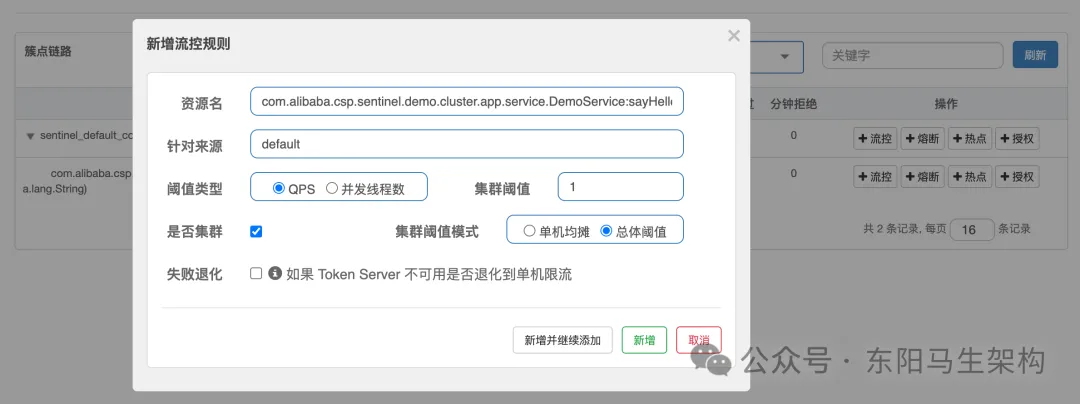
在人工智能飞速发展的今天,「机器学习」已成为推动数字化转型的核心引擎。无论是手机的人脸解锁、网购平台的推荐系统,还是自动驾驶汽车的决策能力,背后都离不开机器学习的技术支撑。那么,机器学习究竟是什么?它又有哪些类型和应用?让我们一探究竟。
机器学习是什么?
机器学习(Machine Learning)是一门通过从数据中自动分析规律、构建模型,从而对未知数据进行预测或决策的科学。简单来说,它是让计算机像人类一样“学习”的算法工具。例如:
预测房价:通过历史房价数据与房屋特征(面积、地段等),训练模型预测新房源的价格。
疾病诊断:基于患者的体检指标,判断是否患有特定疾病。
机器学习的核心是“从数据中学习规律”,并通过模型将输入数据映射到预期结果(如图像识别中的“猫 vs 狗”分类)。
机器学习的五大核心类型
1. 监督学习(Supervised Learning)
定义:基于带有标签的数据构建模型,通过特征与标签的映射关系进行预测。
典型任务:分类(如肿瘤良恶性判断)与回归(如波士顿房价预测)。
关键特点:依赖完整标注数据,输出明确的目标值。
应用实例:银行贷款风险评估、支付宝用户信用评分。
2. 无监督学习(Unsupervised Learning)
定义:从无标签数据中挖掘隐藏结构,无需预先定义目标。
典型任务:聚类分析(如用户群体细分)与降维(如PCA可视化高维数据)。
关键特点:适用于探索性数据分析,擅长发现潜在模式。
应用实例:产品价值组合划分、电商平台异常交易检测。
3. 半监督学习(Semi-Supervised Learning)
定义:结合少量标签数据与大量无标签数据共同训练模型。
典型任务:标签成本高昂的场景(如医学影像分类),如预测同瓜秧上其他西瓜成熟度。
关键特点:通过无标签数据增强模型泛化能力,缓解小样本问题。
技术示例:“对网站关键词整合建立层级语料库”可视为半监督应用。
4. 自监督学习(Self-Supervised Learning)
定义:利用数据自身构造监督信号(如预测缺失部分)。
典型任务:自然语言处理(如词向量化)、计算机视觉(如预测视频未来帧)。
关键特点:突破标签依赖,利用海量无标注数据。
实现方法:“将词汇转化为结构化向量”即通过TF-IDF等无监督特征生成隐含标签。
5. 强化学习(Reinforcement Learning)
定义:通过环境交互的奖励信号优化策略(如AlphaGo围棋决策)。
典型任务:序列决策问题(如机器人路径规划、游戏AI训练)。
关键特点:注重长期累积奖励,适合动态环境下的自主学习。
应用场景:西瓜种植过程优化(种瓜问题中的多步骤决策)。
为什么需要多种学习范式?
“没有免费的午餐定理”,任何算法在特定任务中的优势都可能在另一任务中失效。例如:
监督学习依赖高质量标签,但实际应用中标签常稀缺(如医学数据)。
自监督学习通过构造辅助任务(如填空、扭曲图像修复)提取通用特征,成为大模型预训练的核心技术。
半监督学习在部分标注场景(如支付宝信用评估的部分用户标签缺失)中实现效率与精度的平衡。
机器学习的关键挑战
过拟合与欠拟合
过拟合:模型在训练集上表现完美,但泛化能力差(如“死记硬背”)。解决方法包括增加数据量、简化模型、使用正则化。
欠拟合:模型无法捕捉数据规律。需增加模型复杂度或改进特征工程。
评价标准
分类任务:准确率、查准率(Precision)、查全率(Recall)。
回归任务:均方误差(MSE)。
聚类任务:簇内距离与簇间距离的平衡。
机器学习的未来:自动化与普及
随着AutoML工具(如AutoGluon)的成熟,机器学习正从“专家专属”走向“全民可用”。未来,结合深度学习、云计算和大数据技术,机器学习将在医疗、金融、制造等领域释放更大潜力。“没有免费的午餐定理提醒我们,没有一种算法能适应所有问题,但理解原理才能做出最佳选择。”










![[OS] vDSO + vvar(频繁调用的处理) | 存储:寄存器(高效)和栈(空间大)| ELF标准包装规范(加速程序加载)](https://i-blog.csdnimg.cn/img_convert/5e9339cb8d1041c1072eb4b1b3906960.png)