文章目录
- 一、概述
- 二、Stable Diffusion v1 & v2
- 2.1 简介
- 2.2 LAION-5B数据集
- 2.3 CLIP条件控制模型
- 2.4 模型训练
- 三、Stable Diffusion 发展
- 3.1 图形界面
- 3.1.1 Web UI
- 3.1.2 Comfy UI
- 3.2 微调方法
- 3.1 Lora
- 3.3 控制模型
- 3.3.1 ControlNet
- 四、其他文生图模型
- 4.1 DALL-E2
- 4.2 Imagen
- 4.3 Midjurney
- 五、部署使用
一、概述
Stable diffusion是一种潜在的文本到图像的扩散模型。基于之前的大量工作(如DDPM、LDM的提出),并且在Stability AI的算力支持和LAION的海量数据支持下,Stable diffusion才得以成功。
Stable diffusion能够在来自LAION- 5B数据库子集的512x512图像上训练潜在扩散模型。与谷歌的Imagen类似,这个模型使用一个冻结的CLIP vitl /14文本编码器来根据文本提示调整模型。
Stable diffusion拥有860M的UNet和123M的文本编码器,该模型相对轻量级,可以运行在具有至少10GB VRAM的GPU上。具体可以参考:https://huggingface.co/CompVis/stable-diffusion

二、Stable Diffusion v1 & v2
2.1 简介
Stable Diffusion v1指的是模型架构的特定配置,它使用下采样因子8的自动编码器,带有860M UNet和CLIP vitl /14文本编码器用于扩散模型。该模型在256x256图像上进行预训练,然后在512x512图像上进行微调。
SD v1 是在LDM的基础上建立的,与LDM的主要区别在于:
- 将原来的条件机制改成用强大的CLIP模型
- 采用更大的数据集LAION- 5B进行训练
关于训练程序和数据的详细信息,以及模型的预期用途,可以参考:https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md。
模型获取地址:https://huggingface.co/CompVis
2.2 LAION-5B数据集
LAION-5B 包含 58.5 亿个 CLIP 过滤的图像-文本对的数据集,比 LAION-400M 大 14 倍,是世界第一大规模、多模态的文本图像数据集,共80T数据,并提供了色情图片过滤、水印图片过滤、高分辨率图片、美学图片等子集和模型,供不同方向研究。
LAION-5B通过CommonCrawl获取文本和图片,OpenAI的CLIP计算后获取图像和文本的相似性,并删除相似度低于设定阈值的图文对(英文阈值0.28,其余阈值0.26),500亿图片保留了不到60亿,最后形成58.5亿个图文对,包括23.2亿的英语,22.6亿的100+语言及12.7亿的未知语言。
LAION-5B 进一步扩展了语言视觉模型的开放数据集规模,使得更多研究者能够参与到多模态领域中。并且为了推动研究,提供了多个子集用于训练各种规模的模型,也可以通过web界面检索构建子集训练。已有多个模型和论文证明了基于LAION子集训练的模型能够取得良好甚至SOTA的效果。
LAION-5B数据集官网:https://laion.ai/blog/laion-5b/
2.3 CLIP条件控制模型
-
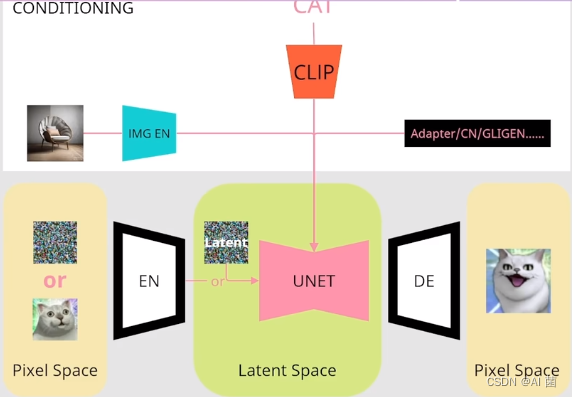
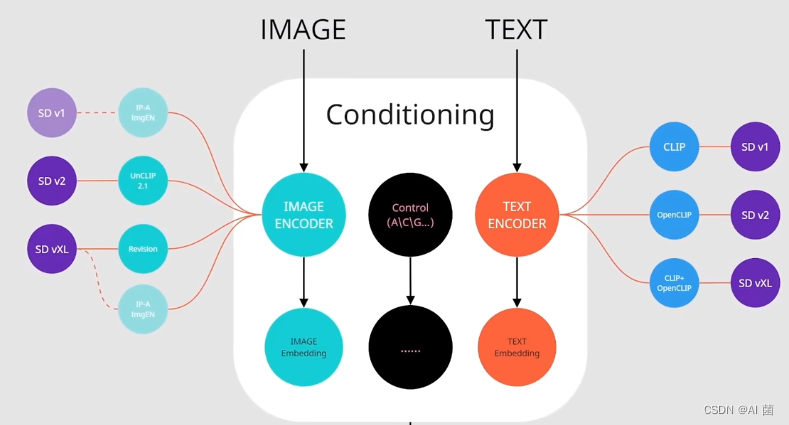
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
-
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。 比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
2.4 模型训练
SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。
训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
SD提供了不同版本的模型,其训练过程如下:
- SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。
三、Stable Diffusion 发展
SDv2在SDv1的基础上引入了更强大的图文编码器(如OpenCLIP),性能进一步得到提升;随着图形界面的出现,微调方法的发布,控制模型的提出,Stable Diffusion逐渐进入了SDvXL时代。
3.1 图形界面
3.1.1 Web UI
Stable Diffusion Web UI 是一个基于 Stable Diffusion 的基础应用,利用 gradio 模块搭建出的交互程序,可以在低代码 GUI 中立即访问 Stable Diffusion。
Stable Diffusion Web UI 提供了多种功能,如 txt2img、img2img、inpaint 等,还包含了许多模型融合改进、图片质量修复等附加升级。通过调节不同参数可以生成不同效果,用户可以根据自己的需要和喜好进行创作。
除此之外,可以通过Stable Diffusion Web UI 训练我们自己的模型,它提供了多种训练方式,通过掌握训练方法可以自己制作模型。
具体介绍可参考:Stable Diffusion Web UI
3.1.2 Comfy UI
ComfyUI 是一个基于节点流程式的stable diffusion AI 绘图工具WebUI, 通过将stable diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。但节点式的工作流也提高了一部分使用门槛。
同时,因为内部生成流程做了优化,生成图片时的速度相较于webui又10%~25%的提升(根据不同显卡提升幅度不同),生成大图片的时候不会爆显存,只是图片太大时,会因为切块运算的导致图片碎裂(个人测试在8G显存下直接生成2360x1440分辨率没有问题,往上有几率切碎)
ComfyUI中简单的lora+Highresfix流程:
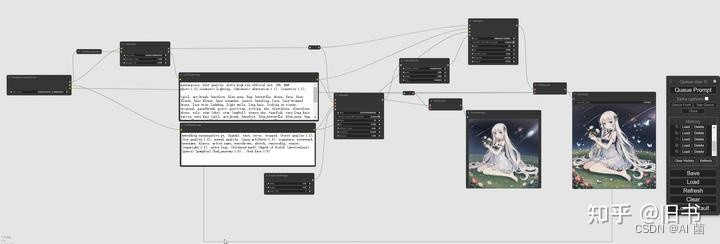
具体介绍可参考:Stable Diffusion Comfy UI
3.2 微调方法
3.1 Lora
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。比如,GPT-3有1750亿参数,为了让它能干特定领域的活儿,需要做微调,但是如果直接对GPT-3做微调,成本太高太麻烦了。
LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。研究发现,LoRA的微调质量与全模型微调相当,我愿称之为神器。
要做个比喻的话,就好比是大模型的一个小模型,或者说是一个插件。LoRA本来是给大语言模型准备的,但把它用在cross-attention layers(交叉关注层)也能影响用文字生成图片的效果。最早的Stable Diffusion模型其实不支持LoRa的,后来才加入了对LoRa的支持。
参考链接:https://huggingface.co/blog/lora
3.3 控制模型
3.3.1 ControlNet
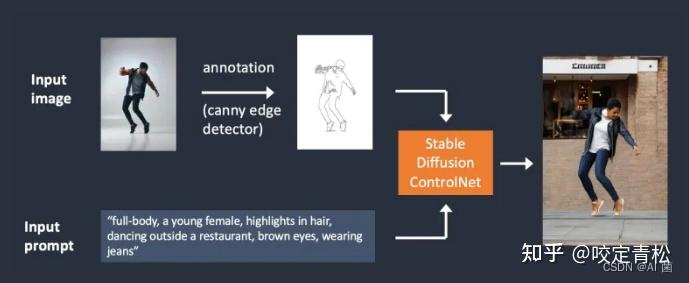
ControlNet 是用来控制SD模型的一种神经网络模型,是SD的一种扩展模型。通过这种扩展模型,可以 引入更多条件来干预图像生成过程,比如能够将参考图像的构图(compositions )或者人体姿势迁移到目标图像。
比如使用canny边缘检测 来控制图像生成:
四、其他文生图模型
4.1 DALL-E2
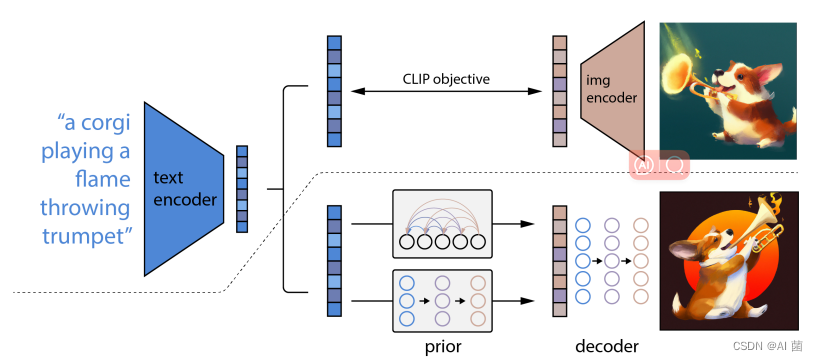
2022年OpenAI发表了《Hierarchical Text-Conditional Image Generation with CLIP Latents》这篇论文,这正是DALL-E2的由来。DALL-E2并不是一蹴而就,而是基于OpenAI最近数年已有的工作成果,包括DALL-E、CLIP、GLIDE等。
DALL-E2 的基本原理和SD一样,都是源于最初的扩散概率模型(DDPM),与之不同发是,SD继承了LDM的思想,在潜在空间中进行扩散学习;而DALL-E2是在像素空间中进行扩散学习,所以其计算复杂度较高。
4.2 Imagen
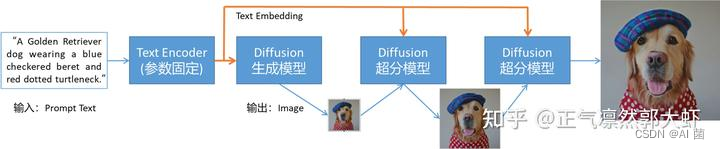
Imagen 于 2022 年 5 月由谷歌发布,Imagen 使用 T5-XXL 通用大型语言模型作为文本编码器,通过扩散模型实现文本到低分辨率图像的生成,最后将低分辨率图像进行两次超分,得到高分辨率图像。
4.3 Midjurney
midjourney是一个AI绘画工具,其源码是未公开的,算法整体是基于stable diffusion,在稳定扩散算法的基础上进行了改进。Midjourney 的优势在于:
- 更高的图像质量:Midjourney 能够生成更高质量的图像,这得益于其引入了一个新的中间状态表示,使得模型更好地学习图像的细节和结构。
- 更好的控制能力:Midjourney 的中间状态表示使得其可以对图像生成过程进行更精细的控制,包括颜色、纹理等方面。
- 更快的训练速度:Midjourney 的训练速度相对较快,这得益于其采用了一种新的训练策略,能够更好地平衡生成图像的质量和训练速度。
五、部署使用
- 后续持续更新
相关参考:
- 文生图模型之Stable Diffusion
- 2 万字带你了解 Stable Diffusion 发展史
- 从DDPM到DALL-E2和Stable Diffusion——扩散模型相关论文阅读
- Stable Diffusion ComfyUI 入门感受
- stable diffusion LORA模型训练最全最详细教程