如何用rr来debug你的C/C++程序(Linux)
想象一下如果你的程序某时会崩溃,但是不能稳定复现,你会如何debug它?
用传统debugger面临的问题就是你不知道这次运行的时候能不能复现,你猜测可能某段代码出现了问题,所以进行了一番检查。但如果最后不能复现的话,刚刚所做的工作就是无用的。gdb通过一个反向调试的功能解决了这个问题。但是gdb的反向调试代价很大,在大型项目上运行很吃力。Bug出现的几率高还好,但如果出现的概率是1/100,甚至1/1000呢?
要么就用大量printf,通过print出数据来进行debug,好处是重复运行程序的成本较低,可以写个脚本,反复可以多次尝试,直到程序崩溃,然后反回去看log。但也有一样的问题就是效率不高,哪怕复现成功了,也很有可能现有的printf并不能解决问题,需要加更多的printf,又要反复运行程序来复现。
rr的出现就是来解决上面提到的问题。rr是一个debugger,通过记录程序运行时的状态,来提供一个可以反复反向调试的debug环境。
rr的优点
-
比gdb的反向调试更成熟,并且有更少的消耗
-
对多线程进程友好,可以只调试某个进程
-
支持gdb的指令
安装
推荐按着官方文档来进行本地编译,然后安装。请注意rr现在只能在Linux上运行并且对CPU有一定的要求,具体要求请看官方文档。
ubuntu快速安装
cd /tmp
wget https://github.com/rr-debugger/rr/releases/download/5.5.0/rr-5.5.0-Linux-$(uname -m).deb
sudo dpkg -i rr-5.5.0-Linux-$(uname -m).deb操作系统配置
需要 Linux 内核 3.11 或更高版本(检查uname -r)。
/proc/sys/kernel/perf_event_paranoid必须 <= 1 rr 才能有效工作(即能够使用perf计数器)。一些发行版将其设置为 2 或更高,在这种情况下,您需要将其设置为 1 或使用rr record -n,这很慢。通过运行临时更改设置
$ sudo sysctl kernel.perf_event_paranoid=1基础使用方法
使用rr总共分成两步
-
第一步是
rr record- 运行程序,并且记录下程序运行时的状态。 -
第二部是
rr replay- 回放记录好的程序。
实例
#include <cstdio>
#include <thread>
#include <stdlib.h>
void inc(int& x, int id) {
id = id + 1; //这一行有点多余,主要是为了展示rr的reverse-continue 功能
if (x == 2 && id == 3) {
abort();
}
++x;
printf("x=%d\n", x);
}
int main () {
int x = 0;
std::thread t1(inc, std::ref(x), 1);
std::thread t2(inc, std::ref(x), 2);
std::thread t3(inc, std::ref(x), 3);
std::thread t4(inc, std::ref(x), 4);
t1.join();
t2.join();
t3.join();
t4.join();
}上面这个程序启动了多个线程,会在当t2这个线程运行时x == 2 && id == 3的时候崩溃。因为线程运行的顺序是不可控的,所以这个程序并不会总是崩溃。
我们首先编译上面这个程序
-
运行
g++ -g main.cpp -o main -lpthread。编译好后,我们得到了main这个二进制文件。
然后我们来record
-
这里我们运行
rr record --chaos ./main。
rr record --chaos ./main-
正常情况我们
rr record ../main就可以了,但我们这里用了--chaos让rr可以更加随机的进行调度,从而增加复现这个bug的概率。 -
我们还可以自动化这个步骤通过
while rr record --chaos ./main; do :; done来反复运行这个程序,这个while循环会在main崩溃的时候自动结束。
while rr record --chaos ./main; do :; done 
我这次运行了32次才成功复现这个崩溃。
rr 会把每次的记录存放在~/.local/share/rr里面,这时候我们ls看一下。

每个main-<数字>就是rr存放的记录,rr支持我们回放每一个记录,rr replay 默认会回放最新的那个,我们直接rr replay就好了。

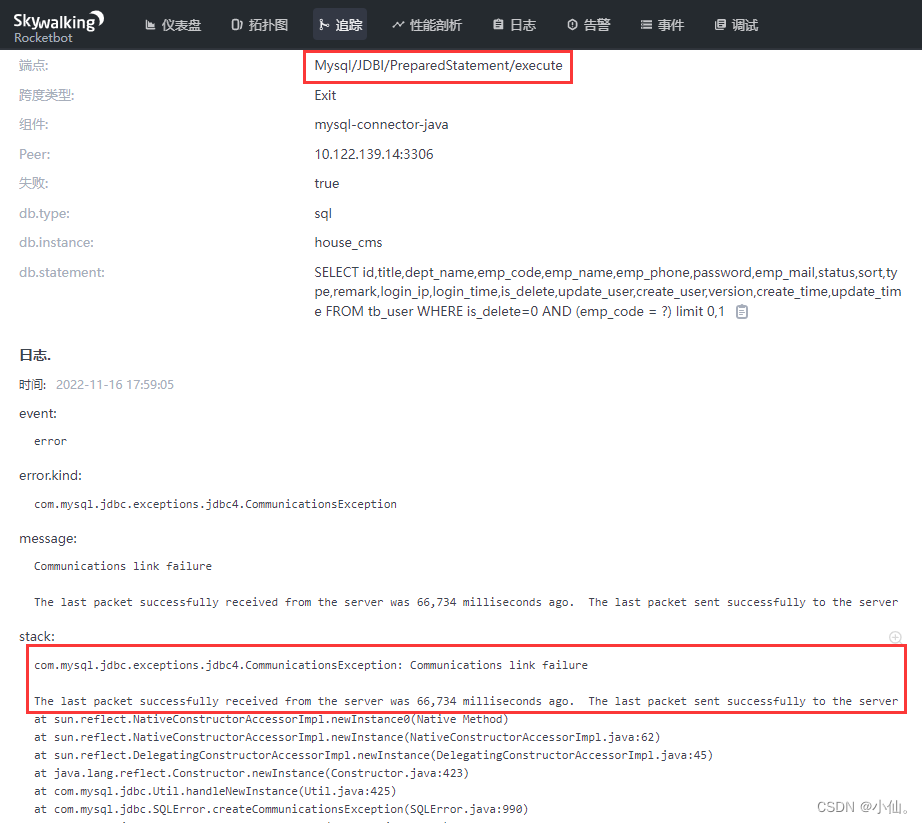
上图就是rr debugger的样子。因为rr使用的是gdb protocol,所以我们可以运行各种gdb的指令。
我们接下来利用gdb的continue指令 (continue指令会让程序一直运行,直到程序结束,程序崩溃,或者命中断点),让程序自动停在崩溃的地方。
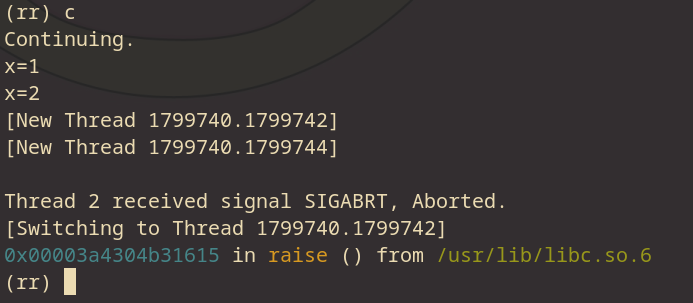
我们看到rr的回放也print出了x=1 和 x=2, 跟当时运行时是完全一样的。这里我们输入bt可以检查call stack的内容。可以看到abort()是让程序崩溃的原因。
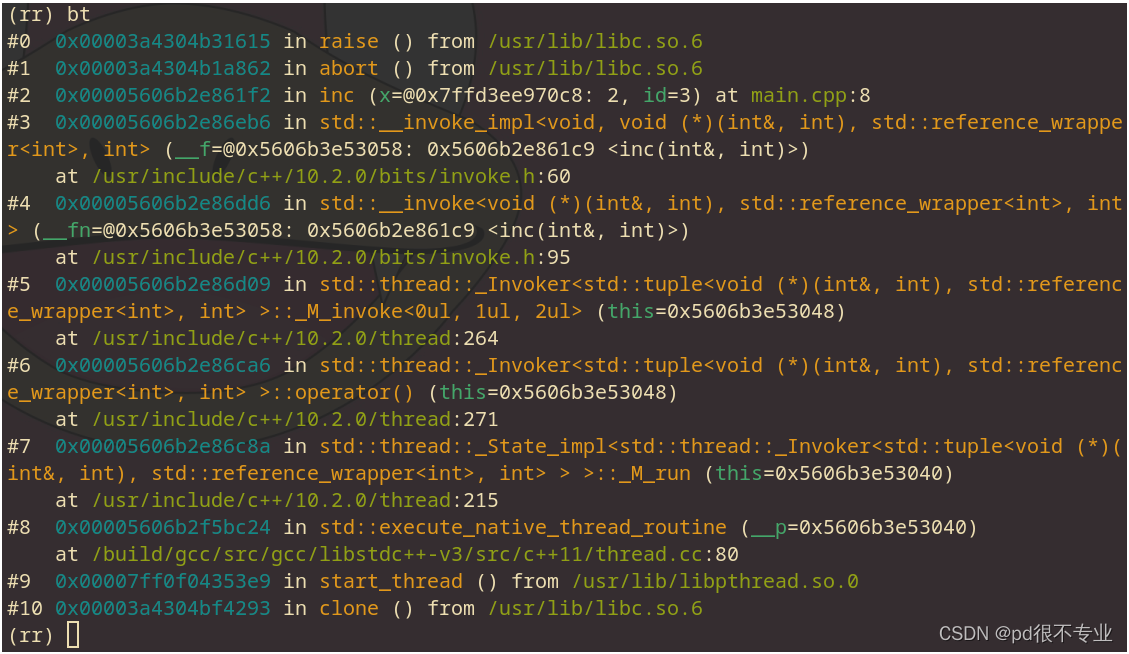
输入up 2,来到inc()的这个frame。再配合list,就可以看到具体造成崩溃的代码。这里我们输入 p id 可以看到当前id的数据,确实是id == 3造成了崩溃。
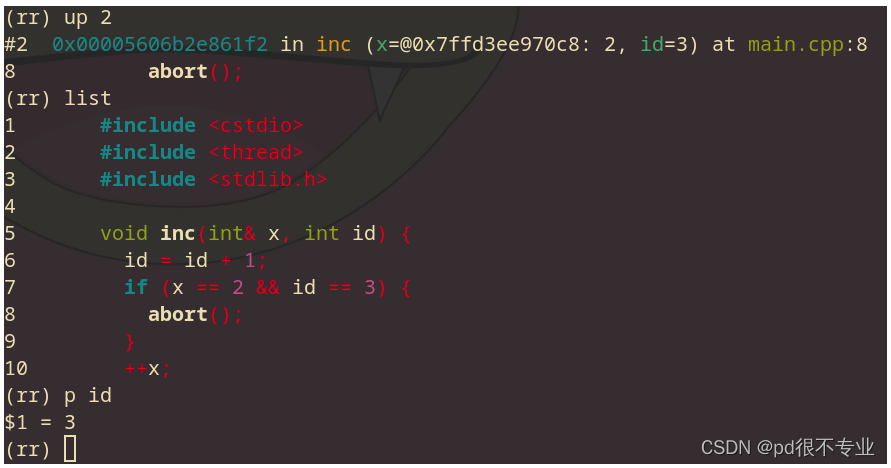
这时候我们需要寻找为什么id是3的原因,这段代码很明显是由id = id + 1造成的,但是假如我们不知道是哪里造成id变化,我们可以输入watch -l id 来观察这个变量,再通过rc来回到造成变化的代码。
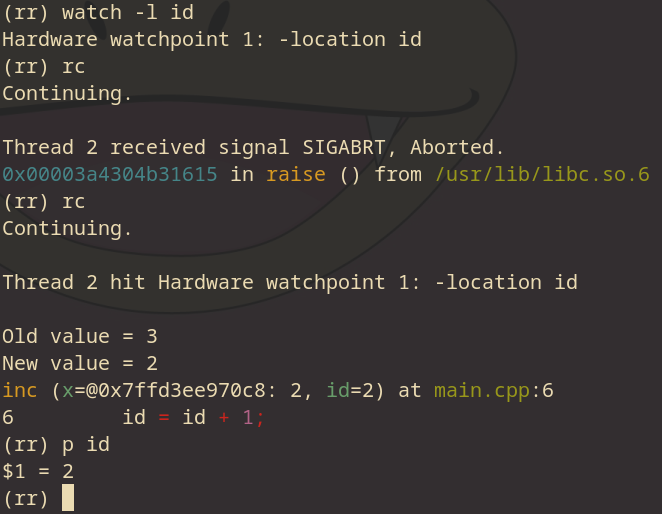
注意这里我们输入了rc两次,第一次rc的时候,rr收到了程序崩溃的信号,所以停止了,我们需要再输入一次让它继续。rr自动就帮我们回到了id变化的这一行代码,这时候我们再看p id,id就是2了。通过追逐id的变化,我们就可以对代码进行必要的修改了。
这就是rr的能力,不单单我们返回到了这一行代码,连程序相应的状态都回到了这个时刻。rr的强大之处就是给我们的一种回到过去的能力。
ROS下使用方式补充
调试ROS节点方式如下:
rosrun --prefix 'rr record' you_ros_node
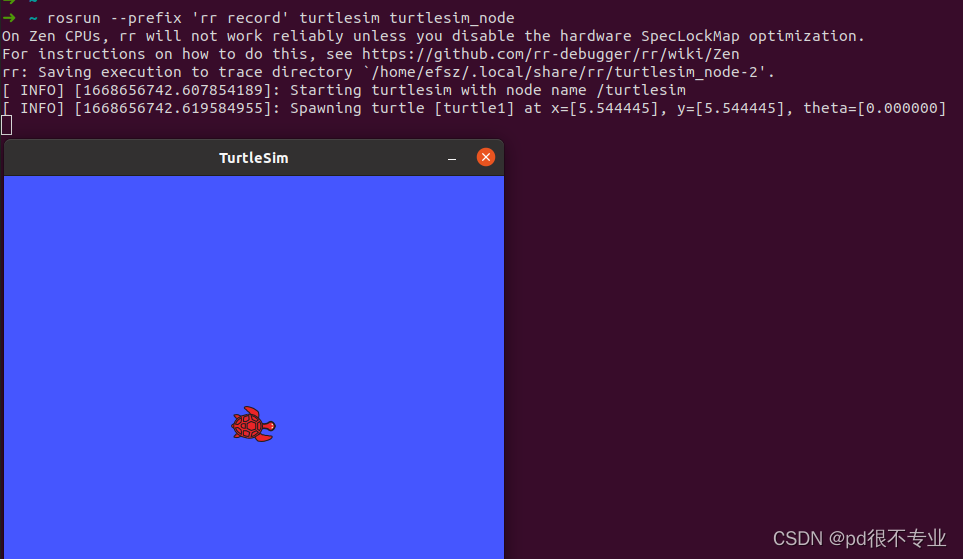
rosrun --prefix 'rr record --chaos' teleop_twist_keyboard teleop_twist_keyboard.py例如调试小乌龟:
➜ ~ rosrun --prefix 'rr record' turtlesim turtlesim_node
On Zen CPUs, rr will not work reliably unless you disable the hardware SpecLockMap optimization.
For instructions on how to do this, see https://github.com/rr-debugger/rr/wiki/Zen
rr: Saving execution to trace directory `/home/efsz/.local/share/rr/turtlesim_node-1'.
[ INFO] [1668656353.548471340]: Starting turtlesim with node name /turtlesim
[ INFO] [1668656353.562282765]: Spawning turtle [turtle1] at x=[5.544445], y=[5.544445], theta=[0.000000]




![[附源码]Python计算机毕业设计java高校社团管理系统](https://img-blog.csdnimg.cn/46b79143ec1e4600aeef458e9490f001.png)