步,该特性可以动态地同步新增表,同时又不影响已有表的同步。
再如,还支持自动缩容的能力,因为 Flink CDC 在做数据同步的过程中,会分为历史数据的全量同步阶段和增量 CDC 数据的同步阶段,一般来说,在历史数据同步阶段,由于数据量较大,一般会使用较大的并发,快速、高吞吐地把历史的数据同步到目标端中,但到了增量阶段,一般来说,只需要单并发就足以支撑数据量。在以前,用户一般会手动调整并发度,重启作业,以达到降低并发度、节省资源的目的。如今,自动缩容能力已经做到了框架内部,框架在从全量阶段切换到增量阶段时,会自动地把并发度调低,回收空闲的资源,降低成本。
同时,还提供了异步分片的能力,让 split 的分配和读取 pipeline 化,极大地提升超大表的读取性能。
此外,还支持指定位点能力,用户可以指定 Binlog 的 offset 位点,或者指定开始读取 Binlog 的时间戳,而无需全量加增量的方式读取。
还支持 At-Least-Once 读取模式,因为对于某些能够接受幂等更新场景的用户来说,At-Least-Once 模式可以提供比 Excel-Once 模式更快的读取效率。
最后,还支持了从 Flink 1.14 到最新的 Flink 1.18 全版本,兼容横跨了五个大版本的能力。
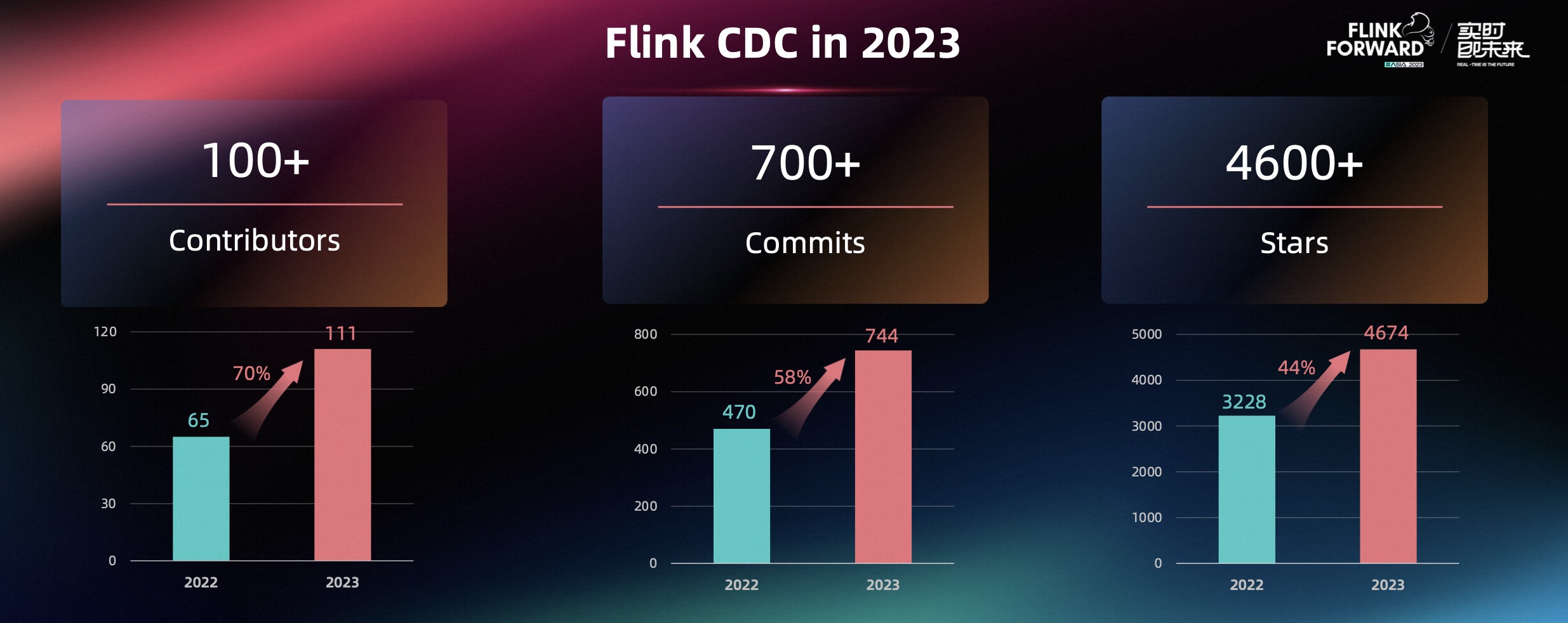
其一,生态的快速发展、引擎的全面增强,离不开活跃的社区。Flink CDC 在过去一年中,各项指标也都呈现蓬勃发展的态势。在贡献者数量上,提升了 70%,在 Commit 数上提升了 58%,在 Star 数上提升了 44%,达到了 4600 多个 Star。
其二,活跃的社区也离不开每位在 Flink CDC 中开源贡献的 100 多个贡献者,以及使用和落地 Flink CDC 的广大用户。
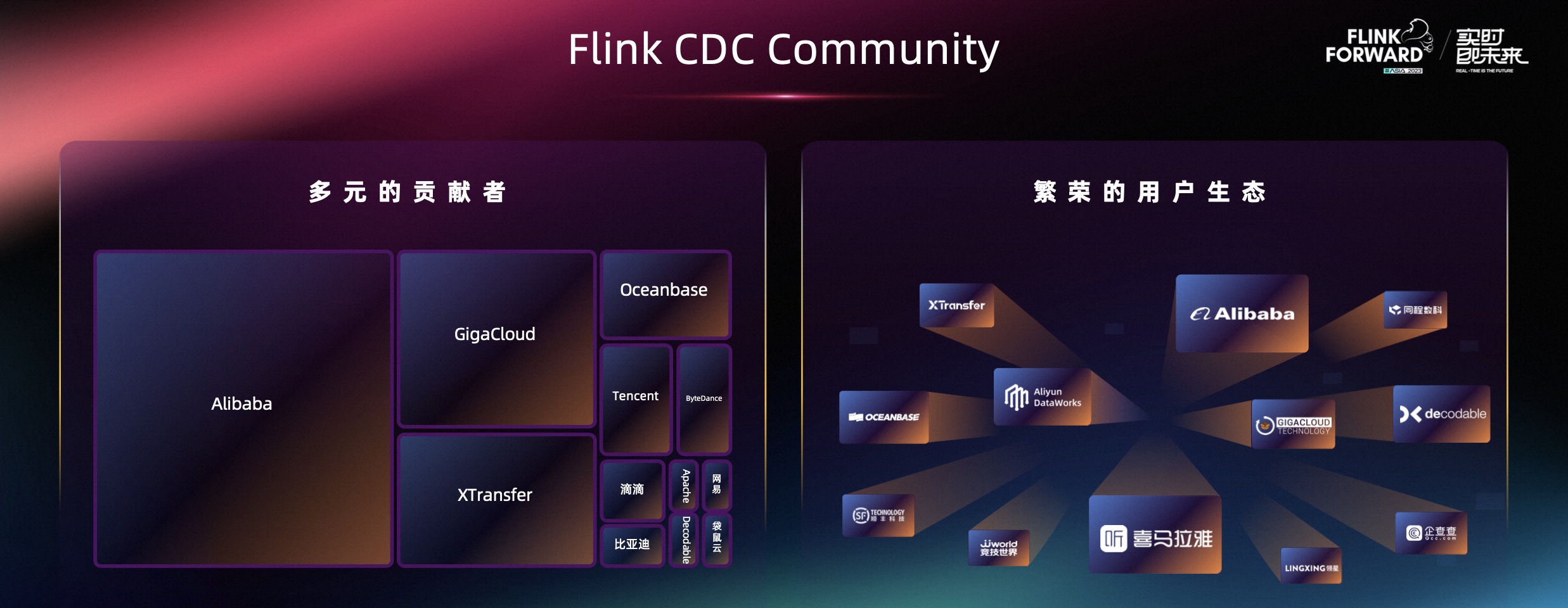
在 Flink CDC 的社区贡献中,有近一半的贡献来自于阿里巴巴以外的贡献者,包括大建云仓、XTransfer、Oceanbase、腾讯、滴滴等公司,都为 Flink CDC 做了很多的贡献,是一个非常多元的贡献者生态。
同时在用户生态方面,Flink CDC 现已经覆盖了很多的用户场景,横跨了包括金融、物流、游戏、互联网,甚至云厂商和云服务的场景。
二、用户对话环节:Flink CDC 企业实践分享
下面通过喜马拉雅和阿里云 Dataworks 用户交流对话,让大家更加直接地了解 Flink CDC 在用户场景下如何做选型以及落地情况。
2.1 喜马拉雅基于 Flink CDC 构建实时高效的数据集成链路
喜马拉雅成立于 2012 年,至今已有 11 年了,业务主要包括像有声书、有声剧、播客、亲子、直播电商等,据 2022 年前三季度的统计,喜马拉雅全产业的活跃用户在 2.8 亿左右。喜马拉雅业务发展如此迅速,那它有什么样的业务特点?在数据的使用上又有遇到哪些挑战/痛点?下面通过与喜马拉雅大数据平台架构负责人陈叶超的对话,一起了解喜马拉雅在做数据集成工具选型的过程中为何选择了 Flink CDC 。
对话嘉宾
伍 翀|阿里云智能 Flink SQL、Flink CDC 负责人
陈叶超|喜马拉雅大数据平台架构负责人

【用户对话环节 1 - 视频回放】
视频观看地址:https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442935384348.mp4
2.2 Flink CDC 在阿里云 DataWorks 数据集成应用实践
Dataworks 是国内现有的数据集成领域业务量上最大的项目之一,且其业务场景非常具有代表性,发展至今,其已经非常稳定、强大了。经过十多年的发展,Dataworks 之前有数据集成引擎 DataX,在采用 Flink CDC 作为新引擎上线的过程中,可能会有较大的挑战,因为 Datawork 要服务很多的云上客户,那如何让新引擎兼容旧引擎的行为呢?以及如何能够在架构上做到无感的灰度升级?通过与阿里云智能 DataWorks 数据集成负责人崔亮对话,一起了解 Dataworks 是如何转向 Flink CDC 的。
对话嘉宾
伍 翀|阿里云智能 Flink SQL、Flink CDC 负责人
崔 亮|阿里云智能 DataWorks 数据集成负责人

【用户对话环节 2 - 视频回放】
视频观看地址:https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/442918316460.mp4
三、Flink CDC 的下一站
回到今天分享的主题 Flink CDC 的下一站。

Flink CDC 已有三年多的发展历史了,其最初的定位是一系列数据库数据源的连接器,但随着 Flink CDC 在业界的广泛应用,我们越来越发现其最初的产品定位无法覆盖更多的业务场景,因此,是时候要重新思考 Flink CDC 的定位。
3.1 重新思考 Flink CDC 的定位
刚刚两位嘉宾分享的都是数据集成的场景,这其实也是 Flink CDC 在业界最广泛应用的场景——数据集成,但是如果 Flink CDC 仅作为数据源的连接器,用户要去搭建数据集成的解决方案,还需要做很多额外的拼装工作,也会遇到一些功能上的限制。

我们希望 Flink CDC 能够连接更多的数据源,包括数据库、消息队列、数据湖、文件格式、SaaS 服务等。同时,我们希望 Flink CDC 不仅仅连接数据源,更希望它是端到端的实时数据集成的解决方案和工具,去打通从数据源、数据管道到数据目标的全套端到端的解决方案。

3.2 Flink CDC 3.0 正式发布
社区经过一段时间紧锣密鼓的设计和研发,很荣幸,今天 Flink CDC 3.0 实时数据集成框架正式发布了,这是 Flink CDC 又一新的里程碑版本。该框架是基于 Apache Flink 的内核之上去构建的。同时,也开源开放了很多之前在阿里内部研发的高级特性,包括实时同步、整库同步、分库分表合并同步、Schema 变更同步、Schema 自动推导、动态加表、自动缩容等一系列高级能力。此外,在连接层,我们已经支持了 MySQL 到 StarRocks、Apache Doris 的同步链路。在下一期我们会打通更多的链路,包括 Paimon、Kafka、MongoDB 等。在接入层,我们提供了 YAML + CLI 的用户 API,极大地降低用户开发实时数据集成的成本。

若要开发 MySQL 到 DORIS 的整个同步链路,只需要在 YAML 文件中定义 MySQL 数据源的连接信息,DORIS 结果表的连接信息,以及要同步的表的信息。比如,这里我们要同步库中的所有表。然后使用 Flink CDC 的 Shell 脚本提交 YAML 文件,就可以提交了从 MySQL 到 DORIS 的整库同步的作业。然后,该作业会自动地把库下面的上千张表同步到 DORIS 中,在 DORIS 中自动创建上千张表的表结构信息,将上千张表的数据全增量一体化地同步到 DORIS 中。同时,一些增量的 Binlog 数据也能实时秒级地同步到 DORIS 中。以及,MySQL 上发生的 Schema 变更也能实现实时的同步。

该过程把一切所有的复杂度都隐藏在了引擎内部,而把自动化的极简的体验留给了用户。大家可以点击 Release Release 3.0.0 · ververica/flink-cdc-connectors · GitHub Flink CDC 3.0 的下载链接试用体验,欢迎大家的反馈和建议。
3.3 Flink CDC 开源旅程的下一站
Flink CDC 发展了三年多的时间。2020 年,从作为个人的 Side project 出发,后来被越来越多人认识到,把项目放到 ververica 仓库上,作为正式的开源项目去运营。到 2.0 版本我们发布了增量快照,使 Flink CDC 成为可以大规模生产使用的工具,社区也迎来了快速的发展。再到今天,我们发布了 3.0 版本的数据集成框架,这是在技术上的又一新的里程碑。
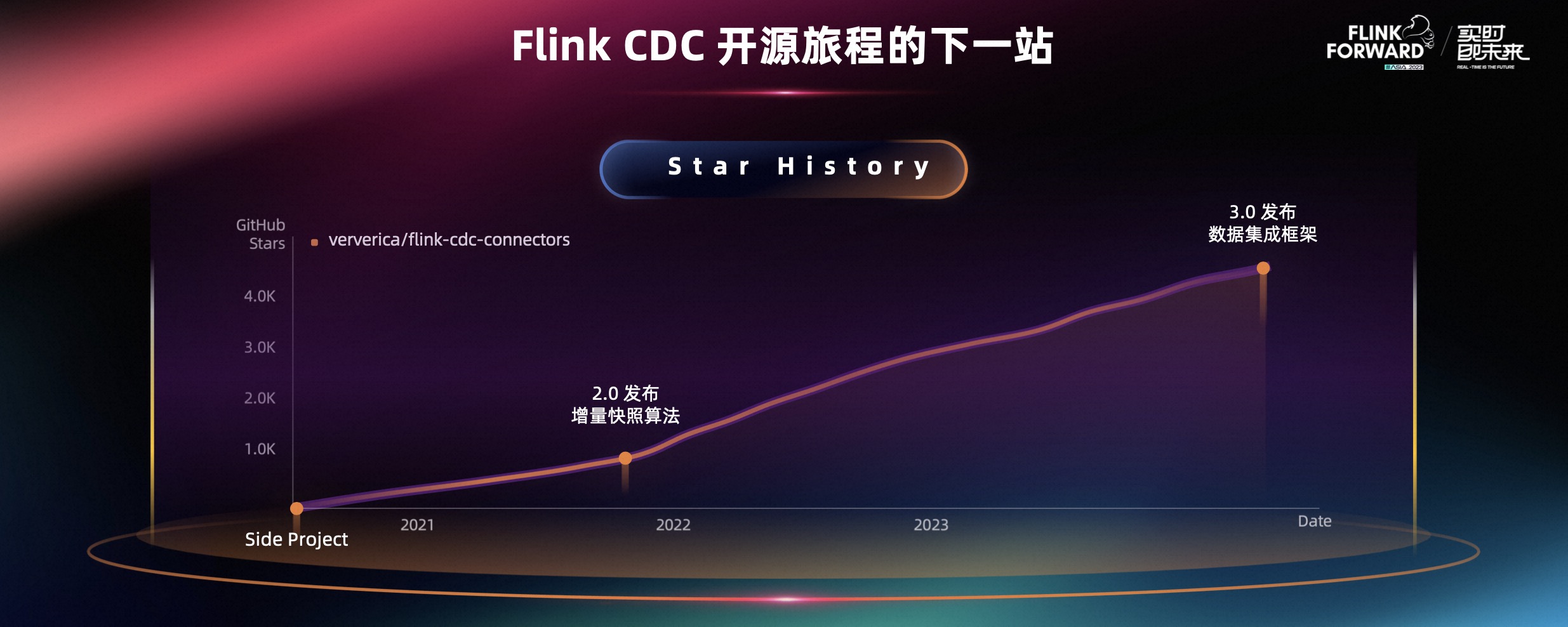
除了 Flink CDC 在技术上的下一站,我们也想分享 Flink CDC 开源旅程的下一站。Flink CDC 能构建出如此繁荣的社区,离不开社区的力量、开源的力量,所以我们希望能够进一步去回馈开源。我们非常荣幸地宣布阿里巴巴启动捐赠 Flink CDC 到 Apache Flink 和 Apache 软件基金会,相关的讨论已经在社区中发起,大家可以点击 https://s.apache.org/flink-cdc-donate关注更多社区的相关讨论 。

Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可扫描图片二维码观看全部议题的视频回放及 FFA 2023 峰会资料!