“晨兴理荒秽,带月荷锄归”
夜深闻讯,有点兴奋~
苹果为 UMA 设计的深度学习框架真的来了
统一内存架构 得益于 CPU 与 GPU 内存的共享,同时与 MacOS 和 M 芯片 交相辉映,在效率上,实现对其他框架的降维打击。
搓手学习,有点精彩👐🏻

MLX 地址
翻译:
MLX是苹果硅片上机器学习的数组框架,由苹果机器学习研究团队带来。
MLX的一些关键特性包括:
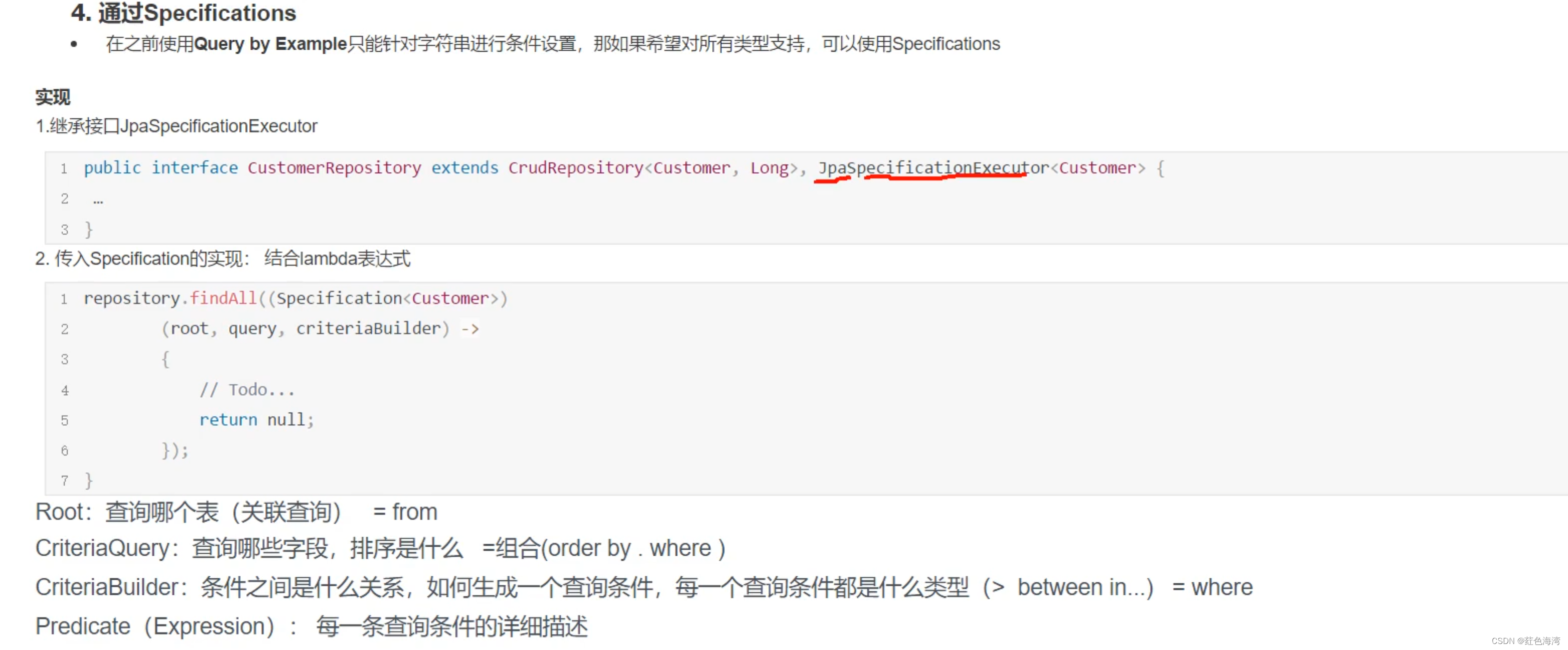
熟悉的API:MLX具有与NumPy非常相似的Python API。MLX还有一个功能齐全的C++ API,与Python API非常相似。MLX拥有像mlx.nn和mlx.optimizers这样的高级包,其API紧密跟随PyTorch,以简化构建更复杂的模型。
可组合函数转换:MLX支持自动微分、自动向量化和计算图优化的可组合函数转换。
延迟计算:MLX中的计算是延迟的。数组只有在需要时才实现。
动态图构建:MLX中的计算图是动态构建的。更改函数参数的形状不会触发慢速编译,调试简单直观。
多设备:操作可以在任何支持的设备上运行(目前是CPU和GPU)。
统一内存:MLX与其他框架的一个显著区别是统一内存模型。MLX中的数组存在于共享内存中。在任何支持的设备类型上对MLX数组进行的操作都无需传输数据。
MLX由机器学习研究人员为机器学习研究人员设计。该框架旨在用户友好,但仍然高效地训练和部署模型。框架本身的设计也概念上很简单。我们的目标是让研究人员能够轻松扩展和改进MLX,以快速探索新想法。
MLX的设计灵感来自于像NumPy、PyTorch、Jax和ArrayFire这样的框架。
![[GXYCTF2019]Ping Ping Ping (文件执行漏洞)](https://img-blog.csdnimg.cn/direct/0e3a68884def40d8ba5d7da2dc71880b.png)