1、减少长文本模糊匹配,降低 CPU 大量分词上的开销
长文本全文查询由于在查询时需要进行分词处理,因此在查询并发较大的情况下, cpu会先于IO被打满,从而出现大量的查询拒绝。
2、设置多副本提高并发和均衡单节点压力
Search查询请求是从索引的主副本分片中随机选择一个分片进行查询,因此 多个副本可以充分利用多节点性能,避免 单节点压力过大导致整体性能下降。
3、使用 SSD 硬盘,读多写少场景比高性能云盘性能提升
当索引的段很多的时候,实际上请求过程,是很多小文件的IO。在聚合分析请求中,也是非常吃IO资源的。特别是大规模是的聚合分析。通常是IO先于CPU跑满,导致load高。
SSD至少有30以上的提升。这里跟我我自己的生产经验。云上的服务器的IO性能普遍虚高。没有本地机房的效果好。
4、频繁更新的索引要定期执行 Forcemerge,降低查询时Segment文件的遍历
频繁更新的索引会产生大量的soft_deleted文档,既占用磁盘空间,还会消 耗查询性能,建议在低峰期定期执行ForceMerge。
执行forcemerage常用API:
POST /my-index/_forcemerge
POST /myindex/_forcemerge?max_number_segme
nts=1
POST /myindex/_forcemerge?only_expunge_delete
s=true
5、利用缓存:不需要算分的查询使用 filter context 代替 query
query 关注的是此文档与查询子句的匹配相关度如何? filter 关注的是此文档与查询子句是否匹配,是否满足查询条件?(不涉 及算分) 具体说明可参考官方文档。使用filter可以跳过打分过程,从而降低延迟。
6、搜索排序场景在写入时对索引设置Index Sorting数据提前排序,减少随机 IO,提升查询性能
默认情况下,Lucene 不会做任何排序操作,Search 请求必须检索与查询相匹配的 所有文档,然后返回按指定字段排序的 TopN 文档。 而通过 index.sort.* 设置可以对Segment内的特定字段进行排序,字段类型支持 boolean、numeric、date 和 keyword(doc_values)。详情可参考官方文档。
通过降低写入速度间接提升检索速度,适用于读多写少场景。
PUT index_name
{
"settings": {
"index": {
"sort.field": "timestamp",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"timestamp": {
"type": "date"
}
}
}
}
GET /index_name/_search
{
"size": 10,
"sort": [
{ "timestamp": "desc" }
]
}
ES会检查每个提前排好序的segment文件
的topN条doc返回,而不再对shard上所有
的segment文件进行遍历,大大降低查询耗
时。7、为文件系统缓存预留足够的内存空间
ES的检索性能高度依赖底层的 Filesystem Cache,如果给 Filesystem Cache 预留足够的内存,那么搜索时候将基本都是走内存,检索性能会非常高。
建议
机器的总内存容量至少可以容纳索引数据量的一半
,并预热Filesystem Cache, 这样基本可以做到亿级文档毫秒级响应。详情可参考官方文档。

8、 自定义 routing 写入和检索,减少分片查询范围
自定义 routing 查询,可以做到精准分片检索,减少索引分片的 查询范围,提升查询性能。
容易踩坑的点:
如果routing存在严重数据不均等情况,可能会出现严重的热点分 片和查询超时问题。
这种情况下先通过reindex临时解决问题,长期解决需去除自定义 routing并拆分索引。
9、docvalue_fields 替代 source,降低查询过程中解压及网络传输开销
- 从 source中 取数据,由于走的是行存,因此每次查询都会读取一行数据, 从一行数据中过滤字段,其中在解压、序列化等操作上有较多的性能开销
- 通过使用 docvalues_fileds 替代source,由于是直接从列存中取数据,可 以大大降低检索过程中的source 字段的解压缩及序列化开销。行存检索变列存检索
- 通过将 stored_fileds 设置为 _none_,可以降低返回结果的流量消耗,提 升查询性能
经验总结:
docvalue_fields + stored_fileds 结合使用,可大幅度提升查 询性能。
GET filebeat-7.2.1/_search
{
"from": 0,
"size": 5000,
"_source": {
"includes": [
"region","host.name”
]
}
}GET filebeat-7.2.1/_search
{
"from": 0,
"size": 5000,
"stored_fields": ["_none_"],
"docvalue_fields": [
"region","host.name”
]
}这里看到测试结果。提升有数10倍。

此优化不适用的场景:
需要取回的字段中包含如下情况:
1、text类型相关的字段
2、嵌套类型的对象
3、显示设置doc_value为false的字段("doc_values": false)
10、docvalue_fields 替代 source,降低查询过程中解压及网络传输开销
性能测试:
基于8C 32G 规格,构建100w 条测试数据(每条数据包含100个字段)不断变化查询字段数进行查询,得到如下结果:
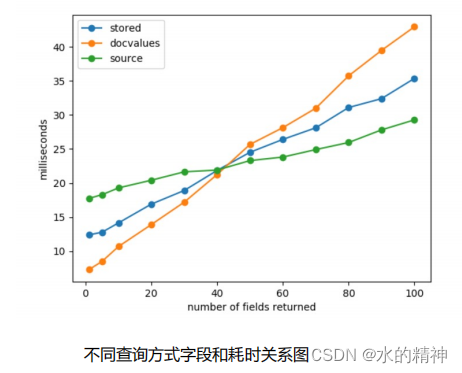
性能测试结果分析:
1、当字段数很少时,低于40,使用 doc_value Fields 拉取,耗时最低,性能最优。
分析:
如果我们只需要返回其中包含的一小部分字段时,读取并解压这个巨大的
_source字段可能会开销很高。
2、
当字段超较多时,达到40以上时,使用 _source 耗时最低,查询性能最优。
分析:
当需要非常多、几乎全部字段时,此时使用 doc_value Fields 可能会有非常多
的随机IO。此时读取 _source 一个字段就能够包含几乎全部字段,耗时最低。
3、在不同数据场景下,_source、列存、Store 查询性能的平衡点可能会偏移,还是
需要实际的压测





![[Big Bird]论文解读:Big Bird: Transformers for Longer Sequences](https://img-blog.csdnimg.cn/direct/3874e79640974bf9bf1df85a1c18262f.png)