实验一、MySQL主从服务器搭建
实验前准备
Master服务器:192.168.188.14 mysql5.7
Slave服务器1:192.168.188.15 mysql5.7
Slave服务器2:192.168.188.16 mysql5.7
关闭虚拟机防火墙
systemctl stop firewalld
setenforce 0
- 主服务器准备
- 安装相关软件
yum -y install ntp - 修改ntp配置
vim /etc/ntp.conf
在末尾添加以下内容:server 127.127.1.0 fudge 127.127.1.0 stratum 8
启动服务
service ntpd start
- 安装相关软件
- 从服务器准备
- 安装相关软件
yum -y install ntp ntpdate -y - 进行时间同步
/usr/sbin/ntpdate 192.168.188.14
设置定时任务,每30分钟同步一次时间
crontab -e*/30 * * * * /usr/sbin/ntpdate 192.168.188.14
- 安装相关软件
- 主服务器的mysql配置
- 修改mysql配置文件
vim /etc/my.cnf
添加以下内容:server-id = 11 log-bin=master-bin binlog_format = MIXED log-slave-updates=true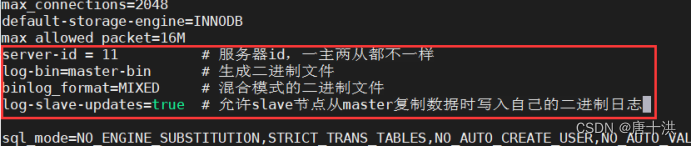
重启mysql服务
systemctl restart mysqld - 给myslave用户赋权,从节点可以通过myslave用户获取需要复制的数据
mysql -uroot -p
grant replication slave on *.* to 'myslave'@'192.168.188.%' identified by ‘123456’; flush privileges;
查看节点状态
show master status;
File显示日志名,Position显示偏移量
- 修改mysql配置文件
- 从服务器的mysql配置
- 修改mysql配置文件
vim /etc/my.cnfserver-id = 22 # 服务器id,各不相同 relay-log=relay-log-bin # 开启中继日志 relay-log-index=slave-relay-bin.index # 定义中继日志的位置和名称 relay_log_recovery = 1 # slave宕机后,如果relay-log损坏,会放弃所有还未执行的relay-log,重新从master上获取
另一台从服务器的配置,只有id改了
重启mysql服务
systemctl restart mysqld - 进入数据库配置同步
mysql -uroot -pchange master to master_host='192.168.188.14', master_user='myslave',master_password='123456', master_log_file='master-bin.000001', master_log_pos=604;
- 启动slave节点
start slave;
查看状态,如果能看到Slave_IO_Running: Yes和Slave_SQL_Running: Yes,说明没问题
show slave status\G
- 修改mysql配置文件
- 验证
- 在主MySQL服务器上创建一个数据库
create database db_test;
在从服务器上能看到就说明没问题
show databases;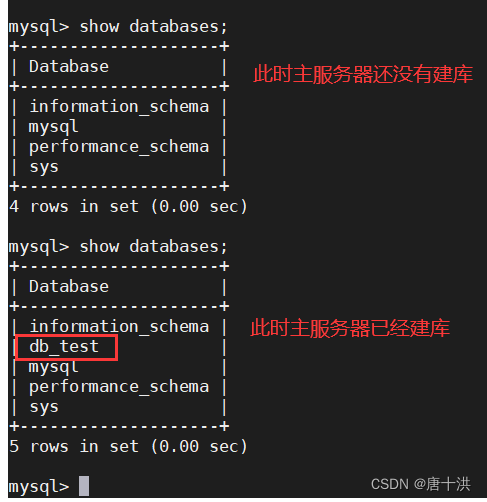
- 在主MySQL服务器上创建一个数据库
实验一点五、MySQL读写分离实验
实验前准备
该实验建立在实验一基础上,使用Amoeba对数据库的操作进行读写分离,读操作将会分发到两个从MySQL服务器上,写操作则会分发到主MySQL服务器上
Master服务器:192.168.188.14 mysql5.7
Slave服务器1:192.168.188.15 mysql5.7
Slave服务器2:192.168.188.16 mysql5.7
Amoeba服务器:192.168.188.13 jdk1.6、Amoeba(jdk不建议版本太高)
客户端:192.168.188.12
- 安装Java环境
- cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
我用的是编译好的文件,所以直接赋权执行
chmod +x jdk-6u14-linux-x64
./jdk-6u14-linux-x64.bin - 优化Java环境
mv jdk1.6.0_14/ /usr/local/jdk1.6
vim /etc/profile
在最后添加路径export JAVA_HOME=/usr/local/jdk1.6 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin export AMOEBA_HOME=/usr/local/amoeba export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile
看一下Java版本,三个java说明没问题
java -version
- cd /opt/
- 安装amoeba
- mkdir /usr/local/amoeba
tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
如果显示amoeba start|stop 说明没问题
- mkdir /usr/local/amoeba
- 配置amoeba读写分离
- 首先需要在三台服务器的MySQL上开放权限给amoeba
grant all on *.* to 'amo'@'192.168.188.%' identified by '123456'; - 修改amoeba配置文件
cd /usr/local/amoeba/conf/
做个备份
cp amoeba.xml amoeba.xml.bak
修改配置文件
vim amoeba.xml
主要需要修改以下内容

- 修改数据库配置文件
先备份
cp dbServers.xml dbServers.xml.bak
修改文件
vim dbServers.xml
主要改以下内容
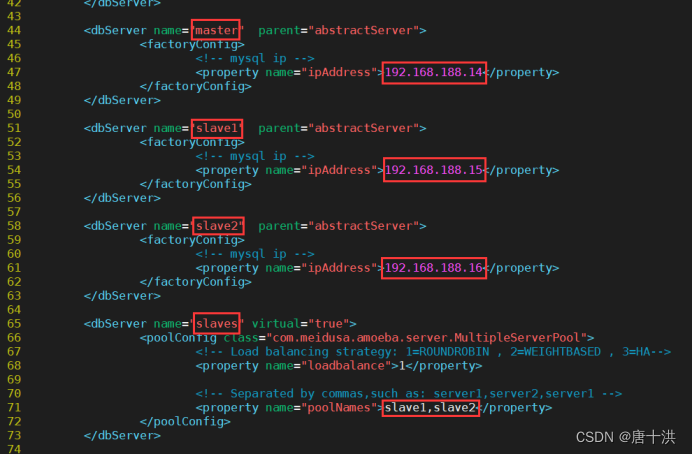
后台运行
/usr/local/amoeba/bin/amoeba start&
ctrl+c返回
查看一下端口是否正常使用,主要是8066是否开启
netstat -anpt | grep java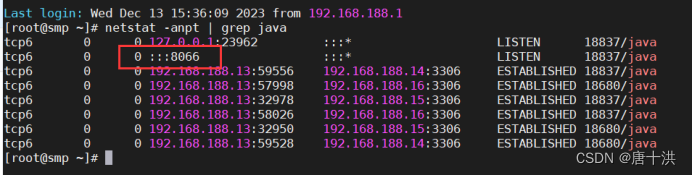
- 首先需要在三台服务器的MySQL上开放权限给amoeba
- 测试读写分离
- 客户端上安装mariadb
yum -y install mariadb-server mariadb
启动
systemctl start mariadb
通过amoeba代理服务器访问mysql
mysql -uamoeba -p123456 -h192.168.188.13 -P8066(端口号前面是大写P!千万别写错)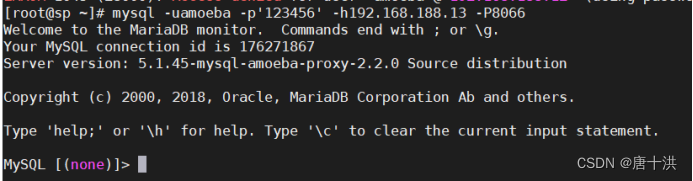
- 在主服务器上新建表
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));
两台从服务器上先关闭同步
stop slave;
在从服务器1上往新表中插入数据
use db_test;
insert into test values('1','zhangsan','this_is_slave1');
在从服务器2上往新表中插入数据
use db_test;
insert into test values('2','lisi','this_is_slave2');
在主服务器上往新表中插入数据
use db_test;
insert into test values('3','wangwu','this_is_master'); - 在客户端上查询新表
use db_test;
select * from test;
为什么是这样的结果?首先因为我们关闭了同步,所以主服务器写入的数据无法同步到从服务器,同时因为我们设定从服务器用来读,所以当我们查询时就会去找两台从服务器,所以就能看到这两台服务器上的数据,而且是独立分开的,因为我们是直接往从服务器上插入数据,从服务器上的数据本身就无法同步,在工作中是因为他们同时复制主服务器的数据才能保持一致。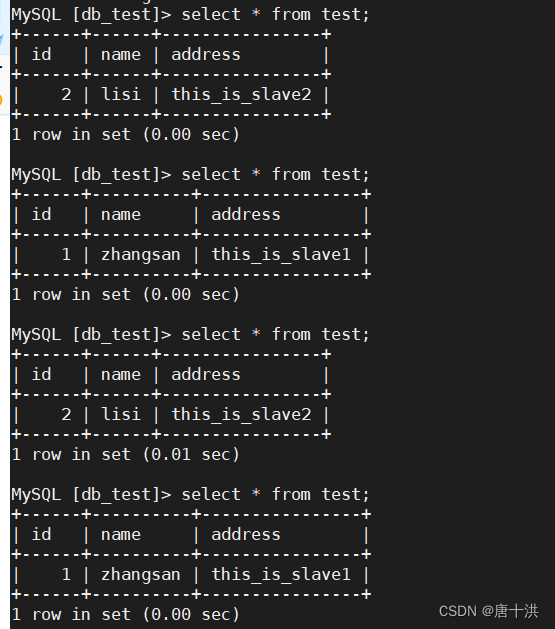
- 如果我们在上一步基础上,在客户端上往数据库插入新数据
use db_test;
insert into test values('4','qianqi','this_is_client');
在主服务器上查询的结果如下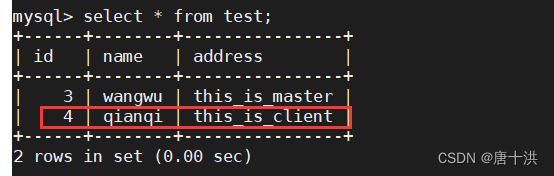
两台从服务器上查询结果如下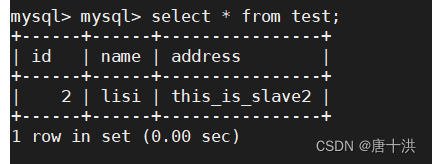
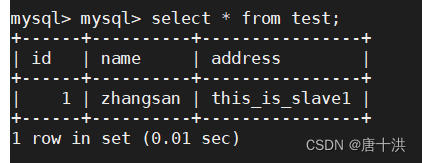
设定上主服务器用来写,所以我们在客户端上写入的数据会直接保存在主服务器上,因为没开同步的原因,从服务器无法复制主服务器上的数据,所以从服务器上的数据没变。
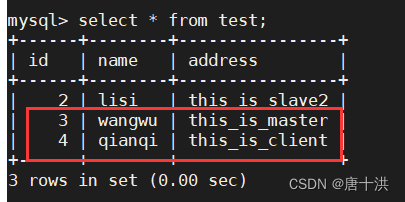
那么我们在从服务器上打开同步
start slave;
再查询,立马就有了主服务器上的数据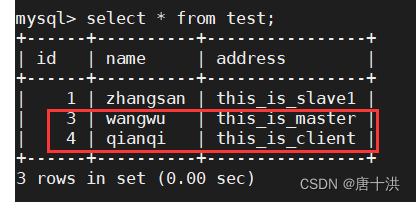
- 客户端上安装mariadb