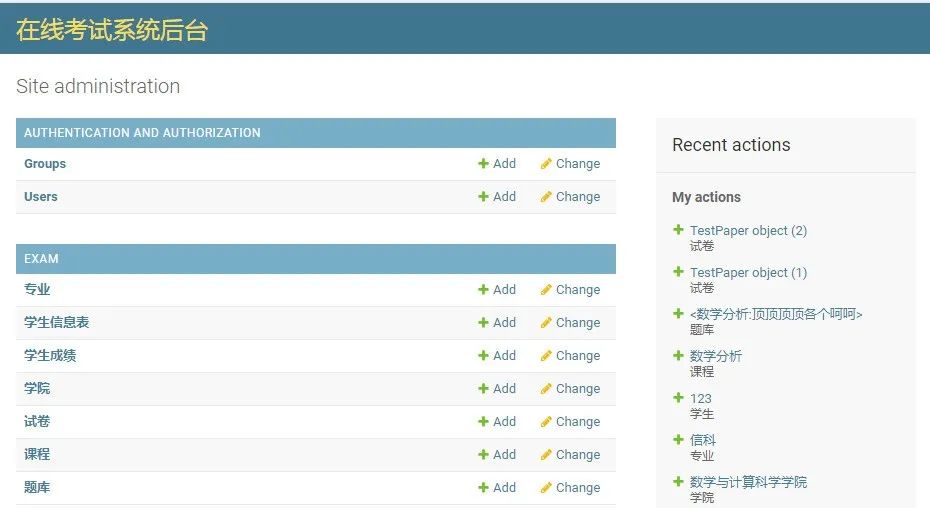
定义如下mapping,并且创建索引,索引包括四个字段
有三个分片 (number_of_shards),每个分片有一个副本分片(number_of_replicas)
PUT books
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"author": {
"type": "keyword"
},
"intro": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}ElasticSearch提供了两种新建索引的方式,一种是使用 Index API 索引文档,一种是使用 Create API 创建文档。
1、通过 Index API 索引文档
PUT books/_doc/1
{
"book_id": 1,
"name": "linux入门到放弃",
"author": "huayuanbb",
"intro": "test"
}返回的数据为
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}result 为 created 创建,且version为1,通过Index API新建的文档,如果id已经存在的情况下,多次执行,不会报错,只会将返回结果的result 变为 updated version在原来的基础上 +1.
其实在索引一个文档的时候,如果文档 ID 已经存在,会先删除旧文档,然后再写入新文档的内容,并且增加文档版本号。
2、通过 create API 创建文档
通过create API 创建文档有两种方式 POST 和 PUT
POST方式
POST books/_doc
{
"book_id": 1,
"name": "linux入门到放弃",
"author": "huayuanbbsssss",
"intro": "test"
}采用POST方式创建的文档,无需指定id,系统会自动生成UUID

PUT方式
PUT books/_create/2
{
"book_id": 1,
"name": "linux入门到放弃",
"author": "ss",
"intro": "test"
}如上示例,使用 PUT 的方式创建文档需要指定文档的 ID,如果文档 ID 已经存在,则返回 http 状态码为 409 的错误。
总结
| 序号 | 语句 | 特性描述 |
|---|---|---|
| 1 | PUT books/_doc/1 | 插入时需要指定id,且重复插入相同id的文档,只会将返回的结果中的version自增,且result改为updated,本质上是先删除,再写入,并将版本号+1 |
| 2 | PUT books/_create/1 | 插入时同样需要指定id,但当插入相同id的文档时,会返回状态码为409的错误 |
| 3 | POST books/_doc/ | 不需要指定文档 ID, 系统自动生成。 |
上表是新建文档时 3 种写法的总结,如果你有更新文档内容的需求,应该使用第一种方式。如果写入文档时有唯一性校验需求的话,应该使用第二种方式。如果需要系统为你创建文档 ID,应该使用第三种方式。相对于第一种方式来说,第三种方式写入的效率会更高,因为不需要在库里查询文档是否已经存在,并且进行后续的删除工作。
同时更新不仅仅可以通过 PUT books/_doc/1 来实现,ElasticSearch也提供了Update API来完成更新操作。
POST books/_update/2
{
"doc": {
"name":"时间简史(视频版)",
"intro": "探索时间和空间核心秘密的引人入胜的视频故事。"
}
}
#结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"result" : "updated",
......
}二者间的区别是updated是在原数据上进行修改,而PUT操作是之间将原数据删除,再插入一条新纪录,且Update只指定要更新的字段即可。
除了使用指定 ID 的方式来更新数据外,还可以用 update_by_query 的方式:
POST books/_update_by_query
{
"query": {
"term": {
"book_id": {
"value": 1
}
}
},
"script": {
"source": "ctx._source.name='深入Linux内核架构'",
"lang": "painless"
}
}执行完上述代码后,再执行 GET books/_doc/2 操作

可以发现已经修改成功了 ,脚本中 'ctx._source' 可以拿到匹配的文档的数据,所以 ctx._source.name='深入Linux内核架构' 的意思是将匹配文档的 'name' 字段的数据设置为 '深入Linux内核架构'。
需要注意的是,如果 query 中匹配的文档数量巨大,那么这个接口在 kibana 中执行的时候可能会发生超时的错误,当然你可以在请求中使用 timeout 参数,但是这个不是解决问题的有效方案。我建议你使用异步的方式进行处理,并且控制需要更新的数据量,例如按日期分批来进行更新,即在请求的URL后携带一个参数,wait_for_completion=false,其结果会返回一个task id ,再通过
GET _tasks/task_id 来查询任务的执行状态
POST books/_update_by_query?wait_for_completion=false
{
"query": {
"term": {
"book_id": {
"value": 1
}
}
},
"script": {
"source": "ctx._source.name='深入Linux内核架构111'",
"lang": "painless"
}
}
{
"task" : "CyKKcsubQBupaq7v4Yc_Rg:1102573"
}
![[SUCTF 2018]MultiSQL(预处理)](https://img-blog.csdnimg.cn/d59014d56d814130878475850eadb54f.png)