技术选型实则是取舍的艺术
这句话是我偶然在一篇技术架构方面的文章上看到的,每当我需要给新项目进行技术选型,决定技术架构时,一直坚信的。
当我们做技术选型时,需要考虑的东西非常多。比如,用关系型数据库还是非关系型数据库,MySQL还是PGsql,要不要用Redis,需不需要支持分布式文件存储,模块化还是耦合,用什么协议与第三方系统交互,用golang还是java,golang的话用gin还是kratos,微服务还是单体,系统预计有多大并发。
这些技术都没有优劣之分,我们需要根据实际的场景选择最合适的方案。记住,可以有远见,但不要过度设计。过度的设计对于系统和开发人员都是一种负担。我见过很多小团队,无脑上微服务,实际上微服务有它的代价,而小团队没有得到微服务的好处,反而为了微服务架构付出了不必要的代价。
先理解需求
在技术选型上,我最常犯的错就是对于需求的理解不够,常常因为一些细节问题推翻技术架构设计的某一个局部,虽不至于整体推翻,但是也做了很多弯路。在选择数据库的时候,要考虑实际场景,比如,读多写少还是写多读少,数据量有多大,需求会不会频繁变更,变更对于数据结构的影响大吗。一般我会用MongoDB和MySQL处理常规场景。我说的常规场景是指,当项目按照迭代的方式进行,后期大概率会发生不小的调整和变更,数据结构不是特别复杂,数据量单表相对较大等等情况下,我会选择MongoDB,比如文档类项目、社交项目、企业官网等。当数据量不是特别大,数据关系比较传统关系比较确定且复杂等情况下会选择MySQL。其实现在两个数据库在大部分场景下都可以互相替代,在选择的时候还可以考虑团队的偏向、历史技术沉淀等因素。我认为MySQL不适合处理海量数据的存储,单表上亿简直是灾难。MySQL的分库分表也有它的缺陷存在,在需求对整体数据进行分析处理的时候,即时分库分表了,效率也非常低下,同时在使用的时候复杂度也比较高。在技术选型的时候,我会尽量让开发人员能够写简单的代码,不用因为选型给业务思考带来更多的负担。
有一些和第三方对接的场景,要去调研清楚,第三方能够提供什么数据,支持什么技术栈。和第三方之间是通过推还是拉的方式拿数据,是全量还是增量,增量同步的时候多久做一次数据校验。支持什么协议对接,消息队列还是Restful或者别的协议。我曾经对接过一个GPT服务,一开始设计的是会有一个数据清洗加推送的服务,把本服务数据清洗过后推送给他们。后面一聊发现,他们需要自动生成sql语句,连我们的数据库执行查询语句。就把对接方式改成了直连中间库。中间浪费了测试数据清洗和数据推送技术可行性的时间。应该在和GPT方聊完再去确定技术架构的。
一些取舍
沉淀
接的项目多了,就可以沉淀下来一些规范。现在部门也沉淀出了一套处理不同类型项目的技术选型规范,可以复制粘贴基础库半小时内搭好一个框架。
除了框架搭建和技术选型以外,我们还沉淀了CICD规范、代码规范、依据DDD的分层规范、Git管理规范、研发流程规范等等各个维度的大大小小十几个规范。
MySQL还是MOngoDB
现在MongoDB用的多,一般不是很复杂的业务都直接上MongoDB了,主要是简单灵活,开发快。
时序数据库
有时候会有一些IOT设备的实时数据推送,一般会把这类数据存到TDengine,还挺好用的,可以用
SQL的语法处理数据,不用搭建一整套的大数据脚手架工具,就是生态不够完整,希望越来越好吧。
搜索
搜索要求比较高的时候会上Elasticsearch(以下简称ES),不过这个东西太吃资源了。有时候要求不高的时候会用MongoDB的Text类型索引,也支持搜索,不过只能支持完整单词匹配,分词做的不是很好,毕竟不是专门做搜索的。MongoDB好就好在不用多加一个第三方组件,然后也没有ES那么吃资源,内存毕竟挺贵的。虽然MongoDB也基于内存做查询优化的,但是相比于ES就好多了。
动态属性
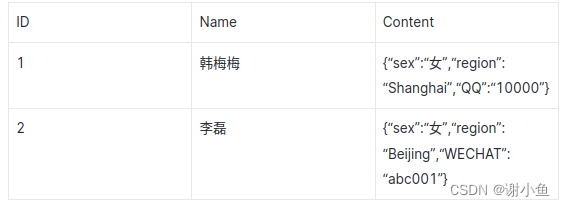
曾经给IT部门设计过一个资产管理系统,他们要求资产类型和资产的属性都是可以扩展和自定义的。于是用了MongoDB去实现。其实需求就是一个EAV模型 Entity-Attribute-Value(实体、属性、值),使用MongoDB实现EAV会更加方便灵活,因为MongoDB天然支持JSON格式数据的存储。具体不再赘述了,有空再另一篇文章记录一下当时怎么设计的。简单讲就是下面这种结构,这是一个人员的实体,固定属性是Name,还有sex、region、QQ等可以让用户自定义的扩展属性。
golang的服务开发框架选择
golang在业界并没有一个统一的标准,不像java,基本上被Spring一统天下了。我司用的比较多的分别是Gin和Kratos,我一般用Kratos,可以做单体,也方便扩展微服务。Kratos这套是完整的解决方案,有API生成,依赖注入,限流,错误处理等等部件。在做一些组件上的技术选型的时候,一般会花更多的心思。比如选择限流方案,需要考虑限流的策略算法,资源池型和令牌桶型;需要考虑社区活跃度,有多少人用,除了问题官方会不会立马解答,要看看issue库里面坑多不多;另外还要考虑对代码侵入性高不高,能不能在中间件层无侵入注入。
服务监控和告警
没什么特殊要求的话, 整个部门共用一套K8s监控集群,内部安装了Prometheus+Grafana+alertmanager做监控、看板和告警。可以满足集群内部和外部的监控需求。
命名规范
这里主要是MongoDB的命名规范,下划线、中划线、首字母大写驼峰、首字符小写驼峰,这些选择感觉很多厂的选择都各不相同。我觉得只要部门内所有的系统保持一致就行了,具体用哪种反而不重要。我会去MongoDB的官方文档中,看他们CRUD的示例的集合和字段是用哪种风格,然后决定用什么,把这套规范推广至整个部门,让所有项目保持一致。只要一致,就可以减少一些成本。
代码检查
一般会利用Git的Pre-Commit做一个代码提交前的自动检查,在代码提交前,自动调用golangci-lint插件检查代码风格。
Git管理
GIt管理一般有GItFlow和GIthub Flow。少于5个开发的项目用GIthub Flow,就一个Master分支,用MR进行合并代码。多于5人用GIthub Flow,多了一些develop或者版本分支,代码合入到这些分支,分支开发完了才合入到master。提MR之前要用git rebase保证提交历史是线性的。