一、本文介绍
本文给大家带来利用RT-DETR模型主干HGNet去替换YOLOv8的主干,RT-DETR是今年由百度推出的第一款实时的ViT模型,其在实时检测的领域上号称是打败了YOLO系列,其利用两个主干一个是HGNet一个是ResNet,其中HGNet就是我们今天来讲解的网络结构模型(亲测这个HGNet网络比YOLO的主干更加轻量化和精度更高的主干,非常适合轻量化研究的读者),这个网络结构目前还没有推出论文,所以其理论知识在网络上也是非常的少,我也是根据网络结构图进行了分析(亲测替换之后主干GFLOPs降低到7.7,精度mAP提高0.05)。
轻量化效果:⭐⭐⭐⭐⭐
涨点效果:⭐⭐⭐⭐⭐
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
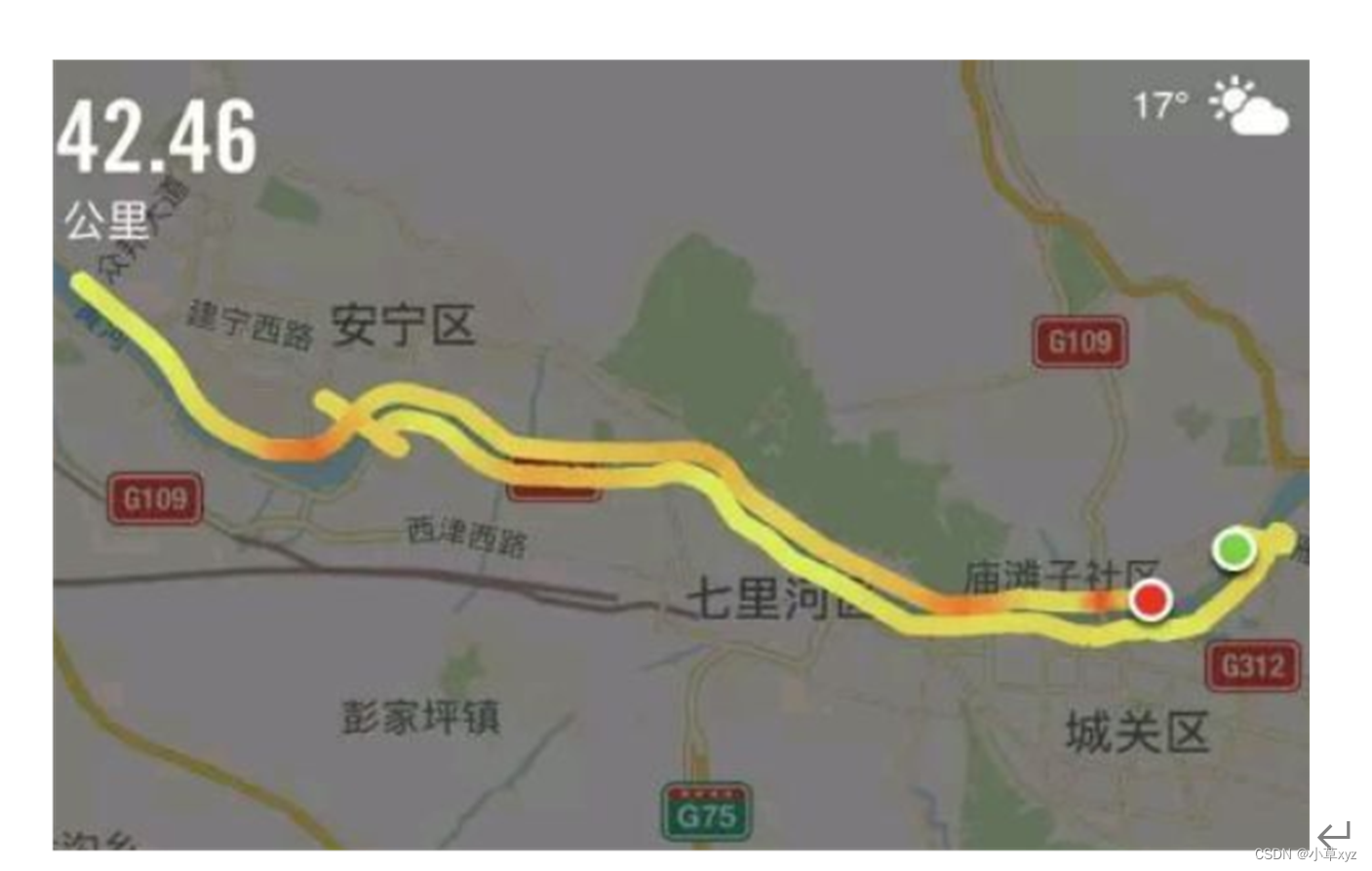
训练结果对比图->
这次试验我用的数据集大概有七八百张照片训练了150个epochs,虽然没有完全拟合但是效果有很高的涨点幅度,所以大家可以进行尝试毕竟不同的数据集上效果也可能差很多,同时我在后面给了多种yaml文件大家可以分别进行实验来检验效果。
可以看到这个图片的mAP50和mAP50-95都有一定程度的上涨。

目录
一、本文介绍
二、HGNetV2原理讲解
三、HGNetV2的代码
四、手把手教你添加HGNetV2
4. 1 HGNetV2-l的yaml文件(此为对比试验版本)
4.2 HGNetV2-x的yaml文件
五、运行成功记录
六、本文总结
二、HGNetV2原理讲解

论文地址:RT-DETR论文地址
本文代码来源:HGNetV2的代码来源

PP-HGNet 骨干网络的整体结构如下:

其中,PP-HGNet是由多个HG-Block组成,HG-Block的细节如下:
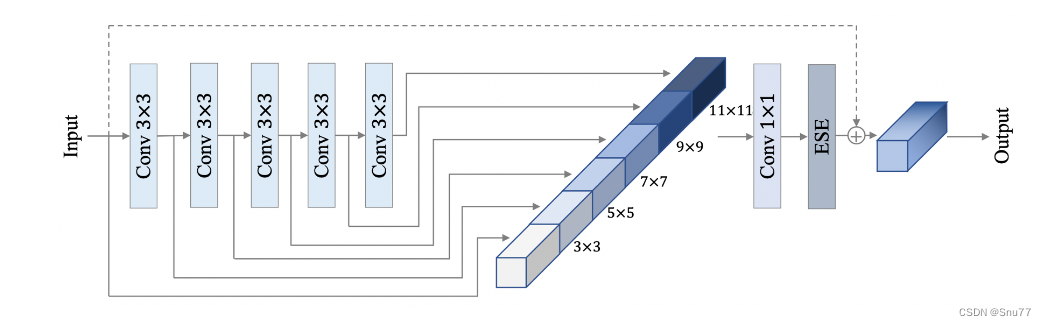
上面的图表是PP-HGNet神经网络架构的概览,下面我会对其中的每一个模块进行分析:
1. Stem层:这是网络的初始预处理层,通常包含卷积层,开始从原始输入数据中提取特征。
2. HG(层次图)块:这些块是网络的核心组件,设计用于以层次化的方式处理数据。每个HG块可能处理数据的不同抽象层次,允许网络从低级和高级特征中学习。
3. LDS(可学习的下采样)层:位于HG块之间的这些层可能执行下采样操作,减少特征图的空间维度,减少计算负载并可能增加后续层的感受野。
4. GAP(全局平均池化):在最终分类之前,使用GAP层将特征图的空间维度减少到每个特征图一个向量,有助于提高网络对输入数据空间变换的鲁棒性。
5. 最终的卷积和全连接(FC)层:网络以一系列执行最终分类任务的层结束。这通常涉及一个卷积层(有时称为1x1卷积)来组合特征,然后是将这些特征映射到所需输出类别数量的全连接层。
这种架构的主要思想是利用层次化的方法来提取特征,其中复杂的模式可以在不同的规模和抽象层次上学习,提高网络处理复杂图像数据的能力。
这种分层和高效的处理对于图像分类等复杂任务非常有利,在这些任务中,精确预测至关重要的是在不同规模上识别复杂的模式和特征。图表还显示了HG块的扩展视图,包括多个不同滤波器大小的卷积层,以捕获多样化的特征,然后通过一个元素级相加或连接的操作(由+符号表示)在数据传递到下一层之前。
三、HGNetV2的代码
需要注意的是HGNetV2这个版本的所需组件已经集成在YOLOv8的仓库了,所以我们无需做任何的代码层面的改动,只需要设计yaml文件来配合Neck部分融合特征即可了,但是我还是把代码放在这里,供有兴趣的读者看一下,也和上面的结构进行一个对照。主要的三个结构HGStem,HGBlock,DWConv。
class HGStem(nn.Module):
"""
StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2):
"""Initialize the SPP layer with input/output channels and specified kernel sizes for max pooling."""
super().__init__()
self.stem1 = Conv(c1, cm, 3, 2)
self.stem2a = Conv(cm, cm // 2, 2, 1, 0)
self.stem2b = Conv(cm // 2, cm, 2, 1, 0)
self.stem3 = Conv(cm * 2, cm, 3, 2)
self.stem4 = Conv(cm, c2, 1, 1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
x = self.stem1(x)
x = F.pad(x, [0, 1, 0, 1])
x2 = self.stem2a(x)
x2 = F.pad(x2, [0, 1, 0, 1])
x2 = self.stem2b(x2)
x1 = self.pool(x)
x = torch.cat([x1, x2], dim=1)
x = self.stem3(x)
x = self.stem4(x)
return x
class HGBlock(nn.Module):
"""
HG_Block of PPHGNetV2 with 2 convolutions and LightConv.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=True):
"""Initializes a CSP Bottleneck with 1 convolution using specified input and output channels."""
super().__init__()
block = LightConv if lightconv else Conv
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # squeeze conv
self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # excitation conv
self.add = shortcut and c1 == c2
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
y = [x]
y.extend(m(y[-1]) for m in self.m)
y = self.ec(self.sc(torch.cat(y, 1)))
return y + x if self.add else y
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class DWConv(Conv):
"""Depth-wise convolution."""
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
"""Initialize Depth-wise convolution with given parameters."""
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
四、手把手教你添加HGNetV2
这里不需要改动什么,如果你的版本是老版本的,没有集成RT-DETR的版本,那么大家可以下载一个新版本可以参考其中的怎么改,我这里就不在描述,否则拉下某一步在导致大家报错。
4. 1 HGNetV2-l的yaml文件(此为对比试验版本)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 3], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.2 HGNetV2-x的yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 64]] # 0-P2/4
- [-1, 6, HGBlock, [64, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [128, 512, 3]]
- [-1, 6, HGBlock, [128, 512, 3, False, True]] # 4-stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 5-P3/16
- [-1, 6, HGBlock, [256, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [256, 1024, 5, True, True]]
- [-1, 6, HGBlock, [256, 1024, 5, True, True]]
- [-1, 6, HGBlock, [256, 1024, 5, True, True]]
- [-1, 6, HGBlock, [256, 1024, 5, True, True]] # 10-stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 11-P4/32
- [-1, 6, HGBlock, [512, 2048, 5, True, False]]
- [-1, 6, HGBlock, [512, 2048, 5, True, True]] # 13-stage 4
- [-1, 1, SPPF, [1024, 5]] # 14
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 15
- [[-1, 10], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 19 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 16], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 22 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 25 (P5/32-large)
- [[19, 22, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
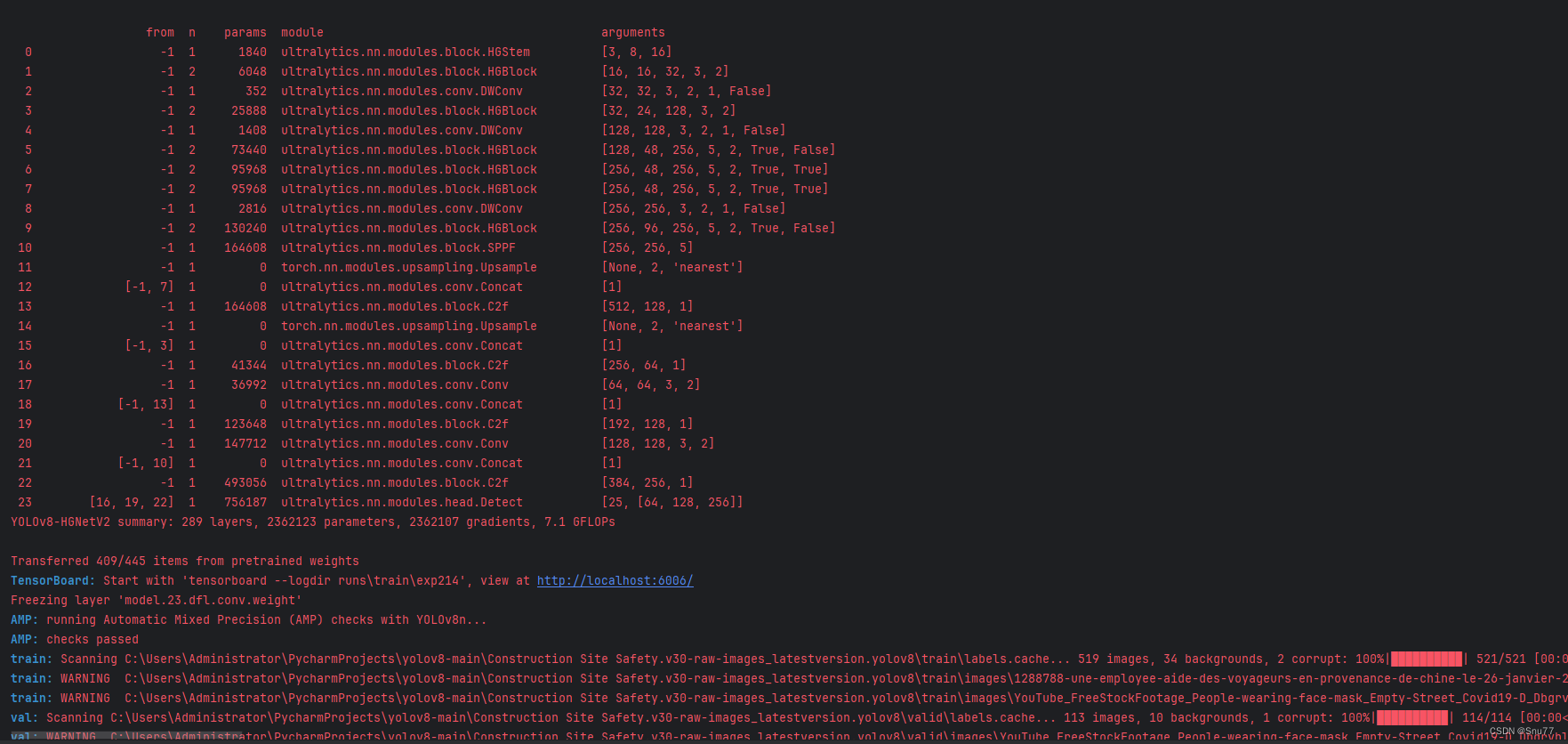
五、运行成功记录
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备