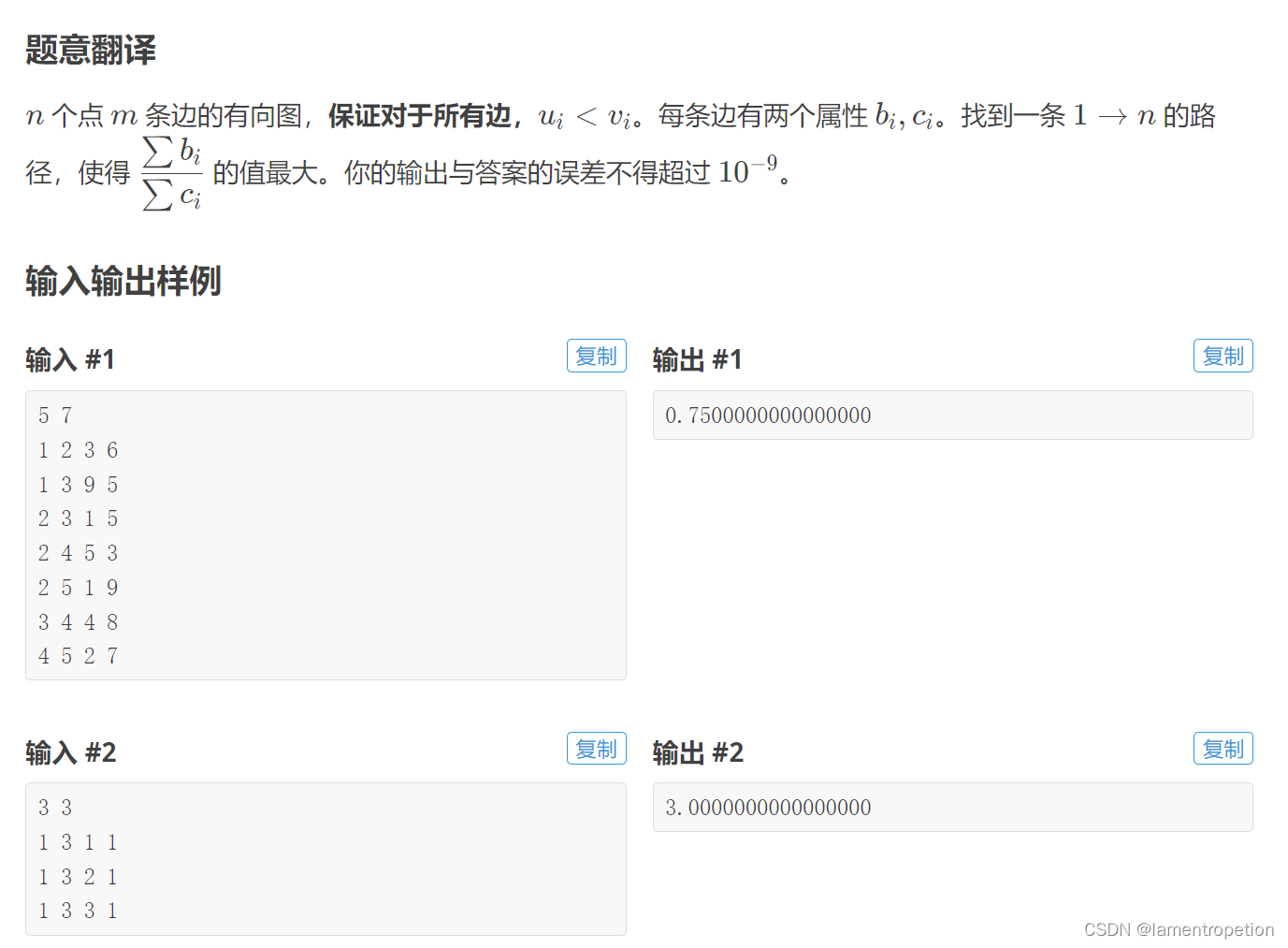
前言
为什么要学selenium??前面已经学了requests库我们会发现
对于绝大多数动态渲染的网页来说,用requests进行爬虫比较繁琐。
所以我们还是要学习一下selenium库,以帮助我们更高效的爬取网页。
环境:
pychar 2020.1 x64版本
谷歌浏览器驱动,需要根据自己的谷歌浏览器版本所对应的驱动进行下载。

selenium库,如果没有安装,可以在pychar终端输入 pip install selenium。
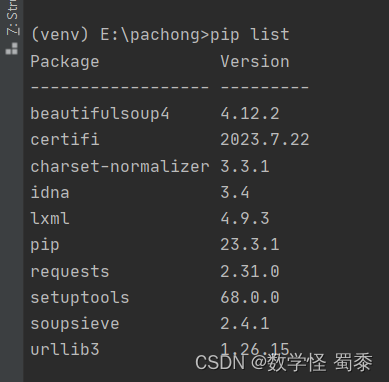
这是我没有安装之前的,可以使用pip list命令来查看自己有没有安装selenium库
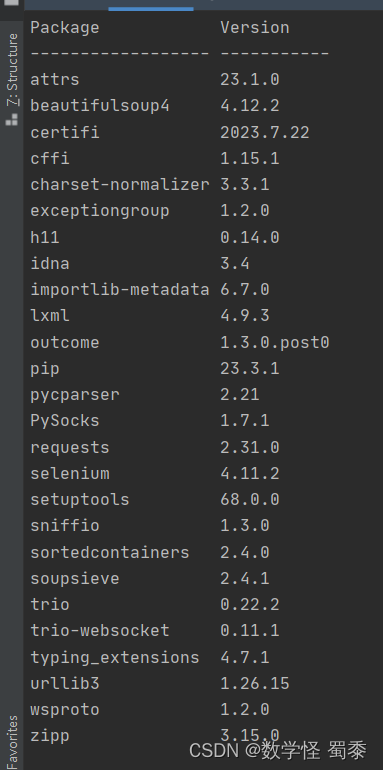
这是安装之后的,可以看到selenium库已经安装完成了。
下面进行简单的代码测试。咱们用淘宝网址和百度来进行测试。
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#浏览器驱动
bro=webdriver.Chrome()
#目标网址
bro.get('https://www.taobao.com')
#标签定位
s_input=bro.find_element(By.ID,'q')
#内容(key)输入
s_input.send_keys('java')
#标签定位
btn=bro.find_element(By.CLASS_NAME,'btn-search')
#点击事件
btn.click()
#垂直滚动2000xp
bro.execute_script('window.scrollTo(0,2000)')
time.sleep(2)
bro.get('https://www.baidu.com')
time.sleep(2)
bro.back()
time.sleep(2)
bro.forward()
time.sleep(2)
bro.quit()#释放内存最后附录一个比较官方的解释,selenium和requests的区别
Selenium 和 Requests 是两个用于 Web 爬虫和自动化的 Python 库,它们之间有一些主要区别:
1. 工作方式:
- Selenium:Selenium 是一个自动化测试工具,主要用于模拟用户与浏览器的交互。它通过控制 Web 浏览器(如 Chrome、Firefox)来加载网页并与网页元素进行交互。这使得它能够处理 JavaScript 生成的动态内容和与 Web 页面上的表单、按钮等元素进行交互。
- Requests:Requests 是一个用于发送 HTTP 请求的库。它可以模拟发送各种类型的请求(如 GET、POST、PUT 等)并处理响应。Requests 主要用于获取网页的 HTML 内容,不能直接处理 JavaScript 生成的动态内容。
2. 性能:
- Selenium:由于 Selenium 使用真实浏览器加载页面,因此在处理动态内容和需要与页面元素交互的场景下性能较低。此外,使用真实浏览器还需要额外的资源(如浏览器安装、驱动程序等)。
- Requests:Requests 直接发送 HTTP 请求并获取 HTML 内容,因此性能较高。但是,它不能处理 JavaScript 生成的动态内容。
3. 处理 JavaScript:
- Selenium:Selenium 可以很好地处理 JavaScript 生成的动态内容。
- Requests:Requests 无法直接处理 JavaScript 生成的动态内容。但是,可以结合其他库(如 BeautifulSoup、PyQuery 等)来解析 HTML 内容。
4. API 使用:
- Selenium:Selenium 提供了丰富的 API,可以用于查找、定位和操作网页元素。
- Requests:Requests 主要用于发送 HTTP 请求和处理响应。它不提供用于查找和操作网页元素的 API。
总之,Selenium 更适合用于需要模拟用户与浏览器交互的场景,例如处理动态内容、与表单和按钮等元素交互。而 Requests 更适合用于简单的数据抓取任务,例如获取网页的基本内容。在实际应用中,根据需求和场景选择合适的库。

![[C/C++]——内存管理](https://img-blog.csdnimg.cn/direct/dcac7a5806ed4cf0beab859ce6be3ebd.png)