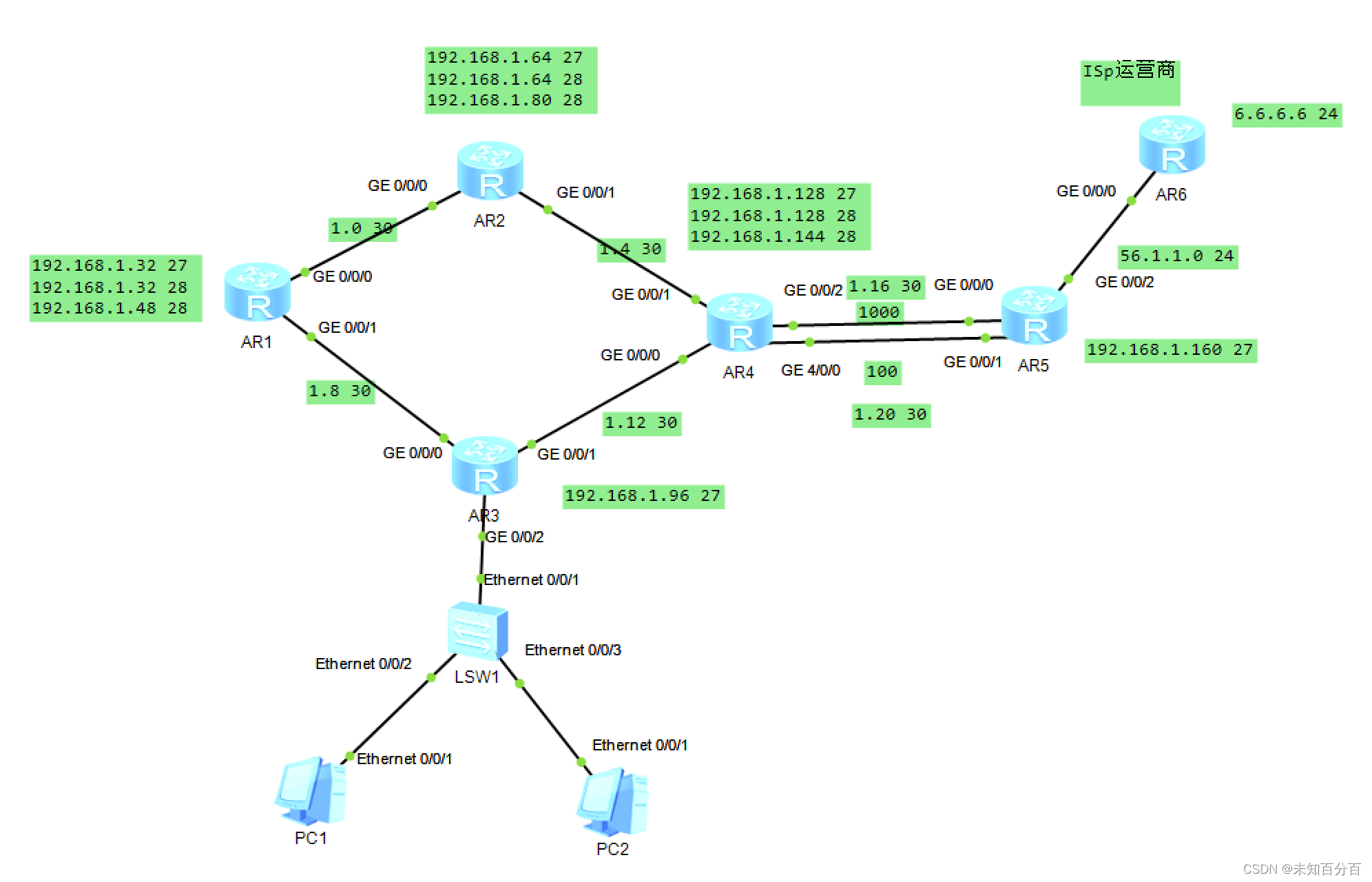
应用AI和机器学习来预测消费者行为
在这篇文章中,我们将学习和分析一般的消费者行为。我们还将了解人工智能是如何帮助发现有价值的见解的,从而使公司做出正确的决定,以实现提供更好的价值和创造更好的收入的愿景。
我们还将通过一个案例进行分析,在这个案例中,我们使用数据科学和分析方法来发现有价值的见解,从而得出更好的解决方案。
前提条件
作为先决条件,读者必须对Python和机器学习有一定的了解。
什么是人工智能?
人工智能是指机器像人一样学习的能力,从而达到人类智能的水平,甚至更多。
随着人工智能领域的进步,它导致了多个行业的改进,如自动化、供应链、电子商务、制造业等等。
不仅如此,人工智能的子部分,即数据科学和机器学习已经使企业能够做出正确的决定。更简单地说,为了提高电子商务商店的收入,我们可以根据客户的喜好、最常购买的物品、以前的搜索、物品购买之间的相关性等,分析并向客户提供个性化的建议。
人工智能通过规划库存、物流、寻找趋势、模式、根据历史趋势预测未来结果、告知基于事实的决策等,在电子商务中发挥了重要作用。
了解消费者行为
消费者行为,在其最广泛的意义上,涉及到消费者如何选择、决定、使用和处置商品和服务。它涵盖了任何垂直领域的个人、团体或组织。
它对影响购买行为的消费者的情感、态度和偏好提供了一个很好的想法和见解。因此,帮助营销人员了解客户的需求,为客户带来价值,并反过来为公司创造收入。
预测消费者行为
大公司明白,预测客户行为可以填补市场空白,确定所需的产品,从而产生更大的收入。
消费者行为的预测可以通过以下方式进行。
- 细分:根据购买行为将顾客分成更小的群体。这有助于分离关注点,反过来帮助我们确定市场的区域。
- 预测分析:我们使用统计技术来分析以前的历史数据,以预测客户的未来行为。
一步一步的实施
现在,让我们用一个实时的例子来了解这是怎么做的。
了解数据集
在这个数据集中,我们有与客户相关的信息,比如。
CustomerID- 客户的IDGender- 客户的性别Age- 客户的年龄AnnualIncome- 顾客的年收入SpendingScore- 根据客户的行为和他们的购买数据分配的分数
目的
本教程的目的是根据客户的购买数据来了解客户的行为。这有助于营销团队了解并制定相应的新策略。
导入库
对于数据探索,必须要安装一些Python库。
需要下载的库有。
- [NumPy]
- [Pandas]
- [Matplotlib]
- [Sklearn]
- [剑桥大学]
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
复制代码查看数据集
在我们开始之前,让我们看一下数据集。为了查看数据集,我们必须通过读取CSV文件来导入,如下图所示。
df = pd.read_csv(r'../input/Mall_Customers.csv')
df.head()
复制代码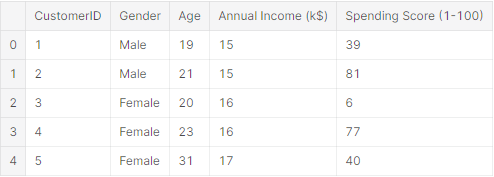
数据集的前5行
数据可视化
年龄、收入和消费分数之间的相关性
一个更好的营销策略是分析消费模式。在这里,让我们试着分析并找出客户的年龄、年收入和消费分数的情况。
plt.figure(1 , figsize = (15 , 6)) # sets the dimensions of image
n = 0
for x in ['Age' , 'Annual Income (k$)' , 'Spending Score (1-100)']:
n += 1
plt.subplot(1 , 3 , n) # creates 3 different sub-plots
plt.subplots_adjust(hspace =0.5 , wspace = 0.5)
sns.distplot(df[x] , bins = 20) # creates a distribution plot
plt.title('Distplot of {}'.format(x)) # sets title for each plot
plt.show() # displays all the plots
复制代码输出。
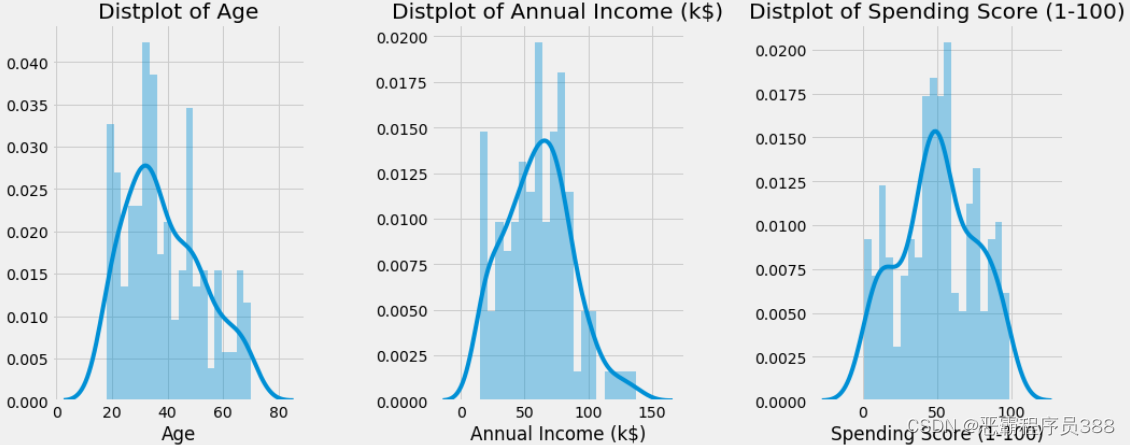 年龄、年收入和消费分数的分布图
年龄、年收入和消费分数的分布图
性别分析
决定策略的第二件最重要的事是根据性别分析消费模式。在这里,我们发现女性比男性更倾向于购买。
plt.figure(1 , figsize = (15 , 5))
sns.countplot(y = 'Gender' , data = df)
plt.show()
复制代码输出。
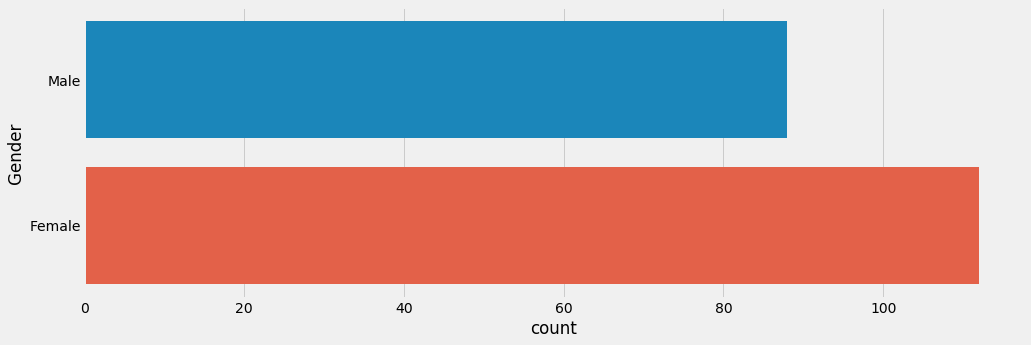
描述男性和女性的消费模式的计数图。
客户细分
细分有助于将一组大数据划分为较小的观察组,这些观察组在与营销相关的特定方面具有相似性。
每组包含的个体之间有相似之处,但与其他组的个体不同。
细分作为一种营销工具被广泛使用,用于创建客户群,并为每个客户调整相关策略。
在这里,我们将学习根据几个因素对这些数据进行细分,并了解它是如何帮助改善现有战略的。
使用年龄和消费分数进行细分
让我们试着根据客户的年龄和他们的消费分数来细分。这有助于我们了解客户的年龄类别,这可能会提高消费分数,从而增加公司的收入。
在这里,我们必须决定可能的集群(细分)的数量,以获得最佳结果。为此,我们在1 到11 ,并找出哪个群组是正确的选择。
X_age_spending = df[['Age' , 'Spending Score (1-100)']].iloc[: , :].values # extracts only age and spending score information from the dataframe
inertia = []
for n in range(1 , 11):
model_1 = (KMeans(n_clusters = n ,init='k-means++', n_init = 10 , max_iter=300,
tol=0.0001, random_state= 111 , algorithm='elkan')) # use predefined Kmeans algorithm
model_1.fit(X_age_spending) # fit the data into the model
inertia.append(model_1.inertia_)
复制代码让我们通过一个图表来说明这个问题。
plt.figure(1 , figsize = (15 ,6)) # set dimension of image
plt.plot(np.arange(1 , 11) , inertia , 'o') # Mark the points with a solid circle
plt.plot(np.arange(1 , 11) , inertia , '-' , alpha = 0.5) # connect remaining points with a line
plt.xlabel('Number of Clusters') , plt.ylabel('Inertia') # label the x and y axes
plt.show() # display
复制代码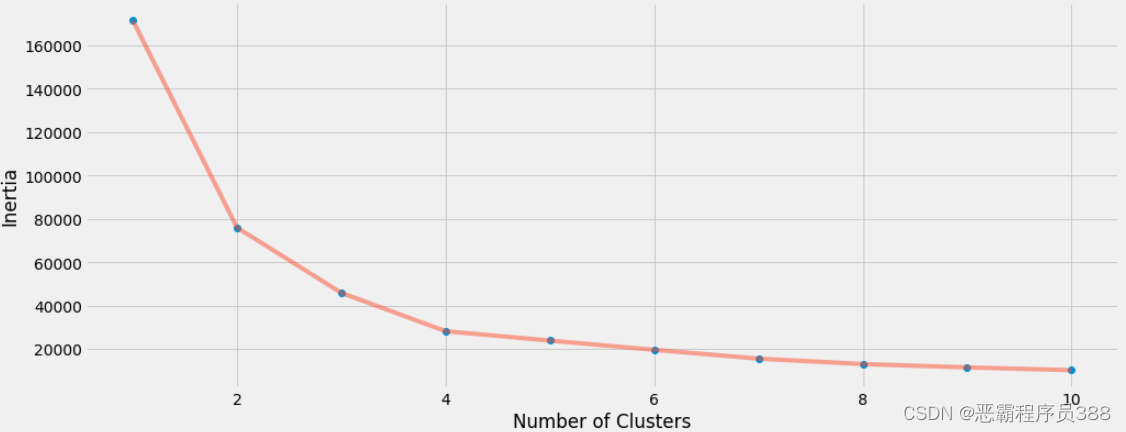 显示集群的线图
显示集群的线图
正如你可能注意到的,在集群4 ,线图开始变得稳定。这种方法被称为 "弯头法"。
现在,让我们进一步探索有4个集群的情况。
model_2 = (KMeans(n_clusters = 4 ,init='k-means++', n_init = 10 ,max_iter=300,
tol=0.0001, random_state= 111 , algorithm='elkan') ) # set number of clusters as 4
model_2.fit(X_age_spending) # fit the model
labels1 = model_2.labels_
centroids1 = model_2.cluster_centers_
复制代码现在让我们把它们可视化。
在此之前,有一些绘制图形的先决条件--比如设置最大值和最小值的范围,初始化一个meshgrid() ,等等。
h = 0.02
x_min, x_max = X_age_spending[:, 0].min() - 1, X_age_spending[:, 0].max() + 1
y_min, y_max = X_age_spending[:, 1].min() - 1, X_age_spending[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model_2.predict(np.c_[xx.ravel(), yy.ravel()]) # returns flattened 1D array
复制代码现在,让我们来绘制图形。
plt.figure(1 , figsize = (15 , 7) )
plt.clf()
Z = Z.reshape(xx.shape)
plt.imshow(Z , interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap = plt.cm.Pastel2, aspect = 'auto', origin='lower')
plt.scatter( x = 'Age' ,y = 'Spending Score (1-100)' , data = df , c = labels1 ,
s = 200 )
plt.scatter(x = centroids1[: , 0] , y = centroids1[: , 1] , s = 300 , c = 'red' , alpha = 0.5)
plt.ylabel('Spending Score (1-100)') , plt.xlabel('Age')
plt.show()
复制代码输出。
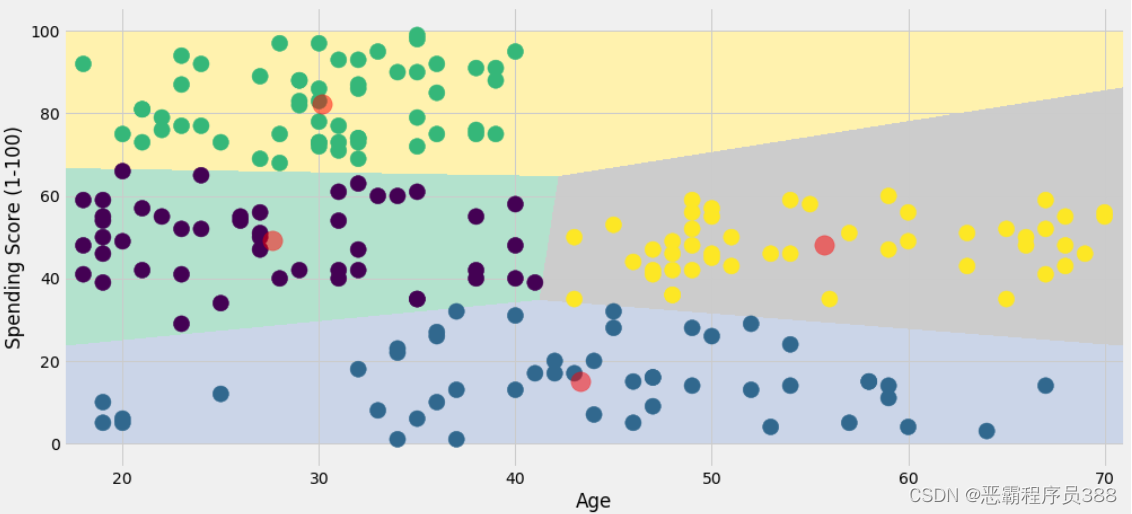 有4个聚类的KMeans
有4个聚类的KMeans
从上面的图中,我们可以推断出许多关于消费模式的信息。
- 不分年龄的平均消费分数大约是
20 - 在最上面的聚类中,年龄在
40以下的顾客具有最高的消费分数。这个群组的稀疏程度较低。 - 在年龄超过
40,消费分数始终保持在30 - 60的范围内。
关于这些数据的更多见解可以通过与所有可能的直接或间接相关的参数相关联的更深入的数据分析来提取。
结论
正如我们从上述简单的案例研究中了解到的,我们发现人工智能在几乎所有的行业都发挥了重要作用。随着数据分析趋势的上升,客户的行为正被持续监测,以改善战略和采取更好的决策。
这篇文章只是作为初学者的指南,让他们在这个领域开始。



![[阿里云] 10分钟带你玩转阿里云ECS和云盘 (大数据上云必备)](https://img-blog.csdnimg.cn/fcb82890e5204b3aaf42942643d1ea2d.png)