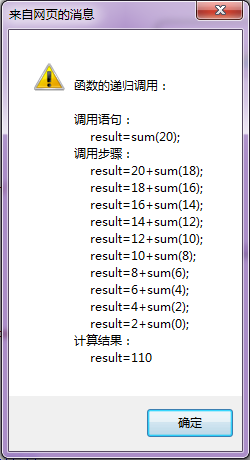
数字营销最吸引人的部分之一是对数据的内在关注。
如果一种策略往往有积极的数据,那么它就更容易采用。同样,如果一种策略尚未得到证实,则很难获得支持进行测试。
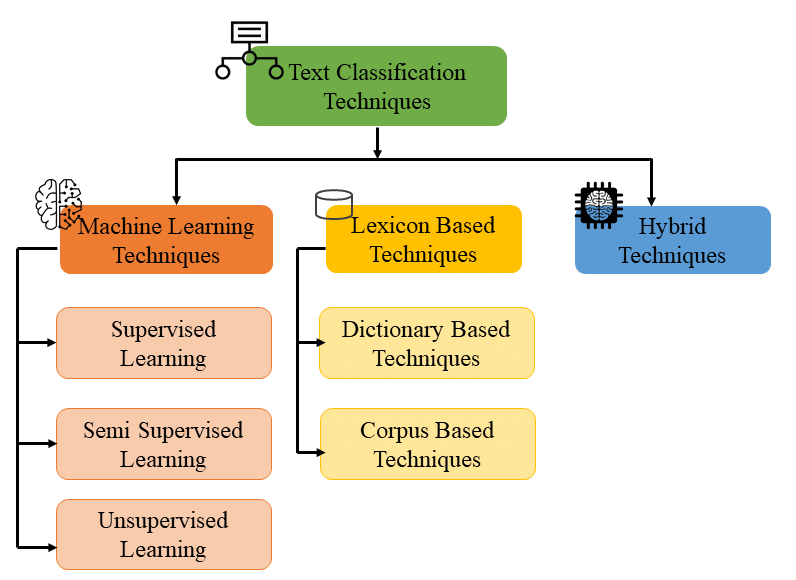
数字营销人员建立数据信心的主要方式是通过研究。这些研究通常分为两类:
- 轶事:然而,数据点数量有限,通常有更多关于单个机制的细节。
- 具有统计显著性:大量数据点(通常为 100+),由于要分析的实体数量庞大,这些数据点可能被迫进行更简单的分析。
这两个数据集在制定数字营销策略中都占有一席之地。这就是为什么过分依赖其中一个是危险的。
作为一个在能够发布这两种数据集的组织工作过的人,以及这两种数据集的狂热消费者,我认为深入研究会很有用:
- 每种研究类型的最低标准。
- 品牌可以从这两种类型的研究中获得什么价值。
- 如何建立自己的学习。
这篇文章将着眼于数字营销学科中的一些不同研究。
这是因为管理轶事(较小数据)和具有统计意义(大数据)的核心原则在营销学科中非常相似。
每种研究类型的最低标准
人们在进行研究时常犯的一个错误是认为数据量是使他们的研究有价值的唯一标准。
是的,当有大量数据时,这很可爱,但还有其他关键因素:
- 正在考虑多少变量?
- 对于异常值/多余变量,有哪些缓解措施(如果有)?
- 该研究能否用数据与情感来回应批评者?
无论您专注于轶事研究还是具有统计学意义的研究,这三个都将是最低要求。但是,也有一些特定于研究的标准。
轶事研究
当查看较小的数据集时(即少于 10 个帐户、少于一年的数据等),要深入研究要测试的任何事物的前后影响的压力要大得多。
人们会想要尽可能多的细节,因为该研究通常会显示一个帐户/一个品牌所采取的具体行动的结果。
这意味着屏幕截图将至关重要。如果你不能确切地显示发生了什么,它就不会被认真对待。
但是,屏幕截图不需要您透露您正在为之工作的客户。过滤掉品牌名称是绝对合理的。
省略基准、重要指标以及一项计划是否具有“不公平的优势”(大预算、品牌活动等)则不然。
轶事研究的一个很好的例子是研究几个月内变化的影响。这张来自 Will O’Harra 的图表显示了“粉丝”网站与大牌网站的网站流量变化。
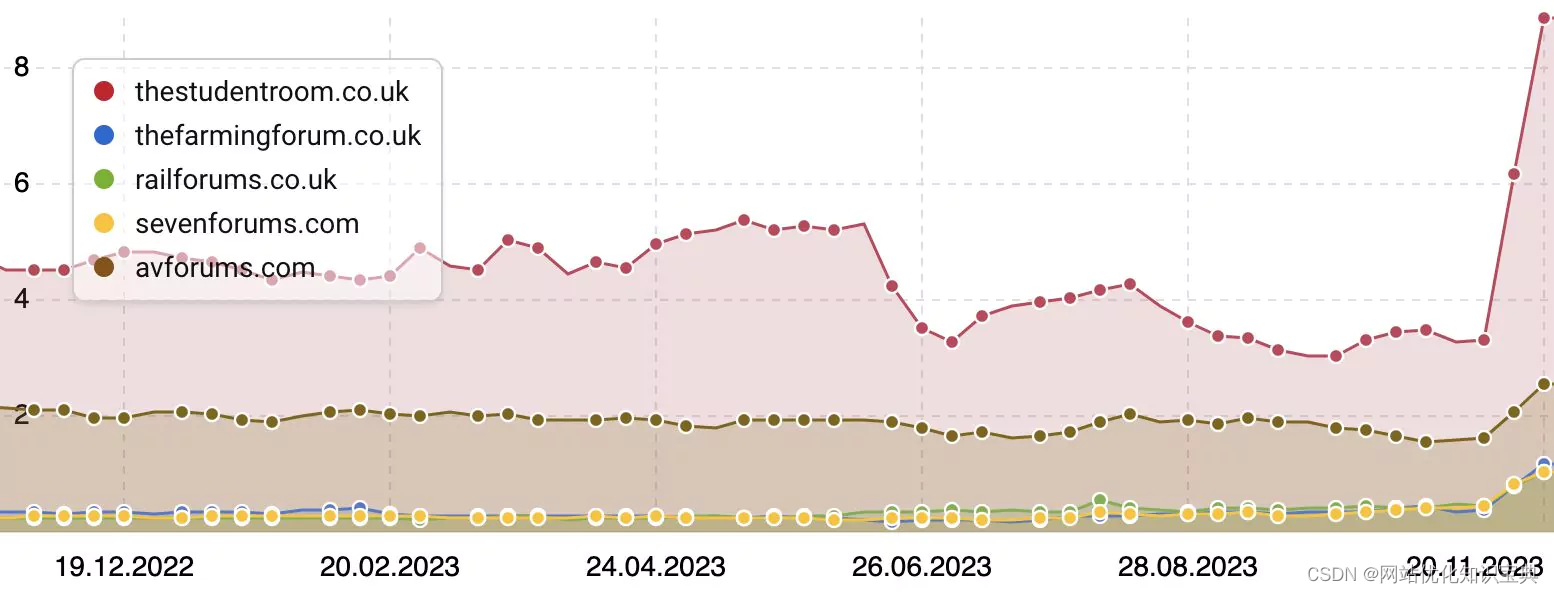
在这项研究中,我们可以看到,由于质量内容标准的变化,原本流量较低的网站得到了很大的飙升。这是一项轶事研究,因为它只研究了五个地点。
大数据研究
人们会因为轶事研究缺乏细节而相当不宽容,而大数据研究则得到了更多的宽容。
这是因为他们的主要衡量标准是反映特定趋势的账户数量。然而,这并不意味着大数据研究不受审查,只是重点放在不同的事情上。
大数据在纳入标准上需要非常严格。包含的实体需要尽可能靠近彼此。
此外,大数据研究通常需要大量实体。如果您要对特定趋势发表评论,则需要有足够的数量来支持该声明。
品牌可以从这两种类型的研究中获得什么价值
只关注一种类型的研究可能很诱人。但是,两者都有其位置,并且可以为有意义的客户策略提供信息。
大数据有助于了解可能影响您帐户的总体概念和趋势。这些将是指导原则,例如:
- 哪些结构选择的成功机会更高?
- 内容生成工作的重点在哪里。
- 人们是如何花钱的?
- 何时在买家漏斗中使用哪种类型的消息传递?
这些学习的用处在于,它们为你提供了一个形成战略的良好起点。它们也有助于检查自己的理智。
例如,才华横溢的 Mike Ryan (SMEC) 进行了一项研究,研究了成功的 PMax 活动需要多少转化。虽然这些数据在每种情况下都很有用,但知道它基于 14,000 个广告系列是有帮助的。

从这些数据中,我们可以看到,为了取得不错的效果,我们的 PMax 广告系列应该在 30 天内至少获得 60 次转化。
如果不能,可能值得评估其他广告系列类型。在这项研究的结果之外,一个账户很有可能成功,但它们将是一般规则的异常值。
同样,同样聪明和有趣的Greg Gifford(搜索实验室)对Google Business Profile列表进行了一项研究,以评估“最佳实践”是否真的经得起分析。
他和他的团队研究了 1,000 家经销商,发现一些最佳实践是正确的,而另一些则是相关性而不是因果关系。
轶事研究会更好地给你“疯狂而疯狂的想法”来测试。它们也非常适合风险承受能力强的人探索新兴趋势。
如何建立自己的研究
建立研究归结为了解研究的范围以及它的可重复性。如果你只做一次研究,它就没有那么有用了,因为趋势总是在变化。
此外,如果范围太窄或太宽,可能会使数据混乱或无法完全解决重要问题。
确保你的假设为你留下了被证明是错误的空间。
如果你不采取预防措施,数据可以说明任何事情。对所包含的内容和原因保持严格的指导方针至关重要。