概念
统计信息是为优化器的 cost 估算提供数据支撑,其中很重要的一点需求便是等值查询(EQUALS, IN 等) 场景下的基数估算。考虑以下 Case
CREATE TABLE `mc_tac_template` (
`ID` BIGINT ,
`NAME` varchar(50) NOT NULL,
`GENDER` varchar(10) NOT NULL,
PRIMARY KEY (`ID`),
KEY `KEY_NAME` USING BTREE (`NAME`),
KEY `KEY_GENDER` USING BTREE (`GENDER`)
)
SELECT * FROM User WHERE Name='wy' AND Gender='female'
我们的客户同时为性别和姓名设置了索引,这时优化器就要基于各个条件过滤行数多寡来估算选择不同索引的代价开销。就这个 case 而言,如果选到了 gender 的索引,查询过程很可能就不太妙了。
如果统计信息可以提供精确基数,例如 Name=‘wy’ 可以过滤出5行, Gender=‘female’ 只能过滤出一半的数据, 优化器就会知道,此时选择 KEY_NAME 是代价更小的选择。
为了支撑这里的估算过程,统计信息需要决定使用什么样的算法,这也决定了如何收集,如何估算。
算法
数据库中的基数估算类似于 Data Sketching,等值场景下的基数估算一般有两种选择,基于 sample 或基于全量数据。
SAMPLE
当数据量增长时, sample 是一种非常有效提升估算效率的手段。但 sample 必须至少面对以下问题
● 采样的随机化
● 采样数据与整体数据间的差异估算
○ 多少 sample 量才能确保误差率
● 当新数据出现时,如何采样
采样随机化是个很现实的问题,例如存储中的采样有两种做法, 一种按页采样,一种是每页都采一部分数据。第一种方案虽然非常高效,但随机性太差很容易导致估算的效果非常差,第二种方案虽然估算效果高一些,但在 IO 上相当于全量扫描了一遍。
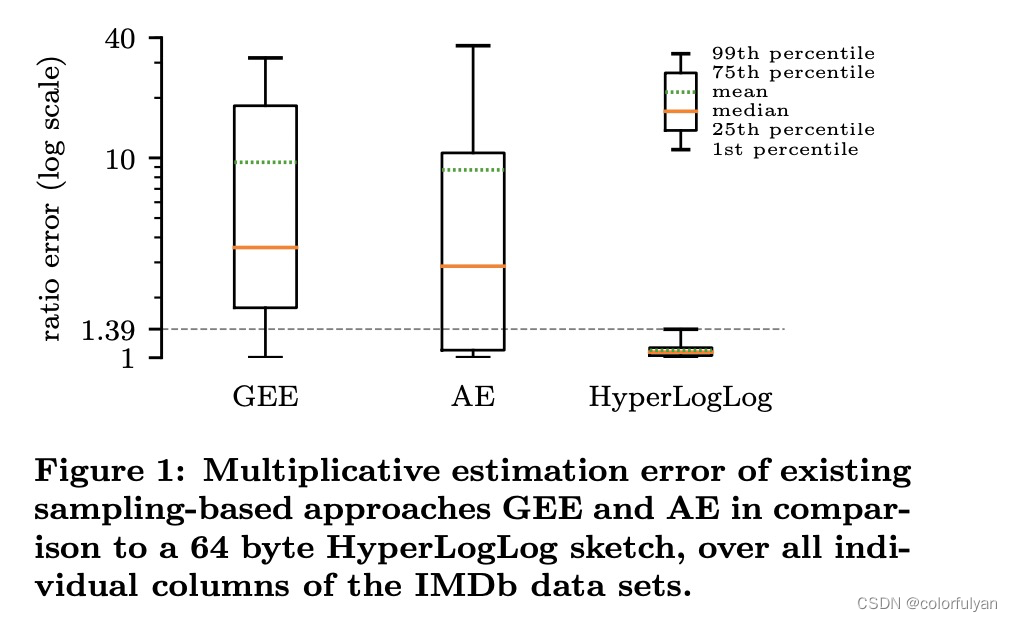
在 Every Row Counts: Combining Sketches and Sampling for Accurate Group-By Result Estimates 这篇论文中,作者比较了基于 Sample 的 GEE/AE 与面向全量数据的 HyperLogLog sketch 算法,HyperLogLog 的精确度完胜。当然这仅仅是在计算 NDV 的场景。
当我们需要某个单一确定数据在集群中的特征时, sample 都很难回答该类问题。举个例子,数据的存在问题,即某数据是否在集群中存在,如果该数据不在 sample 集中存在,那既有可能整体中也不存在,也有可能只是没有被 sample 到。
再例如通过采样估算 ndv 时,如果采样数据(假设 100000 行) 中 ndv 接近 100000,那么整体数据(假设 10000000行)的 ndv 有可能是 100000,或者也有可能是 10000000。
NDV: number of the different value
Sample 的数据集更适合用于解答范围条件下数据的特征问题。例如通过 sample 的数据来构建直方图,用于处理范围条件的查询问题,或者通过 sample 集估算多表等值 Join 的基数问题等。这些问题不在本文的讨论范围内,暂不展开。
非 Sample
● frequency:等值场景的基数估算就是获取某值在集合中的数量,也就是一个获取 frequency 的问题
CountMin Sketch
CountMin Sketch 通常用于解决 frequency 问题。它有点像 Bloom filter,同样需要一个数组以及一个 Hash 函数的集合,当遍历数据时,每个数据会被各个 Hash 函数 Map 到数组中的某个位置,并使该位置的计数器加1。在估算环节,取该数据对应所有计数器所得的最小值。可以预见它一定会确保估算值大于等于真实值,然后再通过一些手段确保误差率。具体的原理这里不再赘述。
CountMin Sketch 具体原理见 An Improved Data Stream Summary:The Count-Min Sketch and its Applications
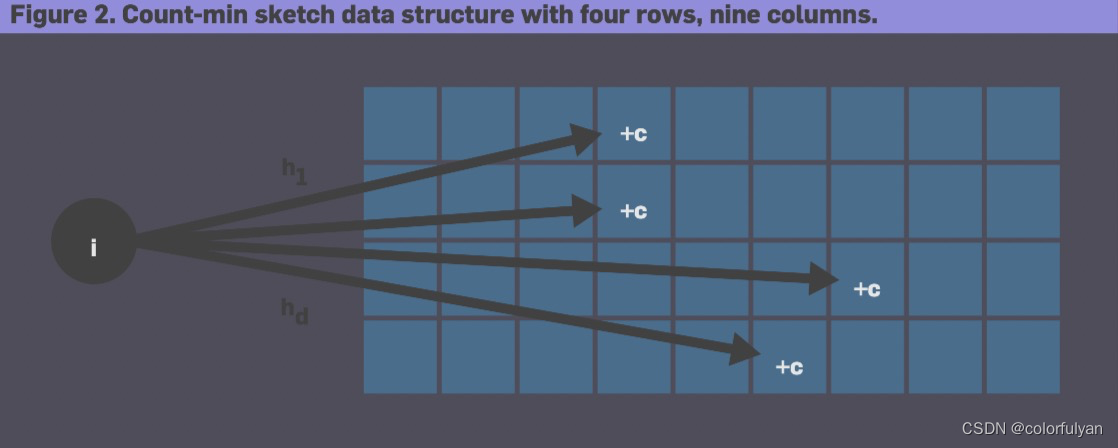
CountMin Sketch 最大的问题是当 Sketch 大小不合适时,很容易因 Hash collision 出现过度膨胀的估算。不管是增大 rows (即 Hash 函数)数量或 columns (即 Counter)的数量,都可以减少错误率。CountMin Sketch 在处理大量重复数据时很有优势,但在处理非倾斜数据时,很容易产生过于膨胀的结果。
当然,最开始 CountMin 也是用于处理热点数据获取这种场景。但在数据分布比较均匀的场景并不十分友好。
HyperLogLog+TopN
在 PolarDB-X 中,我们权衡之后使用 HyperLogLog+TopN 的方式处理 frequency 问题。具体的做法是这样的。
HyperLogLog 用于估算出准确的 NDV 值,TopN 用于处理数据倾斜。具体的算法大致如下:
if (topN.get(i) != 0) {
return (long)(topN.get(i) / sampleRate);
}
return (rowcount / cardinality);
HyperLogLog 需要扫描全量数据, TopN 可以通过 Sample 数据构建。
这种数据结构在处理数据的分布整体较为平均,仅有少数倾斜严重的数据场景中非常优秀。通过 rowcount / cardinality 稳定大多数非倾斜数据,通过 TopN 解决倾斜数据,但 TopN 的 Sample 可能会导致倾斜数据出现较大偏差。
从优化器的需求考虑,能够通过估算值明显的区别出倾斜与非倾斜数据,这已经可以满足 Plan 的选择需求。
测试
我们基于模拟的随机数据,对比了 CountMin Sketch 与 HyperLogLog+TopN ,在几个特定场景下的表现。
主要观察的数据有以下两项:
● 最大误差:估算值与真实值最大差异值
● 误差平方差:代表误差范围的稳定程度
阿里云双十一2核2G49.68/年
数据场景有以下三种:
bound = 100000
// 均衡:
for (int i = 0; i < size; i++) {
rs[i] = r.nextInt(bound);
}
// 一半数据倾斜到 1000 个 slot 中
if (r.nextBoolean()) {
rs[i] = r.nextInt(1000);
} else {
rs[i] = r.nextInt(bound);
}
// 一半数据倾斜至 100 个 slot 中
if (r.nextBoolean()) {
rs[i] = r.nextInt(100);
} else {
rs[i] = r.nextInt(bound);
}
算法初始化参数如下:
● CountMin Sketch 初始化参数 epsOfTotalCount = 0.0001,confidence=0.99,形成了 7*20000 的 long 数组,sketch大约占1M空间
● TopN 固定 sample 10W 个数据,保留约不超过5000个最大值。 HyperLogLog 精确度在1.04/sqrt(2^16) = 0.004, 空间大约在50K以下
测试的大致结果如下:
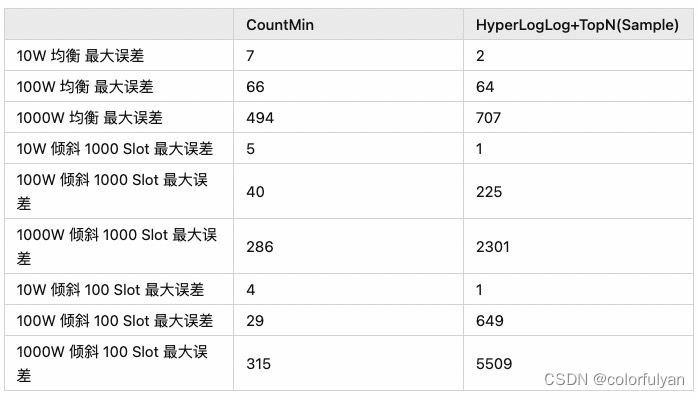
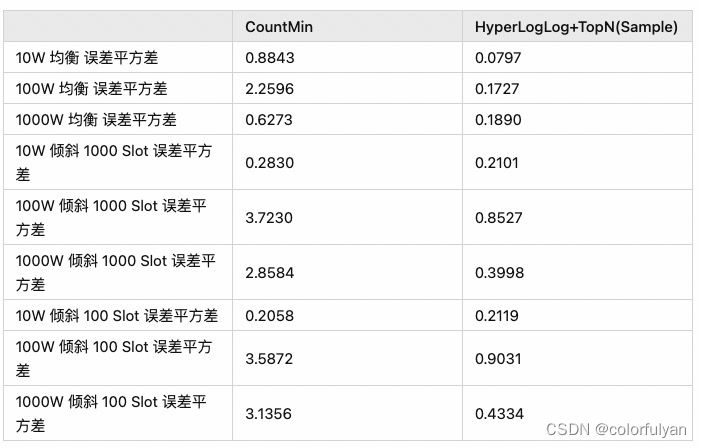
在最大误差中,CountMin 主要来自于均衡数据的膨胀。Hll + TopN 在 10W 的场景最大误差来自于单一值被估算成了 rowcount/cardinality, 但这个误差非常小。在100W 和 1000W 的场景,Hll + TopN 的最大误差远大于 CountMin,但从整体上判断,HLL+TopN的误差平方差相比而方更加稳定,这些误差主要来自于 TopN 中未记录的 Skew 数据(未 Sample 到或 TopN 容量不足)。
整体上比较来看,CountMin Sketch 随数据量增长,针对倾斜数据的估算会更准确,但非倾斜数据的估算会出现较严重偏差,这体现在误差平方差在大数据场景一直保持较高。Hll+TopN 非倾斜数据的估算中非常稳定且准确,倾斜数据的估算会随数据量增长或 sample 的非随机性增加而有较严重膨胀。
从等值条件基数估算的场景考虑,如果要确保倾斜数据的精确度,应该要选择 CountMin Sketch,如果要保证非倾斜数据的精确度,倾斜数据只要能识别出就好,采用 Hll+TopN 是更加实用的选择。
注意以上测试结果仅针对模拟的数据场景。
采集
虽然 CountMin 和 HyperLogLog 回答的问题不同(一个是 frequency, 一个是 ndv ),但本质上都是基于 Sketch 来描述整体数据。基于 Sketch 的算法除了内存占用小以外,还有个非常大的好处是多个 Sketch 可以合并,并用于描述多分片数据。
大部分统计信息模块需要收集的数据是不需要考虑多分片带来的影响的,比如说最大最小值,rowcount,null 值数量,列长度等等。但 ndv 不同,多个分片的 ndv 值无法简单相加得出。但 HyperLogLog 的 Sketch 数据可以通过多分片合并的方式估算出整体的 ndv 值。CountMin 的 Sketch 也可以通过合并处理。
CountMin 和 HyperLogLog 如果想要较高的精确度,必须要扫描全量的数据,但这会至少给 IO 带来巨大的影响。 Sketch 类型的算法可以针对各个分片数据建立不同的 Sketch,然后仅扫描有数据变更分片并更新其 Sketch,这样避免了扫描全量数据的同时,仍然可以在全局得到精确的估算值。
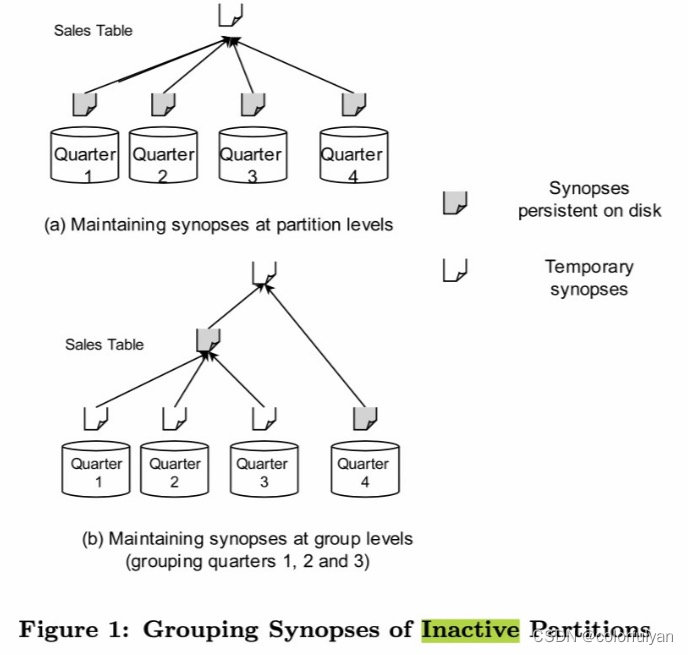
在 Oracle 11g 中,对不活跃的数据分片分成一组统一进行 sketch,这可以极大减少 sketch 占用的内存空间
结语
The approximate approach is often faster and more efficient
--BY GRAHAM CORMODE
到目前为止,数据特征领域已然展开了很长时间的研究,非常多的工具被开发出来。本文主要简单介绍了其中一部分基于 Sketch 的技术在数据库等值查询场景中的区别与影响。
可以看到,这些技术提供了不同场景下解决特定问题的能力,但并非银弹,谨慎权衡的选择工具,才能带来更佳的优化效果。
参考
● Efficient and Scalable Statistics Gathering for Large Databases in Oracle 11g∗
● An Improved Data Stream Summary:The Count-Min Sketch and its Applications
● Every Row Counts: Combining Sketches and Sampling for Accurate Group-By Result Estimates
● HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm
● Towards Estimation Error Guarantees for Distinct Values
● Data Sketching
● New Sampling-Based Summary Statistics for Improving Approximate Query Answers
● A Comparison of Five Probabilistic View-Size Estimation Techniques in OLAP
● http://content.research.neustar.biz/blog/hll.html