概述
卷积神经网络(Convolutional Neural Network,CNN)是一类专门用于处理具有网格结构数据的神经网络。它主要被设计用来识别和提取图像中的特征,但在许多其他领域也取得了成功,例如自然语言处理中的文本分类任务。
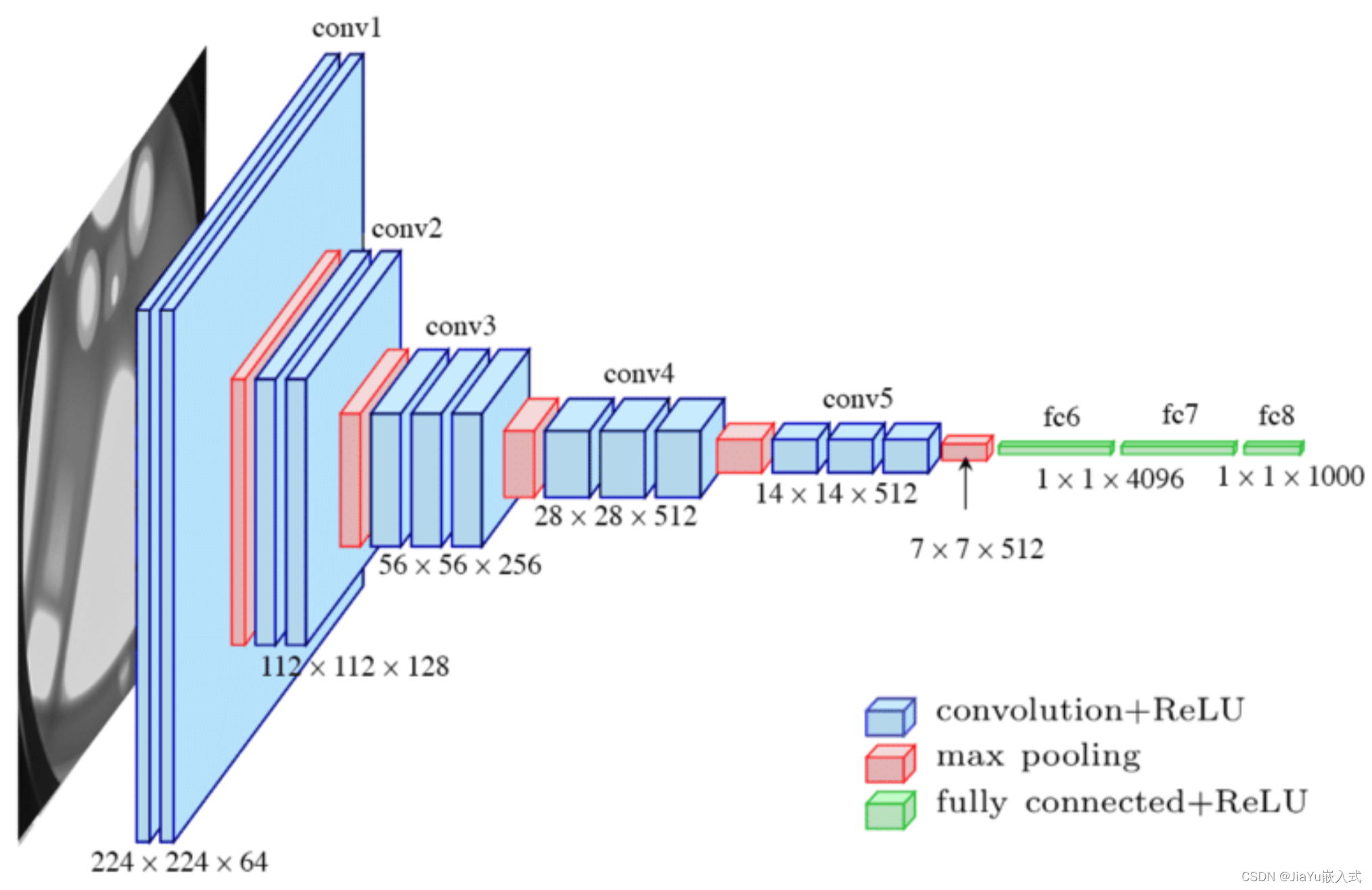
CNN 的主要特点是它使用了卷积层(convolutional layer)来处理输入数据。卷积层通过卷积操作在输入数据上滑动一个或多个卷积核(也称为滤波器),从而学习局部特征。这种局部感知能力使得 CNN 能够有效地捕捉输入数据中的空间结构和模式。
基本组成部分
卷积层(Convolutional Layer)
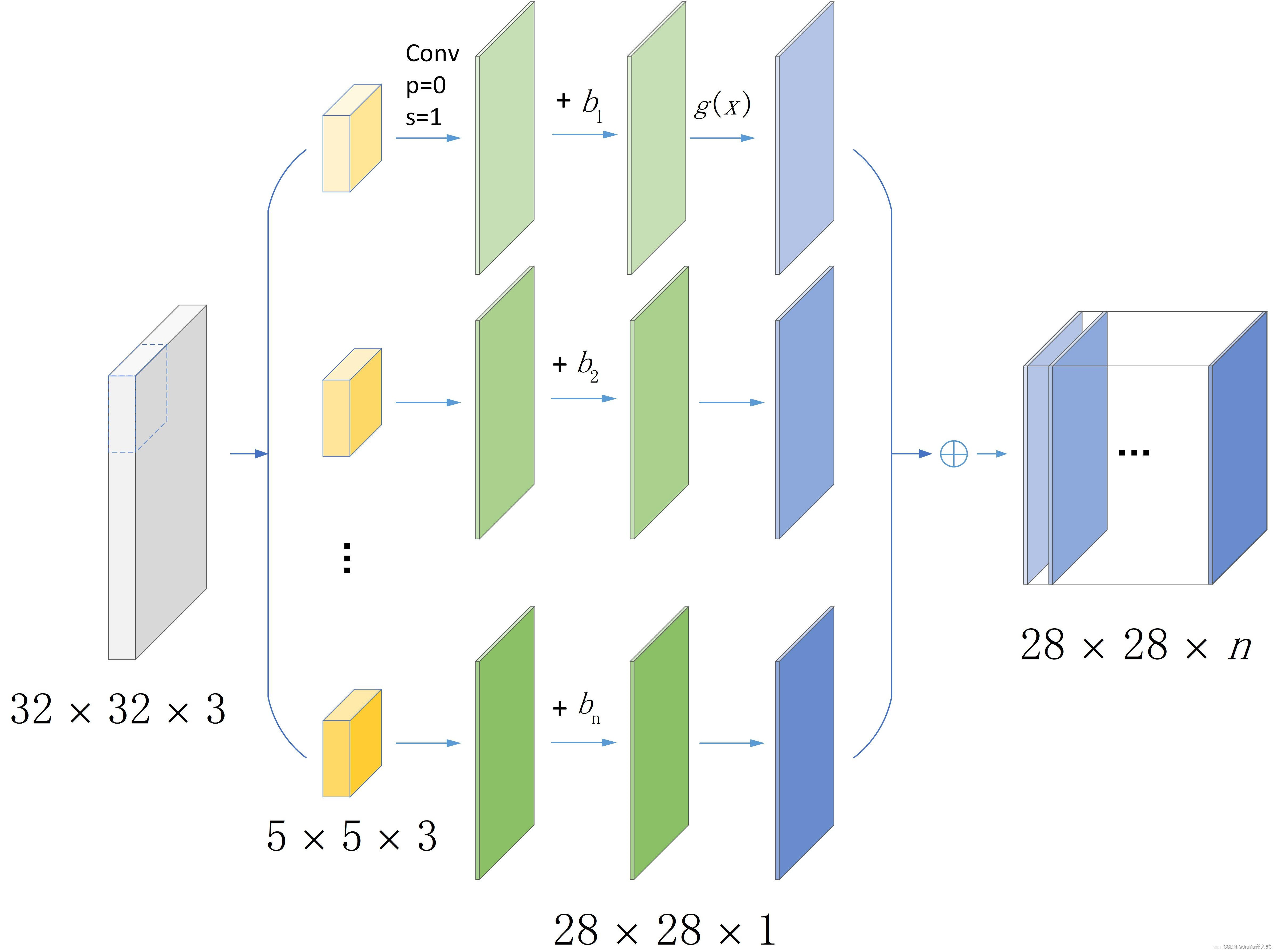
由多个卷积核组成,每个卷积核用于检测输入数据中的特定特征。卷积操作通过在输入数据上滑动卷积核并计算局部区域的加权和来提取特征。
池化层(Pooling Layer)
用于减小数据的空间维度,降低计算复杂度,并且增强模型对平移变化的鲁棒性。最大池化是常用的池化操作,它选择输入区域中的最大值作为输出。
激活函数(Activation Function)
通常在卷积层之后应用,引入非线性特性。常用的激活函数包括ReLU(Rectified Linear Unit)。
全连接层(Fully Connected Layer)
在卷积层和输出层之间,用于整合卷积层提取的特征并生成最终的输出。全连接层将前一层的所有节点与当前层的每个节点连接。
CNN 在图像处理任务中表现出色,因为它能够学习到图像的局部和全局特征,具有平移不变性(通过共享权重)、参数共享和稀疏交互等特性。这些特性使得 CNN 在图像分类、目标检测、图像生成等任务中取得了显著的成功。
基本实现原理
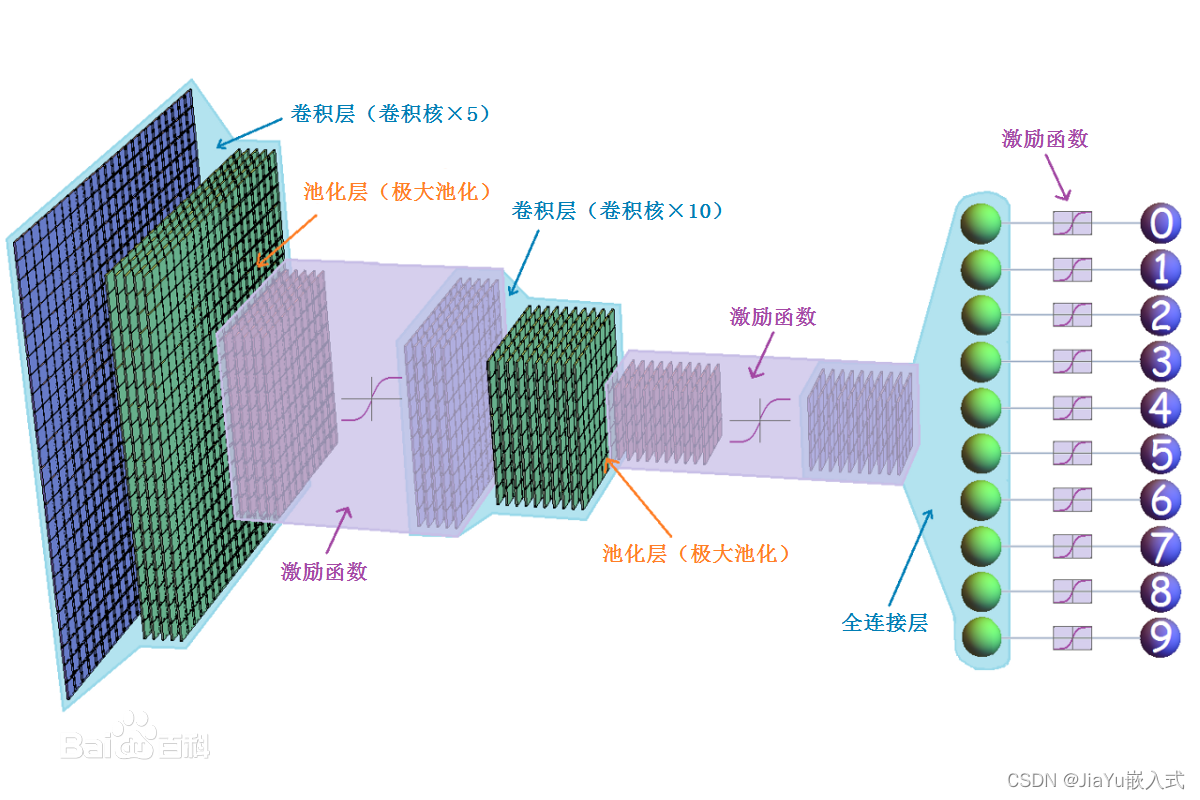
卷积神经网络(CNN)的实现原理涉及卷积层、池化层、激活函数、全连接层等关键组件。
输入层(Input Layer)
接收原始输入数据,通常是图像或其他具有网格结构的数据。
卷积层(Convolutional Layer)
使用卷积核(filter)对输入数据进行卷积操作,通过在输入数据上滑动卷积核,提取局部特征。卷积操作通过计算局部区域的加权和来生成输出特征图(feature map)。
激活函数(Activation Function)
在卷积操作后,应用激活函数引入非线性,增加网络的表示能力。常用的激活函数包括ReLU(Rectified Linear Unit)。
池化层(Pooling Layer)
对卷积层的输出进行下采样,减小空间维度,提高计算效率,并增强网络对平移变化的鲁棒性。最大池化是常用的池化操作,选择局部区域中的最大值作为输出。
全连接层(Fully Connected Layer)
将池化层的输出扁平化,并通过全连接层连接到输出层。全连接层负责整合卷积层和池化层提取的特征,并生成最终的输出。
输出层(Output Layer)
输出层根据任务的性质确定,可以是分类问题的softmax层,回归问题的线性层,或者其他适当的输出层结构。
在训练过程中,通过反向传播算法更新网络参数,以最小化损失函数。这个过程包括前向传播(计算预测输出)、计算损失、反向传播(计算梯度),以及使用优化算法(如梯度下降)来更新权重。
CNN 的关键之一是参数共享,即卷积核在整个输入上共享权重,这减少了参数数量,提高了模型的效率和泛化能力。此外,卷积操作和池化操作的重复使用使得网络能够逐渐构建出对输入数据的抽象表示。卷积神经网络通过多层次的特征提取和抽象,能够学习到输入数据的有用表示,从而在图像分类、目标检测等任务中表现出色。
案例代码
下面是一个使用PyTorch的简单卷积神经网络(CNN)的代码案例。
在这个例子中,使用PyTorch来构建一个简单的CNN模型,以进行图像分类。确保你已经安装了PyTorch:
pip install torch torchvision
代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 设置随机种子,以保证实验的可重复性
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 定义CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = self.flatten(x)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 数据预处理和加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 5
for epoch in range(num_epochs):
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 在测试集上评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print('Test Accuracy: {:.2%}'.format(accuracy))
这个示例中,使用PyTorch构建了一个包含两个卷积层和两个全连接层的简单CNN模型,并在MNIST手写数字数据集上进行训练和测试。可以根据自己的需求修改模型架构、训练参数等。
总
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 定义CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = self.flatten(x)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 数据预处理和加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 5
for epoch in range(num_epochs):
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 保存模型
torch.save(model.state_dict(), 'simple_cnn_model.pth')
print("Model has been saved.")
# 加载模型
new_model = SimpleCNN()
new_model.load_state_dict(torch.load('simple_cnn_model.pth'))
new_model.eval()
# 在测试集上评估加载的模型
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = new_model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print('Test Accuracy of Loaded Model: {:.2%}'.format(accuracy))
这个示例中,添加了模型的保存和加载过程。模型在训练完成后被保存到simple_cnn_model.pth文件,然后通过加载这个文件,可以重新创建模型并在测试集上进行评估。这对于在训练后的应用部署和模型共享上都是非常有用的。