文章目录
- 二叉树
- 一、二叉树的概念
- 二、二叉树的基本形态
- 三、二叉树的性质
- 四、特殊的二叉树
- 五、二叉树的存储结构
- 5.1 顺序
- 5.2 链表
- 5.2.1 二叉链表
- 5.2.1 三叉链表
- 六、二叉树的遍历
- 先序遍历(T L R)
- 中序遍历(L T R)
- 后序遍历(L R T)
- 应用题
- 七、树与二叉树的转换
- 八、树和森林
- 九、二叉树排序
- 9.1 二叉排序树的定义
- 9.2 二叉排序树的查找
- 9.3 二叉排序树的插入
- 9.4 二叉排序树的删除
- 十、哈夫曼树
- 10.1 哈夫曼树的概念
- 10.2 哈夫曼数的应用
- 10.3 哈夫曼树的构造
- 10.4 哈夫曼编码
二叉树
树是一种分枝结构的对象,在树的概念中,对每一个结点孩子的个数没有限制,因此树的形态多种多样,本章我们主要讨论一种最简单的树——二叉树。
一、二叉树的概念

二叉树:或为空树,或由根及两颗不相交的左子树、右子树构成,并且左、右子树本身也是二叉树。
说明:
1)二叉树中每个结点最多有两颗子树,二叉树每个结点度小于等于2
2)左、右子树不能颠倒——有序树
3)二叉树是递归结构,在二叉树的定义中又用到了二叉树的概念

(a)、(b)是不同的二叉树, (a)的左子树有四个结点,(b)的左子树有两个结点
返回顶部
二、二叉树的基本形态

三、二叉树的性质
性质1 在二叉树的第i 层上最多有 2 i − 1 2^{i-1} 2i−1个结点
性质2 深度为k的二叉树最多有 2 k − 1 2^k-1 2k−1 个结点
性质3 设二叉树叶子结点数为 n 0 n_0 n0,度为2的结点 n 2 n_2 n2,则 n 0 = n 2 + 1 n_0 = n_2 +1 n0=n2+1
四、特殊的二叉树
满二叉树:如果深度为 k k k的二叉树,有 2 k − 1 2^k - 1 2k−1个结点则称为满二叉树

完全二叉树:如果一颗二叉树只有最下一层结点数可能未达到最大,并且最下层结点都集中在该层的最左端,则称为完全二叉树。简单的说就是:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。

性质4:具有n个结点的完全二叉树的深度为: t r u n c ( l o g 2 n ) + 1 trunc(log_2 n)+1 trunc(log2n)+1。 trunc(x) 为取整函数。
- 对完全二叉树的结点编号:从上到下,每一层从左到右
性质5:在完全二叉树中编号为i的结点
1)若有左孩子,则左孩编号为 2 i 2i 2i
2)若有右孩子,则右孩子结点编号为 2 i + 1 2i+1 2i+1
3)若有双亲,则双亲结点编号为 t r u n c ( i / 2 ) trunc(i/2) trunc(i/2)
返回顶部
五、二叉树的存储结构
5.1 顺序
满二叉树或完全二叉树的顺序结构。用一组连续的内存单元,按编号顺序依次存储完全二叉树的元素.例如,用一维数组bt[ ]存放一棵完全二叉树,将标号为 i 的结点的数据元素存放在分量 bt[i-1]中。存储位置隐含了树中的关系,树中的关系是通过完全二叉树的性质实现的。例如,bt[5](i=6)的双亲结点标号是k=trunc(i/2)=3,双亲结点所对应的数组分量bt[k-1]=bt[2]

按完全二叉树的形式补齐二叉树所缺少的那些结点,对二叉树结点编号,将二叉树原有的结点按编号存储到内存单元“相应”的位置上。但这种方式对于畸形二叉树,浪费较大空间。

返回顶部
5.2 链表
5.2.1 二叉链表
二叉链表中每个结点包含三个域:数据域、左指针域、右指针域

Struct node {
int data;
struct node *lch,*rch;
};
5.2.1 三叉链表
三叉链表中每个结点包含四个域:数据域、双亲指针域、左指针域、右指针域
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SzBwhHF0-1672621000034)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221212182523363.png#pic_center)]](https://img-blog.csdnimg.cn/08b68b365bdc4c3187e8891c0c017560.png#pic_center)
Struct node {
int data;
struct node *lch,*rch,*parent;
};
返回顶部
六、二叉树的遍历
遍历:按某种搜索路径访问二叉树的每个结点,而且每个结点仅被访问一次。
访问:含义很广,可以是对结点的各种处理,如修改结点数据、输出结点数据。
- 遍历是各种数据结构最基本的操作,许多其他的操作可以在遍历基础上实现。
二叉树由根、左子树、右子树三部分组成, 二叉树的遍历可以分解为:
-
访问根
-
遍历左子树
-
遍历右子树

约定先左后右,有三种遍历方法: T L R、L T R、L R T ,分别称为 先序遍历、中序遍历、后序遍历。
返回顶部
先序遍历(T L R)
若二叉树非空
1)访问根结点;2)先序遍历左子树;3)先序遍历右子树**;**


返回顶部
中序遍历(L T R)
若二叉树非空
1)中序遍历左子树;2)访问根结点;3)中序遍历右子树**;**


返回顶部
后序遍历(L R T)
若二叉树非空
1)后序遍历左子树;2)后序遍历右子树;3)访问根结点**;**



返回顶部
应用题
孩子兄弟表示法又称二叉树表示法,或者二叉链表表示法。链表中结点的两个链域分别指向该节点的第一个孩子结点和下一个兄弟结点,对于二叉树来说就是左右两个节点。
创建二叉树的时候主要使用递归。第一步先创建根节点,然后创建根节点左子树,开始递归创建左子树,直到递归创建到的节点下不继续创建左子树,也就是当下递归到的节点下的左子树指向NULL,结束本次左子树递归,返回这个节点的上一个节点,开始创建右子树,然后又开始以当下这个节点,继续递归创建左子树,左子树递归创建完,就递归创建右子树,直到递归结束返回到上一级指针节点(也就是根节点下),此时根节点左边子树创建完毕,开始创建右边子树,原理和根节点左边创建左右子树相同。
/**
* File : Work1.c
* Author: 骑着蜗牛ひ追导弹'
* Date: 2022/12/13
*/
# include <stdio.h>
# include <stdlib.h>
typedef char nodeType;
typedef struct Tree {
nodeType data; // 数据域
struct Tree *left;
struct Tree *right;
} Tree, *BitTree;
BitTree createLink() {
BitTree tree; // 二叉树
char data; // 节点数据
char tmp;
scanf("%c", &data);
// 前面的scanf()在读取输入时会在缓冲区中留下一个字符’\n’(输入完按回车键所致),
// 所以如果不在此加一个getchar()把这个回车符取走的话,
// 接下来的scanf()就不会等待从键盘键入字符,
// 而是会直接取走这个“无用的”回车符,从而导致读取有误
tmp = getchar(); // 吸收空格
if (data == '#') {
return NULL; // 当前节点不存在数据
} else {
tree = (BitTree) malloc(sizeof(Tree)); // 分配空间
tree->data = data; // 存储节点数据
printf("请输入%c的左子树:", data);
tree->left = createLink(); // 开始递归创建左子树
printf("请输入%c的右子树:", data);
tree->right = createLink(); // 开始到上一级节点的右边递归创建左右子树
return tree; // 返回根节点
}
}
// 先序遍历
void showXianXu(BitTree T) {
if (T == NULL) return; // 遇到空返回上一层节点
printf("%c ", T->data);
showXianXu(T->left); // 递归遍历左子树
showXianXu(T->right);// 递归遍历右子树
}
// 中序遍历
void showZhongXu(BitTree T) {
if (T == NULL) return; // 遇到空返回上一层节点
showZhongXu(T->left); // 递归遍历左子树
printf("%c ", T->data);
showZhongXu(T->right);// 递归遍历右子树
}
// 后序遍历
void showHouXu(BitTree T) {
if (T == NULL) return; // 遇到空返回上一层节点
showHouXu(T->left); // 递归遍历左子树
showHouXu(T->right);// 递归遍历右子树
printf("%c ", T->data);
}
int main() {
BitTree S;
printf("请输入第一个节点的数据:\n");
S = createLink();
printf("先序遍历结果:\n");
showXianXu(S);
printf("\n中序遍历结果:\n");
showZhongXu(S);
printf("\n后序遍历结果:\n");
showHouXu(S);
return 0;
}
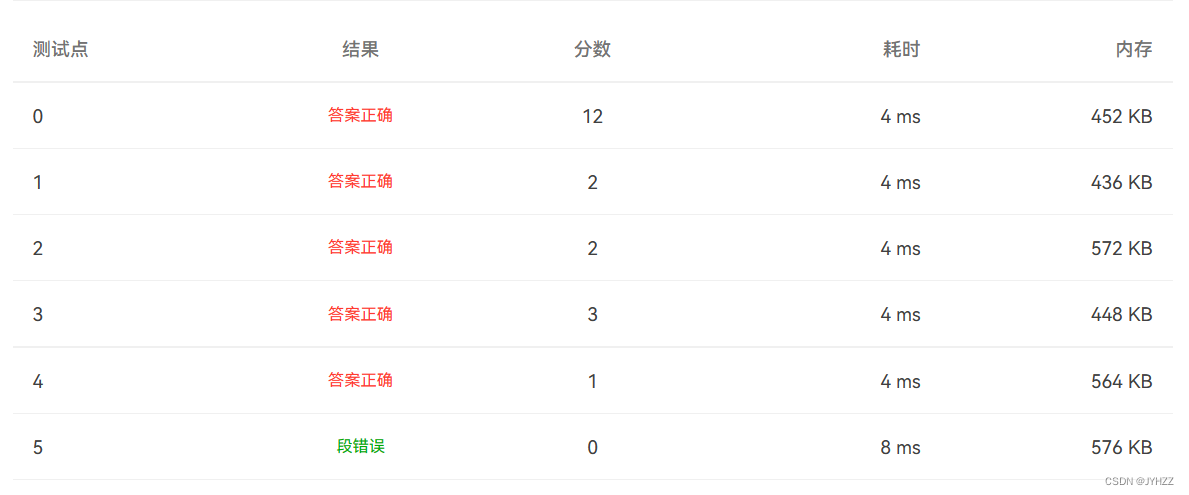
执行结果:

返回顶部
七、树与二叉树的转换
二叉树与树都可用二叉链表存贮,以二叉链表作中介,可导出树与二叉树之间的转换。

基本转换步骤:
(1)加线:在兄弟之间加一连线。
(2)抹线:对每个结点,除了其左孩子外,抹掉其与其余孩子之间的连线。
(3)旋转:将树作适当的旋转即可。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9goHayl9-1672621000042)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221217190906709.png#pic_center)]](https://img-blog.csdnimg.cn/f469bfe02b82411aa477a8bd86afa70f.png#pic_center)
返回顶部
八、树和森林
森林:树的集合
-
将森林中树的根看成兄弟,可用树孩子兄弟表示法存储森林;用树与二叉树的转换方法,进行森林与二叉树转换;从树的二叉链表示的定义可知,任何一棵和树对应的二叉树,其右子树必为空。
-
所以只要将森林中所有树的根结点视为兄弟,即将各个树转换为二叉树;再按森林中树的次序,依次将后一个树作为前一棵树的右子树,并将第一棵树的根作为目标树的根,就可以将森林转换为二叉树。

若 F ={ T1,T2,T3,…,Tn }是森林,则 B(F)={root,LB,RB}:
(1)若 F 为空,即 n=0,则 B(F)为空树。
(2)若 F 非空,则 B(F)的根是T1的根,其左子树为LB,是从T1根结点的子树森林F1={T11,T12,…,T1m}转换而成的二叉树;其右子树为RB,是从除T1外的森林F’={T2,T3,…,Tn}转换而成的二叉树;
二叉树还原为森林
若 B(F)={root,LB,RB}是一棵二叉树,则转换为森林F ={ T1,T2,Tn }:
(1)若 B 为空,则 F 为空树。
(2)若 B 非空,则 F 第一棵树T1的根是二叉树的根,T1中根结点的子森林F1是由B的左子树LB转换而成的森林,F中除T1外其余树组成的森林F’={T2,T3,…,Tn}是由B(F)的右子树RB转换转换而成的;
返回顶部
九、二叉树排序
9.1 二叉排序树的定义

一种特殊的二叉树,它的每个结点数据中都有一个关键值,并有如下性质:
- 对于每个结点,如果其左子树非空,则左子树的所有结点的关键值都小于该结点的关键值;
- 如果其右子树非空,则右子树的所有结点的关键值都大于该结点的关键值。
二叉排序树有查找效率高,增、删方便的优点,且对二叉排序树进行中序遍历,将得到一个按结点关键值递增有序的中序线性序列。所以,它被广泛用来作为动态查找的数据结构。
返回顶部
9.2 二叉排序树的查找
- 在二叉排序树中进行查找,将要查找的值从树根开始比较,若与根的关键值相等,则查找成功,若比根值小,则到左子树找,若比根值大,则到右子树找,直到查找成功或查找子树为空(失败)。
NODE *search(int x, NODE *root){
// 与根的关键值相等,则查找成功
if ((root==NULL)||(root->data= =x)) return(root);
if (root->data < x) {
// 若比根值大,则到右子树找
return search(x,root->rch);
} else {
// 若比根值小,则到左子树找
return search(x,root->lch);
}
}
返回顶部
9.3 二叉排序树的插入
插入:二叉排序树的插入是一个动态的查找过程。例如,要插入关键值 x,首先在树中查找,若不存在则插入。因为查找失败的情况是一直查到查找路径的末端,仍然不存在 x ,则待插入结点必作为树叶插入树中。
NODE *insert(NODE *p, NODE *root){
if (root==NULL) return p;
if (p->data < root->data) {
// 比根值小,左递归遍历比较
root->lch=insert(p,root->lch);
} else {
// 比根值大,右递归遍历比较
root->rch=insert(p,root->rch);
}
// 若不存在则插入
return root;
}
返回顶部
9.4 二叉排序树的删除
删除:首先查找到要删除的结点,删除后二叉排序树的中序序列仍然是按关键值递增有序。分三种情况:

(1)若*p结点是叶子,则直接删除。即:将双亲结点指向它的指针设置为空。
f->rch=NULL;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VMLCgtt1-1672621000045)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/数据结构/image-20221217221420875.png#pic_center)]](https://img-blog.csdnimg.cn/b4542429e7024311a4f8edd5b3dff646.png#pic_center)
(2)若*p为单分支结点,则只需用它唯一子树的根去继承它的位置。
f->lch=p->rch;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FDNNtNpA-1672621000046)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/数据结构/image-20221217221549158.png#pic_center)]](https://img-blog.csdnimg.cn/ab14367bc40941a2a07a166d3638b631.png#pic_center)
(3)若*p为双分支结点,用左子树中序遍历的最后一个结点(左子树的最右结点)替换*p。首先,沿*p的左子树的右链,查找到右指针域为空的结点*s,然后用*s的数据替换*p的数据,最后,删除*s结点
NODE *del(NODE *root, int x) {
NODE *p, *f, *s, *s_f;
if (root == NULL) return (root);
f = NULL;
p = root;
// 找到待删的节点
while (p != NULL && p->data != x) {
if (p->data > x)
if (p->lch != NULL) {
f = p;
p = p->lch;
}
else break;
else if (p->rch != NULL) {
f = p;
p = p->rch;
}
else break;
}
if (p == NULL || p->data != x) return (root);
if (p == root) return NULL;
if (p->lch == NULL && p->rch == NULL) {
if (f == NULL) {
free(p);
return (NULL);
}
if (f->lch == p) f->lch = NULL;
else f->rch = NULL;
free(p);
return (root);
}
if (p->lch == NULL) {
if (f == NULL) {
root = p->rch;
free(p);
return (root);
}
if (f->lch == p) f->lch = p->rch;
else f->rch = p->rch;
free(p);
return (root);
}
if (p->rch == NULL) {
if (f == NULL) {
root = p->lch;
free(p);
return (root);
}
if (f->lch == p) f->lch = p->lch;
else f->rch = p->lch;
free(p);
return (root);
}
s_f = p;
s = p->lch;
while (s->rch != NULL) {
s_f = s;
s = s->rch;
}
p->data = s->data;
if (s->lch == NULL) s_f->rch = NULL;
else s_f->rch = s->lch;
free(s);
return (root);
}
测试代码(参考:https://blog.csdn.net/weixin_46263870/article/details/121807060):
/**
* File : Work2_erchapaixushu.c
* Author: 骑着蜗牛ひ追导弹'
* Date: 2022/12/18
*/
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<windows.h>
#include<stdbool.h>
#include <time.h>
/*
3.随机产生一组关键字,利用二叉排序树的插入算法建立二叉排序树,然后删除某一指定关键字元素。
*/
//二叉排序树
typedef struct BST {
int data;
struct BST *left;
struct BST *right;
} *BST;
//插入结点
void InsertBSTree(BST *root, int k) {
if (!(*root)) {//当节点为空值时
BST p = (BST) malloc(sizeof(struct BST));
p->data = k;
p->left = p->right = NULL;
*root = p;
} else if ((*root)->data >= k)//当前结点值大于要插入的值,那就进入左子树
InsertBSTree(&(*root)->left, k);
else //当前结点值小于要插入的值,那就进入右子树
InsertBSTree(&(*root)->right, k);
}
//查找结点
bool FindBSTree(BST root, int k) {
//找到了返回真,没找到返回假
if (!root)
return false;//空树返回假
if (root->data == k)
return true;//找到了返回真
if (root->data >= k)
return FindBSTree(root->left, k);//去左子树里面找
if (root->data < k)
return FindBSTree(root->right, k);//去右子树里面找
}
//中序遍历打印二叉树
void PrintTree(BST root) {
if (!root)
return;
PrintTree(root->left);
printf("%d ", root->data);
PrintTree(root->right);
}
//创建二叉树
//循环调用插入函数来完成创建,如果
void CreateBSTree(BST *root, int num) {
int a;//a是随机数作结点值
for (int i = 0; i < num; i++) {
srand((unsigned) time(0));//随机数种子
a = rand() % 100;
Sleep(1000);//停留1s
if ((*root) && FindBSTree(*root, a))//不为空树并且树里面没有该值,如果树里有这个值就会执行continue语句从而重新生成一个数字
continue;
//因为srand((unsigned)time(NULL));取的是系统时间,也就是距离1970.1.1午夜有多少秒。而for循环一次远远小于1s,所以随机值种子不会变化,所以加一个sleep间隔一秒
InsertBSTree(root, a);
}
}
//删除结点
bool Delete(BST *root) {
BST pre, s;//pre作目标节点的前一个,s作要删除的结点
//1、右子树为空或叶子节点
if ((*root)->right == NULL) {
pre = *root; //保存好要删除的结点
*root = (*root)->left; //用他的左儿子代替这个位置
free(pre); //再释放掉要删除的结点
}
//2、左子树为空
else if ((*root)->left == NULL) {
pre = *root; //保存好要删除的结点
*root = (*root)->right; //用他的右儿子代替这个位置
free(pre); //再释放掉要删除的结点
}
//3、左右子树均不为空
//用要删除的结点的前驱节点的值来代替要删除的结点的值,然后再把这个前驱节点删除掉就可以了
else {
pre = *root; //保存好要删除的结点
s = (*root)->left; //s是他左子树的根节点
while (s->right) { //循环找到他左子树的最右的结点,也就是找到要删除结点的前驱节点
pre = s; //两个指针依次向下
s = s->right; //
}
//退出循环,s是被删结点的前驱节点,pre是s的前驱节点
(*root)->data = s->data;//这里是赋值,用前驱的值代替被删除的结点的值
if (pre != (*root)) //这里不等于代表着经过了循环,
pre->right = s->left;//因为前面已经把值赋过去了,后面会有删除,又因为s是(*root)的直接前驱说明s没有右儿子,所以这里把s可能有的左儿子连接到pre上
else //这里代表着没有经过循环,也就是说,s直接是(*root)的直接前驱
pre->left = s->left;
free(s); //这里是删除,释放掉这个前驱结点,因为前驱结点的值和儿子都交代完了就可以不要了
}
return true;
}
bool DeleteBSTree(BST *root, int k) {
if ((*root) == NULL)//空树或找不到目标值
return false;
if ((*root)->data == k)//找到目标值
return Delete(root);
if ((*root)->data > k)//当前结点值大于目标值,进入左子树找
return DeleteBSTree(&(*root)->left, k);
if ((*root)->data < k)//当前结点值小于目标值,进入右子树找
return DeleteBSTree(&(*root)->right, k);
}
void menu() {
printf("---------\n1、插入\n");
printf("2、删除\n---------\n");
}
int main() {
BST bstree = NULL;
int chose;
int num;//num作插入值
int num1;//num1作结点个数,
printf("输入结点个数:");
scanf("%d", &num1);
printf("请稍等...\n");
CreateBSTree(&bstree, num1);
printf("二叉排序树:");
PrintTree(bstree);//先遍历输出一次
printf("\n");
while (1) {
menu();
scanf("%d", &chose);
switch (chose) {
case 1:
printf("请输入要插入的值:");
scanf("%d", &num);
InsertBSTree(&bstree, num);
printf("新树:");
PrintTree(bstree);
printf("\n");
break;
case 2:
printf("请输入要删除的值:");
scanf("%d", &num);
if (DeleteBSTree(&bstree, num)) {
printf("新树:");
PrintTree(bstree);
printf("\n");
} else
printf("没有这个值!\n");
break;
default:
return 0;
}
}
return 0;
}

返回顶部
十、哈夫曼树
10.1 哈夫曼树的概念
路径:从一个结点到另一个结点之间的若干个分支
路径长度:路径上的分支数目称为路径长度;
结点的路径长度:从根到该结点的路径长度
树的路径长度:树中所有叶子结点的路径长度之和,一般记为PL。
- 在结点数相同的条件下,完全二叉树是路径最短的二叉树。
结点的权:根据应用的需要可以给树的结点赋权值;
结点的带权路径长度:从根到该结点的路径长度与该结点权的乘积;
树的带权路径长度 = 树中所有叶子结点的带权路径之和,通常记作:
W
P
L
=
∑
W
i
×
L
i
WPL = \sum W_i \times L_i
WPL=∑Wi×Li
哈夫曼树:假设有n个权值(
w
1
,
w
2
,
…
,
w
n
w_1 , w_2, … , w_n
w1,w2,…,wn ),构造有n个叶子结点的严格二叉树,每个叶子结点有一个
w
i
w_i
wi作为它的权值。则带权路径长度最小的严格二叉树称为哈夫曼树。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MiMUQ4tX-1672621000048)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221230093204999.png#pic_center)]
要使二叉树WPL最小,就须在构造树时,将权值大的节点靠近根。
返回顶部
10.2 哈夫曼数的应用


返回顶部
10.3 哈夫曼树的构造
1.根据给定的n个权值 ,构造n棵只有一个根结点的二叉树,n个权值分别是这些二叉树根结点的权。设F是由这n棵二叉树构成的集合
2.在F中选取两棵根结点树值最小的树作为左、右子树,构造一颗新的二叉树,置新二叉树根的权值=左、右子树根结点权值之和;
3.从F中删除这两颗树,并将新树加入F;
4.重复 2、3,直到F中只含一颗树为止;

返回顶部
10.4 哈夫曼编码
在进行数据通讯时,涉及数据编码问题。所谓数据编码就是数据与二进制字符串的转换。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SbjK639C-1672621000050)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221230094308812.png#pic_center)]](https://img-blog.csdnimg.cn/b065e18be0ce449da24215c207b58d48.png#pic_center)
前缀编码: 任何字符编码不是其它字符编码的前缀
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ngx3Rzhf-1672621000051)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221230094500832.png#pic_center)]](https://img-blog.csdnimg.cn/328ba3f9455e4b98b3e4e7dee4b87525.png#pic_center)
某通讯系统只使用8种字符a、b、c、d、e、f、g、h,其使用频率分别为0.05, 0.29, 0.07, 0.08, 0.14, 0.23, 0.03, 0.11,编程实现利用二叉树设计一种不等长编码:
1)构造以 a、b、c、d、e、f、g、h为叶子结点的二叉树;
2)将该二叉树所有左分枝标记1,所有右分枝标记0;
3)从根到叶子结点路径上标记作为叶子结点所对应字符的编码;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XEImAU7m-1672621000051)(https://gcore.jsdelivr.net/gh/Code-for-dream/Blogimages/img/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image-20221230104005523.png#pic_center)]](https://img-blog.csdnimg.cn/b64da75825cd4f1ba33d4dcdb780c0b5.png#pic_center)
/**
* File : Work3_HuffmanTree.c
* Author: 骑着蜗牛ひ追导弹'
* Date: 2022/12/30
*/
/*哈夫曼树及哈夫曼编码实现*/
# include<stdio.h>
# include<malloc.h>
# include<string.h>
# define N 30 //叶子结点的最大值
# define M 2 * N - 1 //所有结点的最大值
# define MAX 99999
/*哈夫曼树的类型定义*/
typedef struct {
int weight; //结点的权值
int parent; //双亲的下标
int LChild; //左孩子结点的下标
int RChild; //右孩子结点的下标
} HTNode, HuffmanTree[M + 1]; //HuffmanTree是一个结构数组类型,0号单元不用
HuffmanTree ht;
/*在ht[1]至ht[n]的范围内选择两个parent为0且weight最小的结点,其序号分别赋给s1,s2*/
void Select(HuffmanTree ht, int n, int *s1, int *s2) {
int i, min1 = MAX, min2 = MAX;
*s1 = 0;
*s2 = 0;
for (i = 1; i <= n; i++) {
if (ht[i].parent == 0) {
if (ht[i].weight < min1) {
min2 = min1;
*s2 = *s1;
min1 = ht[i].weight;
*s1 = i;
} else if (ht[i].weight < min2) {
min2 = ht[i].weight;
*s2 = i;
}
}
}
}
/*创建哈夫曼树算法*/
void CrtHuffmanTree(HuffmanTree ht, int w[], int n) {
//构造哈夫曼树ht[M+1],w[]存放n个权值
int i;
for (i = 1; i <= n; i++) { //1至n号单元存放叶子结点,初始化
ht[i].weight = w[i - 1];
ht[i].parent = 0;
ht[i].LChild = 0;
ht[i].RChild = 0;
}
int m = 2 * n - 1; //所有结点总数
for (i = n + 1; i <= m; i++) { //n+1至m号单元存放非叶结点,初始化
ht[i].weight = 0;
ht[i].parent = 0;
ht[i].LChild = 0;
ht[i].RChild = 0;
}
/*初始化完毕,开始创建非叶结点*/
int s1, s2;
for (i = n + 1; i <= m; i++) { //创建非叶结点,建哈夫曼树
Select(ht, i - 1, &s1, &s2);//在ht[1]至ht[i-1]的范围内选择两个parent为0且weight最小的结点,其序号分别赋给s1,s2
ht[i].weight = ht[s1].weight + ht[s2].weight;
ht[s1].parent = i;
ht[s2].parent = i;
ht[i].LChild = s1;
ht[i].RChild = s2;
}
}
/*哈夫曼编码*/
void CrtHuffmanCode(HuffmanTree ht, int n, char str[]) {
//从叶子结点到根,逆向求每个叶子结点(共n个)对应的哈夫曼编码
char *cd;
cd = (char *) malloc(n * sizeof(char)); //分配当前编码的工作空间
for (int i = 1; i <= n; i++) { //求n个叶子结点对应的哈夫曼编码
int start = n - 1, c = i, p = ht[i].parent;
while (p != 0) {
--start;
if (ht[p].LChild == c) //左分支标0
cd[start] = '0';
else
cd[start] = '1'; //右分支标1
c = p; //向上倒堆
p = ht[p].parent;
}
printf("%c的编码:", str[i - 1]);
for (int j = 0; j < n; j++) {
if (cd[j] == '0' || cd[j] == '1') {
printf("%c", cd[j]); //编码输出
}
}
printf("\n");
memset(cd, -1, n);
}
}
int main() {
int i, w[8] = {5, 29, 7, 8, 14, 23, 3, 11};
char str[8] = {'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'};
CrtHuffmanTree(ht, w, 8);
printf("哈夫曼树各结点值:\n");
for (i = 1; i <= 9; i++)
printf("%d ", ht[i].weight);
printf("\n");
CrtHuffmanCode(ht, 8, str);
return 0;
}

返回顶部