一、 个人博客系统
一)限制强制登录
- 问题:限制用户登录后才能进行相关操作
- 解决:
1)前端:
① 写一个函数用于判断登录状态,如果返回的状态码是200就不进行任何操作,否则Ajax实现页面的跳转操作。
② 因为 登录限制及跳转 在很多页面中都使用,但是我们没必要进行重复性的工作,所以直接在前端代码中新建一个文件夹js,并新建文件 app.js 来存储这些重复的代码,以此来实现代码的复用。
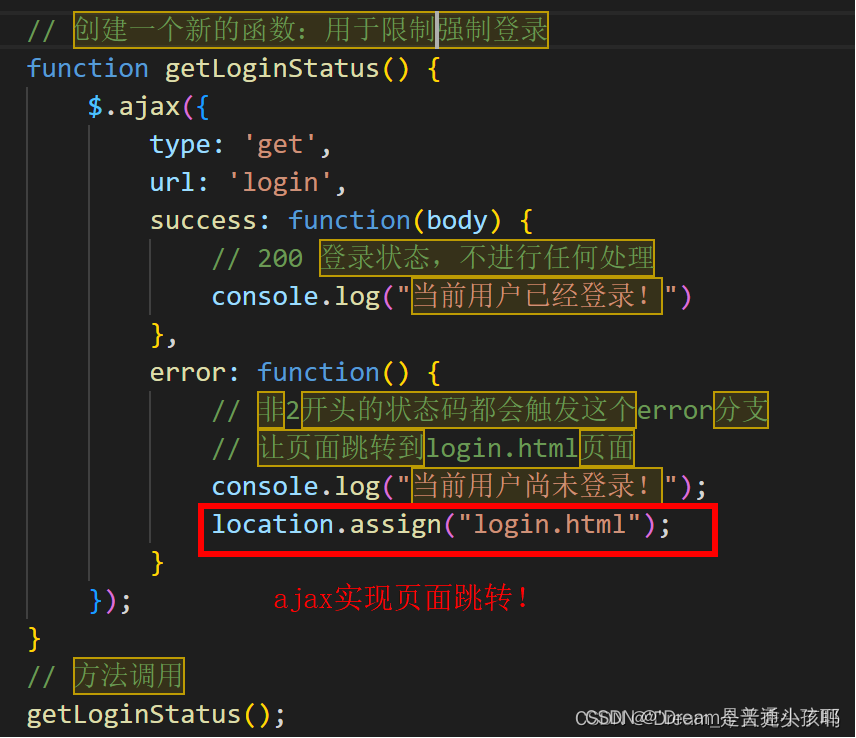
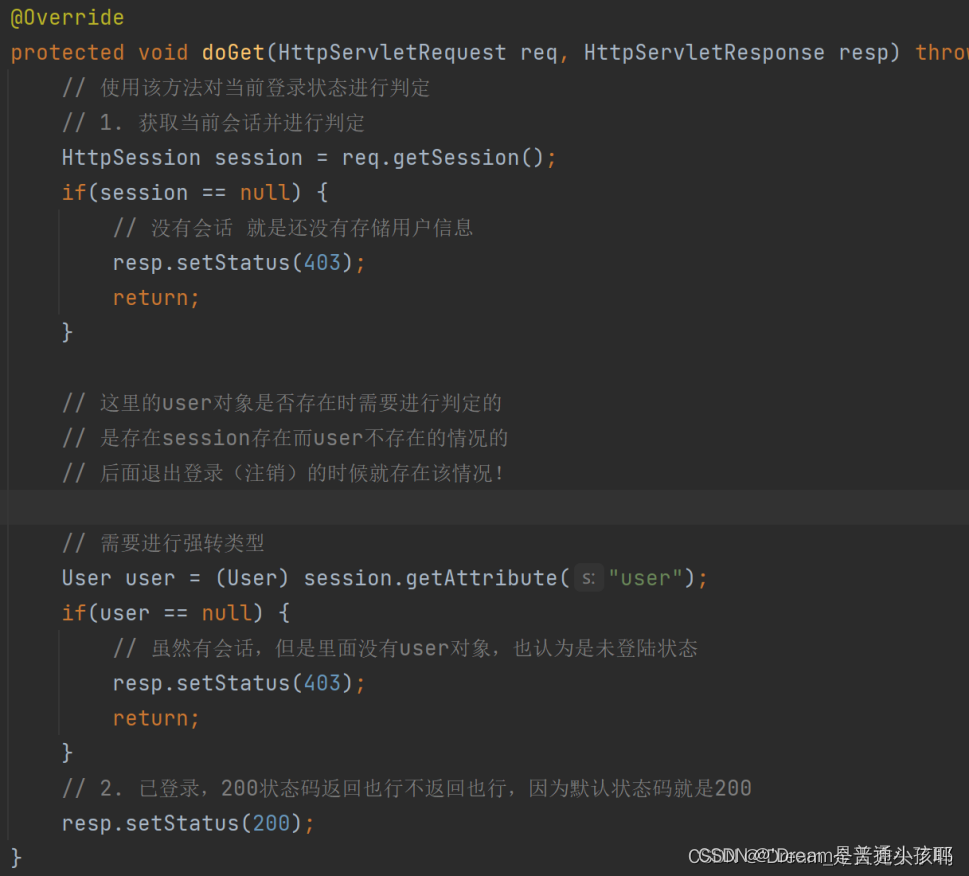
2)后端:
① 重写doGet方法,获取当前会话并判断,如果session存在则继续从session中获取user,如果user不存在则返回403;只有session存在且user也存在才是登录状态。
② 如果用户未登录或者session过期,就会出现session存在但用户未登录的情况。
二)列表页限制博客长度
- 问题:博客列表页展示的是摘要信息,而不是文章的所有内容,需要对展示的文章长度做限制。
- 获取到文章的长度,然后进行判断,如果大于规定长度就使用subString进行截断
// 3. 直接查询博客列表 --博客列表页
public List<Blog> selectAll() {
// 链表用来存储blog
List<Blog> blogs = new ArrayList<>();
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
// 1. 和数据库建立连接
connection = DBUtil.getConnection();
// 2. 构造sql
String sql = "select * from blog order by postTime desc";
statement = connection.prepareStatement(sql);
// 3. 执行sql
resultSet = statement.executeQuery();
// 4. 遍历结果集合拿到结果(while)
while (resultSet.next()) {
Blog blog = new Blog();
blog.setBlogId(resultSet.getInt("blogId"));
blog.setTitle(resultSet.getString("title"));
// blog.setContent(resultSet.getString("content"));
// 进行内容截断作为摘要,避免博客列表页内容过长
String content = resultSet.getString("content");
if(content.length() > 100) {
content = content.substring(0,100) + " ...";
}
blog.setContent(content);
blog.setPostTime(resultSet.getTimestamp("postTime"));
blog.setUserId(resultSet.getInt("userId"));
blogs.add(blog);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
// 释放资源一定不要忘记!!!
DBUtil.close(connection,statement,null);
}
return blogs;
}
三)删除文章做限制
- 问题:作者/登录用户只能删除自己的文章,不能删除别人的文章(暂时没有设置管理员的角色)
- 解决:校验当前登录用户就是文章作者,并且删除时将session中的user对象给移除并重新定位到login页面
if(blog.getUserId() != user.getUserId()) {
// 如果不一样,则说明作者与登录用户不是一个人
// 直接返回403
resp.setStatus(403);
resp.setContentType("text/html; charset=utf8");
resp.getWriter().write("抱歉 您没有权限删除别人的文章!");
return;
}
@WebServlet("/logout")
public class LogoutServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取会话
HttpSession session = req.getSession();
if(session == null) {
resp.setStatus(403);
return;
}
// 直接将session中的user对象给删除就行
session.removeAttribute("user");
// 重定向到登录页面
resp.sendRedirect("login.html");
}
}
四)空指针异常提示
- 问题:如直接在url中输入博客id,此时如果该博客不存在则会报空指针异常
- 解决:如果该id不存在,给出友好提示(后端使用resp.getWriter().write()给出友好提示;在前端页面中定义一个div元素,用于显示后端输出的内容document)
// 2. 获取到blogId
String blogId = req.getParameter("blogId");
if(blogId == null) {
resp.setStatus(404);
resp.setContentType("text/html; charset=utf8");
resp.getWriter().write("当前删除的blogId有误!");
return;
}
// 3. 查询出该blogId对应的Blog对象
BlogDao blogDao = new BlogDao();
Blog blog = blogDao.selectOne(Integer.parseInt(blogId));
if(blog == null) {
resp.setStatus(404);
resp.setContentType("text/html; charset=utf8");
resp.getWriter().write("当前删除的博客不存在! blogId="+blogId);
return;
}
五)时间格式化
- 问题:插入数据库中的数据经查询,将其转换为json字符串之后返回的是TimeStamp类型的,是时间戳的形式
// 从数据库中获取数据:
// executeQuery执行select的sql并将结果进行保存resultSet,遍历结果集合next()并使用getString等获取结果,使用封装的setTimeStamp等来获取到值
public Blog selectOne(int blogId) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
// 1. 和数据库建立连接
connection = DBUtil.getConnection();
// 2. 构造sql
String sql = "select * from blog where blogId = ?";
statement = connection.prepareStatement(sql);
statement.setInt(1,blogId);
// 3. 执行sql
resultSet = statement.executeQuery();
// 4. 遍历结果集合(if)
if (resultSet.next()) {
Blog blog = new Blog();
blog.setBlogId(resultSet.getInt("blogId"));
blog.setTitle(resultSet.getString("title"));
blog.setContent(resultSet.getString("content"));
blog.setPostTime(resultSet.getTimestamp("postTime"));
blog.setUserId(resultSet.getInt("userId"));
return blog;
}
} catch (SQLException throwables) {
throwables.printStackTrace();
} finally {
// 释放资源一定不要忘记!!!
DBUtil.close(connection,statement,resultSet);
}
return null;
}
- 解决:修改getPostTime方法,使其返回值从TimeStamp变为String,然后又使用SimpleDateFormat函数进行格式化。
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
sdf.format(postTime);
// postTime是String类型
补充
-
浏览器访问到的是之前的结果,这是触发了浏览器的缓存。
① 理由:浏览器需要通过网络从远程服务器获取到当前的页面数据,可能比较耗时;此时为了提高效率,做法就是让浏览器把必要的数据进行缓存;下次访问就不必访问网络了,而是直接读取缓存。
② 解决:进行强制刷新保证数据从网络获取。 -
区分:location.href(完整路径) 和 location.seach(query string)

-
后端302重定向
// 返回302重定向
resp.sendRedirect("blog_list.html");
- Ajax中把对象转成字符串
data: JSON.stringify(body)
二、 在线OJ
一)容错能力,如id不存在则友好提示
二)编译运行临时文件uuid
- 问题:
- 解决:
1)获取当前工作路径
System.out.println(System.getProperty("user.dir"));
// 获取当前工作路径
public Task() {
// 使用UUID这个类就能生成一个UUID
WORK_DIR = "./tmp/" + UUID.randomUUID().toString() + "/";
CLASS = "Solution";
CODE = WORK_DIR + CLASS + ".java";
COMPILE_ERROR = WORK_DIR + "compileError.txt";
STDOUT = WORK_DIR + "stdout.txt";
STDERR = WORK_DIR + "stderr.txt";
}
三)黑名单扫描代码
- 简单方法:使用一个黑名单,把有危险代码的特征都放到黑名单中。在获取到用户提交的代码时,就查找一下看当前是否命中了黑名单,如果命中了就提示出错,不去编译执行。
- 实现:
// 0. 进行安全性判断
if (!checkCodeSecurity(question.getCode())) {
System.out.println("用户提交了不安全的代码!");
answer.setError(3);
answer.setReason("您提交的代码可能会危害到服务器,禁止运行!");
return answer;
}
// 1. 将question里的code写入到一个Solution.java文件中
FileUtil.writeFile(CODE,question.getCode());
private boolean checkCodeSecurity(String code) {
// 设定一个黑名单
List<String> blackList = new ArrayList<>();
// 防止提交的代码运行恶意程序
blackList.add("Runtime");
blackList.add("exec");
// 禁止提交的代码读写文件
blackList.add("java.io");
// 禁止提交的代码访问网络
blackList.add("java.net");
// 进行校验
for (String str: blackList) {
int pos = code.indexOf(str);
if(pos >= 0) {
// 找到了恶意代码特征,就不安全,返回false
return false;
}
}
// 遍历结束后还没有发现恶意代码特征,安全
return true;
}
难点:
-
题目详情直接从数据库中获取会发现题目都挤到一行中了。
1)原因:数据库中对题目要求的描述都是使用\n来表示换行的,而HTML不识别\n, HTML中的换行是<br>标签
2)解决:
① 让服务器返回的数据中,\n都替换成
(在后端代码ProblemServlet.java中,获取到题目详情之后,使用replaceAll进行替换)
② 给页面的标签里套一层标签,
标签中的内容是可以识别\n的
-
点击提交之后代码不能进行编译,查看服务器生成的临时文件发现提交过来的代码时编辑框的初始代码
解决:为了查看codeEditor的哪个属性可以看到实时代码,就在console中使用dir(codeEditor)进行查看,发现使用value属性可以看到提交的实时代码。因此在构造请求的时候使用value来替换innerHTML。