文章目录
- 迭代器
- Iterator
- 1、什么是Iterator
- 2,iterator接口的API
- 3、Irerator()方法细节解释
- 4. Irerator的原理示意图
- 4. 1 Irerator的案例
- 5. forEach循环与Iterator遍历的区别与联系
- ListIterator
- 1.ListIterator的概述
- (1) 概念
- (2) 解析
- 2.ListIterator的生成
- 3.ListIterator的API
- 4.ListIterator的add方法解析
- 5.ListIterator与Iterator的区别
- java集合遍历
- 1. ArrayList的遍历方式
- 第一种,通过迭代器遍历。即通过Iterator去遍历。
- 第二种,随机访问index,通过索引值去遍历。
- 第三种,增强for循环遍历。如下:
- 第四种,forEach遍历。如下:
- 第五种,stream流式遍历
- 第六种,forEachRemaining方法遍历:继续输出其余的元素
- 2. LinkedList的遍历方式
- 第七种:通过pollFirst()来遍历LinkedList,获取并移除此列表的第一个元素;如果此列表为空,则返回 null
- 第八种:通过pollLast()来遍历LinkedList,获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
- 第九种:通过removeFirst()来遍历LinkedList,移除并返回此列表的第一个元素。 NoSuchElementException - 如果此列表为空。
- 第十种:通过removeLast()来遍历LinkedList,移除并返回此列表的最后一个元素。NoSuchElementException - 如果此列表为空。
- 3. Set集合的遍历方式
- 4. Map集合的遍历方式
- ①for-each + keySet()/values()遍历key/Value
- ②[重要]for-each + entrySet()遍历
- ③for-each + keySet() + get()方法遍历
- ④Iterator + entrySet()遍历
- ⑤[重要]lambda表达式遍历
- ⑥stream流遍历
- 总结——简洁又好用的遍历方式
迭代器
Iterator
1、什么是Iterator
迭代的概念: Collection集合元素的通用获取方式,再取元素之前要先判断集合中有没有元素,如果有,就把这个元素取出来,继续在进行判断,如果还有就再取出来,一直把集合中的所有元素取出,这种取出方式专业术语就叫做迭代
一些集合类提供了内容遍历的功能,通过java.util.Iterator接口。这些接口允许遍历对象的集合。依次操作每个元素对象。当使用 Iterators时,在获得Iterator的时候包含一个集合快照。通常在遍历一个Iterator的时候不建议修改集合本身。
2、Iterator与ListIterator有什么区别?
Iterator:只能正向遍历集合,适用于获取移除元素。ListIerator:继承Iterator,可以双向列表的遍历,同样支持元素的修改。
2,iterator接口的API
boolean hasNext() 如果仍有元素就可以迭代,返回的就是true,
判断集合中还有没有下一个元素,有就返回true,没有就返回false
E next() 返回迭代的下一个元素。
void remove() 从迭代器指向的集合中移除迭代器返回的最后一个元素(可选操作)。
Iterator也是一个接口,我们无法直接使用,需要使用Iterator接口的实现类。
在Collection接口中有一个方法,Iterator(),这个方法的返回值就是迭代器的实现类
3、Irerator()方法细节解释
Iterator iterator = col.iterator();//获取迭代器对象
hasNext(): 判断游标右边是否还有下一个元素,默认游标都在集合的第一个元素之前。
注意:此时只是判断是否有下一个元素,并不移动指针。
while(iterator.hasNext()){
//next():①指针下移 ②将下移以后集合位置上的元素返回
Object next = iterator.next();
System.out.println(“next=”+next);
}
迭代过程如图所示:
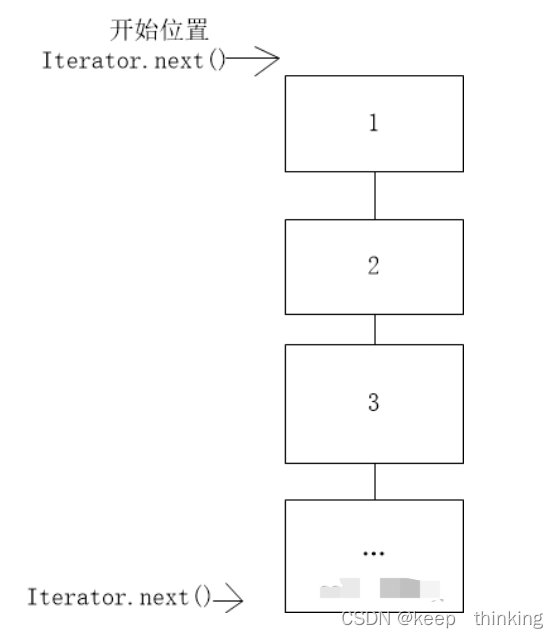
(1)、如果iterato.next()指向的内存中如果没有元素会抛出异常
(2)、当退出while后,iterator.hasNext()中next已经走到尾部,若继续调用iterator.hasNext()将会报错(若要继续遍历,可通过重置迭代器解决)
(3)、void remove()方法 :删除当前指针所指向的元素,一般和next方法一起用,这时候的作用就是删除next方法返回的元素,如果当前指针指向的内存中没有元素,那么会抛出异常
4. Irerator的原理示意图

4. 1 Irerator的案例
Collection coll = new ArrayList(); //面向对象中的多态coll.add(1);
coll.add("abc");
coll.add(1.23);
coll.add("张三");
for(Iterator it = coll.iterator();it.hasNext();){
Object obj = it.next();
System.out.println(obj);//输出1 abc 1.23 张三
}
Iterator it = coll.iterator();
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);//输出结果;1 abc 1.23 张三
}

5. forEach循环与Iterator遍历的区别与联系
(1)使用范围不同
forEach: 不仅可以在集合中使用,也可以在数组中遍历使用
Iterator:专门为遍历集合而生,集合并没有提供专门的遍历的方法。在数组中不能遍历用
(2)遍历过程不同
iterator.remove() 删除当前遍历到的值
foreach遍历集合元素时不能调用remove删除元素,否则会出现ConcurrentModificationException
(3)增强的for循环和Iterator的联系
增强的for循环(遍历集合)时,底层使用的是Iterator
凡是可以使用增强的for循环(遍历的集合),肯定也可以使用Iterator进行遍历
ListIterator
1.ListIterator的概述
(1) 概念
官方文档说,此接口只是用于List的迭代器,通过它我们可以从任意方向遍历列表、在迭代期间修改列表、获取迭代器在列表中的当前位置。ListIterator没有当前元素(current element),它的光标总是处于调用previous()方法返回的元素和next()方法返回的元素之间。长度为n的列表,它的迭代器有n+1个光标位置

绿色代表ListIterator迭代器的位置,在ListItarator中迭代器的位置都是指的光标的位置。红色代表List列表中的元素,把这张图存脑袋里,把这张图存脑袋里,把这张图存脑袋里,这个接口的所有操作都没啥障碍了。
(2) 解析
在使用java集合的时候,都需要使用Iterator。但是java集合中还有一个迭代器ListIterator,在使用List、ArrayList、LinkedList和Vector的时候可以使用。这两种迭代器有什么区别呢?下面我们详细分析。这里有一点需要明确的时候,迭代器指向的位置是元素之前的位置,如下图所示:
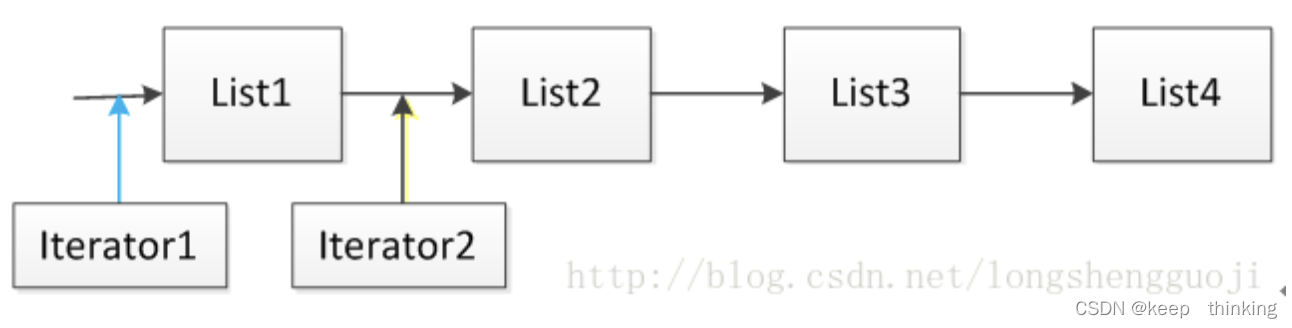
这里假设集合List由四个元素List1、List2、List3和List4组成,当使用语句Iterator it = List.Iterator()时,迭代器it指向的位置是上图中Iterator1指向的位置,当执行语句it.next()之后,迭代器指向的位置后移到上图Iterator2所指向的位置。
2.ListIterator的生成
List<Integer> list =Arrays.asList(1,2,3,4);
ListIterator<Integer> it = list.listIterator(); 无参
ListIterator<Integer> it1 = list.listIterator(list.size()); 有参
3.ListIterator的API
add(E e): 将指定的元素插入列表,插入位置为迭代器当前位置之前
hasNext():以正向遍历列表时,如果列表迭代器后面还有元素,则返回 true,否则返回false
hasPrevious(): 如果以逆向遍历列表,列表迭代器前面还有元素,则返回 true,否则返回false
next():返回列表中ListIterator指向位置后面的元素
nextIndex(): 返回列表中ListIterator所需位置后面元素的索引
previous(): 返回列表中ListIterator指向位置前面的元素
previousIndex():返回列表中ListIterator所需位置前面元素的索引
remove(): 从列表中删除最后一次执行next()或previous()方法返回的元素。(有点拗口,意思就是对迭代器使用hasNext()方法时,删除ListIterator指向位置后面的元素;当对迭代器使用hasPrevious()方法时,删除ListIterator指向位置前面的元素)
remove使用时注意三点:
1.调用remove()方法之前,一定要有next()或previous()方法执行,
否则报错:java.lang.IllegalStateException
2.执行next() 或 previous()之后与执行remove()之前,不能执行add(E)方法,
'否则报错: java.lang.IllegalStateException
3.就近原则。
set(E e):从列表中将next()或previous()返回的最后一个元素返回的最后一个元素更改为指定元素e
在调用set(E)方法前,不能调用remove() 和 add(E) 方法,否则会报错:java.lang.IllegalStateException。
4.ListIterator的add方法解析
void add ( E e ) 将指定元素插入到previous()返回的元素与当前光标位置之间。如何理解呢?上图:
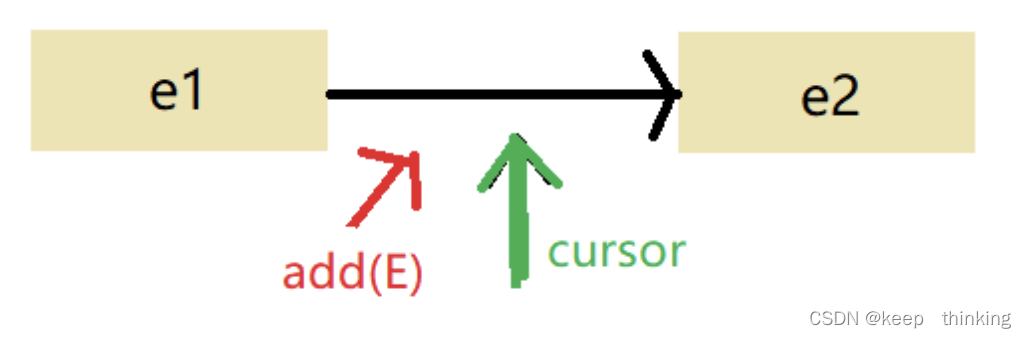
就是说不仅将元素插入到e1和e2之间,也插入到了e1和cursor之间。
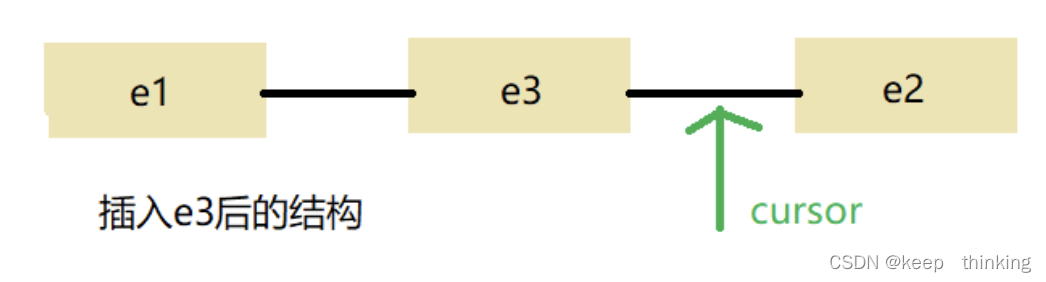
此时调用next()方法,仍然返回的是e2,调用previous()返回的就是新插入的元素了。
值得注意的是,当光标位置处于0(第一个元素左边)时,调用add(E)方法会出现异常,因为现在光标左边还没有元素呀
5.ListIterator与Iterator的区别
一.相同点
都是迭代器,都可以对集合中的元素进行遍历 。当需要对集合中元素进行遍历不需要干涉其遍历过程时,这两种迭代器都可以使用。
二.不同点
(1): 范围不同:Iterator可应用于Collection及其子类型所有的集合,
而ListIterator只能用于List及其子类型,如List、ArrayList、LinkedList和Vector等
(2): 遍历功能略微不同:Iterator和ListIterator都有hasNext()和next()方法,可以实现顺序向后遍历,
但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。
Iterator则不可以逆向遍历。即 ListIterator 因为有hasPrevious()和previous()方法,所以可实现双向遍历,
而terator只能单向顺序向前遍历。
(3): Iterator在遍历过程中仅仅有一个remove移除元素的方法, 故Iterator在遍历过程中不能够往集合里新增、修改元素;
而ListIterator在遍历过程中有add()方法、remove方法、set方法,
可以在遍历过程中向List中添加/删除集合中的元素,或者修改集合元素。
(4): Iterator在遍历过程中不能定位到索引位置,
ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。
注意: map并没有实现Iterator,ListIterator接口,所以其不能使用这两种迭代器直接进行遍历
java集合遍历
1. ArrayList的遍历方式
第一种,通过迭代器遍历。即通过Iterator去遍历。
List<Integer> list =Arrays.asList(1,2,3,4);
Iterator<Integer> iter = list.iterator();
while (iter.hasNext()) {
Integer value = iter.next();
System.out.println("v..."+value);
}
或者通过for的方式
List<Integer> list =Arrays.asList(1,2,3,4);
for(Iterator iter = list.iterator(); iter.hasNext();){
Integer value = iter.next();
System.out.println("v..."+value);
}
第二种,随机访问index,通过索引值去遍历。
由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素。
List<Integer> list =Arrays.asList(1,2,3,4);
for (int i=0; i<list.size(); i++) {
System.out.println("i= "+i+"....v..."+list.get(i));
}
第三种,增强for循环遍历。如下:
List<Integer> list =Arrays.asList(1,2,3,4);
for (Integer value : list) {
System.out.println("v..."+value);
}
第四种,forEach遍历。如下:
List<Integer> list =Arrays.asList(1,2,3,4);
list.forEach(v->System.out.println("v..."+value));
也可以简写为
list.forEach(System.out::println);
第五种,stream流式遍历
List<Integer> list =Arrays.asList(1,2,3,4);
list.stream.map(x->x++).collect(Collectors.toList());
或者
list.stream.forEach(v->System.out.println("v..."+value));
第六种,forEachRemaining方法遍历:继续输出其余的元素
由于某种原因导致遍历停止了,然后在通过foreachRemaing 遍历的时候,只会遍历剩余集合中还存在的元素。
ArrayList<Integer> arrayList=new ArrayList<>();
for (int i = 0; i <10; i++) {
arrayList.add(i);
}
System.out.println("迭代器第一次遍历");
Iterator<Integer> iterator=arrayList.iterator();
while(iterator.hasNext()){
int num=iterator.next();
System.out.print(num);
if(num==5){
break;
}
}
System.out.println("");
System.out.println("输出其余元素:");
iterator.forEachRemaining(new Consumer<Integer>() {
@Override
public void accept(Integer s) {
System.out.print(s);
}
});
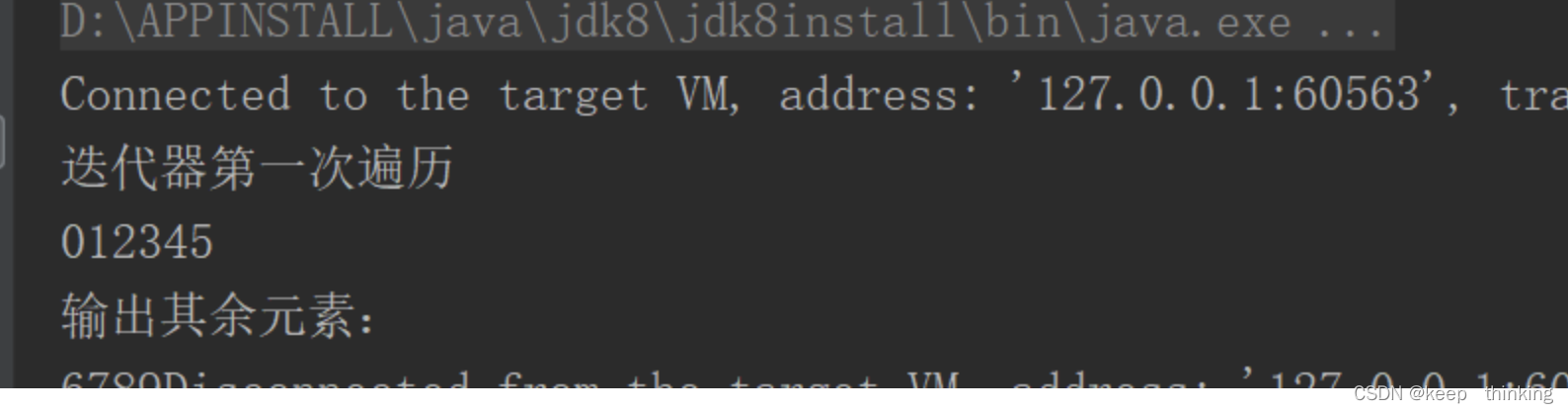
遍历ArrayList时,使用随机访问(即,通过索引序号访问)效率最高,而使用迭代器的效率最低
2. LinkedList的遍历方式
由于LinkedList与ArrayList实现同一个接口List,故ArrayList的六种遍历方式对于LinkedList同样适用,这里只对LinkedList的特有遍历方式做解释说明
数据准备:
List<Integer> list = new LinkedList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
知识回顾:
pollFirst():删除头;并且返回头,如果列表为空,则不会给出任何异常,并且返回null。 特有方法
pollLast():删除尾; 并且返回尾,如果列表为空,则不会给出任何异常,并且返回null。特有方法
removeFirst(E e):删除头,获取元素并删除,返回头;如果列表为空,抛出NoSuchElementException异常。 特有方法
removeLast(E e):删除尾;获取元素并删除,返回尾;如果列表为空,抛出NoSuchElementException异常。 特有方法
第七种:通过pollFirst()来遍历LinkedList,获取并移除此列表的第一个元素;如果此列表为空,则返回 null
while(list.pollFirst() != null){
}
第八种:通过pollLast()来遍历LinkedList,获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
while(list.pollLast() != null) {
}
第九种:通过removeFirst()来遍历LinkedList,移除并返回此列表的第一个元素。 NoSuchElementException - 如果此列表为空。
try {
while(list.removeFirst() != null) {
}
} catch (NoSuchElementException e) {
}
第十种:通过removeLast()来遍历LinkedList,移除并返回此列表的最后一个元素。NoSuchElementException - 如果此列表为空。
try {
while(list.removeLast() != null) {
}
} catch (NoSuchElementException e) {
}
注意:增强for循环(也称为for each循环)是jdk 1.5以后出来的一个高级的for循环,专们用来遍历数组,它的内部原理其实是Iterator迭代器,所以在遍历的过程中,不能对集合进行增删操作;Iterator迭代器遍历时可以做删除
3. Set集合的遍历方式
set集合支持的遍历方式同ArrayList集合的六种遍历方式,这里就不在列举了,有疑问的看ArrayList集合的遍历方式
4. Map集合的遍历方式
①for-each + keySet()/values()遍历key/Value
for-each:一种遍历形式
可以遍历集合或者数组,实际上是迭代器遍历的简化写法,也称增强for循环。
each表示每个;for-each表示循环数组或集合中的对象、数据。
keySet()方法:拿到全部的Key
将Map中所有的键(Key)存入到Set集合中。
Key表示键值;Set表示Set集合。
values()方法:拿到全部的Value
返回一个新的Iterator(迭代器)对象,该对象包含Map中存在的每个元素的值(Value)。
vluees是值的复数形式,表示它有很多的值。
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//for-each + keySet()遍历key
for (String key : map1.keySet()) { //遍历key
System.out.println("key = " + key);
}
//for-each + values()遍历value
for (Integer value : map1.values()) { //遍历value
System.out.println("value = " + value);
}
遍历结果:
key = 小明
key = 小红
key = 小张
value = 1
value = 2
value = 3
一次只能取出Key的值或者Value的值,这样显然是很不方便的。
②[重要]for-each + entrySet()遍历
Map.Entry是为了更方便的输出map键值对。一般情况下,想要输出Map中的key 和 value,就必须先得到key的集合keySet(),然后再循环每个key得到每个value。values()方法是获取集合中的所有值,不包含键,没有对应关系。而Entry可以一次性获得这两个值。
entrySet()方法:拿到全部的键值对
将Map中所有的键(Key)-值(Value)对存入到Set集合中,这个方法返回的是一个Set<Map.Entry<K,V>>。
entry表示条目、清单;Set表示Set集合。
entry里面的内容如下:
Key1, Value1
Key2, Value2
Key3, Value3
… , …
Key65535, Value65535
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//for-each + entrySet()遍历
for (Map.Entry<String, Integer> entry : map1.entrySet()) {
System.out.print("key = " + entry.getKey());
System.out.println(", value = " + entry.getValue());
}
执行结果:
key = 小明, value = 1
key = 小红, value = 2
key = 小张, value = 3
Map.Entry是最常见也最常用的遍历Map的方式
③for-each + keySet() + get()方法遍历
get()方法:传入Key,返回对应的Value
将要返回的元素的键(Key)作为参数,找到并返回对应该键(Key)的值(Value)。
如果没有找到键(Key),返回undefined。
因为键(Key)是唯一的,所以不用担心找到第一个后第二个不输出的问题。
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//for-each + keySet() + get()方法遍历
for (String key : map1.keySet()) {
Integer value = map1.get(key);
System.out.print("key = " + key);
System.out.println(", value = " + value);
}
执行结果:
key = 小明, value = 1
key = 小红, value = 2
key = 小张, value = 3
一般不推荐使用这种方法,因为多了一步根据key查找value的操作,效率会相对慢一些。写法和最开始的for-each遍历很相似,不同的是value使用了get()方法来获取。
map.get(key)方法的底层实现:
先调用Key的Hashcode方法得到哈希值,通过哈希算法得到对应的数组的下标,通过数组下标快速定位到某个位置上,如果这个位置上什么也没有,则返回null,如果这个位置上有单向链表,那么会拿着参数k和单项链表中的每个节点的k进行比较(equals()),如果所有的节点都返回false,那么最终该方法返回null,如果有一个节点的k和我们的k相匹配,那么该k节点所对应的value就是我们要找的value。
原文链接:https://blog.csdn.net/qq_51960163/article/details/117530311
④Iterator + entrySet()遍历
iterator() 方法:返回一个用于遍历当前集合的迭代器
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//Iterator + entrySet()遍历
Iterator<Map.Entry<String, Integer>> iter = map1.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<String, Integer> entry = iter.next();
System.out.print("key = " + entry.getKey());
System.out.println(", value = " + entry.getValue());
}
执行结果:
key = 小明, value = 1
key = 小红, value = 2
key = 小张, value = 3
使用Iterator创建一个迭代器来遍历这个Map,和方法②类似,但区别在于:
for-each通常用于一次性遍历整个集合,大大提升了代码的简洁性和可阅读性,但期间无法控制遍历的过程。而Iterator通过hasNext(),next() 更好地控制便利过程的每一步。
for-each在遍历过程中严禁改变集合的长度,且无法对集合的删除或添加等操作。而Iterator可以在遍历过程中对集合元素进行删除操作。
但是在idea编译器中,编译器会给出警告,提示说该写法可以简化,简化后的写法和for-each + entrySet()方法遍历一致:
for (Map.Entry<String, Integer> entry : map1.entrySet()) {
System.out.print("key = " + entry.getKey());
System.out.println(", value = " + entry.getValue());
}
⑤[重要]lambda表达式遍历
forEach() 方法:遍历数组中每一个元素并执行特定操作
Lambda表达式:能够非常简练地表达特定的操作行为。在遍历集合中的元素时,如果对每个元素都执行同样的操作,也可以用Lambda表达式来指定对元素的操作行为,从而简化遍历访问集合的代码。
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//lambda表达式遍历
map1.forEach((key, value) -> {
System.out.print("key = " + key);
System.out.println(", value = " + value);
});
执行结果:
key = 小明, value = 1
key = 小红, value = 2
key = 小张, value = 3
forEach方法遍历了map1,同时获取到key和value的值。美观,简洁,大气。
⑥stream流遍历
Stream流的作用:区别于IO流,用来对容器(集合,数组)操作进行书写简化,配合众多函数式接口以及lambda表达式,方法引用,集合的遍历,计数,过滤,映射,截取等操作变得异常优雅,上流。
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//stream流遍历
map1.entrySet().stream().forEach((Map.Entry<String, Integer> entry) -> {
System.out.print("key = " + entry.getKey());
System.out.println(", value = " + entry.getValue());
});
执行结果:
key = 小明, value = 1
key = 小红, value = 2
key = 小张, value = 3
但是在idea编译器中,编译器会给出警告,提示说该写法可以简化,简化后的写法和lambda表达式一致:
map1.forEach((key, value) -> {
System.out.print("key = " + key);
System.out.println(", value = " + value);
});
总结——简洁又好用的遍历方式
①for-each + entrySet()遍历
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//for-each + entrySet()遍历
for (Map.Entry<String, Integer> entry : map1.entrySet()) {
System.out.print("key = " + entry.getKey());
System.out.println(", value = " + entry.getValue());
}
②lambda表达式遍历
HashMap<String, Integer> map1 = new HashMap<>();
map1.put("小明", 1);
map1.put("小红", 2);
map1.put("小张", 3);
//lambda表达式遍历
map1.forEach((key, value)->{
System.out.print("key = " + key);
System.out.println(", value = " + value);
});
鸣谢:https://blog.csdn.net/qq_52430605/article/details/132159145