一、Spark理解
数据的操作只有两种
大数据领域中对数据的操作只有两种:聚合 & 处理
无论是多华丽算法,最终都是这两个平平无奇的操作组合而成的
action理解
在spark中,一个action操作为一个jobId(在源码中可以看到runjob 是只有在action操作后才会调用) ,
所以一个应用程序jar包提交后可以生成多个job,因为用户可能会在程序中使用多个action操作。
在SparkUI上jobs列表中可以看清楚
闭包理解
关于spark的闭包检查功能,在java中我们使用lambda表达式的时候变量必须是final的,但是却不会检查匿名函数中的类变量是否实现了序列化,这是因为在java中默认是在一个JVM中执行的!
但在spark中,我们使用匿名函数时,例如: rdd.map(x => user.setAge(x)) 时, 此时spark的闭包则会先检查匿名函数中的是否有类变量,
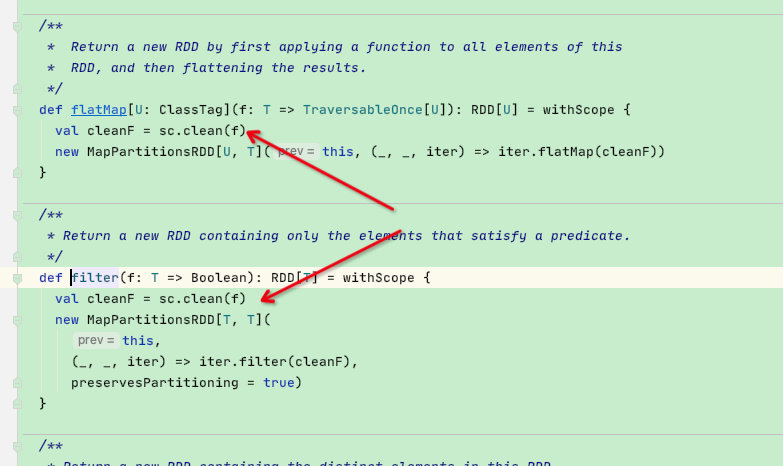
如果有类变量则判断是否序列化,这是由于spark中是分布式计算,故spark的闭包需要检查类变量是否实现了序列化接口,那么这块检查代码在rdd的map/flatmap等函数的第一行就有:val cleanF = sc.clean(f) ; 此函数就是用来检查闭包的!