原文网址:MySQL--整合Keepalived进行双机热备自动切换(升级版)_IT利刃出鞘的博客-CSDN博客
简介
本文介绍MySQL整合Keepalived进行双机热备自动切换(升级版)。
服务器要考虑高可用问题。nginx、tomcat、缓存、队列、数据库,每个环节高可用的最基本要求是避免单点故障,能够自动failover。
我的目的:数据库主库挂了,一定要能自动切换,否则公司停摆。。。
我的要求:简单实用、可靠、主从不要轻易切、尽最大可能不脑裂、不丢事务。
网上常见的一个简单的方案是:mysql双主+Keepalived。猛一看很完美:mysql两个库可写、keepalived任意切换,像管理无状态服务一样自在……,其实这种方案有很明显的缺点:主从同步有延迟时,如果发生切换,发生数据错乱的概率太高(对于很多系统来说,宁可宕机几分钟,也不要产生大量脏数据)
如果不差钱,可以直接使用阿里云的RDB,支持容灾、备份、恢复、监控、迁移等全套解决方案。阿里云RDS基础版110元/月。
方案概述
我的方案是对mysql双主+keepalived的方案的改进:mysql主从半同步复制+keepalived+第三方程序和数据辅助切换判断
主要特点:
1、从库只读,切换为主时才可写
2、keepalived不配置virtual_ipaddress,由notify脚本实现IP漂移
3、把主从切换置于“重量级”的等级,不要轻易切换:
keepalived监控连续失败2分钟再切换(如mysqld宕机后能被mysqld_safe重启,则不切换);
切换脚本要判断很多逻辑,确保不会人为失误导致切换,也确保从库不满足切换条件时不会切换。
4、切换是单向的,从切为主后,需要重建部署主从环境
5、说到MHA,很多人会担心脑裂问题,keepalived网络环境比mha简单,在确保主从两节点在一个二层网络时,即便keepalived发生了脑裂(即双节点都有VIP),ARP广播可以确保只有一个节点的VIP是可以对外服务的,因此脑裂导致脏数据的可能性接近为零。
项目名称:mkf (mysql keepalived failover)
脚本地址:https://github.com/meishd/mkf
架构图:
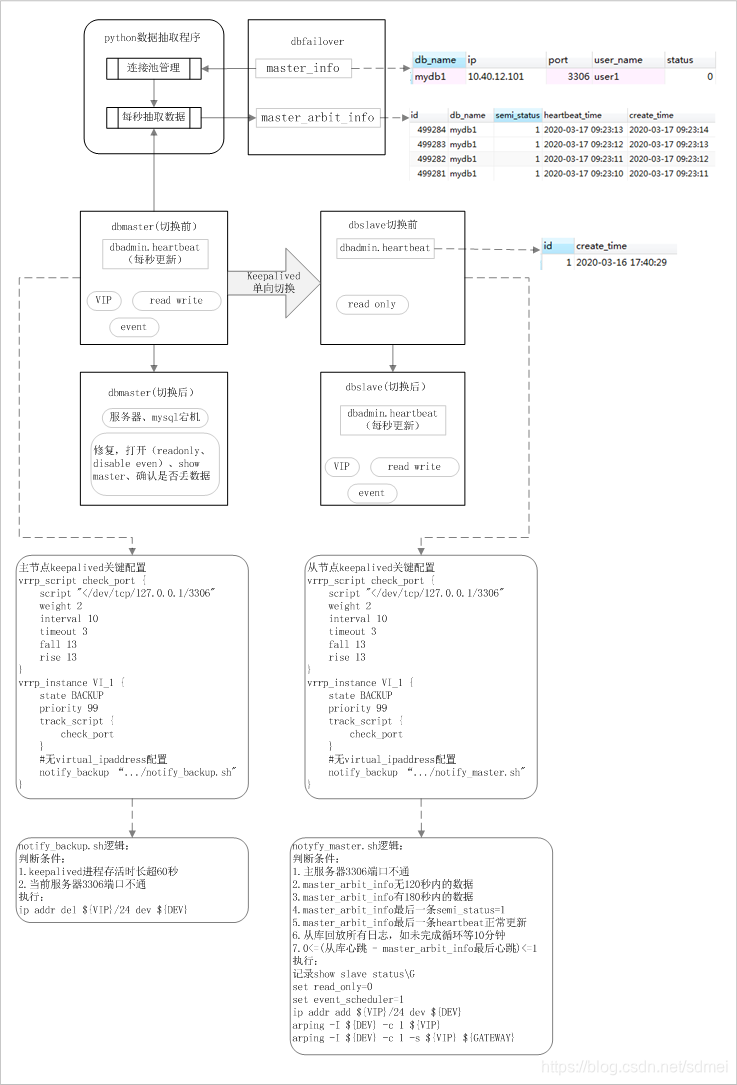
方案说明
心跳表
所有的数据库有一个心跳表dbadmin.heartbeat(id,create_time),JOB每秒更新create_time,该表是我们用来监控从库同步延迟的;这里用这个表判断从库是否满足切主条件。
python数据抽取与dbfailover
dbfailover位于独立的实例,包括两张表:主库配置表master_info,切换仲裁信息表master_arbit_info
master_info自动:
- db_name primary key 唯一标识一套主从的数据库名称
- ip 主IP,切换后要改之
- port 端口
- user_name 用户名
- status 状态,0:启用,1:禁用
- update_time DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,根据该字段判断是否需要reset连接池
master_arbit_info字段:
- id auto_increment
- db_name 数据库名称
- semi_status 半同步状态,1:同步,0:异步
- heartbeat_time 心跳表记录的时间
- create_time 当前时间
python程序读取master_info表初始化每个主库的连接池,定期(10秒)检测连接池、失效重连,定期(每秒)抽取信息到master_arbit_info。
主节点控制
主连续宕机120秒(interval 10,fall 13)才切换,自动重启不切换,避免轻易切换;
主节点通过notify_backup控制VIP删除,降低运维操作的风险、避免对主库正常使用的影响
- 便于线上无缝实施,初始配置时不会影响现有VIP正常访问;
- 主节点只有notify_backup,确保切换单向,进入master无额外操作;
- 刚启动keepalived时主节点会先短暂进入backup状态,再进入master状态,脚本可以根据启动时间判断退出VIP删除操作;
- 正确的启动顺序:先启动主keepalived、再启动从keepalived,如误操作先启动从,则主keepalived进入backup状态,此时通过判断mysql端口退出VIP删除操作。
从节点控制
从节点通过notify_master控制从升为主,目的是尽最大可能确保从库不丢事务才能升为主,否则宁可不切换。
以下是必须按顺序满足的条件,否则终止操作:
- 主服务器3306端口不通
- master_arbit_info无120秒内的数据
- master_arbit_info有180秒内的数据
- master_arbit_info最后一条semi_status=1
- master_arbit_info最后一条heartbeat正常更新
- 从库回放所有relay log,如未完成,每3秒检测1次,超时时间10分钟
- 0<=(从库心跳 - master_arbit_info最后心跳)<=1秒
满足上述条件后,从库正式执行切换操作:
- 记录slave状态show slave status\G,用于主恢复后确认是否丢事务
- set read_only=0
- set event_scheduler=1
- ip addr add ${VIP}/24 dev ${DEV}
- arping -I ${DEV} -c 1 ${VIP}
- arping -I ${DEV} -c 1 -s ${VIP} ${GATEWAY}
从库正常切为主后的日志:
# tail -20 notify_master.log
20200318 14:42:48 notify master begin...
20200318 14:42:48 1. master is offline
20200318 14:42:48 2. master_arbit_info records within 120 seconds: 0
20200318 14:42:48 3. master_arbit_info records within 180 seconds: 52
20200318 14:42:48 4. master_arbit_info last semi status: 1
20200318 14:42:48 5. master_arbit_info last heartbeat_time after create_time: 0
20200318 14:42:48 6. slave exec log lag behind read log: 0
20200318 14:42:48 7. heartbeat lag between master and slave: 1
20200318 14:42:49 switch to master
Warning: Using a password on the command line interface can be insecure.
20200318 14:42:49 add vip
ARPING 10.40.12.104 from 10.40.12.104 eth1
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
ARPING 10.40.12.254 from 10.40.12.104 eth1
Unicast reply from 10.40.12.254 [84:D9:31:9F:29:75] 1.416ms
Sent 1 probes (1 broadcast(s))
Received 1 response(s)
20200318 14:42:51 notify master end
# more slave_status.log.20200318_144248
Warning: Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
Slave_IO_State: Reconnecting after a failed master event read
Master_Host: 10.40.12.101
Master_User: lbadmin
Master_Port: 3366
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 74770
Relay_Log_File: relay-bin.000005
Relay_Log_Pos: 74980
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Connecting
Slave_SQL_Running: Yes
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 74770
Relay_Log_Space: 137461
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'lbadmin@10.40.12.101:3306' - retry-time: 60 retries: 3
Last_SQL_Errno: 0测试用例
| 测试对象 | 判断条件 | 异常条件模拟 |
| 主库 notify_backup.sh | 1.keepalived启动时间超过60秒 | 每次新启动keepalived时会短暂进入backup状态,再进入master状态,触发异常 |
| 2.mysql端口不通 | 主节点keepalived.conf将notify_backup误写为notify_master,启动后触发异常 | |
| 从库 notify_master.sh | 1.主服务器mysql端口不通 | 先起从节点keepalive,导致从进入master状态,触发异常 |
| 2.master_arbit_info无120秒内的数据 | keepalived监测脚本判断时间不足120秒,如interval 10,fall 5 | |
| 3.master_arbit_info有180秒内的数据 | python数据抽取程序挂了 | |
| 4.master_arbit_info最后一条semi_status=1 | 做大数据量的DML,或者从库stop slave一段时间后再起,确保半同步降级2分钟以上,关主库 | |
| 5.master_arbit_info最后一条heartbeat正常更新 | 主库关闭heartbeat job | |
| 6.从库回放所有日志,如未完成循环等10分钟 | 主库DDL大表,DDL完成后关主库 | |
| 7.0<=(从库心跳-master_arbit_info最后心跳)<=1 | 不好用实际场景模拟,关主库后删除master_arbit_info表2条最新的数据 |
运维操作
python程序部署
- 创建第三方mysql库dbfailover,执行脚本install_dbfailover.sql,将需要维护的主库信息初始化至master_info
- 在被管理的主库执行install_dbtarget.sql
- 部署python数据抽取程序(可以和dbfailover同服务器):安装python3环境,requirement: PyMySQL==0.9.3 DBUtils==1.3 APScheduler==3.6.3,设置mkf.py中的dbmanager连接池信息: managerdb_pool = PooledDB(host='dbmanater_ip',user='user1',passwd='password1')
- 启动脚本: python mkf.py
主从库环境部署
主从服务器上安装部署keepalived
主节点配置文件:keepalived_master.conf,脚本文件:notify_backup.sh
从节点配置文件:keepalived_slave.conf,脚本文件:notify_master.sh
其中keepalived_master/slave.conf修改IP信息,notify_backup/master.sh修改文件头的变量
启停keepalived顺序
启动时先起主节点keepalived,再起从节点keepalived;
如果先起从后起主,不会对线上业务有影响,但是要重启从节点的keepalived,确保主进入master状态。
failover后的操作
停止两节点的keepalived;
如果老主服务器可修复,查看Executed_Gtid_Set信息,与从节点切换为主时记录的slave status比较,确认是否有事务丢失;
如有事务丢失则解析binlog,与研发一起处理数据问题,无则搭建新的主从,调整keepalived配置;
更新master_info中的IP信息,python程序会在10秒内自动更新连接池配置。
其他网址
mysql高可用自动切换方案(半同步复制+keepalived+第三方数据逻辑判断)_sdmei的博客-CSDN博客_mysql自动切换方案