一、Hive是什么
- Hive是一款建立在Hadoop之上的开源数据仓库系统,将Hadoop文件中的结构化、半结构化数据文件映射成一张数据库表,同时提供了一种类SQL语言(HQL),用于访问和分析存在Hadoop中的大型数据集。
- Hive的核心是将HQL转换成MapReduce程序,然后将其提交到Hadoop集群执行。(用户只需要编写HQL而不需要编写MapReduce程序,减少了学习成本、开发成本。)
- Hive利用HDFS存储数据,利用MapReduce查询分析数据
- Hive能将数据文件映射成一张表,能将SQL编译成为MapReduce然后处理这个表
- Hive的底层是用Java语言开发的
- 小数据集使用Hive分析,延迟很高。大数据集使用Hive分析,底层使用MapReduce分布式计算,速度才快。因此Hive是使用在大数据的场景下。
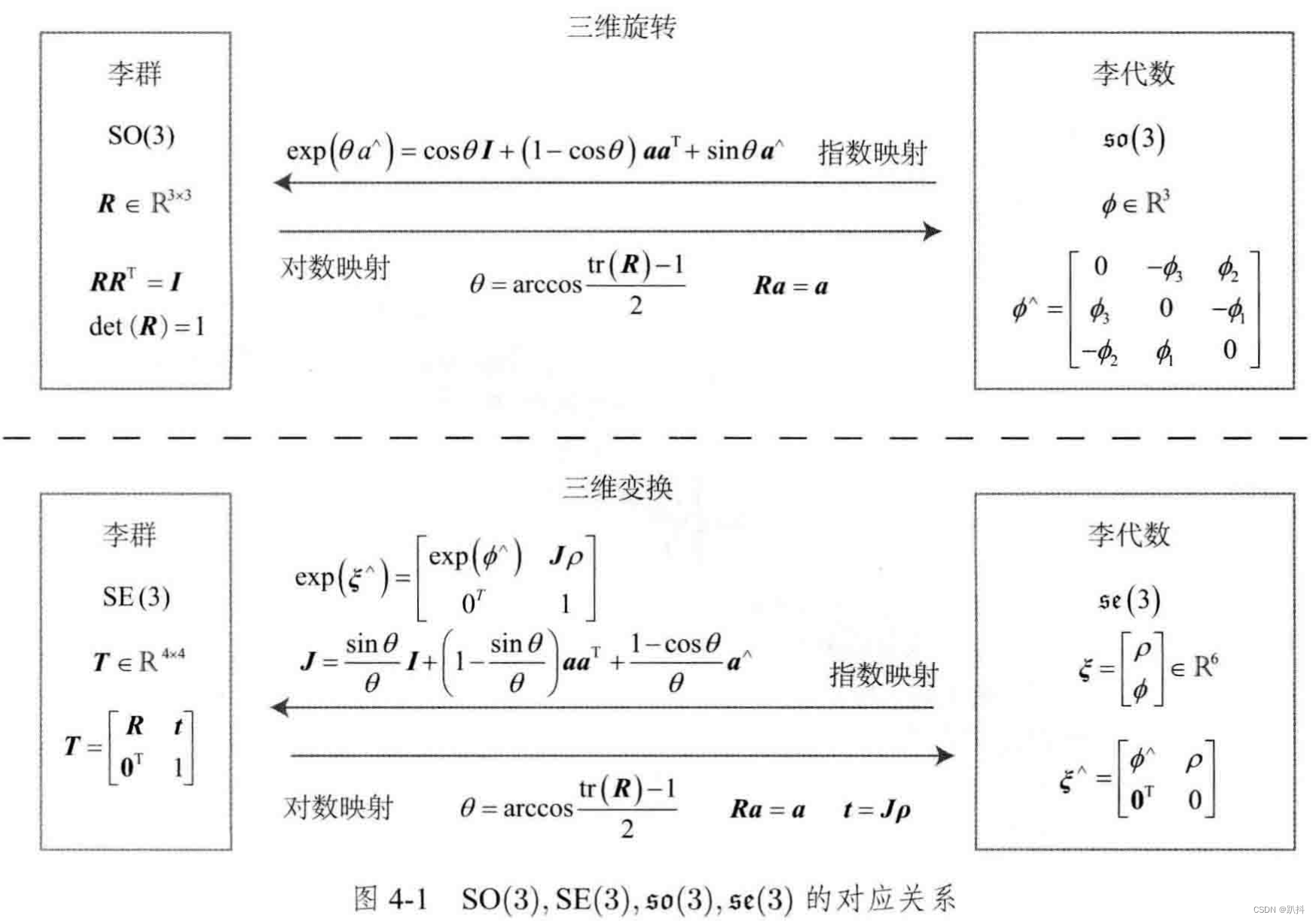
二、Hive的架构图
- hive能够写SQL的前提是针对一张表,而不是文件,因此要将文件和表之间的对应关系记录清楚。这个关系称为元数据信息
元数据信息记录:
- 表对应的什么文件(对应文件的位置)
- 表的每列对应文件的哪个字段,是什么类型(字段顺序,字段类型)
- 文件中各字段的分隔符是什么
Hive工作流程 :
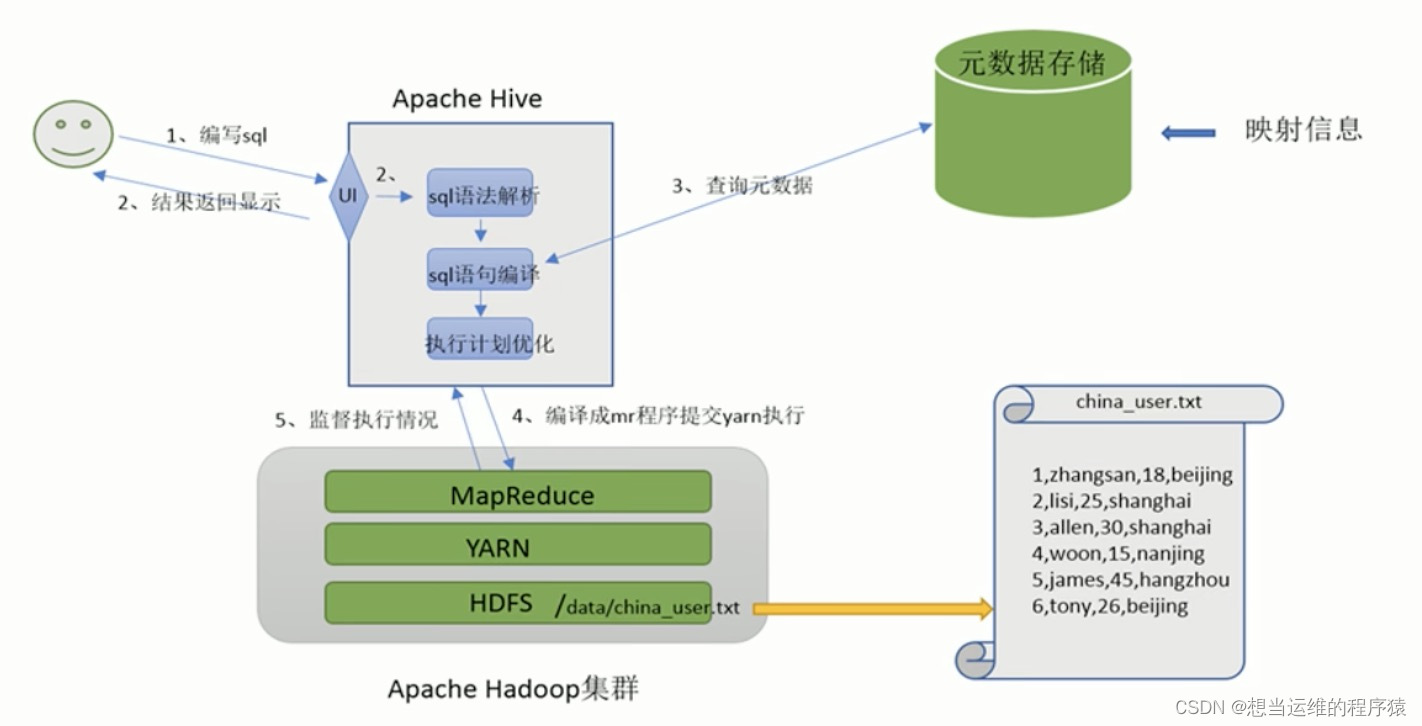
Hive架构图:
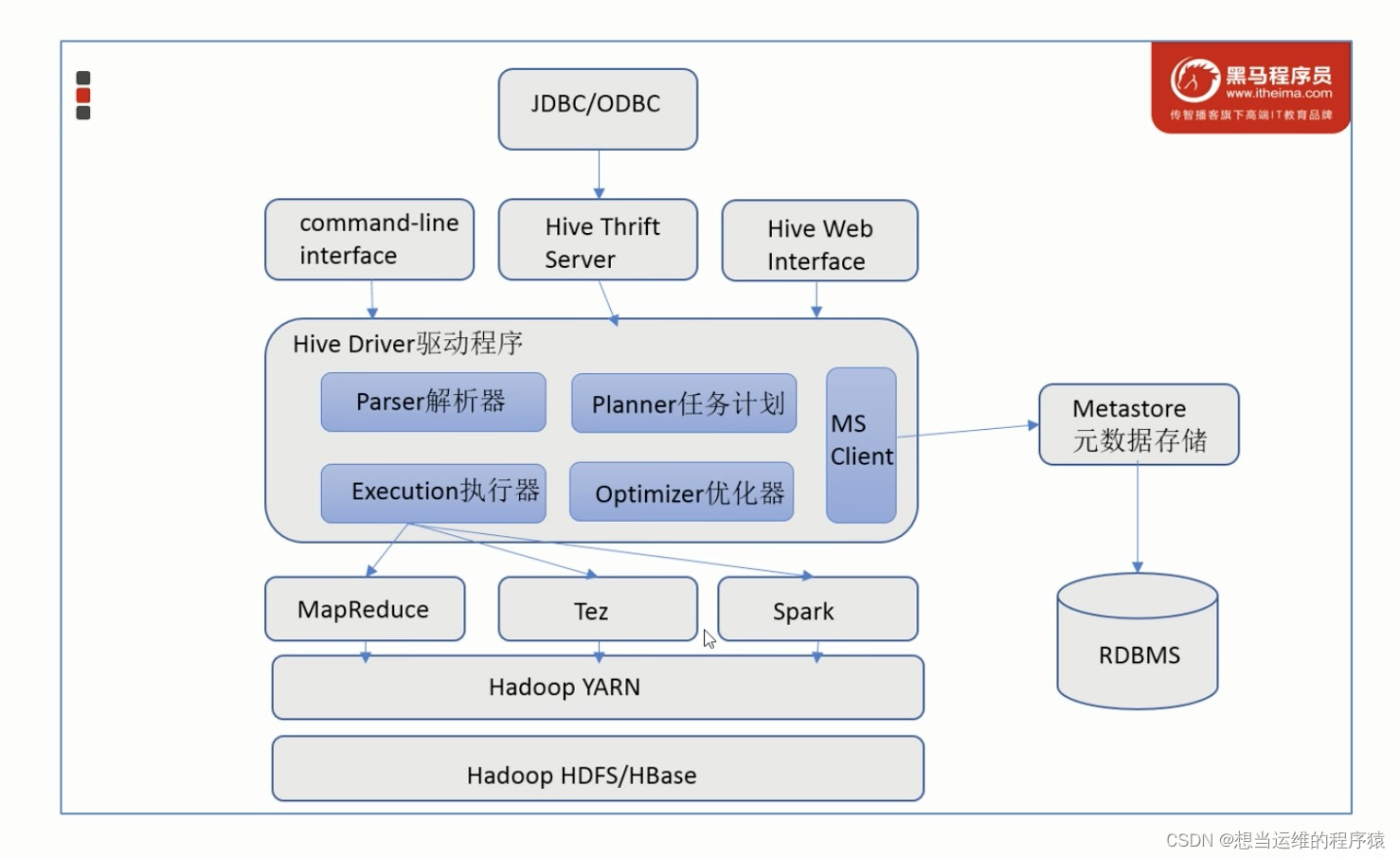
- Metastore元数据服务: 通常用mysql/derby等(关系型数据库)来存储表和文件的映射关系。Metastore服务用来管理metadata元数据,外部只能通过Metastore服务访问元数据的数据库。
- Driver驱动程序: Hive的核心,包括语法解析器、计划编译器、优化器、执行器
- 执行引擎: Hive不处理数据 ,而是由执行引擎处理,目前Hive支持MapReduece、Tez、Spark三种执行引擎。(Hive可以将SQL转换成MapReduce或Tez或Spark,默认是MapReduce)
三、Hive数据模型
Hive从数据模型上看与MySQL很相似,也有库、表、字段。
但是Hive只适合用来做海量数据的离线分析,Hive一般用于数仓,MySQL一般用于业务系统。
| Hive | MySQL | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | 离线数据分析 | 业务数据事务处理 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR、Tez、Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据、查询 | 增删改查 |
- Hive中的数据可以在粒度级别上分成3类
Table 表
Partition 分区
Bucket 分桶 - 底层存储:
数据库存储:itcast数据库对应的存储路径是/user/hive/warehouse/itcast.db(创建数据库相当于创建了个文件夹)
表存储:itcast数据库下t_user表对应的存储路径/user/hive/warehouse/itcast.db/t_user
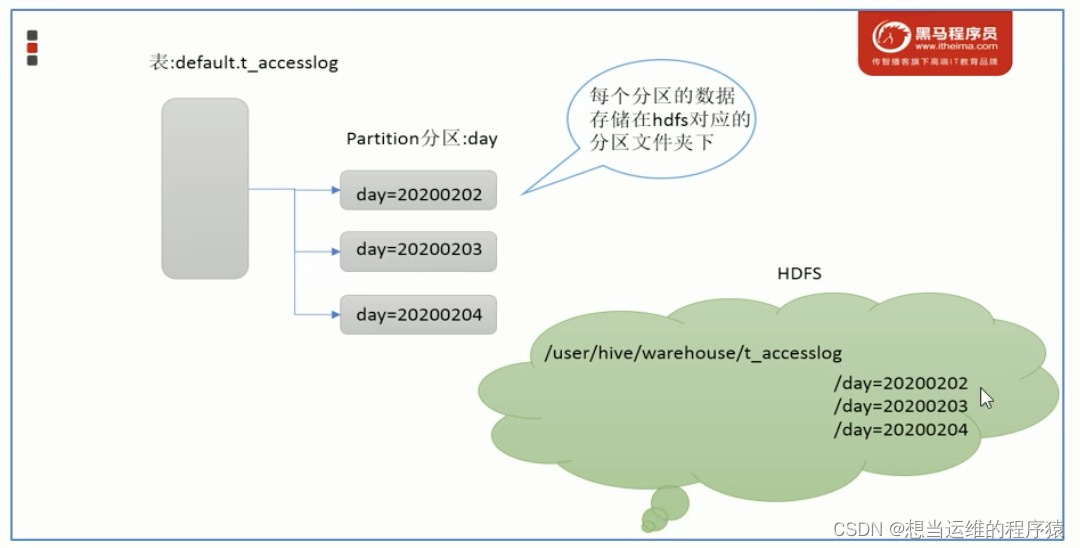
partitions分区:分区是指根据分区列(例如“日期day”)的值将表划分为不同分区,一个文件夹表示一个分区,分区列=分区值
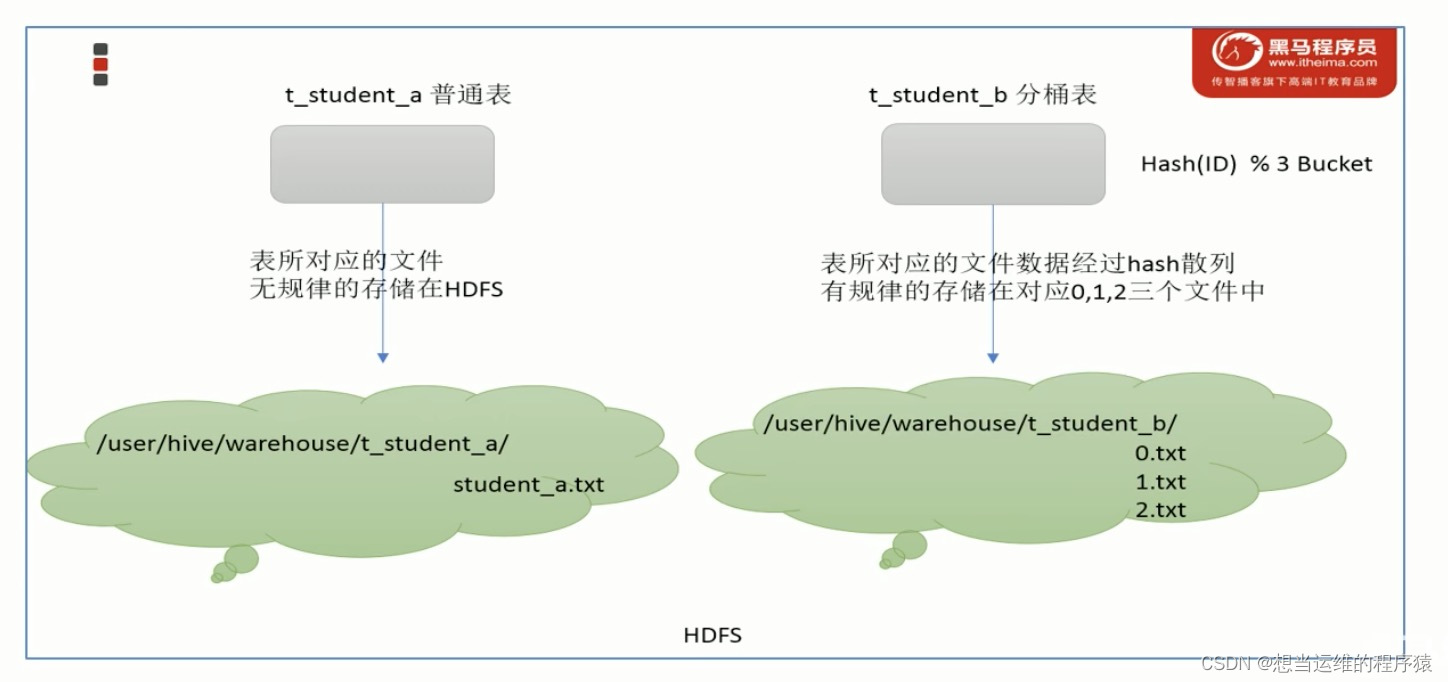
Buckets分桶:分区是指根据表中字段(例如“编号ID”)的值,经过Hash计算规则将文件划分成指定的若干个小文件
四、Hive的各个组件
五、Hive SQL DDL建表语法(重点)
完整的建表语法:

- 不是用loaction的情况下创建表相当于创建了一个文件夹,具体的数据文件需要放在对应的文件夹下
- 也可以在建表语句中使用location关键字指定数据文件在hdfs上的位置
- 一个表对应的文件夹下可以放多个数据文件,会一起解析成一张表
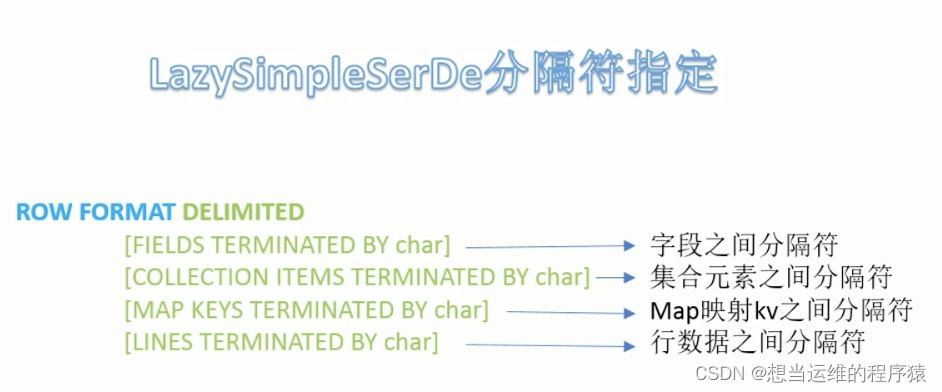
5.1 指定分隔符语法(关键字ROW FORMAT)
5.2 内部表与外部表(关键字EXTERNAL)
建表时用external关键字指定的就是外部表,否则为内部表(Managed Table)
当删除内部表时,会从MetaStore中删除表的元数据,从HDFS中删除表的数据。
当删除外部表时,只会从MetaStore中删除表的元数据,不会删除HDFS中表的数据。
内部表、外部表与是否使用location指定路径没有关系
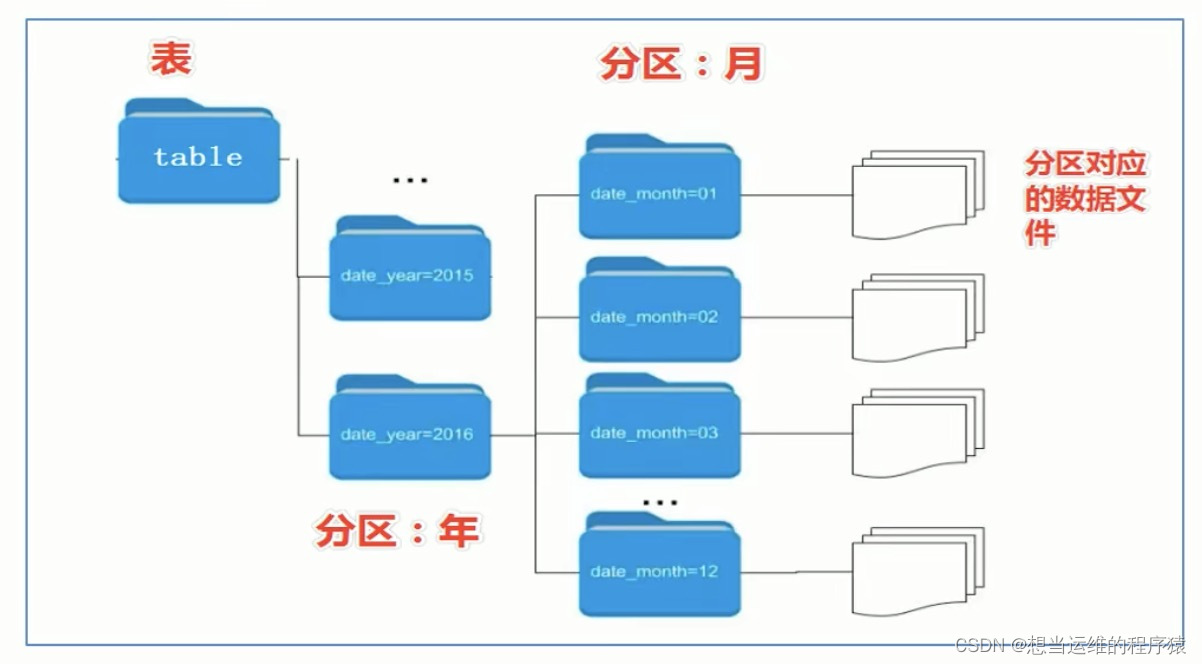
5.3 分区表(关键字PARTITIONED BY)
当Hive表对应的数据量大,文件多时,为了避免查询时全表扫描(速度慢),可以根据指定的字段(比如:日期、地域)对表进行分区,本质上是通过多个文件夹来管理分区,例如下图的多重分区:
- HDFS中分区表的存储方式:
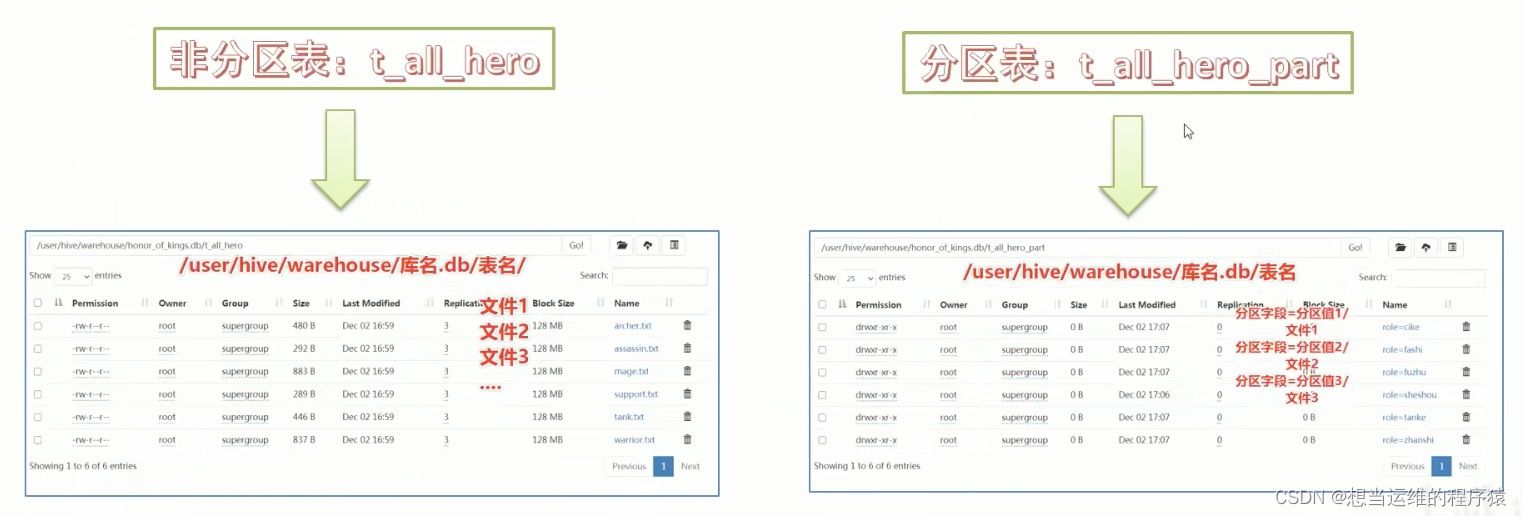
分区表中需要确保每个分区的数据文件是干净的,是和分区值所对应的,否则没有意义
分区表创建完,直接把数据文件移动到对应文件夹下是没用的,静态分区需要使用load data进行加载
静态分区举例:
静态分区指的是分区的字段值是手动写死的
-- 创建分区表,指定两个分区字段,province和city
create table t_user_province_city (id int, name string, age int)
partitioned by (province string,city string);
-- 静态分区加载数据(静态分区指的是province和city手工指定)
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city partiton(province='zhejiang',city='hangzhou');
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city partiton(province='zhejiang',city='ningbo');
-- 使用分区表(不用全表扫描,直接找到对应分区下的文件)
select * from t_user_province_city where province='zhejiang' and city='hangzhou'
动态分区举例:
动态分区指的是分区的字段值是基于查询结果(参数位置)自动推断出来的。核心语法是insert+select
-- 创建分区表,指定两个分区字段,province和city
create table t_user_province_city (id int, name string, age int)
partitioned by (province string,city string);
-- 动态分区(province和city并没有手动指定,而是从select中查出来的province_tmp和city_tmp)
insert into table t_user_province_city partion(province string,city string)
select tmp.*,tmp.province_tmp,tmp.city_tmp from t_user_province_city_tmp tmp
一、分区表不是建表的必要语法,是一种优化手段
二、分区字段不能是表中已有的字段
三、分区字段是虚拟字段,其数据并不存储在底层的文件中
四、分区字段值来自于手动指定(静态分区)或根据查询结果位置推断(动态分区)
五、Hive支持多重分区,可以在分区的基础上继续分区
5.4 分桶表(关键字CLUSTERED BY … INTO 分桶数 BUCKETS)
- 分桶表对应的数据文件在底层会被分解为若干各独立的小文件(一个文件 —> n个文件,当某个分区数据量过大时,可以再进行分桶)
- CLUSTERED BY指定根据哪几个字段进行分桶(字段必须是表中已经存在的字段)
- into n buckets表示分成几桶(几部分文件)
- 指定的字段如果字段一样,一定会分到一个桶中

分桶表的好处:
1.基于分桶字段查询时,减少全表扫描(对分桶字段再次计算哈希,找到对应的分桶编号,只查询那一个文件即可)
2.用分桶的字段join时可以提高mr程序效率,减少笛卡尔积数量
3.分桶表数据进行高效抽样(分桶后可以从每个桶中抽取一定比例的数据,可以保证数据更加的平均)

创建分桶表举例:
create table itheima.t_usa_covid19_bucket(
count_date string,
country string,
state string,
fips int,
cases int,
deaths int
)
clustered by(state) into 5 buckets; -- 根据state分为5桶
create table itheima.t_usa_covid19_bucket(
count_date string,
country string,
state string,
fips int,
cases int,
deaths int
)
clustered by(state)
sorted by (cases desc) into 5 buckets; -- 指定每个分桶内部根据cases降序排列
分桶表数据加载举例:
-- step1:把源数据加载到普通hive表中
create table itheima.t_usa_covid19(
count_date string,
country string,
state string,
fips int,
cases int,
deaths int
)
row format delimited fields terminated by ",";
-- 将源数据上传到HDFS,t_usa_covid19表对应的目录下
hadoop fs -put us-covid-counties.dat /user/hive/warehouse/itheima.db/t_usa_covid19
-- step2:使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket select * from t_usa_covid19
六、其他知识
6.1 四种排序order by、cluster by、distribute by、sort by
- order by:全局排序,要汇总数据才能排序,因此只有一个reduce,排序效率低
- cluster by:对某个字段分组且排序,并且只能升序,分的组数取决于reducetask的个数
- distribute by + sort by:distribute by负责根据指定字段进行分组,sort by负责分组内排序,例如:
select * from student distribute by sex sort by age desc;