引言
深度生成式模型应用于图像、音频、视频合成和自然语言处理等不同领域。随着深度学习技术的快速发展,近年来不同的深度生成模型出现了爆炸式的增长。这导致人们越来越有兴趣比较和评估这些模型的性能和对不同领域的适用性。在
本文中,我们的目标是提供深度生成式模型的全面比较,包括扩散模型、生成对抗网络(GAN)和变分自编码器(VAE)。我将回顾它们的基本原则、优点和缺点。目标是清楚地了解这些模型之间的差异和相似之处,以指导研究人员和从业者为其特定应用选择最合适的深度生成模型。

算法概述
GAN [1, 2] 学习生成类似于训练数据集的新数据。它由两个神经网络:一个生成器和一个鉴别器组成,实际上是一个 two-player game。生成器采用从正态分布中采样的随机值并生成合成样本,而鉴别器则尝试区分真实样本和生成样本。生成器经过训练可以产生可以欺骗鉴别器的真实输出,而鉴别器经过训练可以正确区分真实数据和生成数据。图 1 的顶行显示了其工作方案。
VAE [3, 4] 由编码器和解码器组成。编码器将高维输入数据映射为低维表示,而解码器尝试通过将该表示映射回其原始形式来重建原始高维输入数据。编码器通过预测均值和标准差向量,将隐表示编码的正态分布输出为低维表示。图 1 的中间行演示了其工作原理。
扩散模型 [5, 6] 由前向扩散和反向扩散过程组成。前向扩散是一个马尔可夫链,它逐渐向输入数据添加噪声,直到获得白噪声。这不是一个可学习的过程,通常需要 1000 个步骤。反向扩散过程旨在将正向过程反向逐步去除噪声以恢复原始数据。反向扩散过程是使用可训练的神经网络来实现的。图 1 的底行显示了这一点。
特点总结
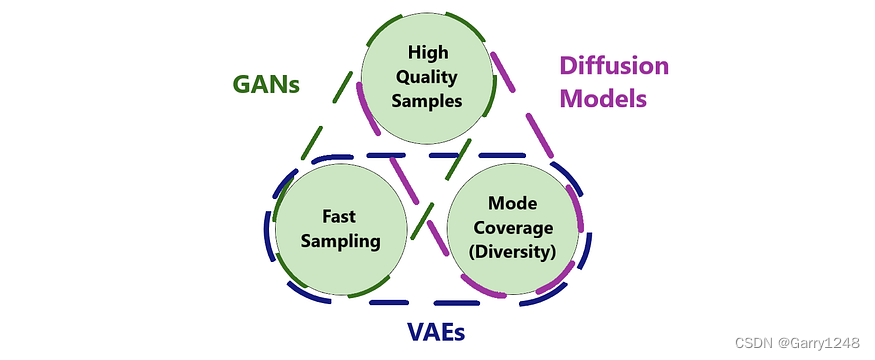
GAN
- 它由两个神经网络组成:生成器和鉴别器。
- 通过对抗性损失进行训练。生成器的目的是通过生成与真实样本无法区分的样本来“欺骗”鉴别器。目的是使鉴别器无法区分真实样本和生成样本。
- 高保真样本。神经网络是收敛的,那么判别器就无法区分真实样本和生成样本。这会产生非常真实的样本。
- 低多样性样本。对抗性损失没有动力覆盖整个数据分布。当鉴别器训练过度或发生灾难性遗忘时,生成器可能会很乐意产生一小部分数据多样性。这是一个常见问题,称为模式崩溃[2]。
- 很难训练。确定网络何时收敛可能很困难。不要监控一项损失的下降,而应该查看两项没有简单解释的损失,有时并不清楚你的神经网络发生了什么。通常你需要应对模式崩溃。
- 通过截断技巧,可以在多样性和保真度之间进行简单的权衡。
VAE
- 它由两个神经网络组成:编码器和解码器。
- 通过最大化似然对数进行训练,经过数学简化后,成为 L2 损失。它估计输入样本和生成样本之间的差异。
- 低保真度样本。有几个原因:
- 由于编码器预测潜在代码的分布,因此可能存在两个潜在代码分布彼此重叠的情况。因此,如果两个输入具有相同的潜在代码,则最佳解码将是两个输入的平均值。这会导致样本模糊。Gan和扩散模型不存在这个问题。
- 它具有基于像素的损失。带有头发的图像的生成将由交替的亮像素和暗像素组成。如果生成仅移动一个像素,则与地面真实情况的相似性损失将显着增加或减少。然而,VAE 不保留此类像素级信息,因为潜在空间比图像小得多。这导致模型预测明暗像素的平均值以找到最佳解决方案,从而产生模糊的图像。GAN 不存在这样的问题,因为判别器可以利用样本的模糊性来区分真实样本和生成样本。同样,扩散模型尽管具有相同的基于像素的损失,但不存在此问题。他们依靠从真实情况获得的当前噪声图像结构来预测下一步的去噪。
- 高多样性样本。似然最大化强制覆盖训练数据集的所有模式,为每个训练数据点提供神经网络容量。
- 易于训练。它有一个易于处理的似然损失。
- 编码器使您能够获取任何图像的潜在代码,这提供了超出生成范围的额外可能性。
扩散模型
- 它由固定的前向扩散过程和可学习的反向扩散过程组成。
- 前向扩散过程是一个多步骤的过程,逐渐向样本中添加少量高斯噪声,直到变成白噪声。常用的步数值为 1000。
- 反向扩散过程也是一个多步骤过程,它反转正向扩散过程,将白噪声带回到图像中。反向扩散过程的每一步都由神经网络执行,并且其步骤数与正向过程相同。
- 通过最大化似然对数进行训练,经过数学简化后,成为 L2 损失。在训练期间,我们使用随机选择的 T 值的公式计算 T 和 T-1 步骤的噪声图像。然后,扩散模型根据 T 步噪声图像预测 T-1 步图像。使用 L2 损失对生成的图像和 T-1 步图像进行比较。
- 高保真样本。这是由于逐渐消除噪音的本质。与一次性生成样本的 VAE 和 GAN 不同,扩散模型逐步创建样本。该模型首先创建一个粗糙的图像结构,然后专注于在顶部添加精细的细节。
- 高多样性样本。似然最大化涵盖了训练数据集的所有模式。
- 中间噪声图像用作潜在代码,并且具有与训练图像相同的大小。这就是扩散模型能够生成高保真样本的原因之一。
- 易于训练。它有一个易于处理的似然损失。
- 样本生成缓慢。与 GAN 和 VAE 不同,它需要神经网络多次运行才能逐渐生成样本。尽管有一些采样方法可以将这个过程加速几个数量级,但它们仍然比 GAN 和 VAE 慢得多。
- 只需利用输入噪声,多步骤过程即可提供新功能,例如修复或图像到图像生成。
结论
GAN、VAE 和扩散模型都是流行的深度学习生成式模型,它们具有独特的功能并适合不同的用例。每种模型都有其优点和缺点,在为特定应用选择模型之前了解其细微差别非常重要。
参考资料
- Generative Adversarial Nets. Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio — https://arxiv.org/pdf/1406.2661.pdf
- GAN Mode Collapse Explanation — https://medium.com/towards-artificial-intelligence/gan-mode-collapse-explanation-fa5f9124ee73
- Auto-Encoding Variational Bayes. Diederik P Kingma, Max Welling — https://arxiv.org/pdf/1312.6114.pdf
- Understanding Variational Autoencoders (VAEs) — https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, Surya Ganguli — https://arxiv.org/pdf/1503.03585.pdf
- What are Diffusion Models? Lilian Weng — https://lilianweng.github.io/posts/2021-07-11-diffusion-models







![[足式机器人]Part2 Dr. CAN学习笔记-数学基础Ch0-8Matlab/Simulink传递函数Transfer Function](https://img-blog.csdnimg.cn/direct/301838452fb34a849ecb0dad60eff3d6.png)